 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-PDM: Temporally Consistent Patch Diffusion Models for Infrared-to-Visible Video Translation
Aug 26, 2024



Infrared imaging offers resilience against changing lighting conditions by capturing object temperatures. Yet, in few scenarios, its lack of visual details compared to daytime visible images, poses a significant challenge for human and machine interpretation. This paper proposes a novel diffusion method, dubbed Temporally Consistent Patch Diffusion Models (TC-DPM), for infrared-to-visible video translation. Our method, extending the Patch Diffusion Model, consists of two key components. Firstly, we propose a semantic-guided denoising, leveraging the strong representations of foundational models. As such, our method faithfully preserves the semantic structure of generated visible images. Secondly, we propose a novel temporal blending module to guide the denoising trajectory, ensuring the temporal consistency between consecutive frames. Experiment shows that TC-PDM outperforms state-of-the-art methods by 35.3% in FVD for infrared-to-visible video translation and by 6.1% in AP50 for day-to-night object detection. Our code is publicly available at https://github.com/dzungdoan6/tc-pdm
Weakly Supervised Test-Time Domain Adaptation for Object Detection
Jul 08, 2024



Prior to deployment, an object detector is trained on a dataset compiled from a previous data collection campaign. However, the environment in which the object detector is deployed will invariably evolve, particularly in outdoor settings where changes in lighting, weather and seasons will significantly affect the appearance of the scene and target objects. It is almost impossible for all potential scenarios that the object detector may come across to be present in a finite training dataset. This necessitates continuous updates to the object detector to maintain satisfactory performance. Test-time domain adaptation techniques enable machine learning models to self-adapt based on the distributions of the testing data. However, existing methods mainly focus on fully automated adaptation, which makes sense for applications such as self-driving cars. Despite the prevalence of fully automated approaches, in some applications such as surveillance, there is usually a human operator overseeing the system's operation. We propose to involve the operator in test-time domain adaptation to raise the performance of object detection beyond what is achievable by fully automated adaptation. To reduce manual effort, the proposed method only requires the operator to provide weak labels, which are then used to guide the adaptation process. Furthermore, the proposed method can be performed in a streaming setting, where each online sample is observed only once. We show that the proposed method outperforms existing works, demonstrating a great benefit of human-in-the-loop test-time domain adaptation. Our code is publicly available at https://github.com/dzungdoan6/WSTTA
Assessing Domain Gap for Continual Domain Adaptation in Object Detection
Feb 21, 2023



To ensure reliable object detection in autonomous systems, the detector must be able to adapt to changes in appearance caused by environmental factors such as time of day, weather, and seasons. Continually adapting the detector to incorporate these changes is a promising solution, but it can be computationally costly. Our proposed approach is to selectively adapt the detector only when necessary, using new data that does not have the same distribution as the current training data. To this end, we investigate three popular metrics for domain gap evaluation and find that there is a correlation between the domain gap and detection accuracy. Therefore, we apply the domain gap as a criterion to decide when to adapt the detector. Our experiments show that our approach has the potential to improve the efficiency of the detector's operation in real-world scenarios, where environmental conditions change in a cyclical manner, without sacrificing the overall performance of the detector. Our code is publicly available at https://github.com/dadung/DGE-CDA.
Facial De-occlusion Network for Virtual Telepresence Systems
Oct 23, 2022To see what is not in the image is one of the broader missions of computer vision. Technology to inpaint images has made significant progress with the coming of deep learning. This paper proposes a method to tackle occlusion specific to human faces. Virtual presence is a promising direction in communication and recreation for the future. However, Virtual Reality (VR) headsets occlude a significant portion of the face, hindering the photo-realistic appearance of the face in the virtual world. State-of-the-art image inpainting methods for de-occluding the eye region does not give usable results. To this end, we propose a working solution that gives usable results to tackle this problem enabling the use of the real-time photo-realistic de-occluded face of the user in VR settings.
Attention based Occlusion Removal for Hybrid Telepresence Systems
Dec 02, 2021
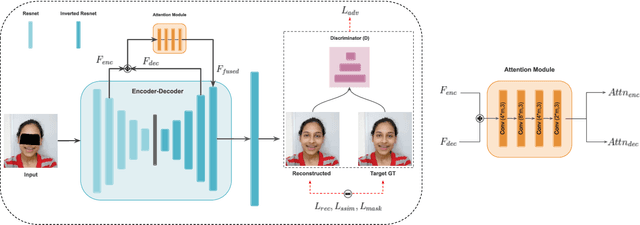


Traditionally, video conferencing is a widely adopted solution for telecommunication, but a lack of immersiveness comes inherently due to the 2D nature of facial representation. The integration of Virtual Reality (VR) in a communication/telepresence system through Head Mounted Displays (HMDs) promises to provide users a much better immersive experience. However, HMDs cause hindrance by blocking the facial appearance and expressions of the user. To overcome these issues, we propose a novel attention-enabled encoder-decoder architecture for HMD de-occlusion. We also propose to train our person-specific model using short videos (1-2 minutes) of the user, captured in varying appearances, and demonstrated generalization to unseen poses and appearances of the user. We report superior qualitative and quantitative results over state-of-the-art methods. We also present applications of this approach to hybrid video teleconferencing using existing animation and 3D face reconstruction pipelines.