 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than the Sum: Panorama-Language Models for Adverse Omni-Scenes
Mar 10, 2026Existing vision-language models (VLMs) are tailored for pinhole imagery, stitching multiple narrow field-of-view inputs to piece together a complete omni-scene understanding. Yet, such multi-view perception overlooks the holistic spatial and contextual relationships that a single panorama inherently preserves. In this work, we introduce the Panorama-Language Modeling (PLM)paradigm, a unified $360^\circ$ vision-language reasoning that is more than the sum of its pinhole counterparts. Besides, we present PanoVQA, a large-scale panoramic VQA dataset that involves adverse omni-scenes, enabling comprehensive reasoning under object occlusions and driving accidents. To establish a foundation for PLM, we develop a plug-and-play panoramic sparse attention module that allows existing pinhole-based VLMs to process equirectangular panoramas without retraining. Extensive experiments demonstrate that our PLM achieves superior robustness and holistic reasoning under challenging omni-scenes, yielding understanding greater than the sum of its narrow parts. Project page: https://github.com/InSAI-Lab/PanoVQA.
BCE3S: Binary Cross-Entropy Based Tripartite Synergistic Learning for Long-tailed Recognition
Nov 18, 2025



For long-tailed recognition (LTR) tasks, high intra-class compactness and inter-class separability in both head and tail classes, as well as balanced separability among all the classifier vectors, are preferred. The existing LTR methods based on cross-entropy (CE) loss not only struggle to learn features with desirable properties but also couple imbalanced classifier vectors in the denominator of its Softmax, amplifying the imbalance effects in LTR. In this paper, for the LTR, we propose a binary cross-entropy (BCE)-based tripartite synergistic learning, termed BCE3S, which consists of three components: (1) BCE-based joint learning optimizes both the classifier and sample features, which achieves better compactness and separability among features than the CE-based joint learning, by decoupling the metrics between feature and the imbalanced classifier vectors in multiple Sigmoid; (2) BCE-based contrastive learning further improves the intra-class compactness of features; (3) BCE-based uniform learning balances the separability among classifier vectors and interactively enhances the feature properties by combining with the joint learning. The extensive experiments show that the LTR model trained by BCE3S not only achieves higher compactness and separability among sample features, but also balances the classifier's separability, achieving SOTA performance on various long-tailed datasets such as CIFAR10-LT, CIFAR100-LT, ImageNet-LT, and iNaturalist2018.
DAP-MAE: Domain-Adaptive Point Cloud Masked Autoencoder for Effective Cross-Domain Learning
Oct 24, 2025Compared to 2D data, the scale of point cloud data in different domains available for training, is quite limited. Researchers have been trying to combine these data of different domains for masked autoencoder (MAE) pre-training to leverage such a data scarcity issue. However, the prior knowledge learned from mixed domains may not align well with the downstream 3D point cloud analysis tasks, leading to degraded performance. To address such an issue, we propose the Domain-Adaptive Point Cloud Masked Autoencoder (DAP-MAE), an MAE pre-training method, to adaptively integrate the knowledge of cross-domain datasets for general point cloud analysis. In DAP-MAE, we design a heterogeneous domain adapter that utilizes an adaptation mode during pre-training, enabling the model to comprehensively learn information from point clouds across different domains, while employing a fusion mode in the fine-tuning to enhance point cloud features. Meanwhile, DAP-MAE incorporates a domain feature generator to guide the adaptation of point cloud features to various downstream tasks. With only one pre-training, DAP-MAE achieves excellent performance across four different point cloud analysis tasks, reaching 95.18% in object classification on ScanObjectNN and 88.45% in facial expression recognition on Bosphorus.
* 14 pages, 7 figures, conference
BCE vs. CE in Deep Feature Learning
May 09, 2025When training classification models, it expects that the learned features are compact within classes, and can well separate different classes. As the dominant loss function for training classification models, minimizing cross-entropy (CE) loss maximizes the compactness and distinctiveness, i.e., reaching neural collapse (NC). The recent works show that binary CE (BCE) performs also well in multi-class tasks. In this paper, we compare BCE and CE in deep feature learning. For the first time, we prove that BCE can also maximize the intra-class compactness and inter-class distinctiveness when reaching its minimum, i.e., leading to NC. We point out that CE measures the relative values of decision scores in the model training, implicitly enhancing the feature properties by classifying samples one-by-one. In contrast, BCE measures the absolute values of decision scores and adjust the positive/negative decision scores across all samples to uniformly high/low levels. Meanwhile, the classifier biases in BCE present a substantial constraint on the decision scores to explicitly enhance the feature properties in the training. The experimental results are aligned with above analysis, and show that BCE could improve the classification and leads to better compactness and distinctiveness among sample features. The codes will be released.
Distilled Transformers with Locally Enhanced Global Representations for Face Forgery Detection
Dec 28, 2024



Face forgery detection (FFD) is devoted to detecting the authenticity of face images. Although current CNN-based works achieve outstanding performance in FFD, they are susceptible to capturing local forgery patterns generated by various manipulation methods. Though transformer-based detectors exhibit improvements in modeling global dependencies, they are not good at exploring local forgery artifacts. Hybrid transformer-based networks are designed to capture local and global manipulated traces, but they tend to suffer from the attention collapse issue as the transformer block goes deeper. Besides, soft labels are rarely available. In this paper, we propose a distilled transformer network (DTN) to capture both rich local and global forgery traces and learn general and common representations for different forgery faces. Specifically, we design a mixture of expert (MoE) module to mine various robust forgery embeddings. Moreover, a locally-enhanced vision transformer (LEVT) module is proposed to learn locally-enhanced global representations. We design a lightweight multi-attention scaling (MAS) module to avoid attention collapse, which can be plugged and played in any transformer-based models with only a slight increase in computational costs. In addition, we propose a deepfake self-distillation (DSD) scheme to provide the model with abundant soft label information. Extensive experiments show that the proposed method surpasses the state of the arts on five deepfake datasets.
WiNet: Wavelet-based Incremental Learning for Efficient Medical Image Registration
Jul 18, 2024Deep image registration has demonstrated exceptional accuracy and fast inference. Recent advances have adopted either multiple cascades or pyramid architectures to estimate dense deformation fields in a coarse-to-fine manner. However, due to the cascaded nature and repeated composition/warping operations on feature maps, these methods negatively increase memory usage during training and testing. Moreover, such approaches lack explicit constraints on the learning process of small deformations at different scales, thus lacking explainability. In this study, we introduce a model-driven WiNet that incrementally estimates scale-wise wavelet coefficients for the displacement/velocity field across various scales, utilizing the wavelet coefficients derived from the original input image pair. By exploiting the properties of the wavelet transform, these estimated coefficients facilitate the seamless reconstruction of a full-resolution displacement/velocity field via our devised inverse discrete wavelet transform (IDWT) layer. This approach avoids the complexities of cascading networks or composition operations, making our WiNet an explainable and efficient competitor with other coarse-to-fine methods. Extensive experimental results from two 3D datasets show that our WiNet is accurate and GPU efficient. The code is available at https://github.com/x-xc/WiNet .
EPL: Empirical Prototype Learning for Deep Face Recognition
May 21, 2024Prototype learning is widely used in face recognition, which takes the row vectors of coefficient matrix in the last linear layer of the feature extraction model as the prototypes for each class. When the prototypes are updated using the facial sample feature gradients in the model training, they are prone to being pulled away from the class center by the hard samples, resulting in decreased overall model performance. In this paper, we explicitly define prototypes as the expectations of sample features in each class and design the empirical prototypes using the existing samples in the dataset. We then devise a strategy to adaptively update these empirical prototypes during the model training based on the similarity between the sample features and the empirical prototypes. Furthermore, we propose an empirical prototype learning (EPL) method, which utilizes an adaptive margin parameter with respect to sample features. EPL assigns larger margins to the normal samples and smaller margins to the hard samples, allowing the learned empirical prototypes to better reflect the class center dominated by the normal samples and finally pull the hard samples towards the empirical prototypes through the learning. The extensive experiments on MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace demonstrate the effectiveness of EPL. Our code is available at $\href{https://github.com/WakingHours-GitHub/EPL}{https://github.com/WakingHours-GitHub/EPL}$.
Rediscovering BCE Loss for Uniform Classification
Mar 12, 2024



This paper introduces the concept of uniform classification, which employs a unified threshold to classify all samples rather than adaptive threshold classifying each individual sample. We also propose the uniform classification accuracy as a metric to measure the model's performance in uniform classification. Furthermore, begin with a naive loss, we mathematically derive a loss function suitable for the uniform classification, which is the BCE function integrated with a unified bias. We demonstrate the unified threshold could be learned via the bias. The extensive experiments on six classification datasets and three feature extraction models show that, compared to the SoftMax loss, the models trained with the BCE loss not only exhibit higher uniform classification accuracy but also higher sample-wise classification accuracy. In addition, the learned bias from BCE loss is very close to the unified threshold used in the uniform classification. The features extracted by the models trained with BCE loss not only possess uniformity but also demonstrate better intra-class compactness and inter-class distinctiveness, yielding superior performance on open-set tasks such as face recognition.
UniTSFace: Unified Threshold Integrated Sample-to-Sample Loss for Face Recognition
Nov 04, 2023



Sample-to-class-based face recognition models can not fully explore the cross-sample relationship among large amounts of facial images, while sample-to-sample-based models require sophisticated pairing processes for training. Furthermore, neither method satisfies the requirements of real-world face verification applications, which expect a unified threshold separating positive from negative facial pairs. In this paper, we propose a unified threshold integrated sample-to-sample based loss (USS loss), which features an explicit unified threshold for distinguishing positive from negative pairs. Inspired by our USS loss, we also derive the sample-to-sample based softmax and BCE losses, and discuss their relationship. Extensive evaluation on multiple benchmark datasets, including MFR, IJB-C, LFW, CFP-FP, AgeDB, and MegaFace, demonstrates that the proposed USS loss is highly efficient and can work seamlessly with sample-to-class-based losses. The embedded loss (USS and sample-to-class Softmax loss) overcomes the pitfalls of previous approaches and the trained facial model UniTSFace exhibits exceptional performance, outperforming state-of-the-art methods, such as CosFace, ArcFace, VPL, AnchorFace, and UNPG. Our code is available.
Activation Template Matching Loss for Explainable Face Recognition
Jul 05, 2022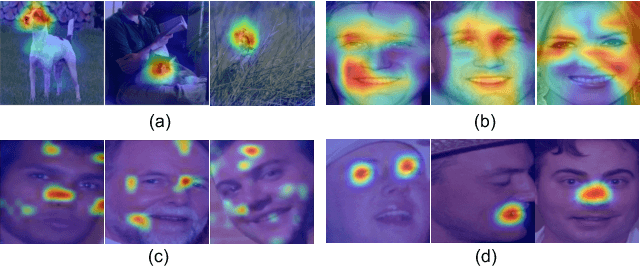
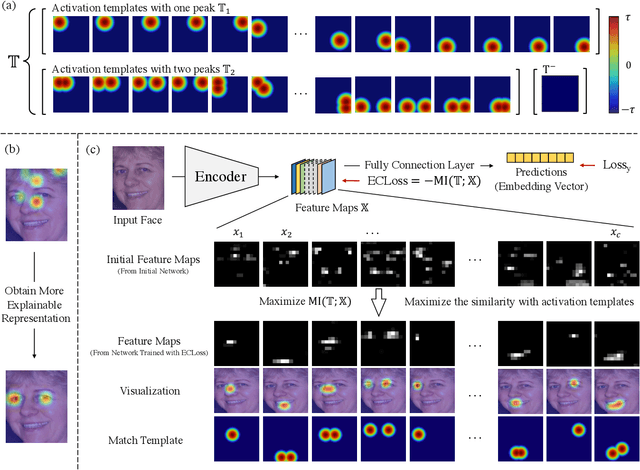
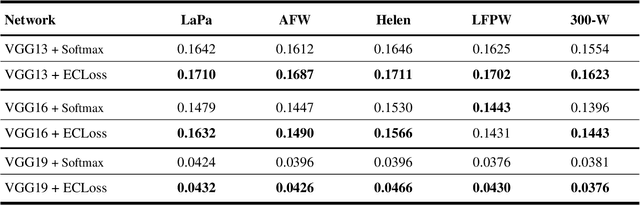
Can we construct an explainable face recognition network able to learn a facial part-based feature like eyes, nose, mouth and so forth, without any manual annotation or additionalsion datasets? In this paper, we propose a generic Explainable Channel Loss (ECLoss) to construct an explainable face recognition network. The explainable network trained with ECLoss can easily learn the facial part-based representation on the target convolutional layer, where an individual channel can detect a certain face part. Our experiments on dozens of datasets show that ECLoss achieves superior explainability metrics, and at the same time improves the performance of face verification without face alignment. In addition, our visualization results also illustrate the effectiveness of the proposed ECLoss.