 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Hierarchical Photo-Scene Encoder for Album Storytelling
Feb 02, 2019

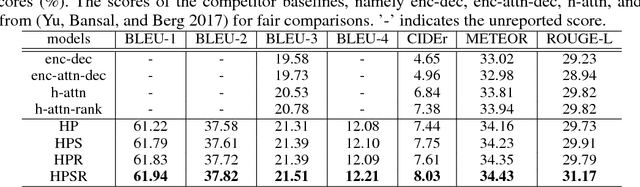
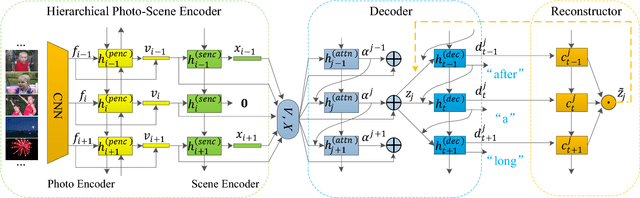
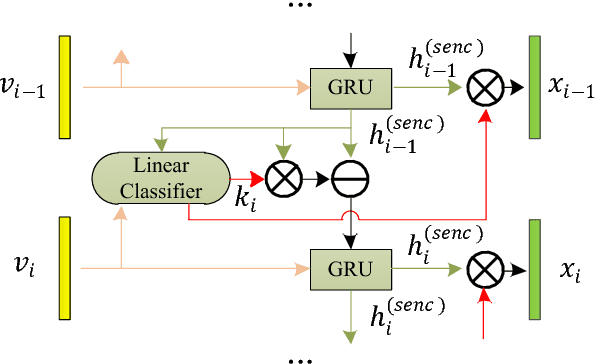
In this paper, we propose a novel model with a hierarchical photo-scene encoder and a reconstructor for the task of album storytelling. The photo-scene encoder contains two sub-encoders, namely the photo and scene encoders, which are stacked together and behave hierarchically to fully exploit the structure information of the photos within an album. Specifically, the photo encoder generates semantic representation for each photo while exploiting temporal relationships among them. The scene encoder, relying on the obtained photo representations, is responsible for detecting the scene changes and generating scene representations. Subsequently, the decoder dynamically and attentively summarizes the encoded photo and scene representations to generate a sequence of album representations, based on which a story consisting of multiple coherent sentences is generated. In order to fully extract the useful semantic information from an album, a reconstructor is employed to reproduce the summarized album representations based on the hidden states of the decoder. The proposed model can be trained in an end-to-end manner, which results in an improved performance over the state-of-the-arts on the public visual storytelling (VIST) dataset. Ablation studies further demonstrate the effectiveness of the proposed hierarchical photo-scene encoder and reconstructor.
Composition-Aided Face Photo-Sketch Synthesis
Jul 10, 2018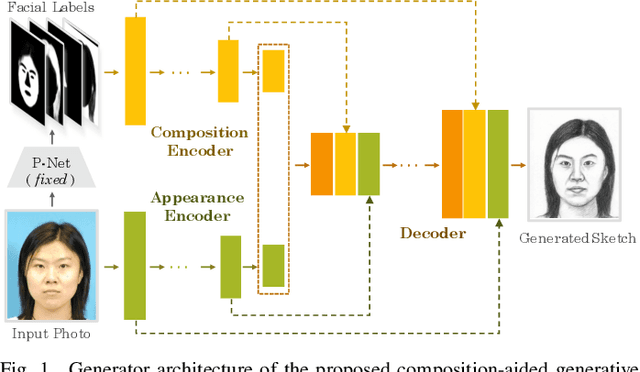
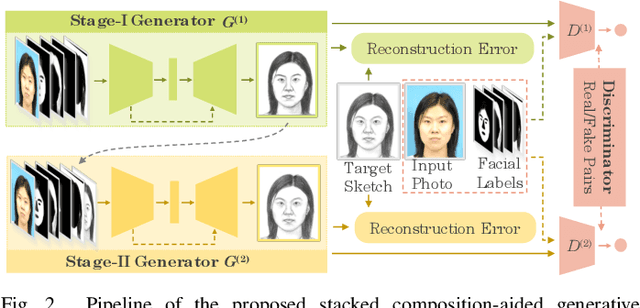

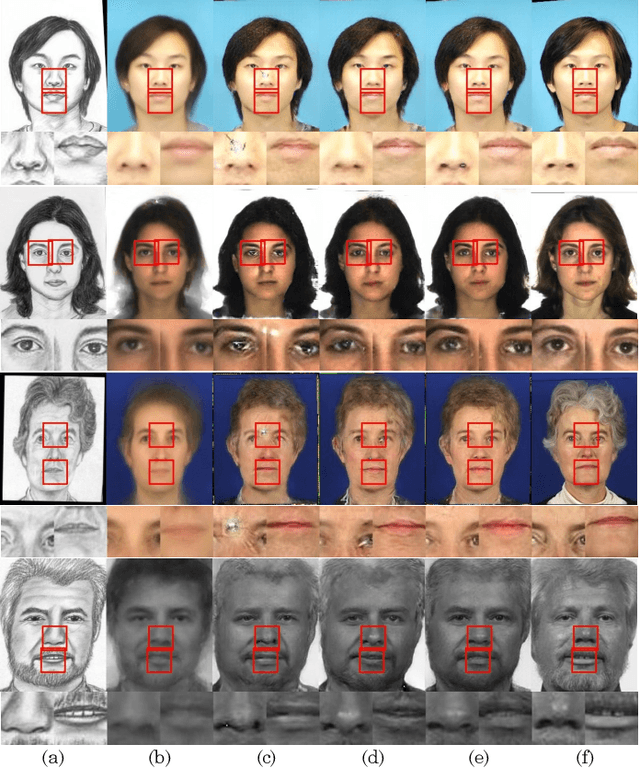
Face photo-sketch synthesis aims at generating a facial sketch (or photo) conditioned on a given photo (or sketch). It is of wide applications including digital entertainment and law enforcement. Despite the great progress achieved by existing methods, they mostly yield blurred effects and great deformation over various facial components. In order to tackle this challenge, we propose to use the facial composition information to help the synthesis of face sketch/photo. Specially, we propose a novel composition-aided generative adversarial network (CA-GAN) for face photo-sketch synthesis. First, we utilize paired inputs including a face photo/sketch and the corresponding pixel-wise face labels for generating the sketch/photo. Second, we propose an improved pixel loss, termed compositional loss, to focus training on hard-generated components and delicate facial structures. Moreover, we use stacked CA-GANs (SCA-GAN) to further rectify defects and add compelling details. Experimental results show that our method is capable of generating identity-preserving and visually comfortable sketches and photos over a wide range of challenging data. Besides, cross-dataset photo-sketch synthesis evaluations demonstrate that the proposed method is of considerable generalization ability.
AniPixel: Towards Animatable Pixel-Aligned Human Avatar
Feb 07, 2023
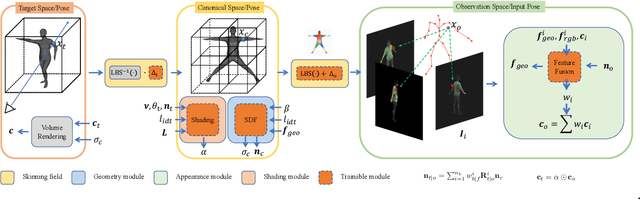
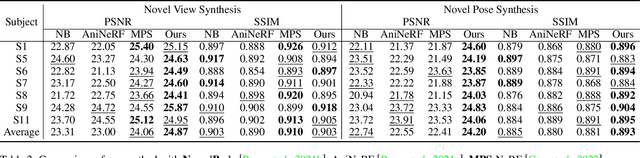
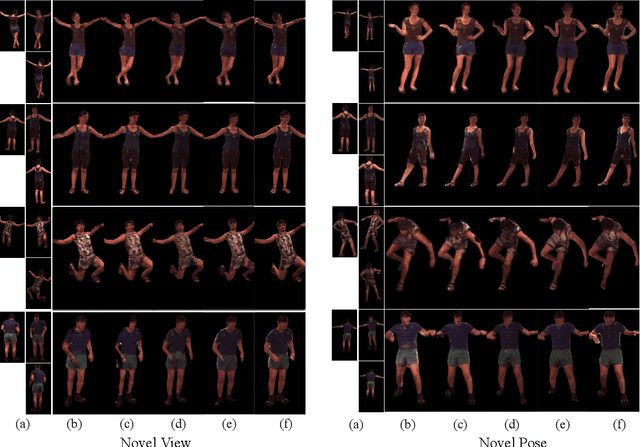
Neural radiance field using pixel-aligned features can render photo-realistic novel views. However, when pixel-aligned features are directly introduced to human avatar reconstruction, the rendering can only be conducted for still humans, rather than animatable avatars. In this paper, we propose AniPixel, a novel animatable and generalizable human avatar reconstruction method that leverages pixel-aligned features for body geometry prediction and RGB color blending. Technically, to align the canonical space with the target space and the observation space, we propose a bidirectional neural skinning field based on skeleton-driven deformation to establish the target-to-canonical and canonical-to-observation correspondences. Then, we disentangle the canonical body geometry into a normalized neutral-sized body and a subject-specific residual for better generalizability. As the geometry and appearance are closely related, we introduce pixel-aligned features to facilitate the body geometry prediction and detailed surface normals to reinforce the RGB color blending. Moreover, we devise a pose-dependent and view direction-related shading module to represent the local illumination variance. Experiments show that our AniPixel renders comparable novel views while delivering better novel pose animation results than state-of-the-art methods. The code will be released.
Legacy Photo Editing with Learned Noise Prior
Nov 24, 2020
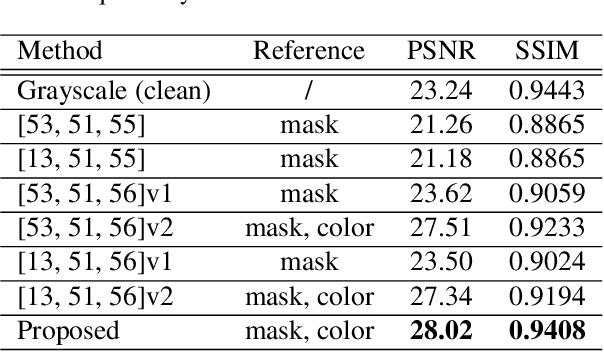

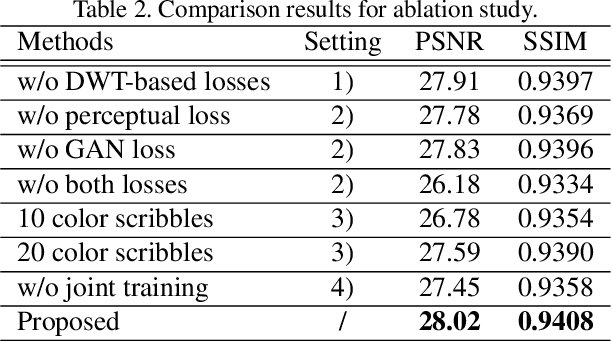
There are quite a number of photographs captured under undesirable conditions in the last century. Thus, they are often noisy, regionally incomplete, and grayscale formatted. Conventional approaches mainly focus on one point so that those restoration results are not perceptually sharp or clean enough. To solve these problems, we propose a noise prior learner NEGAN to simulate the noise distribution of real legacy photos using unpaired images. It mainly focuses on matching high-frequency parts of noisy images through discrete wavelet transform (DWT) since they include most of noise statistics. We also create a large legacy photo dataset for learning noise prior. Using learned noise prior, we can easily build valid training pairs by degrading clean images. Then, we propose an IEGAN framework performing image editing including joint denoising, inpainting and colorization based on the estimated noise prior. We evaluate the proposed system and compare it with state-of-the-art image enhancement methods. The experimental results demonstrate that it achieves the best perceptual quality. https://github.com/zhaoyuzhi/Legacy-Photo-Editing-with-Learned-Noise-Prior for the codes and the proposed LP dataset.
Facial De-occlusion Network for Virtual Telepresence Systems
Oct 23, 2022
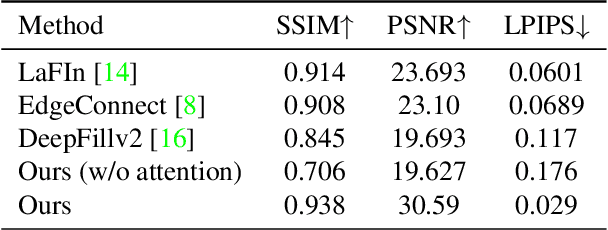
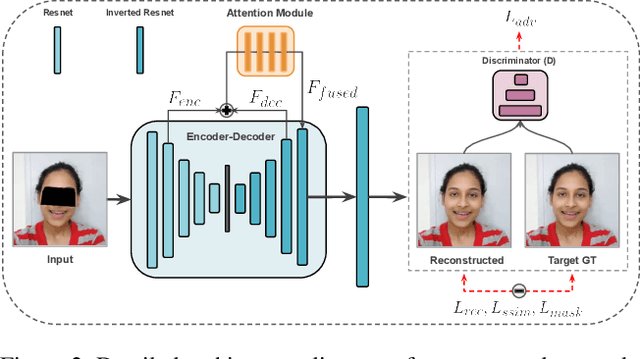
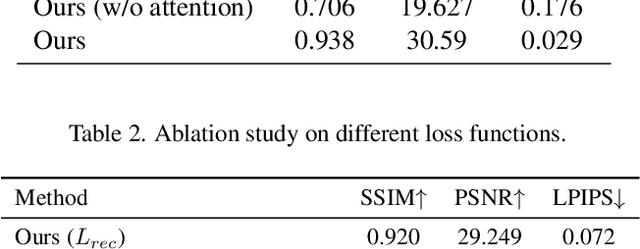
To see what is not in the image is one of the broader missions of computer vision. Technology to inpaint images has made significant progress with the coming of deep learning. This paper proposes a method to tackle occlusion specific to human faces. Virtual presence is a promising direction in communication and recreation for the future. However, Virtual Reality (VR) headsets occlude a significant portion of the face, hindering the photo-realistic appearance of the face in the virtual world. State-of-the-art image inpainting methods for de-occluding the eye region does not give usable results. To this end, we propose a working solution that gives usable results to tackle this problem enabling the use of the real-time photo-realistic de-occluded face of the user in VR settings.
Data-driven soiling detection in PV modules
Jan 30, 2023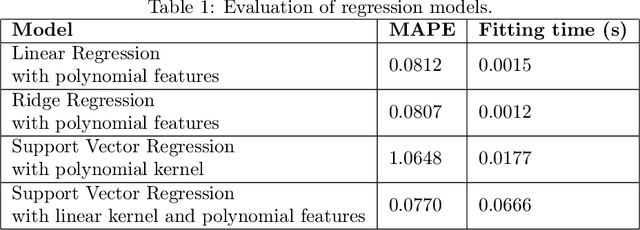
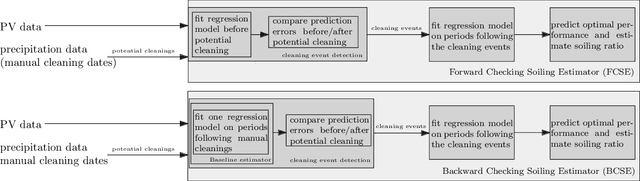
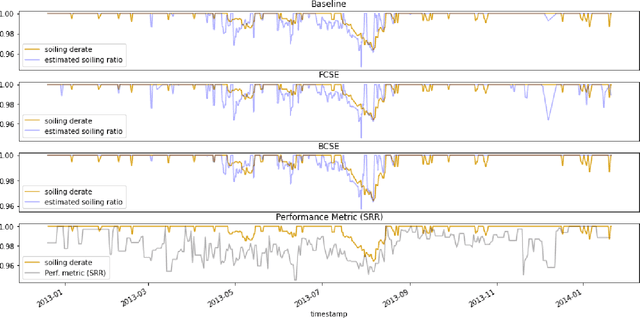
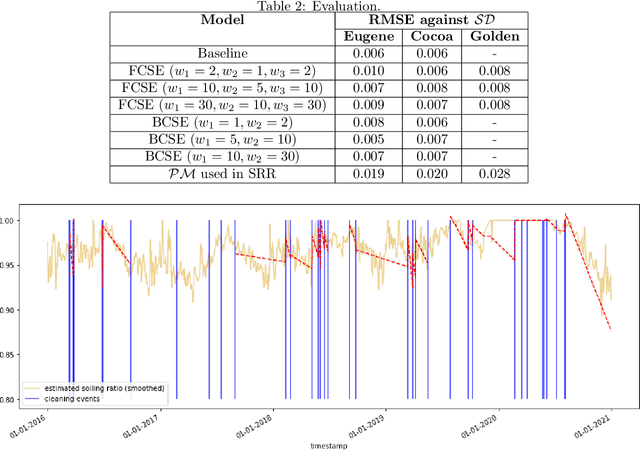
Soiling is the accumulation of dirt in solar panels which leads to a decreasing trend in solar energy yield and may be the cause of vast revenue losses. The effect of soiling can be reduced by washing the panels, which is, however, a procedure of non-negligible cost. Moreover, soiling monitoring systems are often unreliable or very costly. We study the problem of estimating the soiling ratio in photo-voltaic (PV) modules, i.e., the ratio of the real power output to the power output that would be produced if solar panels were clean. A key advantage of our algorithms is that they estimate soiling, without needing to train on labelled data, i.e., periods of explicitly monitoring the soiling in each park, and without relying on generic analytical formulas which do not take into account the peculiarities of each installation. We consider as input a time series comprising a minimum set of measurements, that are available to most PV park operators. Our experimental evaluation shows that we significantly outperform current state-of-the-art methods for estimating soiling ratio.
Towards Local Underexposed Photo Enhancement
Aug 17, 2022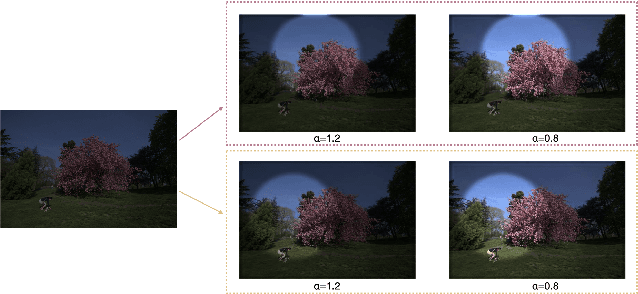
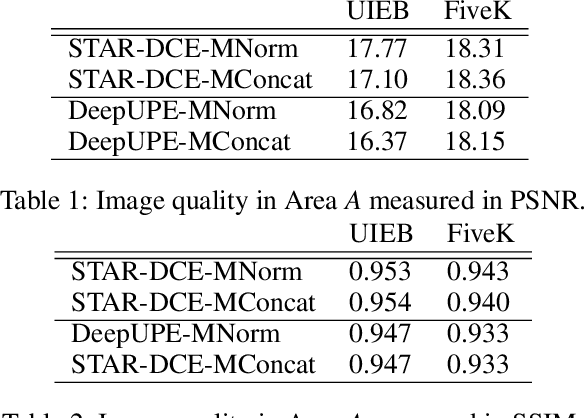
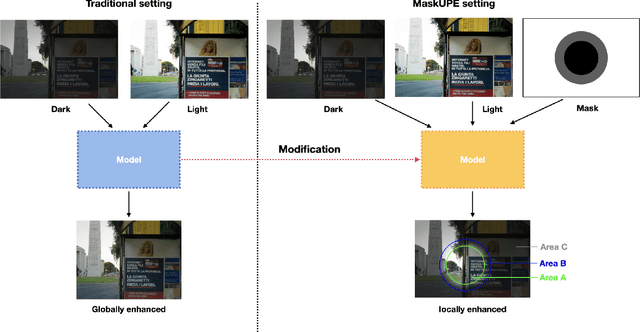
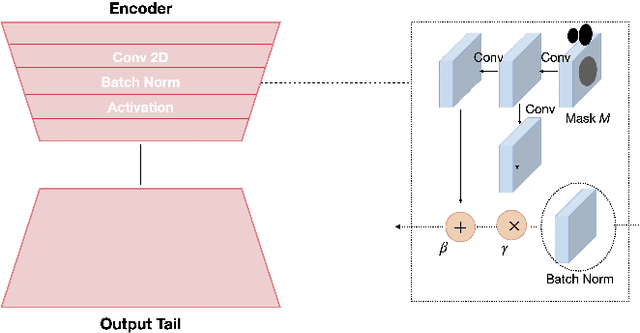
Inspired by the ability of deep generative models to generate highly realistic images, much recent work has made progress in enhancing underexposed images globally. However, the local image enhancement approach has not been explored, although they are requisite in the real-world scenario, e.g., fixing local underexposure. In this work, we define a new task setting for underexposed image enhancement where users are able to control which region to be enlightened with an input mask. As indicated by the mask, an image can be divided into three areas, including Masked Area A, Transition Area B, and Unmasked Area C. As a result, Area A should be enlightened to the desired lighting, and there shall be a smooth transition (Area B) from the enlightened area (Area A) to the unchanged region (Area C). To finish this task, we propose two methods: Concatenate the mask as additional channels (MConcat), Mask-based Normlization (MNorm). While MConcat simply append the mask channels to the input images, MNorm can dynamically enhance the spatial-varying pixels, guaranteeing the enhanced images are consistent with the requirement indicated by the input mask. Moreover, MConcat serves as a play-and-plug module, and can be incorporated with existing networks, which globally enhance images, to achieve the local enhancement. And the overall network can be trained with three kinds of loss functions in Area A, Area B, and Area C, which are unified for various model structures. We perform extensive experiments on public datasets with various parametric approaches for low-light enhancement, %the Convolutional-Neutral-Network-based model and Transformer-based model, demonstrating the effectiveness of our methods.
PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask and Group-Level Consistency
May 19, 2021



Different from general photo retouching tasks, portrait photo retouching (PPR), which aims to enhance the visual quality of a collection of flat-looking portrait photos, has its special and practical requirements such as human-region priority (HRP) and group-level consistency (GLC). HRP requires that more attention should be paid to human regions, while GLC requires that a group of portrait photos should be retouched to a consistent tone. Models trained on existing general photo retouching datasets, however, can hardly meet these requirements of PPR. To facilitate the research on this high-frequency task, we construct a large-scale PPR dataset, namely PPR10K, which is the first of its kind to our best knowledge. PPR10K contains $1, 681$ groups and $11, 161$ high-quality raw portrait photos in total. High-resolution segmentation masks of human regions are provided. Each raw photo is retouched by three experts, while they elaborately adjust each group of photos to have consistent tones. We define a set of objective measures to evaluate the performance of PPR and propose strategies to learn PPR models with good HRP and GLC performance. The constructed PPR10K dataset provides a good benchmark for studying automatic PPR methods, and experiments demonstrate that the proposed learning strategies are effective to improve the retouching performance. Datasets and codes are available: https://github.com/csjliang/PPR10K.
VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild
Nov 27, 2022
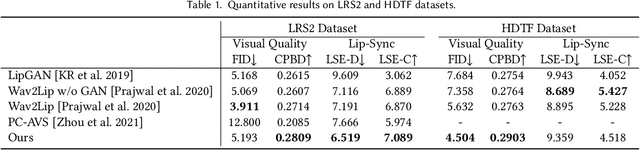
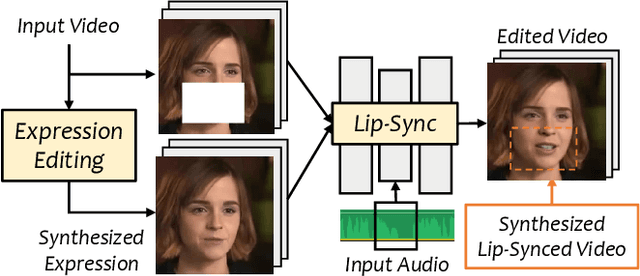
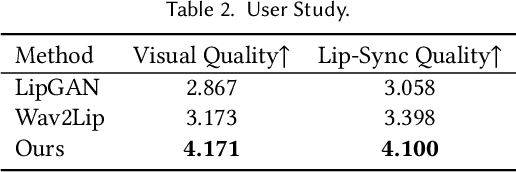
We present VideoReTalking, a new system to edit the faces of a real-world talking head video according to input audio, producing a high-quality and lip-syncing output video even with a different emotion. Our system disentangles this objective into three sequential tasks: (1) face video generation with a canonical expression; (2) audio-driven lip-sync; and (3) face enhancement for improving photo-realism. Given a talking-head video, we first modify the expression of each frame according to the same expression template using the expression editing network, resulting in a video with the canonical expression. This video, together with the given audio, is then fed into the lip-sync network to generate a lip-syncing video. Finally, we improve the photo-realism of the synthesized faces through an identity-aware face enhancement network and post-processing. We use learning-based approaches for all three steps and all our modules can be tackled in a sequential pipeline without any user intervention. Furthermore, our system is a generic approach that does not need to be retrained to a specific person. Evaluations on two widely-used datasets and in-the-wild examples demonstrate the superiority of our framework over other state-of-the-art methods in terms of lip-sync accuracy and visual quality.
RecolorNeRF: Layer Decomposed Radiance Field for Efficient Color Editing of 3D Scenes
Jan 19, 2023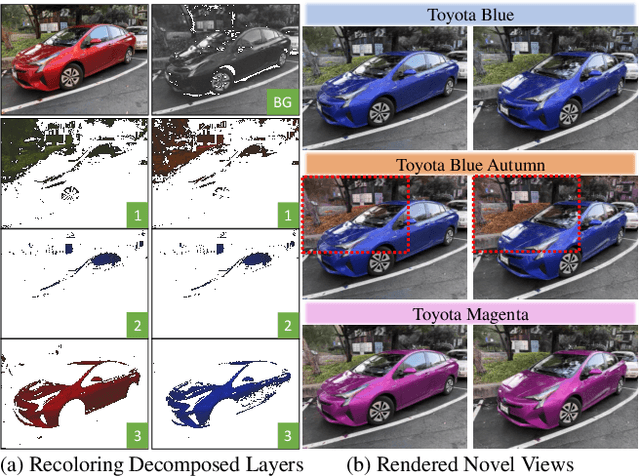
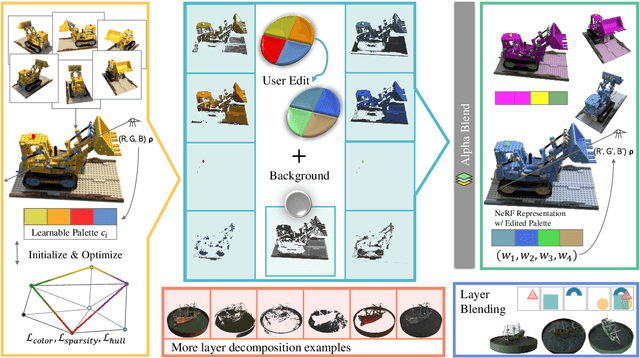
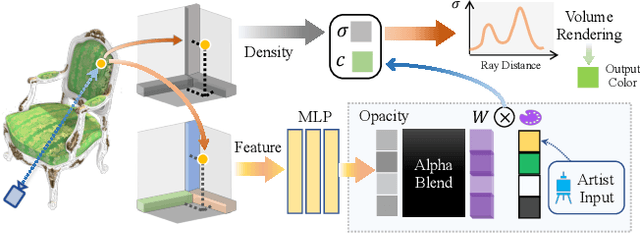
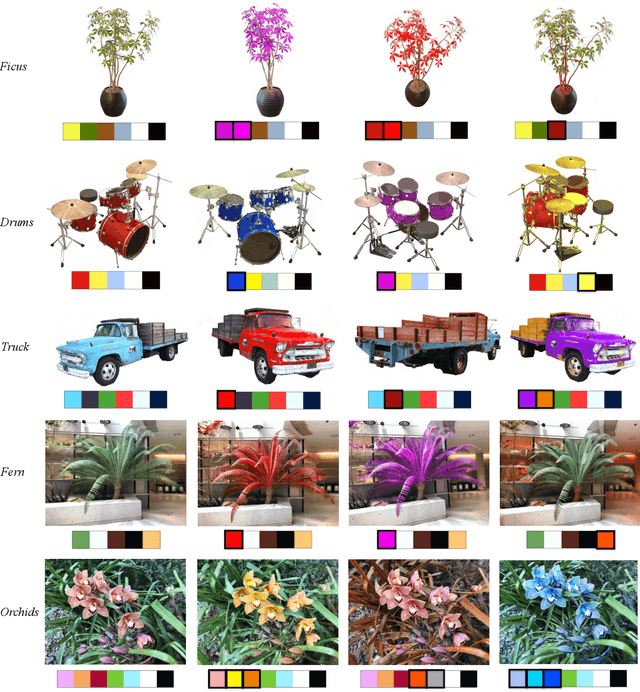
Radiance fields have gradually become a main representation of media. Although its appearance editing has been studied, how to achieve view-consistent recoloring in an efficient manner is still under explored. We present RecolorNeRF, a novel user-friendly color editing approach for the neural radiance field. Our key idea is to decompose the scene into a set of pure-colored layers, forming a palette. Thus, color manipulation can be conducted by altering the color components of the palette directly. To support efficient palette-based editing, the color of each layer needs to be as representative as possible. In the end, the problem is formulated as in an optimization formula, where the layers and their blending way are jointly optimized with the NeRF itself. Extensive experiments show that our jointly-optimized layer decomposition can be used against multiple backbones and produce photo-realistic recolored novel-view renderings. We demonstrate that RecolorNeRF outperforms baseline methods both quantitatively and qualitatively for color editing even in complex real-world scenes.