 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Neural Hair Rendering
Apr 28, 2020
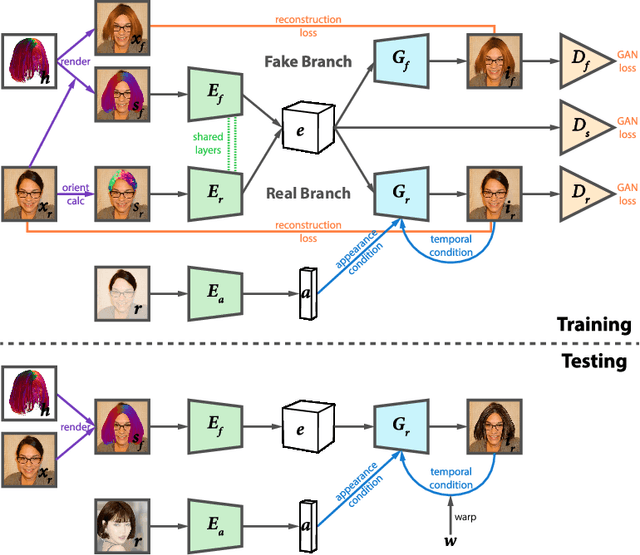
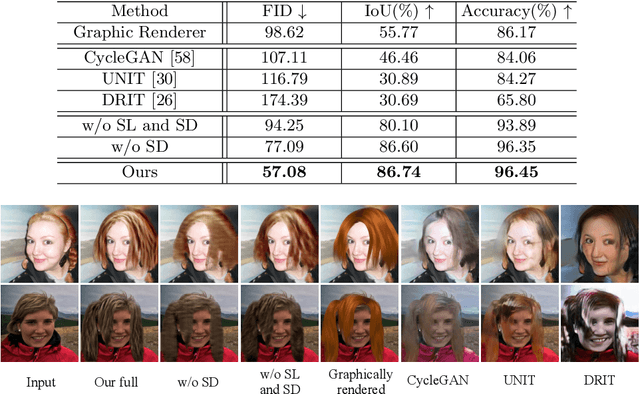


In this paper, we propose a generic neural-based hair rendering pipeline that can synthesize photo-realistic images from virtual 3D hair models. Unlike existing supervised translation methods that require model-level similarity to preserve consistent structure representation for both real images and fake renderings, our method adopts an unsupervised solution to work on arbitrary hair models. The key component of our method is a shared latent space to encode appearance-invariant structure information of both domains, which generates realistic renderings conditioned by extra appearance inputs. This is achieved by domain-specific pre-disentangled structure representation, partially shared domain encoder layers, and a structure discriminator. We also propose a simple yet effective temporal conditioning method to enforce consistency for video sequence generation. We demonstrate the superiority of our method by testing it on large amount of portraits, and comparing with alternative baselines and state-of-the-art unsupervised image translation methods.
Neural Reflectance Fields for Appearance Acquisition
Aug 16, 2020
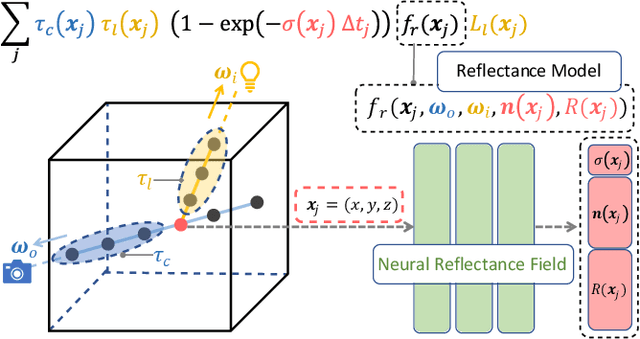
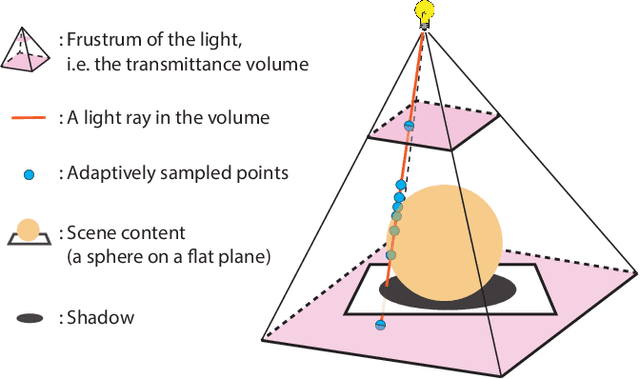
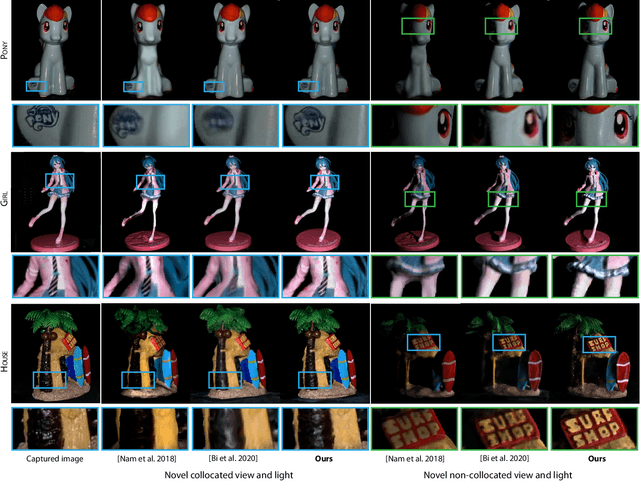
We present Neural Reflectance Fields, a novel deep scene representation that encodes volume density, normal and reflectance properties at any 3D point in a scene using a fully-connected neural network. We combine this representation with a physically-based differentiable ray marching framework that can render images from a neural reflectance field under any viewpoint and light. We demonstrate that neural reflectance fields can be estimated from images captured with a simple collocated camera-light setup, and accurately model the appearance of real-world scenes with complex geometry and reflectance. Once estimated, they can be used to render photo-realistic images under novel viewpoint and (non-collocated) lighting conditions and accurately reproduce challenging effects like specularities, shadows and occlusions. This allows us to perform high-quality view synthesis and relighting that is significantly better than previous methods. We also demonstrate that we can compose the estimated neural reflectance field of a real scene with traditional scene models and render them using standard Monte Carlo rendering engines. Our work thus enables a complete pipeline from high-quality and practical appearance acquisition to 3D scene composition and rendering.
HoughNet: Integrating near and long-range evidence for bottom-up object detection
Jul 05, 2020
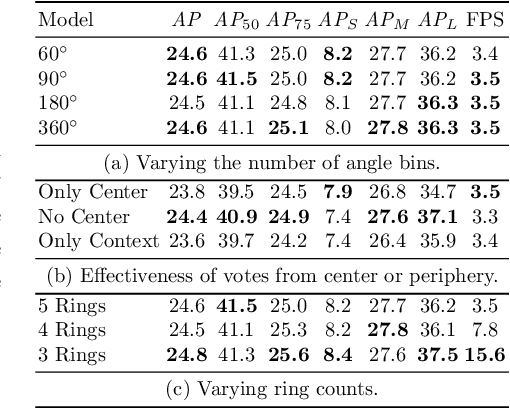
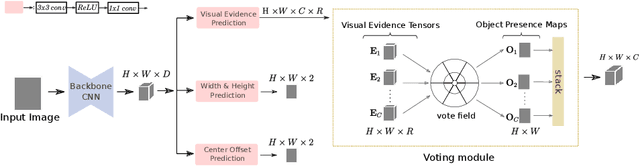
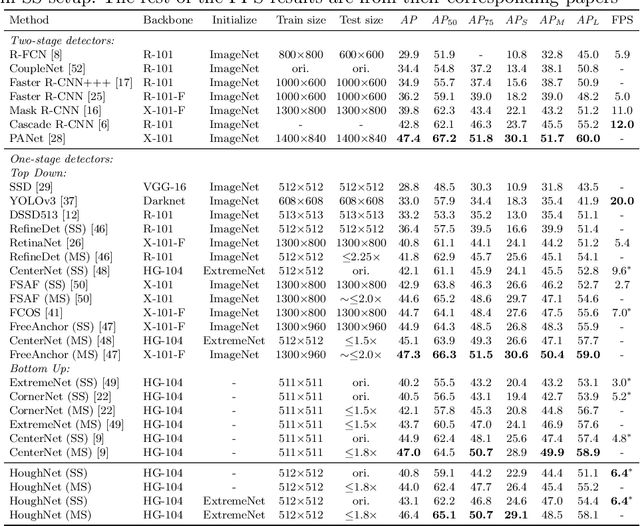
This paper presents HoughNet, a one-stage, anchor-free, voting-based, bottom-up object detection method. Inspired by the Generalized Hough Transform, HoughNet determines the presence of an object at a certain location by the sum of the votes cast on that location. Votes are collected from both near and long-distance locations based on a log-polar vote field. Thanks to this voting mechanism, HoughNet is able to integrate both near and long-range, class-conditional evidence for visual recognition, thereby generalizing and enhancing current object detection methodology, which typically relies on only local evidence. On the COCO dataset, HoughNet achieves 46.4 AP (and 65.1 AP_50), performing on par with the state-of-the-art in bottom-up object detection and outperforming most major one-stage and two-stage methods. We further validate the effectiveness of our proposal in another task, namely, "labels to photo" image generation by integrating the voting module of HoughNet to two different GAN models and showing that the accuracy is significantly improved in both cases. Code is available at: https://github.com/nerminsamet/houghnet
Upgrading the Newsroom: An Automated Image Selection System for News Articles
Apr 23, 2020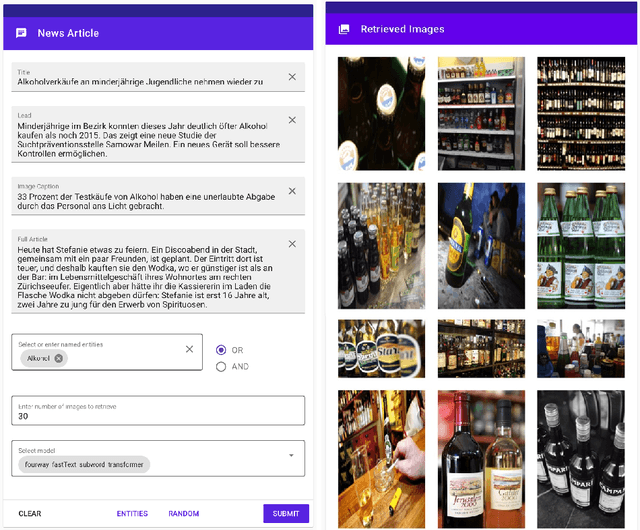
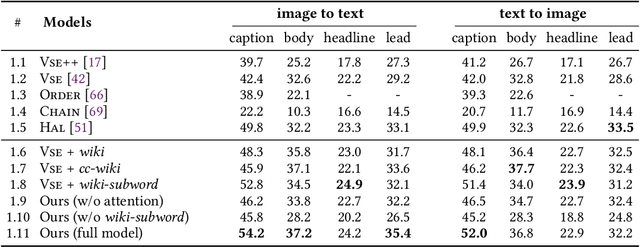
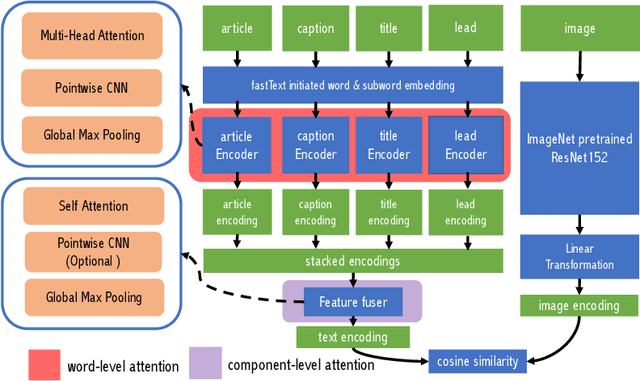
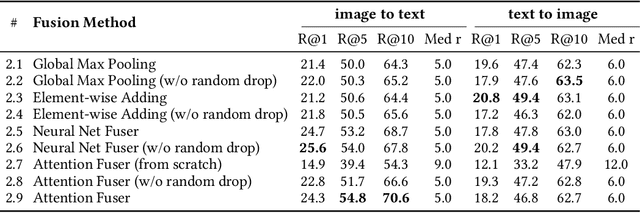
We propose an automated image selection system to assist photo editors in selecting suitable images for news articles. The system fuses multiple textual sources extracted from news articles and accepts multilingual inputs. It is equipped with char-level word embeddings to help both modeling morphologically rich languages, e.g. German, and transferring knowledge across nearby languages. The text encoder adopts a hierarchical self-attention mechanism to attend more to both keywords within a piece of text and informative components of a news article. We extensively experiment with our system on a large-scale text-image database containing multimodal multilingual news articles collected from Swiss local news media websites. The system is compared with multiple baselines with ablation studies and is shown to beat existing text-image retrieval methods in a weakly-supervised learning setting. Besides, we also offer insights on the advantage of using multiple textual sources and multilingual data.
Learning Large Euclidean Margin for Sketch-based Image Retrieval
Dec 11, 2018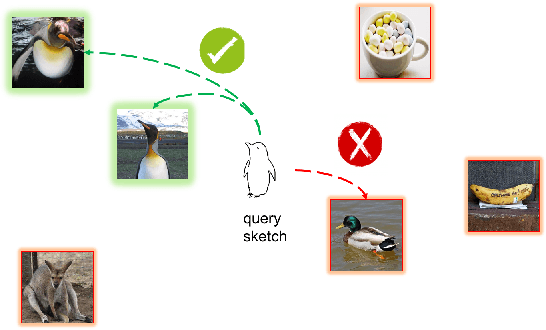
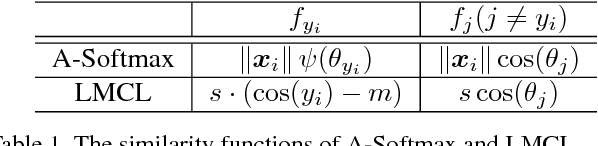
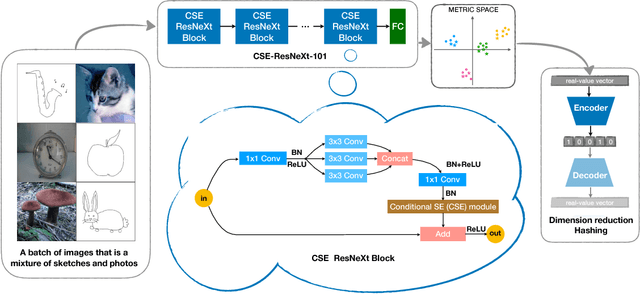
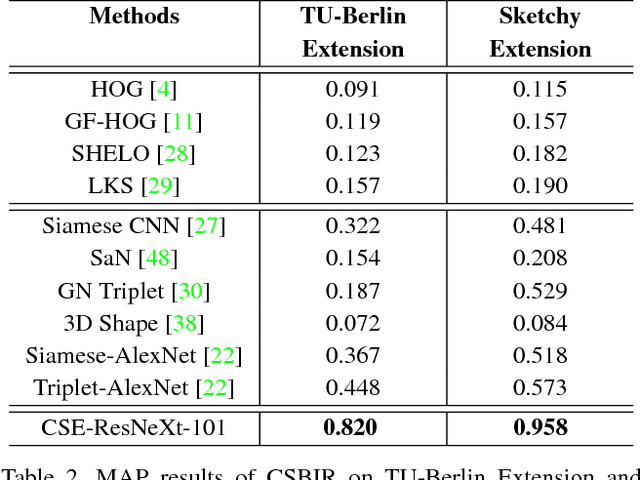
This paper addresses the problem of Sketch-Based Image Retrieval (SBIR), for which bridge the gap between the data representations of sketch images and photo images is considered as the key. Previous works mostly focus on learning a feature space to minimize intra-class distances for both sketches and photos. In contrast, we propose a novel loss function, named Euclidean Margin Softmax (EMS), that not only minimizes intra-class distances but also maximizes inter-class distances simultaneously. It enables us to learn a feature space with high discriminability, leading to highly accurate retrieval. In addition, this loss function is applied to a conditional network architecture, which could incorporate the prior knowledge of whether a sample is a sketch or a photo. We show that the conditional information can be conveniently incorporated to the recently proposed Squeeze and Excitation (SE) module, lead to a conditional SE (CSE) module. Extensive experiments are conducted on two widely used SBIR benchmark datasets. Our approach, although being very simple, achieved new state-of-the-art on both datasets, surpassing existing methods by a large margin.
Categorical Mixture Models on VGGNet activations
Mar 06, 2018

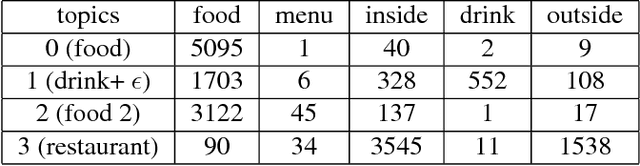

In this project, I use unsupervised learning techniques in order to cluster a set of yelp restaurant photos under meaningful topics. In order to do this, I extract layer activations from a pre-trained implementation of the popular VGGNet convolutional neural network. First, I explore using LDA with the activations of convolutional layers as features. Secondly, I explore using the object-recognition powers of VGGNet trained on ImageNet in order to extract meaningful objects from the photos, and then perform LDA to group the photos under topic-archetypes. I find that this second approach finds meaningful archetypes, which match the human intuition for photo topics such as restaurant, food, and drinks. Furthermore, these clusters align well and distinctly with the actual yelp photo labels.
S2IGAN: Speech-to-Image Generation via Adversarial Learning
May 14, 2020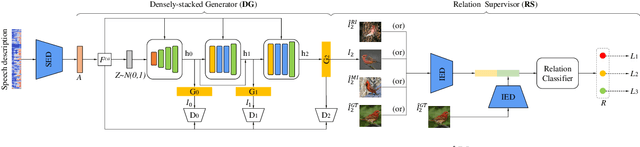
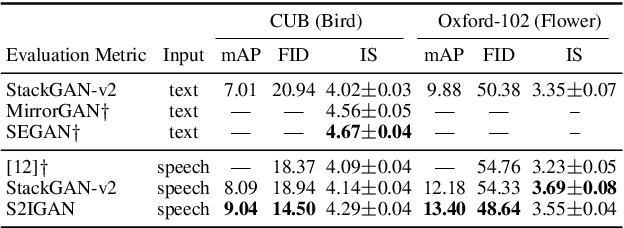


An estimated half of the world's languages do not have a written form, making it impossible for these languages to benefit from any existing text-based technologies. In this paper, a speech-to-image generation (S2IG) framework is proposed which translates speech descriptions to photo-realistic images without using any text information, thus allowing unwritten languages to potentially benefit from this technology. The proposed S2IG framework, named S2IGAN, consists of a speech embedding network (SEN) and a relation-supervised densely-stacked generative model (RDG). SEN learns the speech embedding with the supervision of the corresponding visual information. Conditioned on the speech embedding produced by SEN, the proposed RDG synthesizes images that are semantically consistent with the corresponding speech descriptions. Extensive experiments on two public benchmark datasets CUB and Oxford-102 demonstrate the effectiveness of the proposed S2IGAN on synthesizing high-quality and semantically-consistent images from the speech signal, yielding a good performance and a solid baseline for the S2IG task.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 24, 2021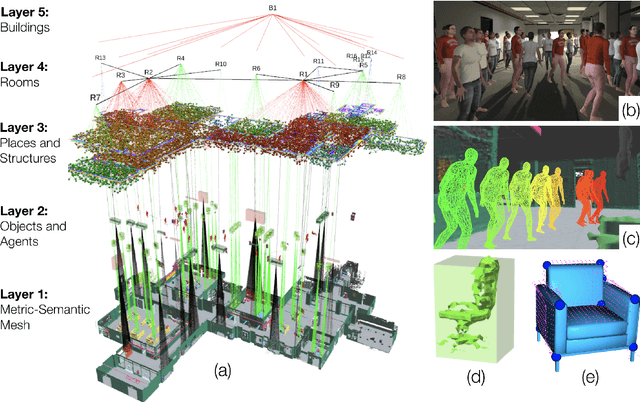
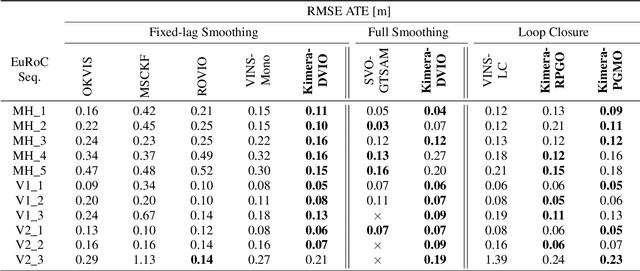
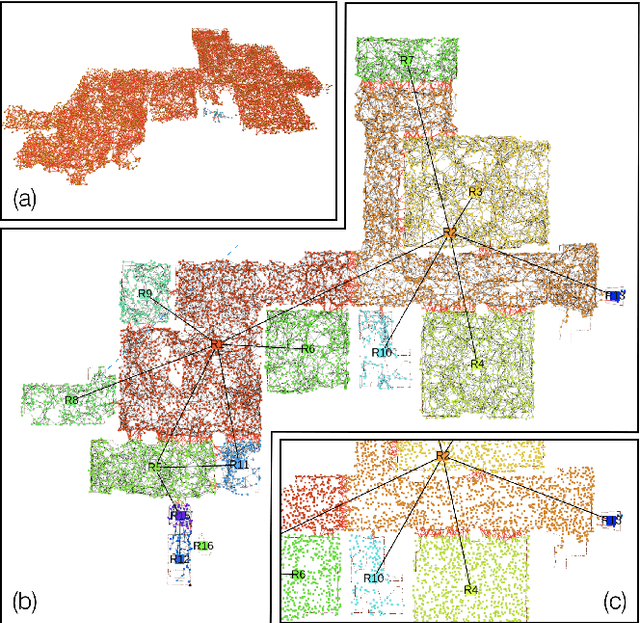
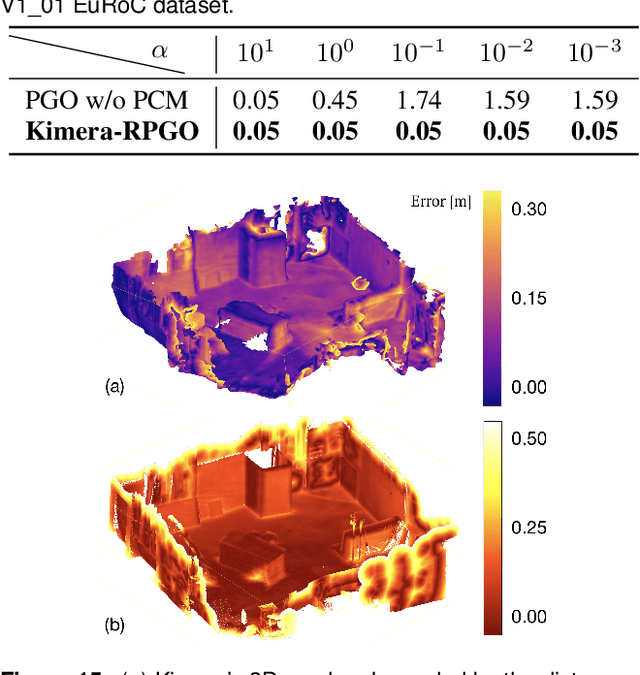
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.
Fighting Fake News: Image Splice Detection via Learned Self-Consistency
Sep 05, 2018
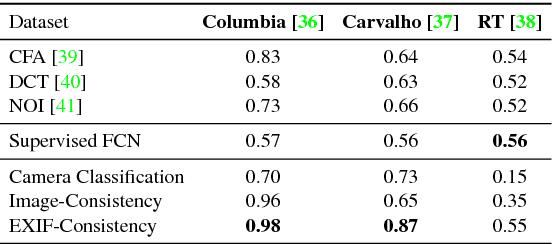

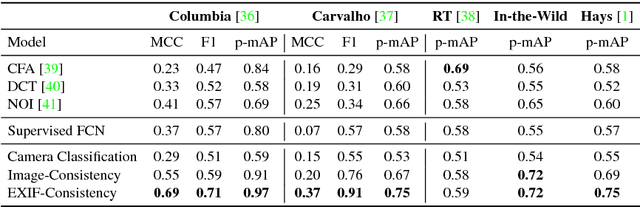
Advances in photo editing and manipulation tools have made it significantly easier to create fake imagery. Learning to detect such manipulations, however, remains a challenging problem due to the lack of sufficient amounts of manipulated training data. In this paper, we propose a learning algorithm for detecting visual image manipulations that is trained only using a large dataset of real photographs. The algorithm uses the automatically recorded photo EXIF metadata as supervisory signal for training a model to determine whether an image is self-consistent -- that is, whether its content could have been produced by a single imaging pipeline. We apply this self-consistency model to the task of detecting and localizing image splices. The proposed method obtains state-of-the-art performance on several image forensics benchmarks, despite never seeing any manipulated images at training. That said, it is merely a step in the long quest for a truly general purpose visual forensics tool.