 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Comprehensive Overview and Comparative Analysis on Deep Learning Models: CNN, RNN, LSTM, GRU
Jun 01, 2023
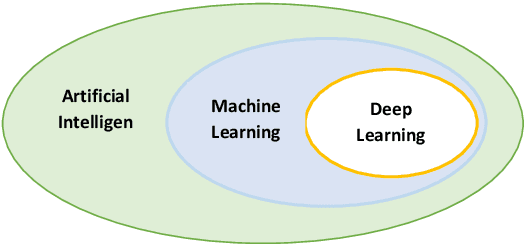
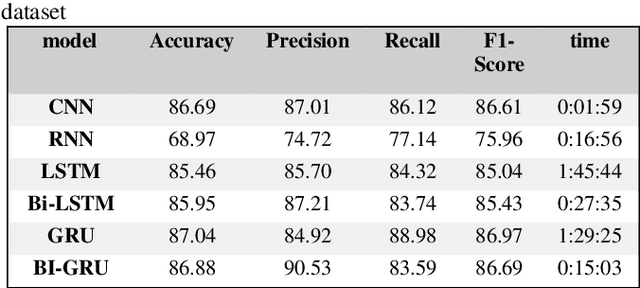
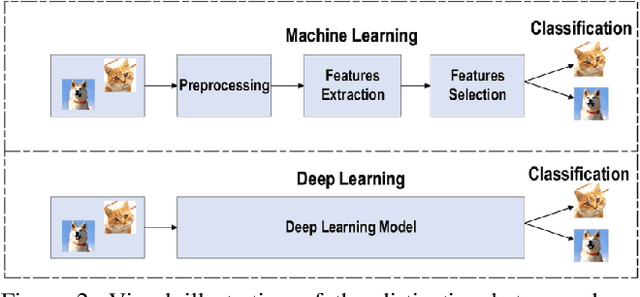
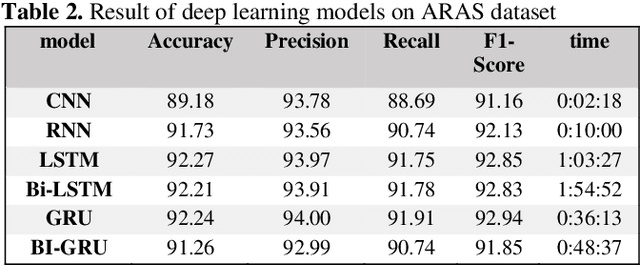
Deep learning (DL) has emerged as a powerful subset of machine learning (ML) and artificial intelligence (AI), outperforming traditional ML methods, especially in handling unstructured and large datasets. Its impact spans across various domains, including speech recognition, healthcare, autonomous vehicles, cybersecurity, predictive analytics, and more. However, the complexity and dynamic nature of real-world problems present challenges in designing effective deep learning models. Consequently, several deep learning models have been developed to address different problems and applications. In this article, we conduct a comprehensive survey of various deep learning models, including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Generative Models, Deep Reinforcement Learning (DRL), and Deep Transfer Learning. We examine the structure, applications, benefits, and limitations of each model. Furthermore, we perform an analysis using three publicly available datasets: IMDB, ARAS, and Fruit-360. We compare the performance of six renowned deep learning models: CNN, Simple RNN, Long Short-Term Memory (LSTM), Bidirectional LSTM, Gated Recurrent Unit (GRU), and Bidirectional GRU.
Joint Speech Recognition and Audio Captioning
Feb 03, 2022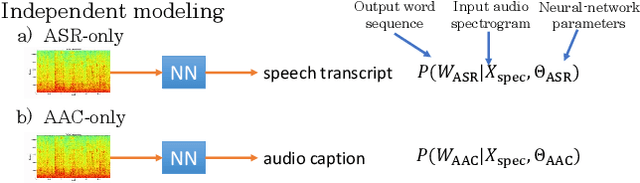
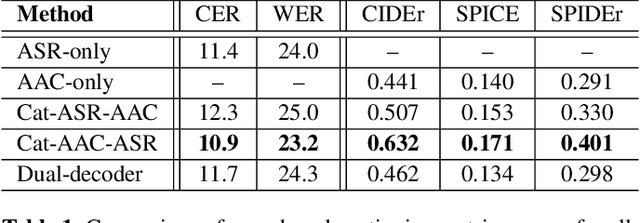
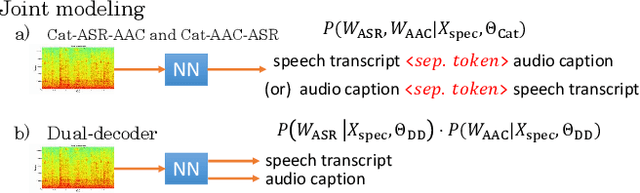
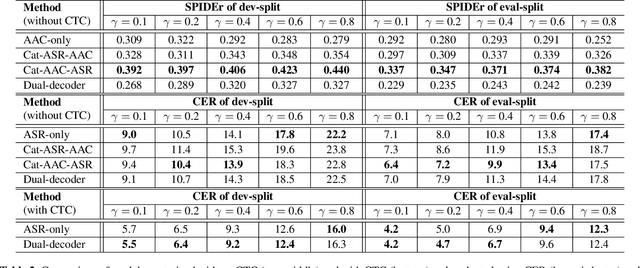
Speech samples recorded in both indoor and outdoor environments are often contaminated with secondary audio sources. Most end-to-end monaural speech recognition systems either remove these background sounds using speech enhancement or train noise-robust models. For better model interpretability and holistic understanding, we aim to bring together the growing field of automated audio captioning (AAC) and the thoroughly studied automatic speech recognition (ASR). The goal of AAC is to generate natural language descriptions of contents in audio samples. We propose several approaches for end-to-end joint modeling of ASR and AAC tasks and demonstrate their advantages over traditional approaches, which model these tasks independently. A major hurdle in evaluating our proposed approach is the lack of labeled audio datasets with both speech transcriptions and audio captions. Therefore we also create a multi-task dataset by mixing the clean speech Wall Street Journal corpus with multiple levels of background noises chosen from the AudioCaps dataset. We also perform extensive experimental evaluation and show improvements of our proposed methods as compared to existing state-of-the-art ASR and AAC methods.
Enhancing Speech Recognition Decoding via Layer Aggregation
Apr 05, 2022
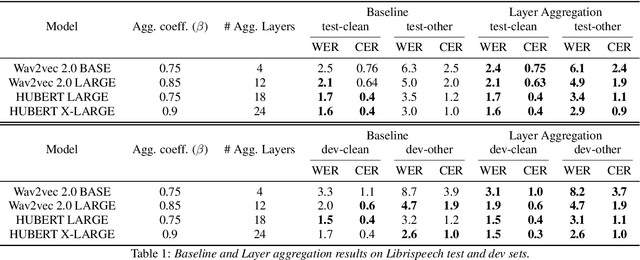
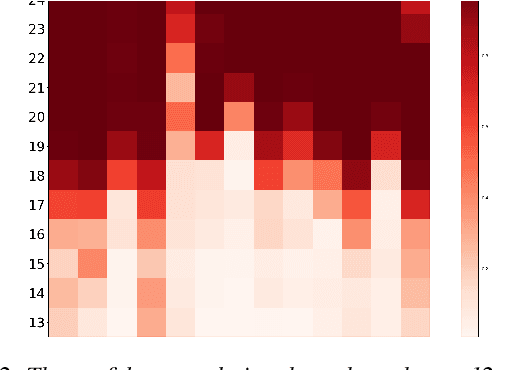
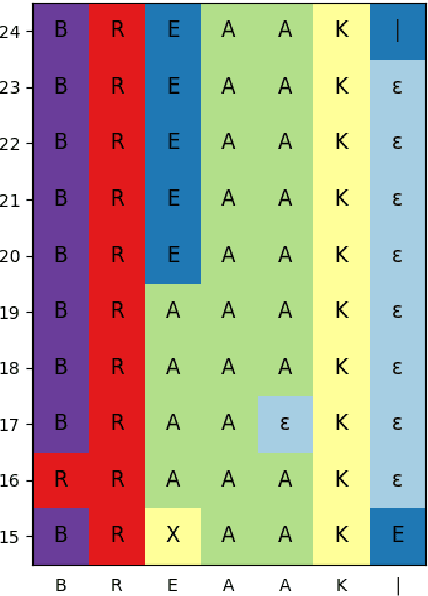
Recently proposed speech recognition systems are designed to predict using representations generated by their top layers, employing greedy decoding which isolates each timestep from the rest of the sequence. Aiming for improved performance, a beam search algorithm is frequently utilized and a language model is incorporated to assist with ranking the top candidates. In this work, we experiment with several speech recognition models and find that logits predicted using the top layers may hamper beam search from achieving optimal results. Specifically, we show that fined-tuned Wav2Vec 2.0 and HuBERT yield highly confident predictions, and hypothesize that the predictions are based on local information and may not take full advantage of the information encoded in intermediate layers. To this end, we perform a layer analysis to reveal and visualize how predictions evolve throughout the inference flow. We then propose a prediction method that aggregates the top M layers, potentially leveraging useful information encoded in intermediate layers and relaxing model confidence. We showcase the effectiveness of our approach via beam search decoding, conducting our experiments on Librispeech test and dev sets and achieving WER, and CER reduction of up to 10% and 22%, respectively.
Can We Trust Explainable AI Methods on ASR? An Evaluation on Phoneme Recognition
May 29, 2023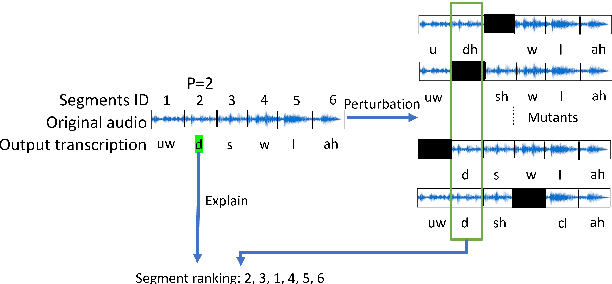



Explainable AI (XAI) techniques have been widely used to help explain and understand the output of deep learning models in fields such as image classification and Natural Language Processing. Interest in using XAI techniques to explain deep learning-based automatic speech recognition (ASR) is emerging. but there is not enough evidence on whether these explanations can be trusted. To address this, we adapt a state-of-the-art XAI technique from the image classification domain, Local Interpretable Model-Agnostic Explanations (LIME), to a model trained for a TIMIT-based phoneme recognition task. This simple task provides a controlled setting for evaluation while also providing expert annotated ground truth to assess the quality of explanations. We find a variant of LIME based on time partitioned audio segments, that we propose in this paper, produces the most reliable explanations, containing the ground truth 96% of the time in its top three audio segments.
Improving Textless Spoken Language Understanding with Discrete Units as Intermediate Target
May 29, 2023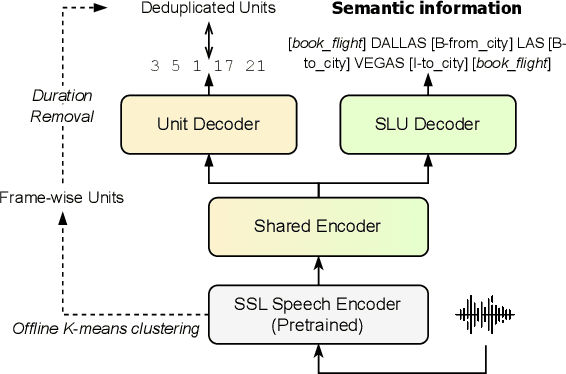



Spoken Language Understanding (SLU) is a task that aims to extract semantic information from spoken utterances. Previous research has made progress in end-to-end SLU by using paired speech-text data, such as pre-trained Automatic Speech Recognition (ASR) models or paired text as intermediate targets. However, acquiring paired transcripts is expensive and impractical for unwritten languages. On the other hand, Textless SLU extracts semantic information from speech without utilizing paired transcripts. However, the absence of intermediate targets and training guidance for textless SLU often results in suboptimal performance. In this work, inspired by the content-disentangled discrete units from self-supervised speech models, we proposed to use discrete units as intermediate guidance to improve textless SLU performance. Our method surpasses the baseline method on five SLU benchmark corpora. Additionally, we find that unit guidance facilitates few-shot learning and enhances the model's ability to handle noise.
Adapting self-supervised models to multi-talker speech recognition using speaker embeddings
Nov 01, 2022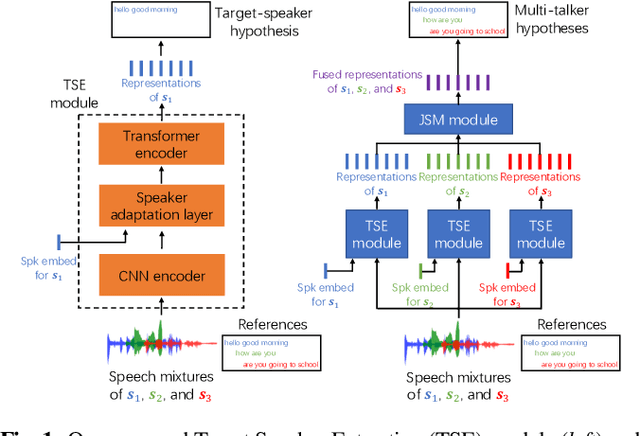
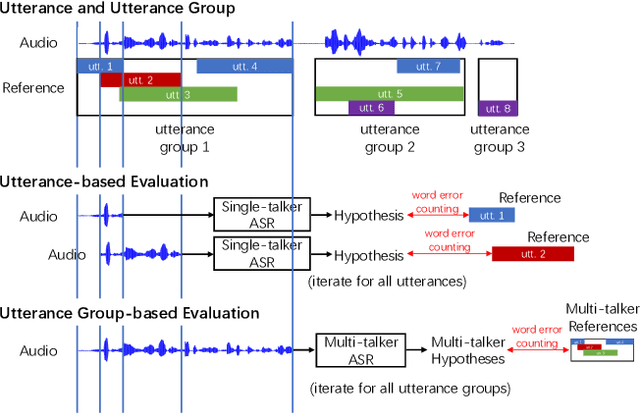
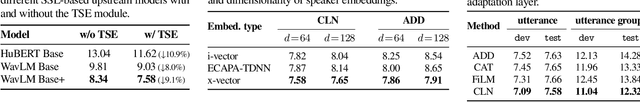
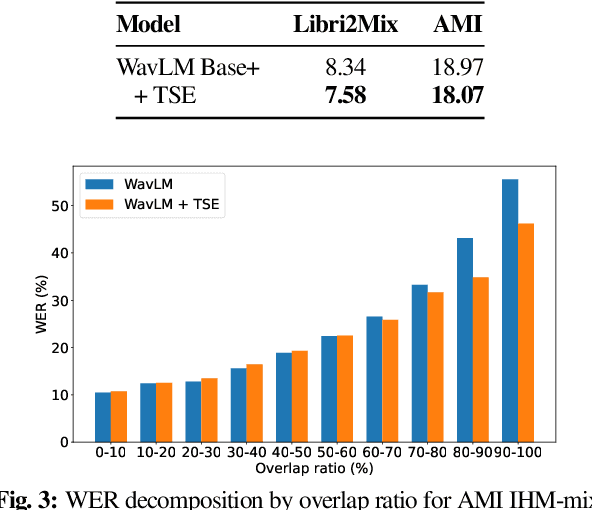
Self-supervised learning (SSL) methods which learn representations of data without explicit supervision have gained popularity in speech-processing tasks, particularly for single-talker applications. However, these models often have degraded performance for multi-talker scenarios -- possibly due to the domain mismatch -- which severely limits their use for such applications. In this paper, we investigate the adaptation of upstream SSL models to the multi-talker automatic speech recognition (ASR) task under two conditions. First, when segmented utterances are given, we show that adding a target speaker extraction (TSE) module based on enrollment embeddings is complementary to mixture-aware pre-training. Second, for unsegmented mixtures, we propose a novel joint speaker modeling (JSM) approach, which aggregates information from all speakers in the mixture through their embeddings. With controlled experiments on Libri2Mix, we show that using speaker embeddings provides relative WER improvements of 9.1% and 42.1% over strong baselines for the segmented and unsegmented cases, respectively. We also demonstrate the effectiveness of our models for real conversational mixtures through experiments on the AMI dataset.
Rethinking Speech Recognition with A Multimodal Perspective via Acoustic and Semantic Cooperative Decoding
May 23, 2023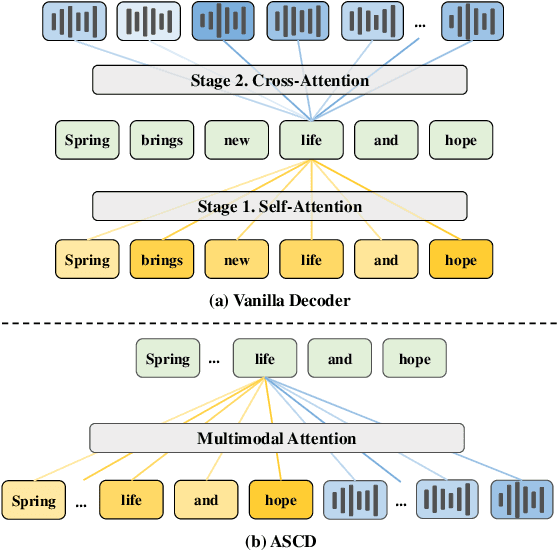
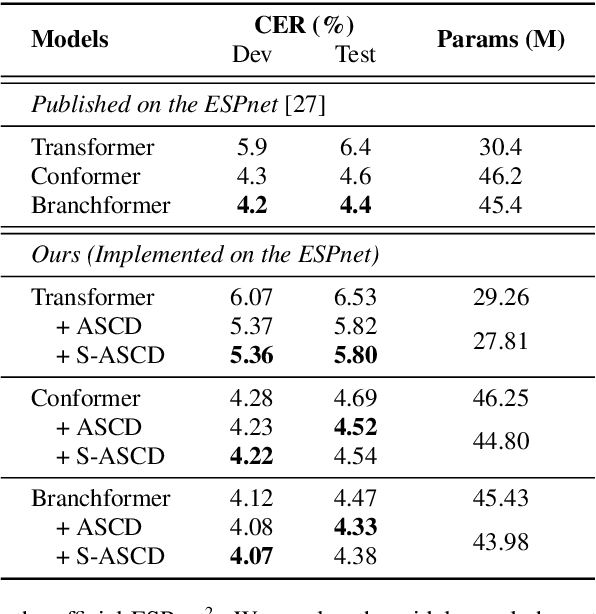
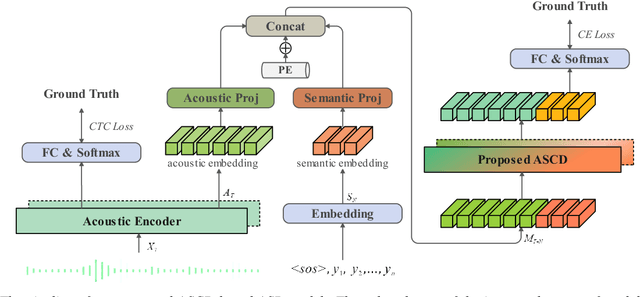
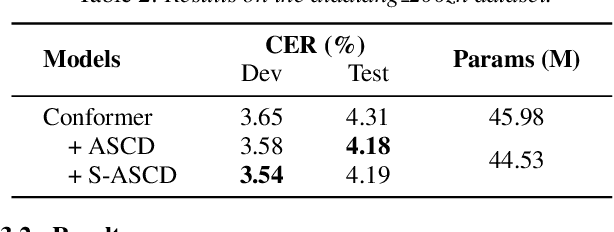
Attention-based encoder-decoder (AED) models have shown impressive performance in ASR. However, most existing AED methods neglect to simultaneously leverage both acoustic and semantic features in decoder, which is crucial for generating more accurate and informative semantic states. In this paper, we propose an Acoustic and Semantic Cooperative Decoder (ASCD) for ASR. In particular, unlike vanilla decoders that process acoustic and semantic features in two separate stages, ASCD integrates them cooperatively. To prevent information leakage during training, we design a Causal Multimodal Mask. Moreover, a variant Semi-ASCD is proposed to balance accuracy and computational cost. Our proposal is evaluated on the publicly available AISHELL-1 and aidatatang_200zh datasets using Transformer, Conformer, and Branchformer as encoders, respectively. The experimental results show that ASCD significantly improves the performance by leveraging both the acoustic and semantic information cooperatively.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 12, 2023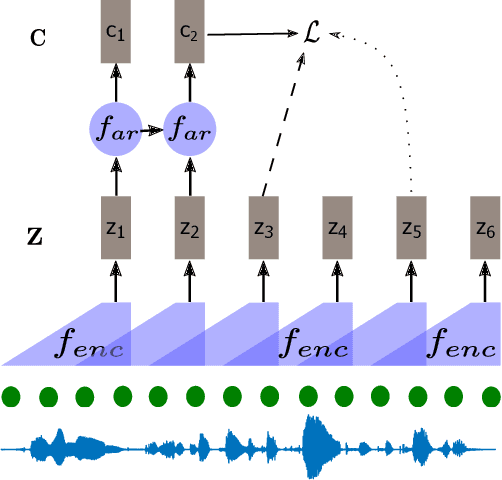
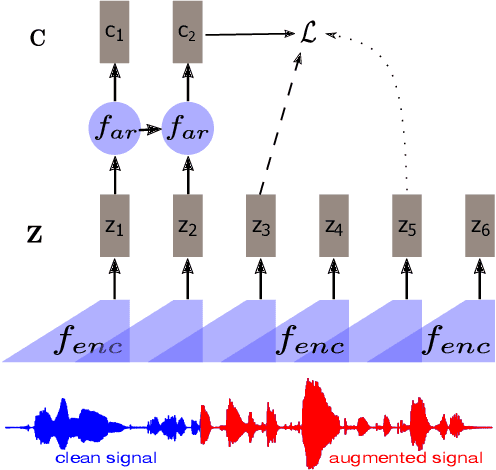
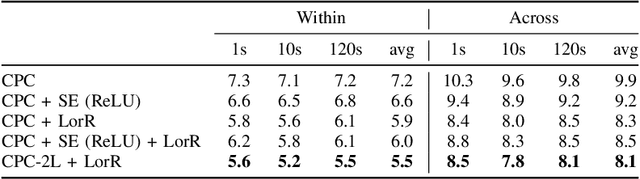
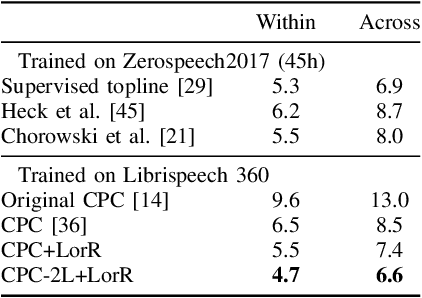
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models.
Weight Averaging: A Simple Yet Effective Method to Overcome Catastrophic Forgetting in Automatic Speech Recognition
Oct 27, 2022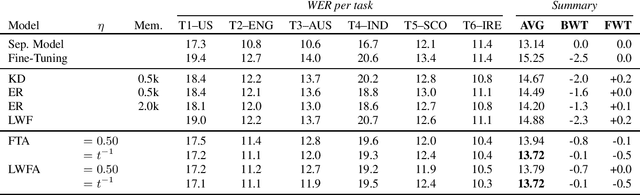
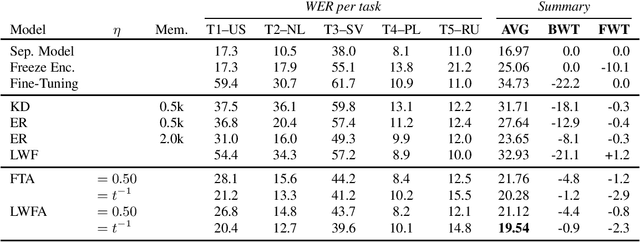
Adapting a trained Automatic Speech Recognition (ASR) model to new tasks results in catastrophic forgetting of old tasks, limiting the model's ability to learn continually and to be extended to new speakers, dialects, languages, etc. Focusing on End-to-End ASR, in this paper, we propose a simple yet effective method to overcome catastrophic forgetting: weight averaging. By simply taking the average of the previous and the adapted model, our method achieves high performance on both the old and new tasks. It can be further improved by introducing a knowledge distillation loss during the adaptation. We illustrate the effectiveness of our method on both monolingual and multilingual ASR. In both cases, our method strongly outperforms all baselines, even in its simplest form.
DWFormer: Dynamic Window transFormer for Speech Emotion Recognition
Mar 03, 2023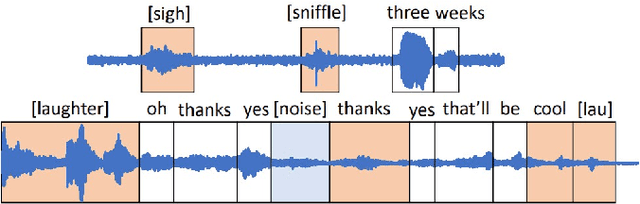
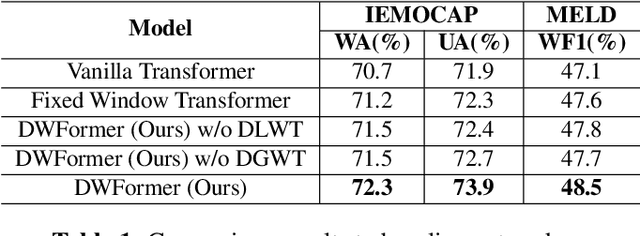
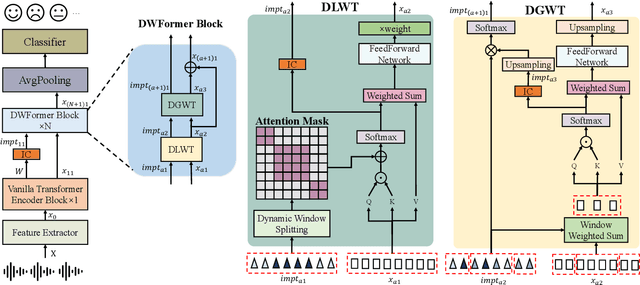
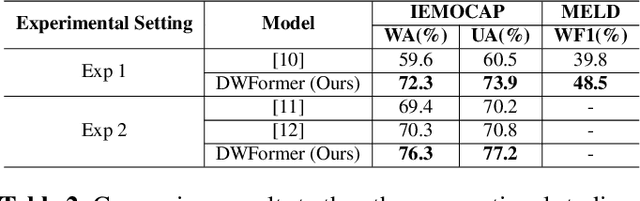
Speech emotion recognition is crucial to human-computer interaction. The temporal regions that represent different emotions scatter in different parts of the speech locally. Moreover, the temporal scales of important information may vary over a large range within and across speech segments. Although transformer-based models have made progress in this field, the existing models could not precisely locate important regions at different temporal scales. To address the issue, we propose Dynamic Window transFormer (DWFormer), a new architecture that leverages temporal importance by dynamically splitting samples into windows. Self-attention mechanism is applied within windows for capturing temporal important information locally in a fine-grained way. Cross-window information interaction is also taken into account for global communication. DWFormer is evaluated on both the IEMOCAP and the MELD datasets. Experimental results show that the proposed model achieves better performance than the previous state-of-the-art methods.