 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Snapture -- A Novel Neural Architecture for Combined Static and Dynamic Hand Gesture Recognition
May 28, 2022
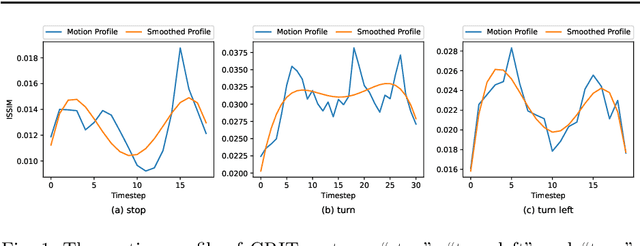

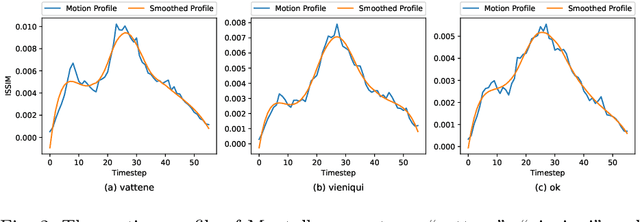
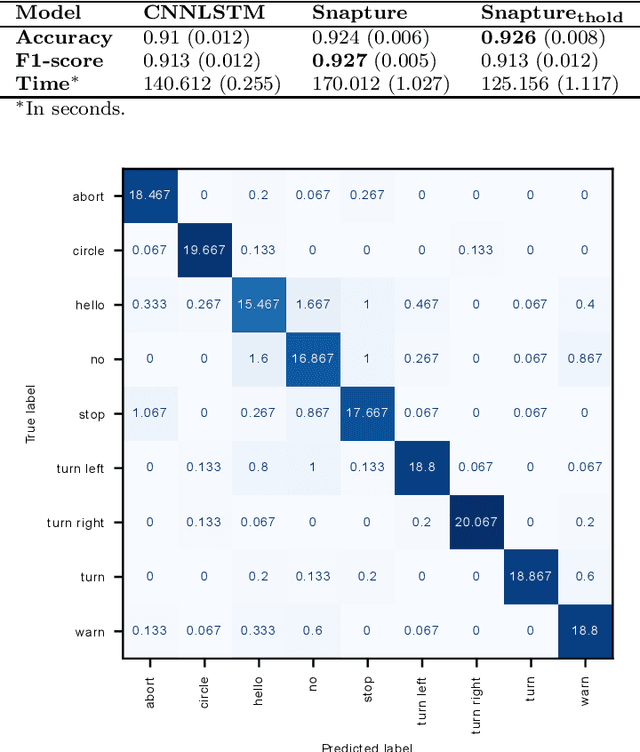
As robots are expected to get more involved in people's everyday lives, frameworks that enable intuitive user interfaces are in demand. Hand gesture recognition systems provide a natural way of communication and, thus, are an integral part of seamless Human-Robot Interaction (HRI). Recent years have witnessed an immense evolution of computational models powered by deep learning. However, state-of-the-art models fall short in expanding across different gesture domains, such as emblems and co-speech. In this paper, we propose a novel hybrid hand gesture recognition system. Our architecture enables learning both static and dynamic gestures: by capturing a so-called "snapshot" of the gesture performance at its peak, we integrate the hand pose along with the dynamic movement. Moreover, we present a method for analyzing the motion profile of a gesture to uncover its dynamic characteristics and which allows regulating a static channel based on the amount of motion. Our evaluation demonstrates the superiority of our approach on two gesture benchmarks compared to a CNNLSTM baseline. We also provide an analysis on a gesture class basis that unveils the potential of our Snapture architecture for performance improvements. Thanks to its modular implementation, our framework allows the integration of other multimodal data like facial expressions and head tracking, which are important cues in HRI scenarios, into one architecture. Thus, our work contributes both to gesture recognition research and machine learning applications for non-verbal communication with robots.
Face-Cap: Image Captioning using Facial Expression Analysis
Jul 06, 2018
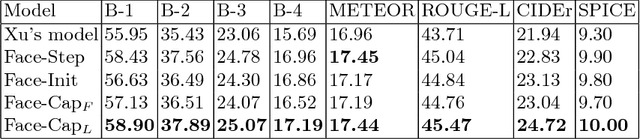
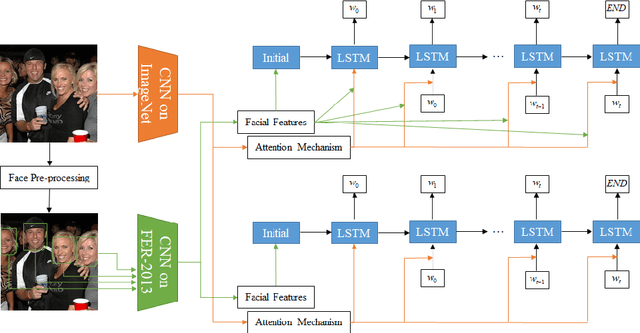
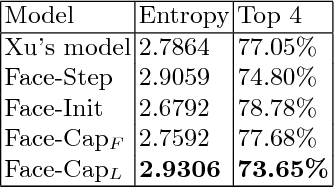
Image captioning is the process of generating a natural language description of an image. Most current image captioning models, however, do not take into account the emotional aspect of an image, which is very relevant to activities and interpersonal relationships represented therein. Towards developing a model that can produce human-like captions incorporating these, we use facial expression features extracted from images including human faces, with the aim of improving the descriptive ability of the model. In this work, we present two variants of our Face-Cap model, which embed facial expression features in different ways, to generate image captions. Using all standard evaluation metrics, our Face-Cap models outperform a state-of-the-art baseline model for generating image captions when applied to an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the captions finds that, perhaps surprisingly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.
Multi-Cue Adaptive Emotion Recognition Network
Nov 03, 2021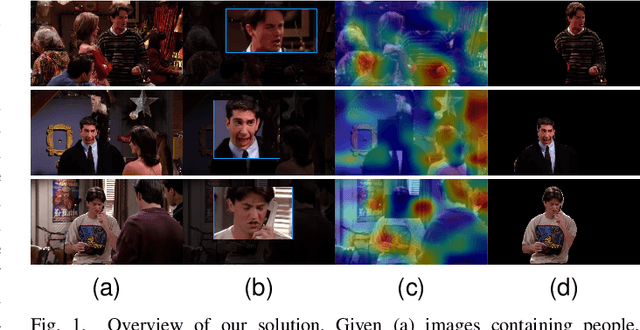
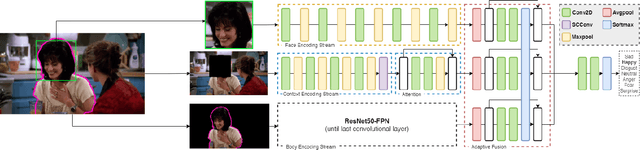

Expressing and identifying emotions through facial and physical expressions is a significant part of social interaction. Emotion recognition is an essential task in computer vision due to its various applications and mainly for allowing a more natural interaction between humans and machines. The common approaches for emotion recognition focus on analyzing facial expressions and requires the automatic localization of the face in the image. Although these methods can correctly classify emotion in controlled scenarios, such techniques are limited when dealing with unconstrained daily interactions. We propose a new deep learning approach for emotion recognition based on adaptive multi-cues that extract information from context and body poses, which humans commonly use in social interaction and communication. We compare the proposed approach with the state-of-art approaches in the CAER-S dataset, evaluating different components in a pipeline that reached an accuracy of 89.30%
Faces in the Wild: Efficient Gender Recognition in Surveillance Conditions
Jul 14, 2021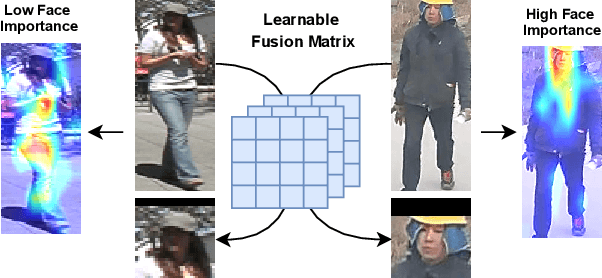
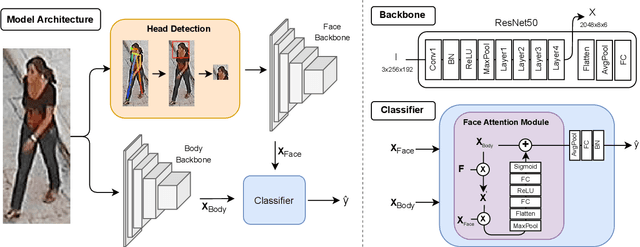


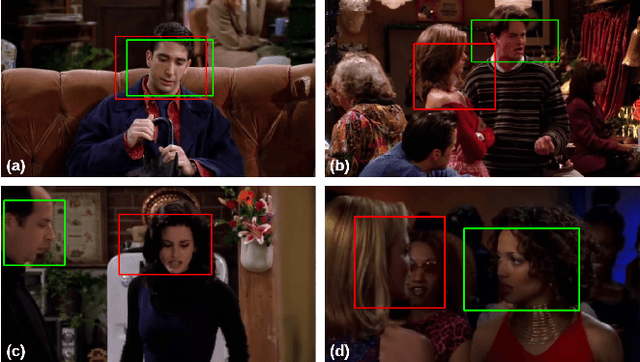
Soft biometrics inference in surveillance scenarios is a topic of interest for various applications, particularly in security-related areas. However, soft biometric analysis is not extensively reported in wild conditions. In particular, previous works on gender recognition report their results in face datasets, with relatively good image quality and frontal poses. Given the uncertainty of the availability of the facial region in wild conditions, we consider that these methods are not adequate for surveillance settings. To overcome these limitations, we: 1) present frontal and wild face versions of three well-known surveillance datasets; and 2) propose a model that effectively and dynamically combines facial and body information, which makes it suitable for gender recognition in wild conditions. The frontal and wild face datasets derive from widely used Pedestrian Attribute Recognition (PAR) sets (PETA, PA-100K, and RAP), using a pose-based approach to filter the frontal samples and facial regions. This approach retrieves the facial region of images with varying image/subject conditions, where the state-of-the-art face detectors often fail. Our model combines facial and body information through a learnable fusion matrix and a channel-attention sub-network, focusing on the most influential body parts according to the specific image/subject features. We compare it with five PAR methods, consistently obtaining state-of-the-art results on gender recognition, and reducing the prediction errors by up to 24% in frontal samples. The announced PAR datasets versions and model serve as the basis for wild soft biometrics classification and are available in https://github.com/Tiago-Roxo.
Gender Transformation: Robustness of GenderDetection in Facial Recognition Systems with variation in Image Properties
Nov 18, 2020In recent times, there have been increasing accusations on artificial intelligence systems and algorithms of computer vision of possessing implicit biases. Even though these conversations are more prevalent now and systems are improving by performing extensive testing and broadening their horizon, biases still do exist. One such class of systems where bias is said to exist is facial recognition systems, where bias has been observed on the basis of gender, ethnicity, and skin tone, to name a few. This is even more disturbing, given the fact that these systems are used in practically every sector of the industries today. From as critical as criminal identification to as simple as getting your attendance registered, these systems have gained a huge market, especially in recent years. That in itself is a good enough reason for developers of these systems to ensure that the bias is kept to a bare minimum or ideally non-existent, to avoid major issues like favoring a particular gender, race, or class of people or rather making a class of people susceptible to false accusations due to inability of these systems to correctly recognize those people.
Few-Shot Head Swapping in the Wild
Apr 27, 2022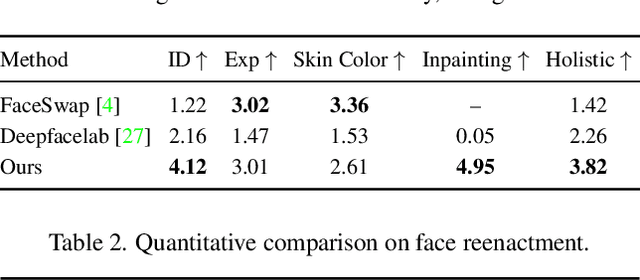
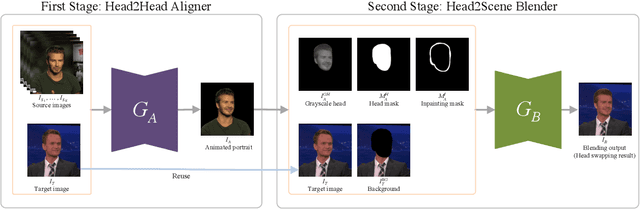
The head swapping task aims at flawlessly placing a source head onto a target body, which is of great importance to various entertainment scenarios. While face swapping has drawn much attention, the task of head swapping has rarely been explored, particularly under the few-shot setting. It is inherently challenging due to its unique needs in head modeling and background blending. In this paper, we present the Head Swapper (HeSer), which achieves few-shot head swapping in the wild through two delicately designed modules. Firstly, a Head2Head Aligner is devised to holistically migrate pose and expression information from the target to the source head by examining multi-scale information. Secondly, to tackle the challenges of skin color variations and head-background mismatches in the swapping procedure, a Head2Scene Blender is introduced to simultaneously modify facial skin color and fill mismatched gaps in the background around the head. Particularly, seamless blending is achieved with the help of a Semantic-Guided Color Reference Creation procedure and a Blending UNet. Extensive experiments demonstrate that the proposed method produces superior head swapping results in a variety of scenes.
TAFIM: Targeted Adversarial Attacks against Facial Image Manipulations
Dec 16, 2021

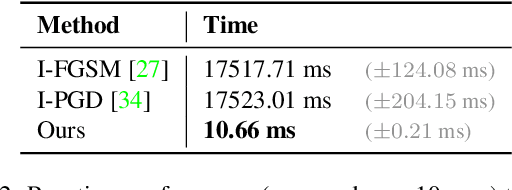

Face image manipulation methods, despite having many beneficial applications in computer graphics, can also raise concerns by affecting an individual's privacy or spreading disinformation. In this work, we propose a proactive defense to prevent face manipulation from happening in the first place. To this end, we introduce a novel data-driven approach that produces image-specific perturbations which are embedded in the original images. The key idea is that these protected images prevent face manipulation by causing the manipulation model to produce a predefined manipulation target (uniformly colored output image in our case) instead of the actual manipulation. Compared to traditional adversarial attacks that optimize noise patterns for each image individually, our generalized model only needs a single forward pass, thus running orders of magnitude faster and allowing for easy integration in image processing stacks, even on resource-constrained devices like smartphones. In addition, we propose to leverage a differentiable compression approximation, hence making generated perturbations robust to common image compression. We further show that a generated perturbation can simultaneously prevent against multiple manipulation methods.
Cross-Cultural and Cultural-Specific Production and Perception of Facial Expressions of Emotion in the Wild
Aug 13, 2018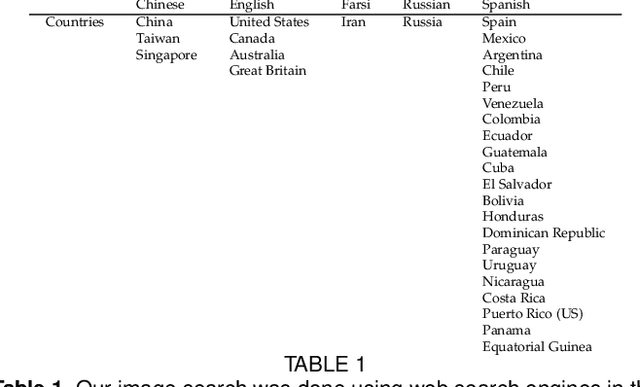
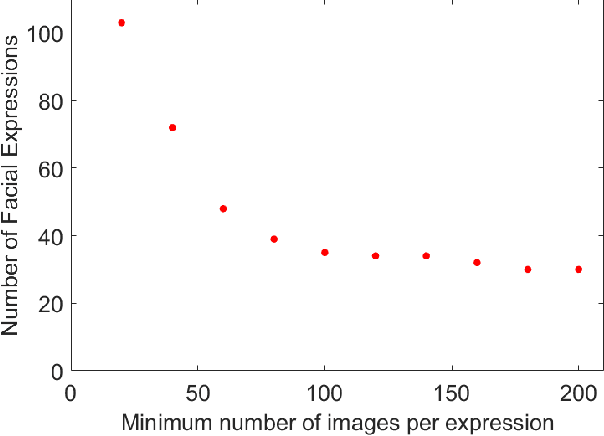

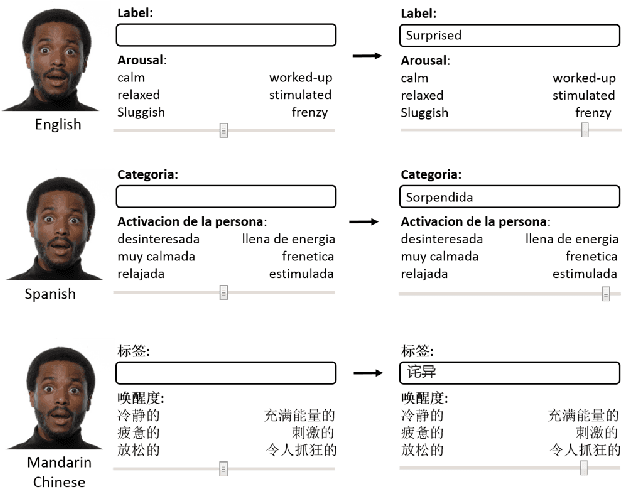
Automatic recognition of emotion from facial expressions is an intense area of research, with a potentially long list of important application. Yet, the study of emotion requires knowing which facial expressions are used within and across cultures in the wild, not in controlled lab conditions; but such studies do not exist. Which and how many cross-cultural and cultural-specific facial expressions do people commonly use? And, what affect variables does each expression communicate to observers? If we are to design technology that understands the emotion of users, we need answers to these two fundamental questions. In this paper, we present the first large-scale study of the production and visual perception of facial expressions of emotion in the wild. We find that of the 16,384 possible facial configurations that people can theoretically produce, only 35 are successfully used to transmit emotive information across cultures, and only 8 within a smaller number of cultures. Crucially, we find that visual analysis of cross-cultural expressions yields consistent perception of emotion categories and valence, but not arousal. In contrast, visual analysis of cultural-specific expressions yields consistent perception of valence and arousal, but not of emotion categories. Additionally, we find that the number of expressions used to communicate each emotion is also different, e.g., 17 expressions transmit happiness, but only 1 is used to convey disgust.
A Self-Supervised Deep Framework for Reference Bony Shape Estimation in Orthognathic Surgical Planning
Sep 11, 2021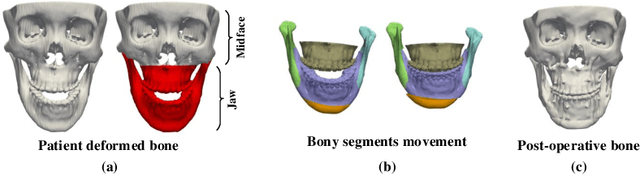
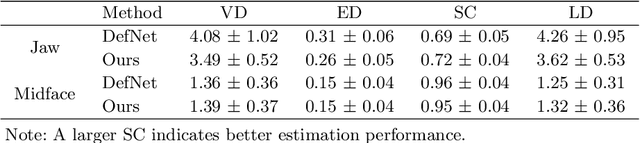
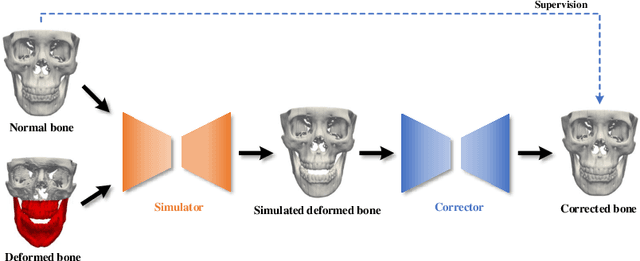
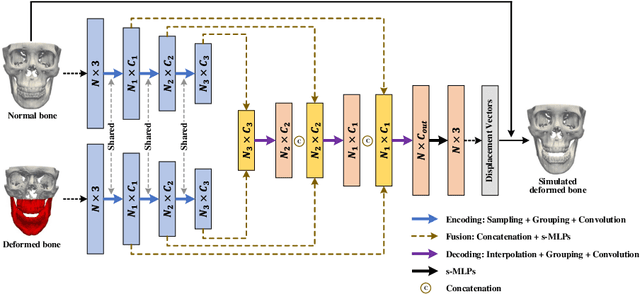
Virtual orthognathic surgical planning involves simulating surgical corrections of jaw deformities on 3D facial bony shape models. Due to the lack of necessary guidance, the planning procedure is highly experience-dependent and the planning results are often suboptimal. A reference facial bony shape model representing normal anatomies can provide an objective guidance to improve planning accuracy. Therefore, we propose a self-supervised deep framework to automatically estimate reference facial bony shape models. Our framework is an end-to-end trainable network, consisting of a simulator and a corrector. In the training stage, the simulator maps jaw deformities of a patient bone to a normal bone to generate a simulated deformed bone. The corrector then restores the simulated deformed bone back to normal. In the inference stage, the trained corrector is applied to generate a patient-specific normal-looking reference bone from a real deformed bone. The proposed framework was evaluated using a clinical dataset and compared with a state-of-the-art method that is based on a supervised point-cloud network. Experimental results show that the estimated shape models given by our approach are clinically acceptable and significantly more accurate than that of the competing method.
Relative Facial Action Unit Detection
May 01, 2014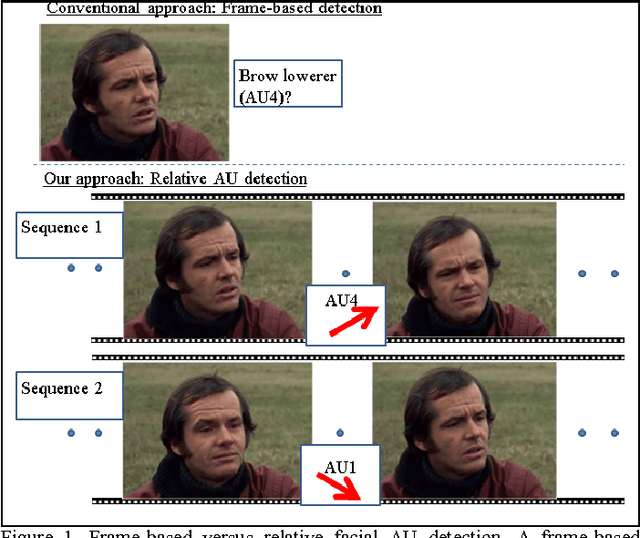
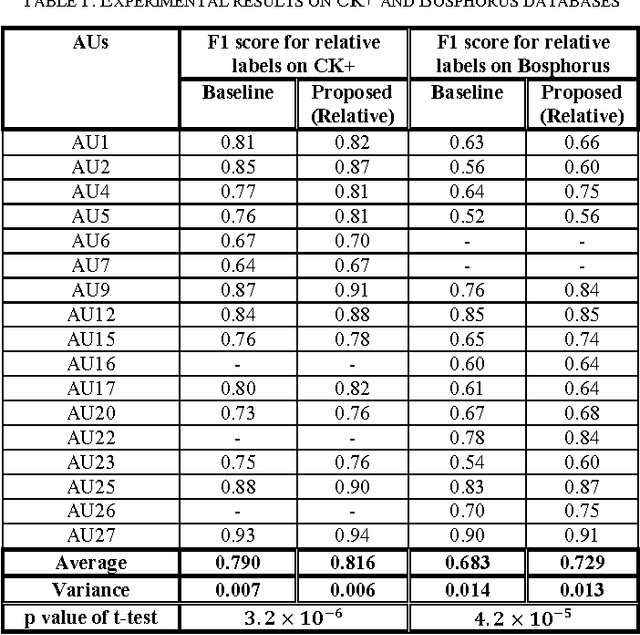
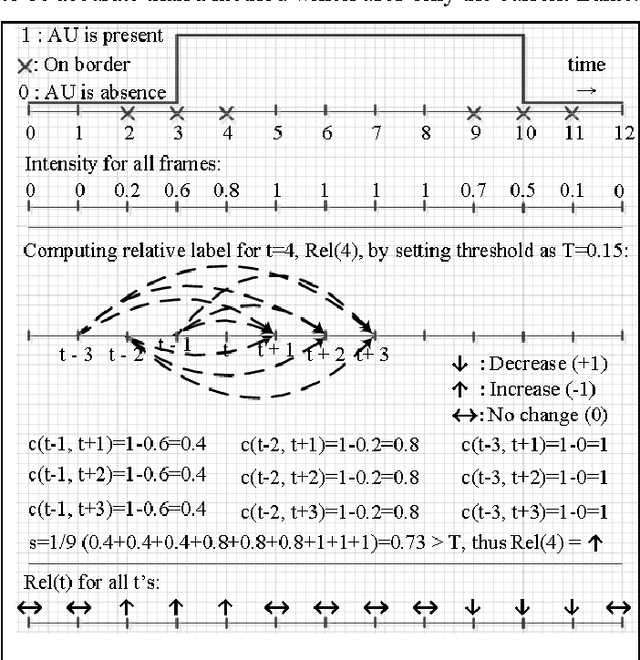
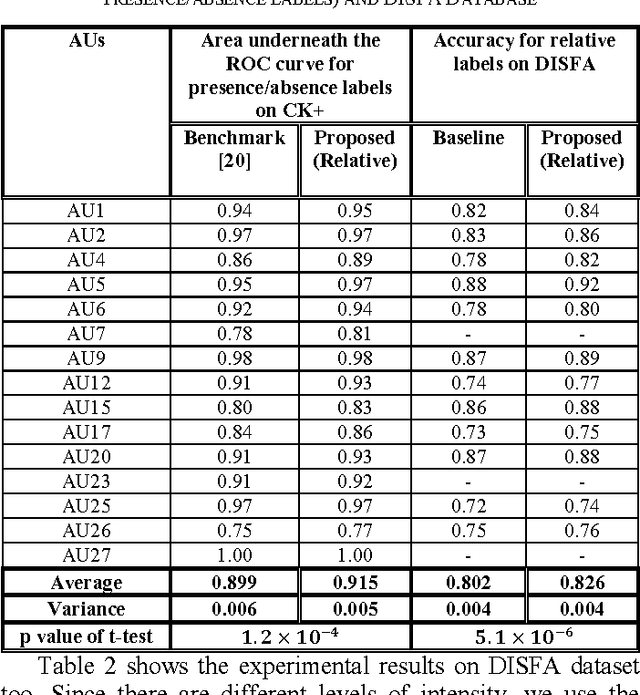
This paper presents a subject-independent facial action unit (AU) detection method by introducing the concept of relative AU detection, for scenarios where the neutral face is not provided. We propose a new classification objective function which analyzes the temporal neighborhood of the current frame to decide if the expression recently increased, decreased or showed no change. This approach is a significant change from the conventional absolute method which decides about AU classification using the current frame, without an explicit comparison with its neighboring frames. Our proposed method improves robustness to individual differences such as face scale and shape, age-related wrinkles, and transitions among expressions (e.g., lower intensity of expressions). Our experiments on three publicly available datasets (Extended Cohn-Kanade (CK+), Bosphorus, and DISFA databases) show significant improvement of our approach over conventional absolute techniques. Keywords: facial action coding system (FACS); relative facial action unit detection; temporal information;