 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting self-supervised models to multi-talker speech recognition using speaker embeddings
Nov 01, 2022Self-supervised learning (SSL) methods which learn representations of data without explicit supervision have gained popularity in speech-processing tasks, particularly for single-talker applications. However, these models often have degraded performance for multi-talker scenarios -- possibly due to the domain mismatch -- which severely limits their use for such applications. In this paper, we investigate the adaptation of upstream SSL models to the multi-talker automatic speech recognition (ASR) task under two conditions. First, when segmented utterances are given, we show that adding a target speaker extraction (TSE) module based on enrollment embeddings is complementary to mixture-aware pre-training. Second, for unsegmented mixtures, we propose a novel joint speaker modeling (JSM) approach, which aggregates information from all speakers in the mixture through their embeddings. With controlled experiments on Libri2Mix, we show that using speaker embeddings provides relative WER improvements of 9.1% and 42.1% over strong baselines for the segmented and unsegmented cases, respectively. We also demonstrate the effectiveness of our models for real conversational mixtures through experiments on the AMI dataset.
Updating Only Encoders Prevents Catastrophic Forgetting of End-to-End ASR Models
Jul 01, 2022
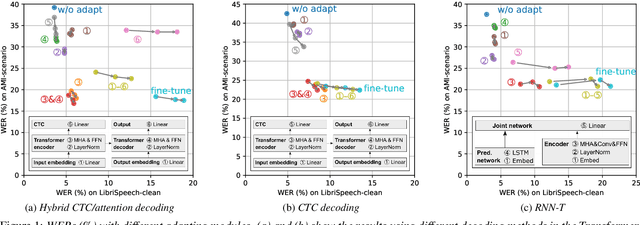
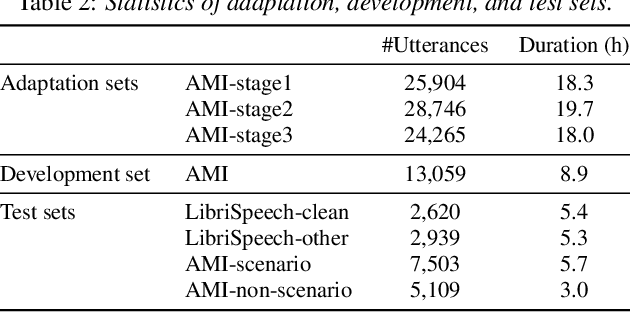
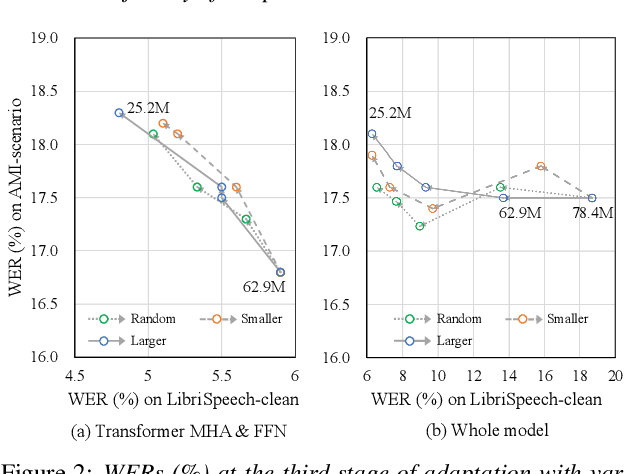
In this paper, we present an incremental domain adaptation technique to prevent catastrophic forgetting for an end-to-end automatic speech recognition (ASR) model. Conventional approaches require extra parameters of the same size as the model for optimization, and it is difficult to apply these approaches to end-to-end ASR models because they have a huge amount of parameters. To solve this problem, we first investigate which parts of end-to-end ASR models contribute to high accuracy in the target domain while preventing catastrophic forgetting. We conduct experiments on incremental domain adaptation from the LibriSpeech dataset to the AMI meeting corpus with two popular end-to-end ASR models and found that adapting only the linear layers of their encoders can prevent catastrophic forgetting. Then, on the basis of this finding, we develop an element-wise parameter selection focused on specific layers to further reduce the number of fine-tuning parameters. Experimental results show that our approach consistently prevents catastrophic forgetting compared to parameter selection from the whole model.
Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Jun 09, 2021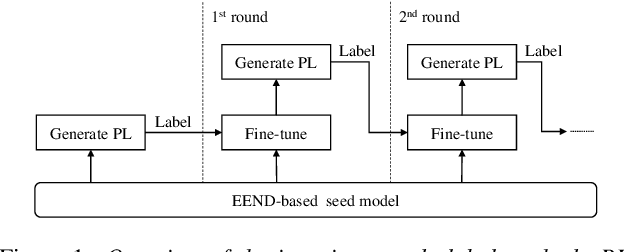
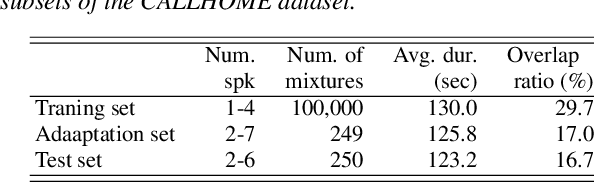
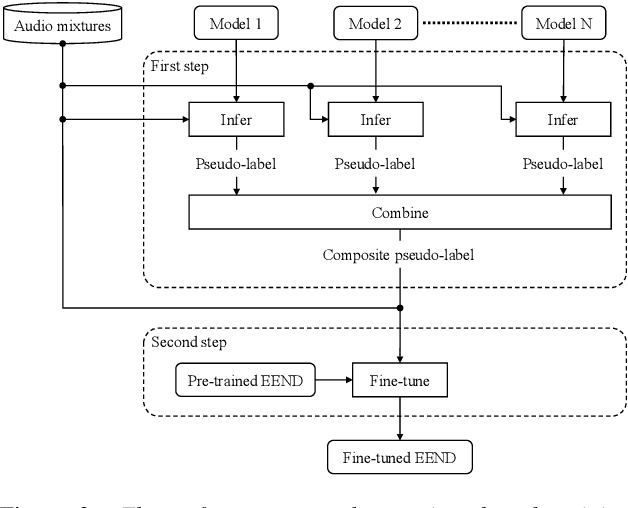
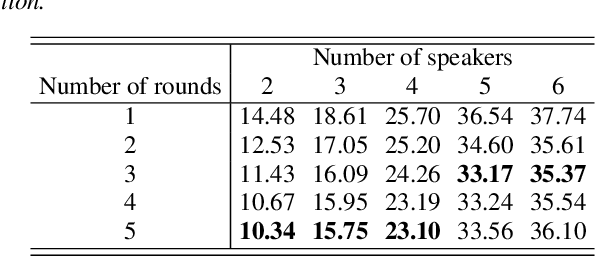
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.
End-to-End Speaker Diarization Conditioned on Speech Activity and Overlap Detection
Jun 08, 2021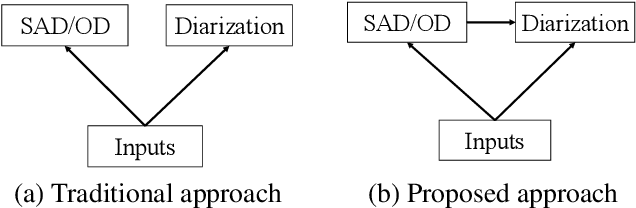
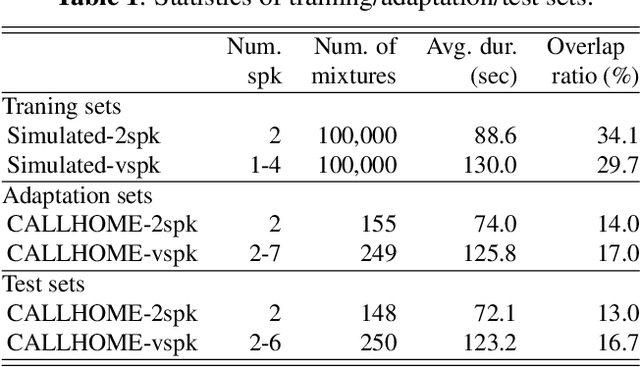
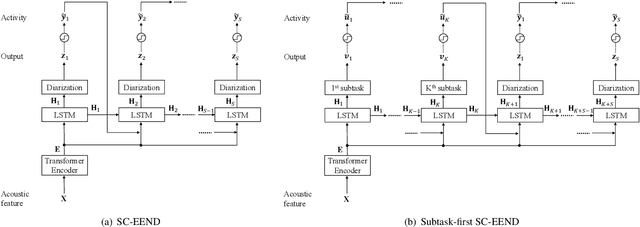
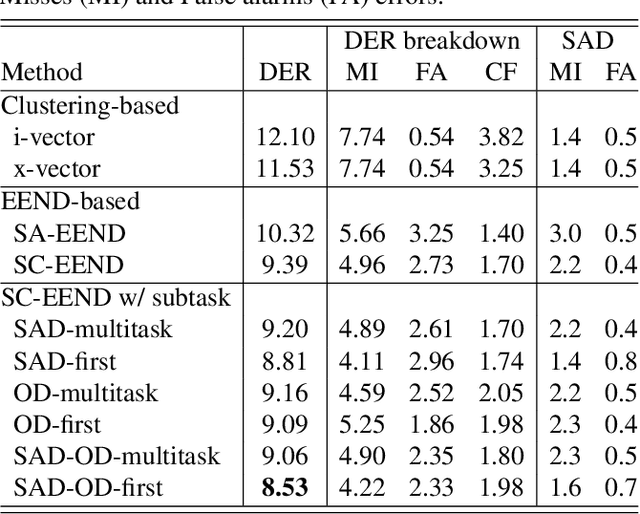
In this paper, we present a conditional multitask learning method for end-to-end neural speaker diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. In this paper, to further improve the performance of the EEND system, we propose a novel multitask learning framework that solves speaker diarization and a desired subtask while explicitly considering the task dependency. We optimize speaker diarization conditioned on speech activity and overlap detection that are subtasks of speaker diarization, based on the probabilistic chain rule. Experimental results show that our proposed method can leverage a subtask to effectively model speaker diarization, and outperforms conventional EEND systems in terms of diarization error rate.
* Accepted for SLT 2021