 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
PARK: Parkinson's Analysis with Remote Kinetic-tasks
Nov 21, 2023
We present a web-based framework to screen for Parkinson's disease (PD) by allowing users to perform neurological tests in their homes. Our web framework guides the users to complete three tasks involving speech, facial expression, and finger movements. The task videos are analyzed to classify whether the users show signs of PD. We present the results in an easy-to-understand manner, along with personalized resources to further access to treatment and care. Our framework is accessible by any major web browser, improving global access to neurological care.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 04, 2023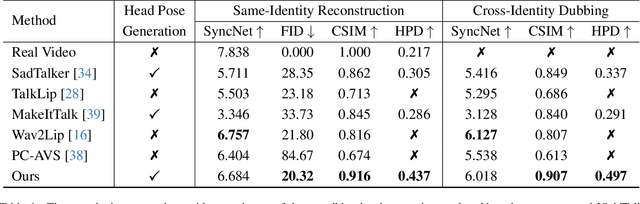
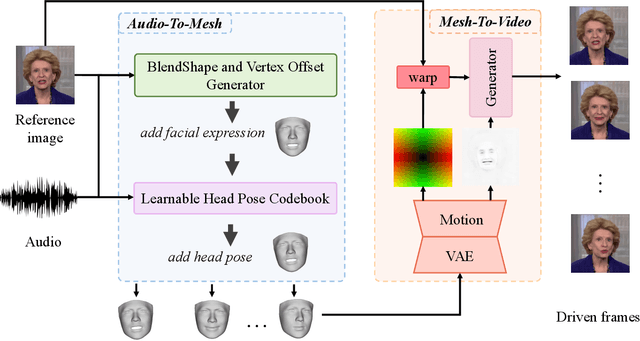
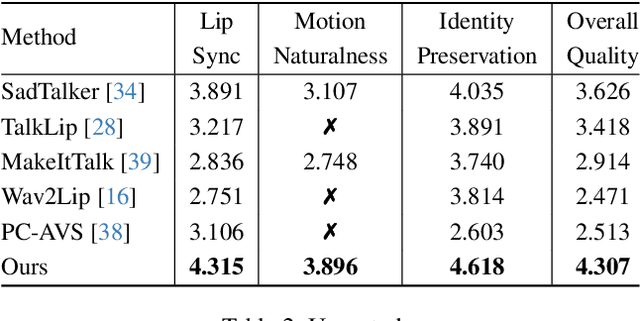
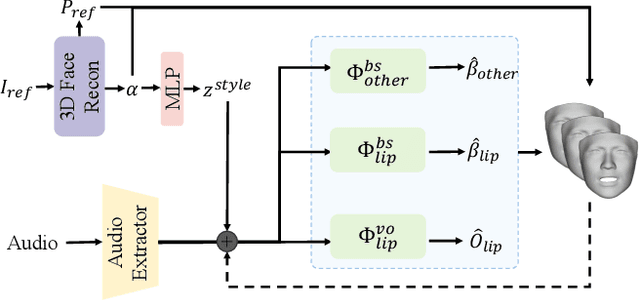
Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
Synthetic Speaking Children -- Why We Need Them and How to Make Them
Nov 08, 2023Contemporary Human Computer Interaction (HCI) research relies primarily on neural network models for machine vision and speech understanding of a system user. Such models require extensively annotated training datasets for optimal performance and when building interfaces for users from a vulnerable population such as young children, GDPR introduces significant complexities in data collection, management, and processing. Motivated by the training needs of an Edge AI smart toy platform this research explores the latest advances in generative neural technologies and provides a working proof of concept of a controllable data generation pipeline for speech driven facial training data at scale. In this context, we demonstrate how StyleGAN2 can be finetuned to create a gender balanced dataset of children's faces. This dataset includes a variety of controllable factors such as facial expressions, age variations, facial poses, and even speech-driven animations with realistic lip synchronization. By combining generative text to speech models for child voice synthesis and a 3D landmark based talking heads pipeline, we can generate highly realistic, entirely synthetic, talking child video clips. These video clips can provide valuable, and controllable, synthetic training data for neural network models, bridging the gap when real data is scarce or restricted due to privacy regulations.
Identity-preserving Editing of Multiple Facial Attributes by Learning Global Edit Directions and Local Adjustments
Sep 25, 2023
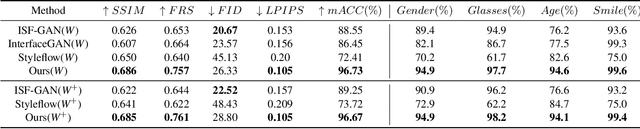
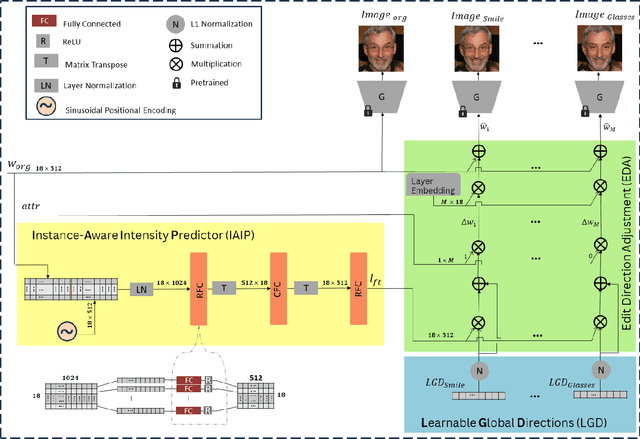
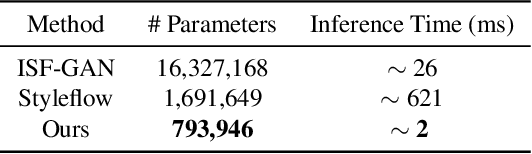
Semantic facial attribute editing using pre-trained Generative Adversarial Networks (GANs) has attracted a great deal of attention and effort from researchers in recent years. Due to the high quality of face images generated by StyleGANs, much work has focused on the StyleGANs' latent space and the proposed methods for facial image editing. Although these methods have achieved satisfying results for manipulating user-intended attributes, they have not fulfilled the goal of preserving the identity, which is an important challenge. We present ID-Style, a new architecture capable of addressing the problem of identity loss during attribute manipulation. The key components of ID-Style include Learnable Global Direction (LGD), which finds a shared and semi-sparse direction for each attribute, and an Instance-Aware Intensity Predictor (IAIP) network, which finetunes the global direction according to the input instance. Furthermore, we introduce two losses during training to enforce the LGD to find semi-sparse semantic directions, which along with the IAIP, preserve the identity of the input instance. Despite reducing the size of the network by roughly 95% as compared to similar state-of-the-art works, it outperforms baselines by 10% and 7% in Identity preserving metric (FRS) and average accuracy of manipulation (mACC), respectively.
Controlling the Output of a Generative Model by Latent Feature Vector Shifting
Nov 15, 2023State-of-the-art generative models (e.g. StyleGAN3 \cite{karras2021alias}) often generate photorealistic images based on vectors sampled from their latent space. However, the ability to control the output is limited. Here we present our novel method for latent vector shifting for controlled output image modification utilizing semantic features of the generated images. In our approach we use a pre-trained model of StyleGAN3 that generates images of realistic human faces in relatively high resolution. We complement the generative model with a convolutional neural network classifier, namely ResNet34, trained to classify the generated images with binary facial features from the CelebA dataset. Our latent feature shifter is a neural network model with a task to shift the latent vectors of a generative model into a specified feature direction. We have trained latent feature shifter for multiple facial features, and outperformed our baseline method in the number of generated images with the desired feature. To train our latent feature shifter neural network, we have designed a dataset of pairs of latent vectors with and without a certain feature. Based on the evaluation, we conclude that our latent feature shifter approach was successful in the controlled generation of the StyleGAN3 generator.
* 7 pages, presented on DISA2023 conference in Ko\v{s}ice
UniTSFace: Unified Threshold Integrated Sample-to-Sample Loss for Face Recognition
Nov 04, 2023Sample-to-class-based face recognition models can not fully explore the cross-sample relationship among large amounts of facial images, while sample-to-sample-based models require sophisticated pairing processes for training. Furthermore, neither method satisfies the requirements of real-world face verification applications, which expect a unified threshold separating positive from negative facial pairs. In this paper, we propose a unified threshold integrated sample-to-sample based loss (USS loss), which features an explicit unified threshold for distinguishing positive from negative pairs. Inspired by our USS loss, we also derive the sample-to-sample based softmax and BCE losses, and discuss their relationship. Extensive evaluation on multiple benchmark datasets, including MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace, demonstrates that the proposed USS loss is highly efficient and can work seamlessly with sample-to-class-based losses. The embedded loss (USS and sample-to-class Softmax loss) overcomes the pitfalls of previous approaches and the trained facial model UniTSFace exhibits exceptional performance, outperforming state-of-the-art methods, such as CosFace, ArcFace, VPL, AnchorFace, and UNPG. Our code is available.
Facial Prior Based First Order Motion Model for Micro-expression Generation
Aug 08, 2023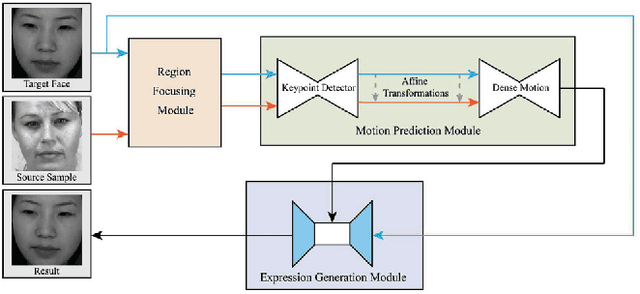

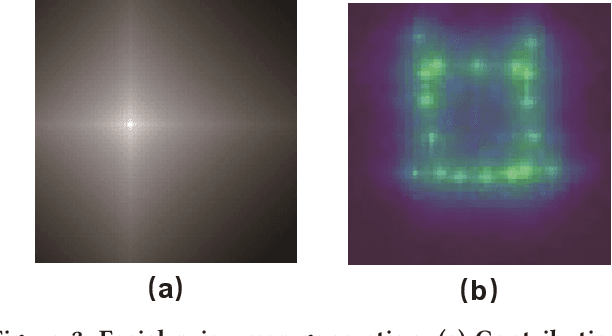
Spotting facial micro-expression from videos finds various potential applications in fields including clinical diagnosis and interrogation, meanwhile this task is still difficult due to the limited scale of training data. To solve this problem, this paper tries to formulate a new task called micro-expression generation and then presents a strong baseline which combines the first order motion model with facial prior knowledge. Given a target face, we intend to drive the face to generate micro-expression videos according to the motion patterns of source videos. Specifically, our new model involves three modules. First, we extract facial prior features from a region focusing module. Second, we estimate facial motion using key points and local affine transformations with a motion prediction module. Third, expression generation module is used to drive the target face to generate videos. We train our model on public CASME II, SAMM and SMIC datasets and then use the model to generate new micro-expression videos for evaluation. Our model achieves the first place in the Facial Micro-Expression Challenge 2021 (MEGC2021), where our superior performance is verified by three experts with Facial Action Coding System certification. Source code is provided in https://github.com/Necolizer/Facial-Prior-Based-FOMM.
Can Protective Perturbation Safeguard Personal Data from Being Exploited by Stable Diffusion?
Nov 30, 2023Stable Diffusion has established itself as a foundation model in generative AI artistic applications, receiving widespread research and application. Some recent fine-tuning methods have made it feasible for individuals to implant personalized concepts onto the basic Stable Diffusion model with minimal computational costs on small datasets. However, these innovations have also given rise to issues like facial privacy forgery and artistic copyright infringement. In recent studies, researchers have explored the addition of imperceptible adversarial perturbations to images to prevent potential unauthorized exploitation and infringements when personal data is used for fine-tuning Stable Diffusion. Although these studies have demonstrated the ability to protect images, it is essential to consider that these methods may not be entirely applicable in real-world scenarios. In this paper, we systematically evaluate the use of perturbations to protect images within a practical threat model. The results suggest that these approaches may not be sufficient to safeguard image privacy and copyright effectively. Furthermore, we introduce a purification method capable of removing protected perturbations while preserving the original image structure to the greatest extent possible. Experiments reveal that Stable Diffusion can effectively learn from purified images over all protective methods.
Non-Contact Breathing Rate Detection Using Optical Flow
Nov 13, 2023Breathing rate is a vital health metric that is an invaluable indicator of the overall health of a person. In recent years, the non-contact measurement of health signals such as breathing rate has been a huge area of development, with a wide range of applications from telemedicine to driver monitoring systems. This paper presents an investigation into a method of non-contact breathing rate detection using a motion detection algorithm, optical flow. Optical flow is used to successfully measure breathing rate by tracking the motion of specific points on the body. In this study, the success of optical flow when using different sets of points is evaluated. Testing shows that both chest and facial movement can be used to determine breathing rate but to different degrees of success. The chest generates very accurate signals, with an RMSE of 0.63 on the tested videos. Facial points can also generate reliable signals when there is minimal head movement but are much more vulnerable to noise caused by head/body movements. These findings highlight the potential of optical flow as a non-invasive method for breathing rate detection and emphasize the importance of selecting appropriate points to optimize accuracy.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023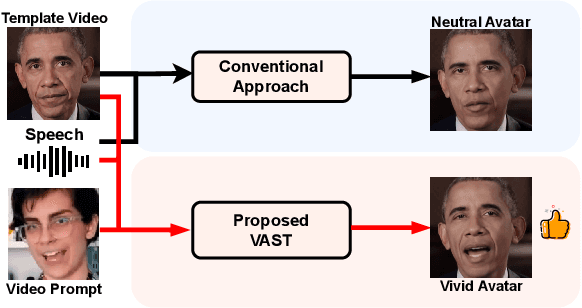

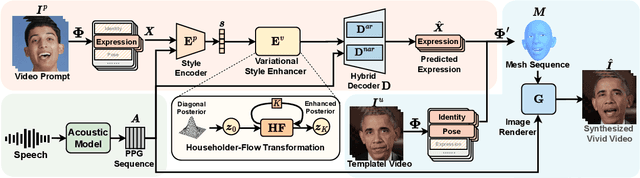
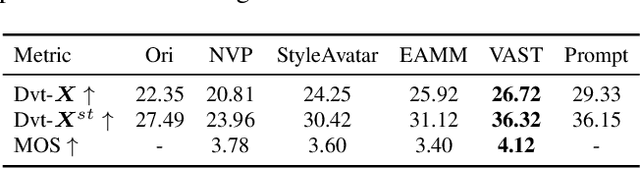
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.