 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-Cap: Image Captioning using Facial Expression Analysis
Paper and Code

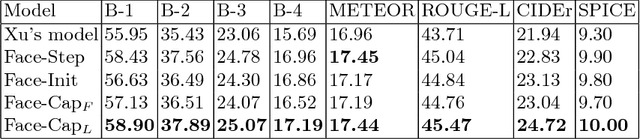
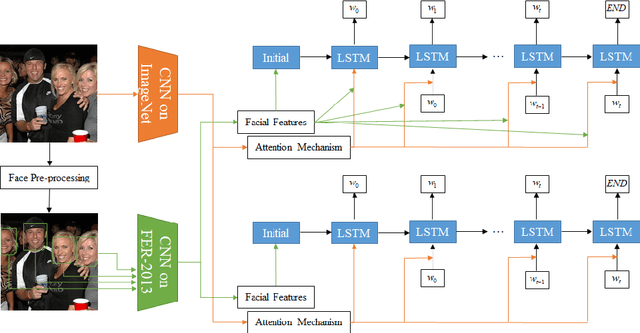
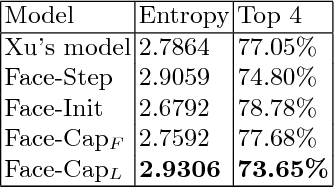
Image captioning is the process of generating a natural language description of an image. Most current image captioning models, however, do not take into account the emotional aspect of an image, which is very relevant to activities and interpersonal relationships represented therein. Towards developing a model that can produce human-like captions incorporating these, we use facial expression features extracted from images including human faces, with the aim of improving the descriptive ability of the model. In this work, we present two variants of our Face-Cap model, which embed facial expression features in different ways, to generate image captions. Using all standard evaluation metrics, our Face-Cap models outperform a state-of-the-art baseline model for generating image captions when applied to an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the captions finds that, perhaps surprisingly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.