 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Language Model for End-to-end Speech Recognition
Jun 15, 2022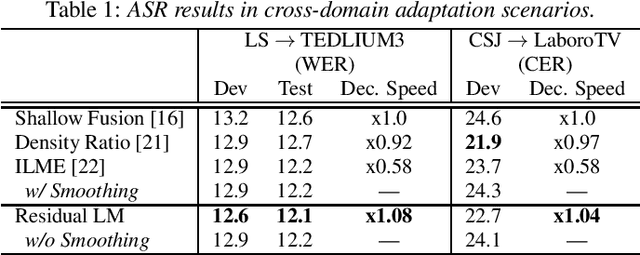
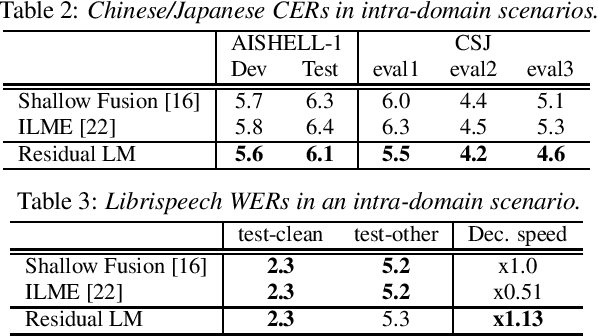
End-to-end automatic speech recognition suffers from adaptation to unknown target domain speech despite being trained with a large amount of paired audio--text data. Recent studies estimate a linguistic bias of the model as the internal language model (LM). To effectively adapt to the target domain, the internal LM is subtracted from the posterior during inference and fused with an external target-domain LM. However, this fusion complicates the inference and the estimation of the internal LM may not always be accurate. In this paper, we propose a simple external LM fusion method for domain adaptation, which considers the internal LM estimation in its training. We directly model the residual factor of the external and internal LMs, namely the residual LM. To stably train the residual LM, we propose smoothing the estimated internal LM and optimizing it with a combination of cross-entropy and mean-squared-error losses, which consider the statistical behaviors of the internal LM in the target domain data. We experimentally confirmed that the proposed residual LM performs better than the internal LM estimation in most of the cross-domain and intra-domain scenarios.
Joint Speech Recognition and Audio Captioning
Feb 03, 2022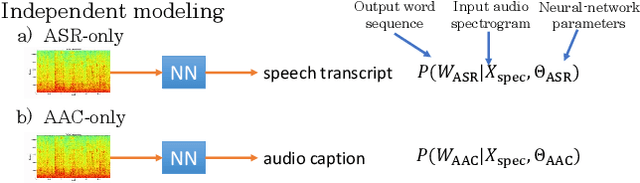
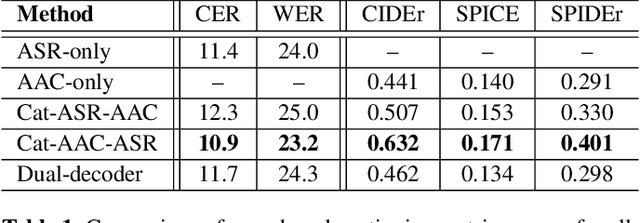
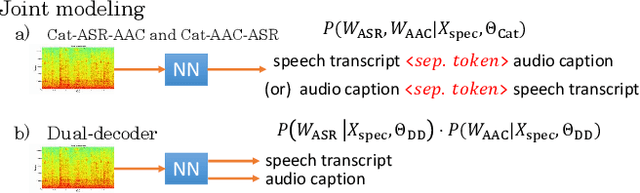
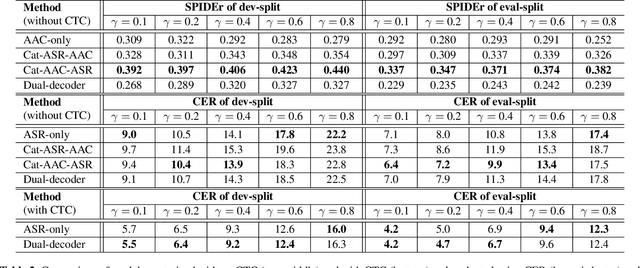
Speech samples recorded in both indoor and outdoor environments are often contaminated with secondary audio sources. Most end-to-end monaural speech recognition systems either remove these background sounds using speech enhancement or train noise-robust models. For better model interpretability and holistic understanding, we aim to bring together the growing field of automated audio captioning (AAC) and the thoroughly studied automatic speech recognition (ASR). The goal of AAC is to generate natural language descriptions of contents in audio samples. We propose several approaches for end-to-end joint modeling of ASR and AAC tasks and demonstrate their advantages over traditional approaches, which model these tasks independently. A major hurdle in evaluating our proposed approach is the lack of labeled audio datasets with both speech transcriptions and audio captions. Therefore we also create a multi-task dataset by mixing the clean speech Wall Street Journal corpus with multiple levels of background noises chosen from the AudioCaps dataset. We also perform extensive experimental evaluation and show improvements of our proposed methods as compared to existing state-of-the-art ASR and AAC methods.
Run-and-back stitch search: novel block synchronous decoding for streaming encoder-decoder ASR
Jan 25, 2022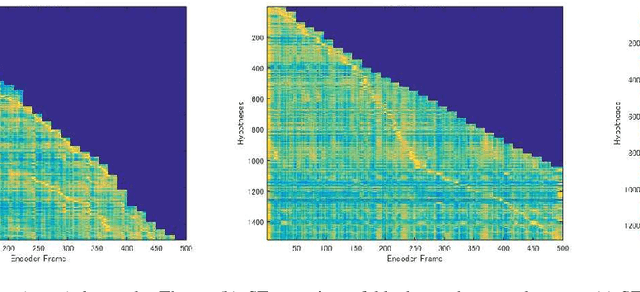
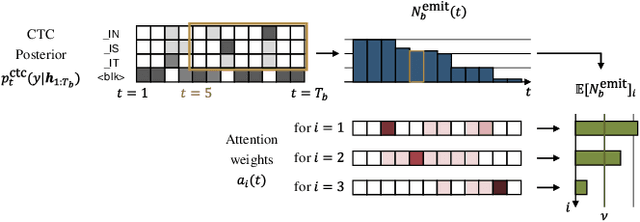
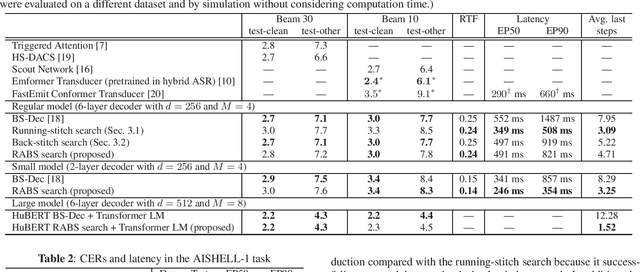
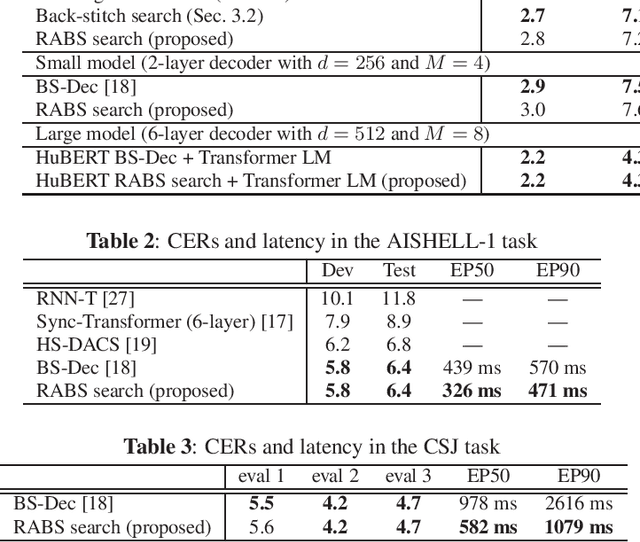
A streaming style inference of encoder-decoder automatic speech recognition (ASR) system is important for reducing latency, which is essential for interactive use cases. To this end, we propose a novel blockwise synchronous decoding algorithm with a hybrid approach that combines endpoint prediction and endpoint post-determination. In the endpoint prediction, we compute the expectation of the number of tokens that are yet to be emitted in the encoder features of the current blocks using the CTC posterior. Based on the expectation value, the decoder predicts the endpoint to realize continuous block synchronization, as a running stitch. Meanwhile, endpoint post-determination probabilistically detects backward jump of the source-target attention, which is caused by the misprediction of endpoints. Then it resumes decoding by discarding those hypotheses, as back stitch. We combine these methods into a hybrid approach, namely run-and-back stitch search, which reduces the computational cost and latency. Evaluations of various ASR tasks show the efficiency of our proposed decoding algorithm, which achieves a latency reduction, for instance in the Librispeech test set from 1487 ms to 821 ms at the 90th percentile, while maintaining a high recognition accuracy.
SAPPHIRE: Approaches for Enhanced Concept-to-Text Generation
Aug 15, 2021
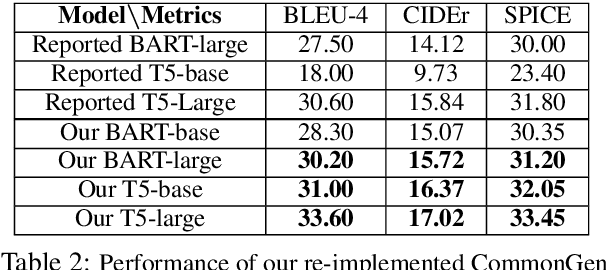
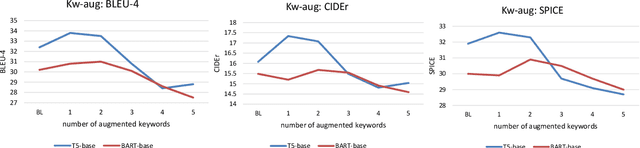
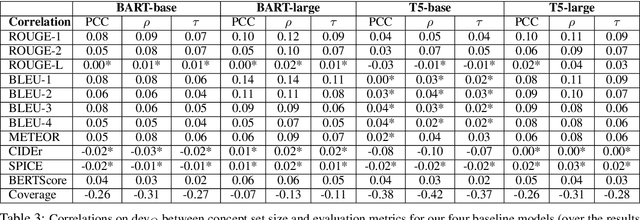
We motivate and propose a suite of simple but effective improvements for concept-to-text generation called SAPPHIRE: Set Augmentation and Post-hoc PHrase Infilling and REcombination. We demonstrate their effectiveness on generative commonsense reasoning, a.k.a. the CommonGen task, through experiments using both BART and T5 models. Through extensive automatic and human evaluation, we show that SAPPHIRE noticeably improves model performance. An in-depth qualitative analysis illustrates that SAPPHIRE effectively addresses many issues of the baseline model generations, including lack of commonsense, insufficient specificity, and poor fluency.
Data Augmentation Methods for End-to-end Speech Recognition on Distant-Talk Scenarios
Jun 07, 2021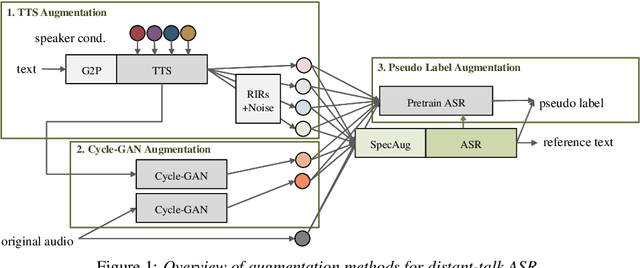
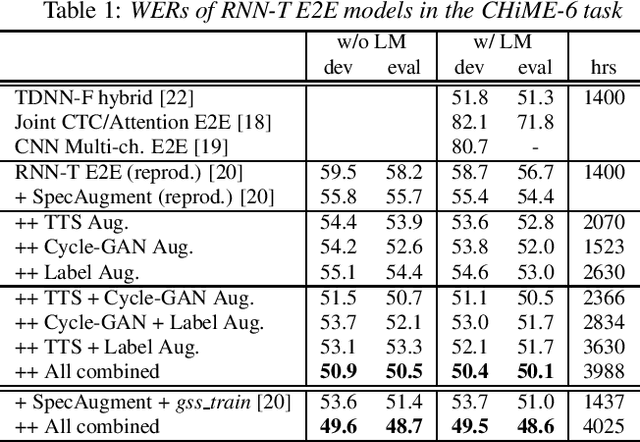
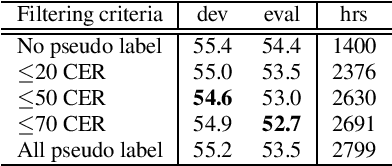
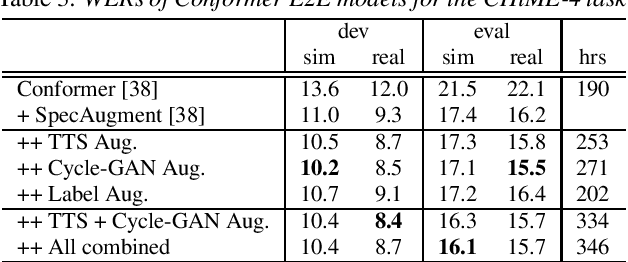
Although end-to-end automatic speech recognition (E2E ASR) has achieved great performance in tasks that have numerous paired data, it is still challenging to make E2E ASR robust against noisy and low-resource conditions. In this study, we investigated data augmentation methods for E2E ASR in distant-talk scenarios. E2E ASR models are trained on the series of CHiME challenge datasets, which are suitable tasks for studying robustness against noisy and spontaneous speech. We propose to use three augmentation methods and thier combinations: 1) data augmentation using text-to-speech (TTS) data, 2) cycle-consistent generative adversarial network (Cycle-GAN) augmentation trained to map two different audio characteristics, the one of clean speech and of noisy recordings, to match the testing condition, and 3) pseudo-label augmentation provided by the pretrained ASR module for smoothing label distributions. Experimental results using the CHiME-6/CHiME-4 datasets show that each augmentation method individually improves the accuracy on top of the conventional SpecAugment; further improvements are obtained by combining these approaches. We achieved 4.3\% word error rate (WER) reduction, which was more significant than that of the SpecAugment, when we combine all three augmentations for the CHiME-6 task.
Bayesian Non-Parametric Multi-Source Modelling Based Determined Blind Source Separation
Apr 08, 2019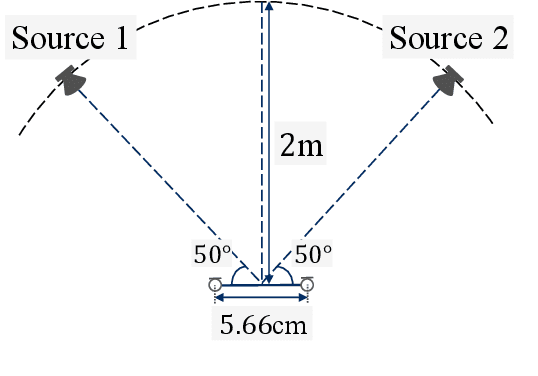
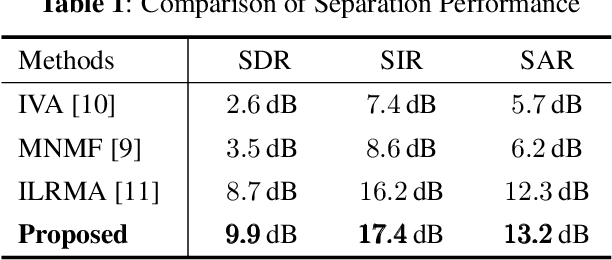
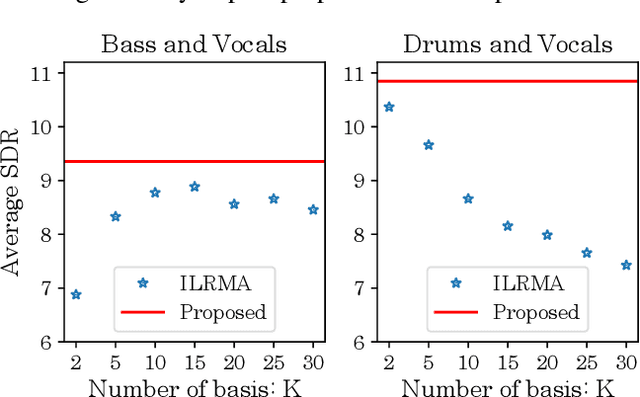
This paper proposes a determined blind source separation method using Bayesian non-parametric modelling of sources. Conventionally source signals are separated from a given set of mixture signals by modelling them using non-negative matrix factorization (NMF). However in NMF, a latent variable signifying model complexity must be appropriately specified to avoid over-fitting or under-fitting. As real-world sources can be of varying and unknown complexities, we propose a Bayesian non-parametric framework which is invariant to such latent variables. We show that our proposed method adapts to different source complexities, while conventional methods require parameter tuning for optimal separation.