 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Deep Learning using Entropic Losses
Aug 06, 2022

Current deep learning solutions are well known for not informing whether they can reliably classify an example during inference. One of the most effective ways to build more reliable deep learning solutions is to improve their performance in the so-called out-of-distribution detection task, which essentially consists of "know that you do not know" or "know the unknown". In other words, out-of-distribution detection capable systems may reject performing a nonsense classification when submitted to instances of classes on which the neural network was not trained. This thesis tackles the defiant out-of-distribution detection task by proposing novel loss functions and detection scores. Uncertainty estimation is also a crucial auxiliary task in building more robust deep learning systems. Therefore, we also deal with this robustness-related task, which evaluates how realistic the probabilities presented by the deep neural network are. To demonstrate the effectiveness of our approach, in addition to a substantial set of experiments, which includes state-of-the-art results, we use arguments based on the principle of maximum entropy to establish the theoretical foundation of the proposed approaches. Unlike most current methods, our losses and scores are seamless and principled solutions that produce accurate predictions in addition to fast and efficient inference. Moreover, our approaches can be incorporated into current and future projects simply by replacing the loss used to train the deep neural network and computing a rapid score for detection.
Distinction Maximization Loss: Efficiently Improving Classification Accuracy, Uncertainty Estimation, and Out-of-Distribution Detection Simply Replacing the Loss and Calibrating
May 19, 2022
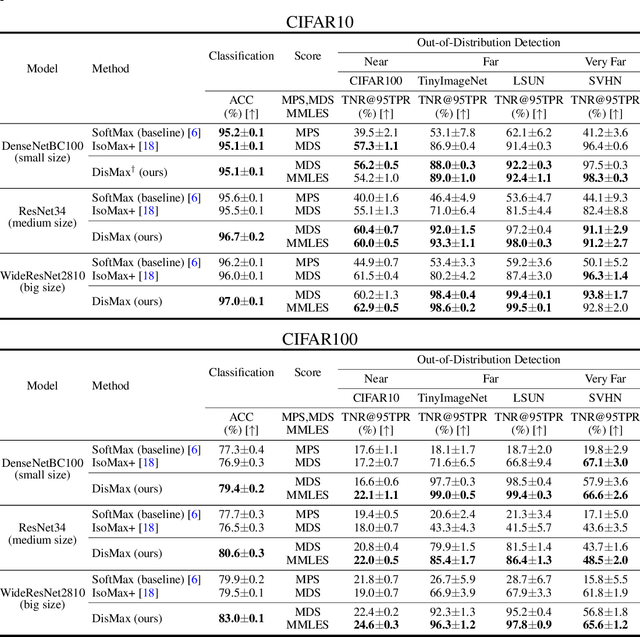
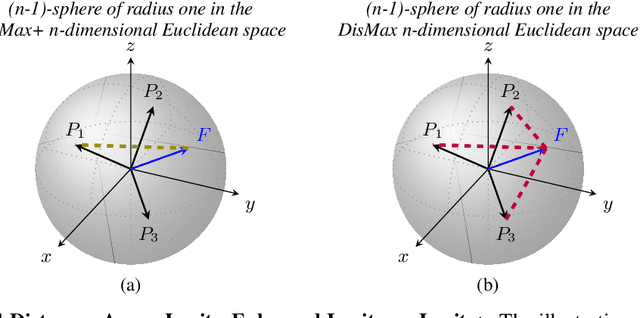
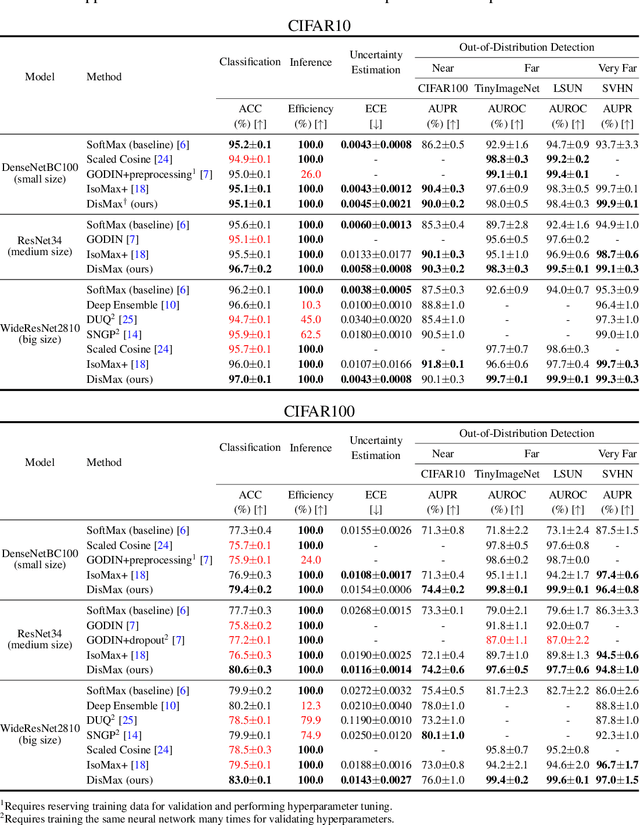
Building robust deterministic neural networks remains a challenge. On the one hand, some approaches improve out-of-distribution detection at the cost of reducing classification accuracy in some situations. On the other hand, some methods simultaneously increase classification accuracy, uncertainty estimation, and out-of-distribution detection at the expense of reducing the inference efficiency and requiring training the same model many times to tune hyperparameters. In this paper, we propose training deterministic neural networks using our DisMax loss, which works as a drop-in replacement for the usual SoftMax loss (i.e., the combination of the linear output layer, the SoftMax activation, and the cross-entropy loss). Starting from the IsoMax+ loss, we create each logit based on the distances to all prototypes rather than just the one associated with the correct class. We also introduce a mechanism to combine images to construct what we call fractional probability regularization. Moreover, we present a fast way to calibrate the network after training. Finally, we propose a composite score to perform out-of-distribution detection. Our experiments show that DisMax usually outperforms current approaches simultaneously in classification accuracy, uncertainty estimation, and out-of-distribution detection while maintaining deterministic neural network inference efficiency and avoiding training the same model repetitively for hyperparameter tuning. The code to reproduce the results is available at https://github.com/dlmacedo/distinction-maximization-loss.
Multi-Cue Adaptive Emotion Recognition Network
Nov 03, 2021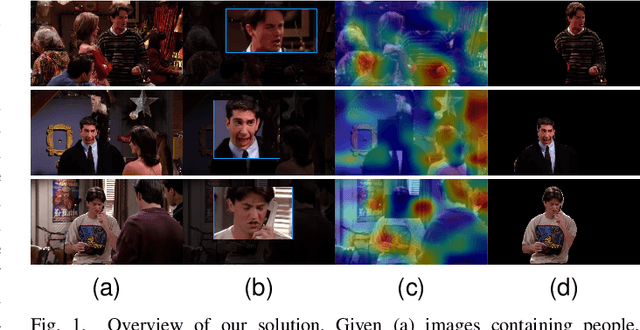
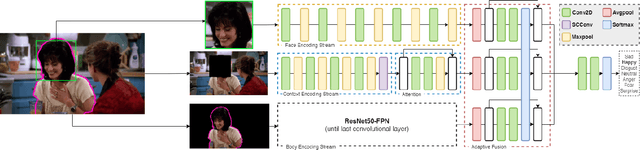
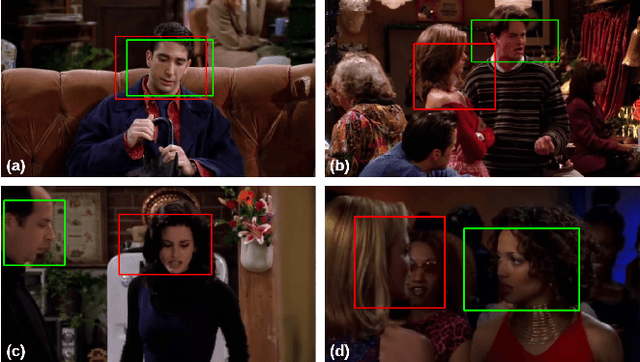

Expressing and identifying emotions through facial and physical expressions is a significant part of social interaction. Emotion recognition is an essential task in computer vision due to its various applications and mainly for allowing a more natural interaction between humans and machines. The common approaches for emotion recognition focus on analyzing facial expressions and requires the automatic localization of the face in the image. Although these methods can correctly classify emotion in controlled scenarios, such techniques are limited when dealing with unconstrained daily interactions. We propose a new deep learning approach for emotion recognition based on adaptive multi-cues that extract information from context and body poses, which humans commonly use in social interaction and communication. We compare the proposed approach with the state-of-art approaches in the CAER-S dataset, evaluating different components in a pipeline that reached an accuracy of 89.30%
Improving Entropic Out-of-Distribution Detection using Isometric Distances and the Minimum Distance Score
Jun 23, 2021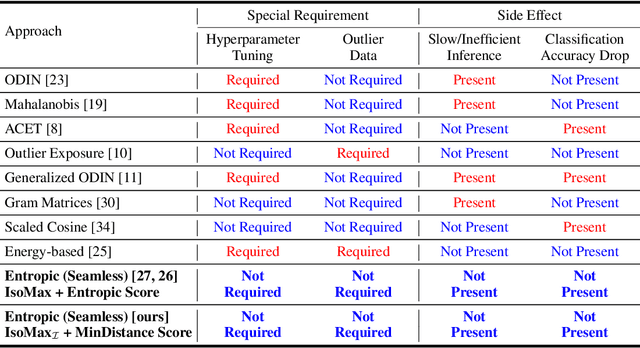
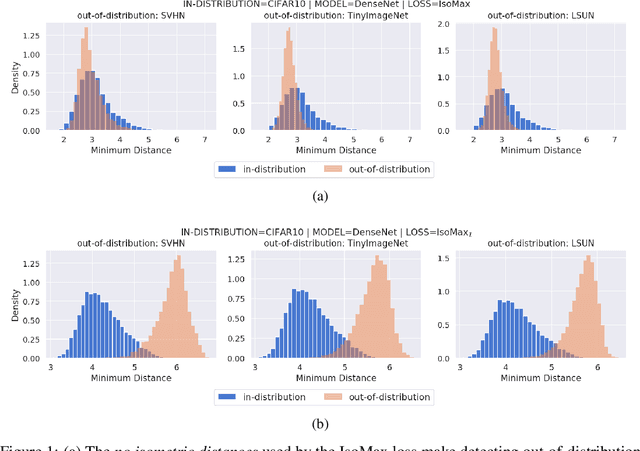
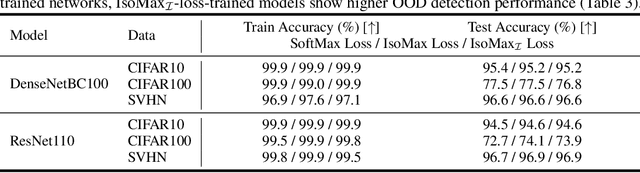
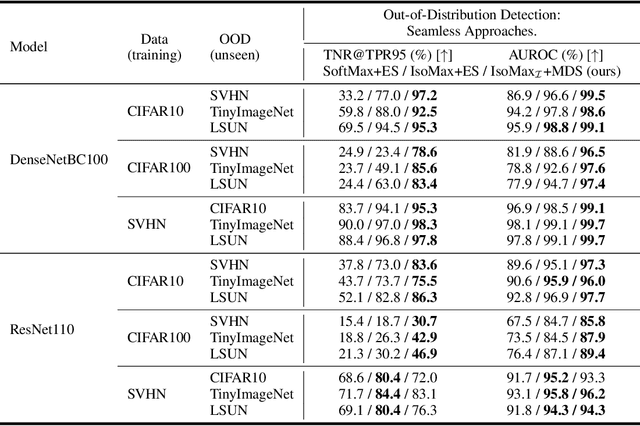
Current out-of-distribution detection approaches usually present special requirements (e.g., collecting outlier data and hyperparameter validation) and produce side effects (classification accuracy drop and slow/inefficient inferences). Recently, entropic out-of-distribution detection has been proposed as a seamless approach (i.e., a solution that avoids all the previously mentioned drawbacks). The entropic out-of-distribution detection solution comprises the IsoMax loss for training and the entropic score for out-of-distribution detection. The IsoMax loss works as a SoftMax loss drop-in replacement because swapping the SoftMax loss with the IsoMax loss requires no changes in the model's architecture or training procedures/hyperparameters. In this paper, we propose to perform what we call an isometrization of the distances used in the IsoMax loss. Additionally, we propose to replace the entropic score with the minimum distance score. Our experiments showed that these simple modifications increase out-of-distribution detection performance while keeping the solution seamless.
Training Aware Sigmoidal Optimizer
Feb 17, 2021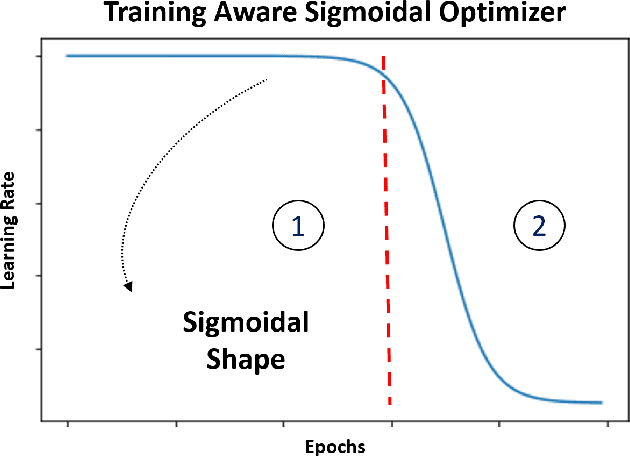

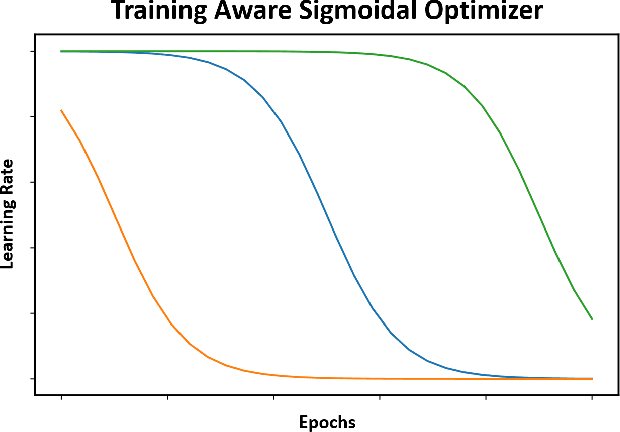
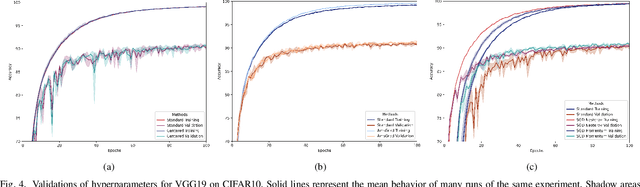
Proper optimization of deep neural networks is an open research question since an optimal procedure to change the learning rate throughout training is still unknown. Manually defining a learning rate schedule involves troublesome time-consuming try and error procedures to determine hyperparameters such as learning rate decay epochs and learning rate decay rates. Although adaptive learning rate optimizers automatize this process, recent studies suggest they may produce overffiting and reduce performance when compared to fine-tuned learning rate schedules. Considering that deep neural networks loss functions present landscapes with much more saddle points than local minima, we proposed the Training Aware Sigmoidal Optimizer (TASO), which consists of a two-phases automated learning rate schedule. The first phase uses a high learning rate to fast traverse the numerous saddle point, while the second phase uses low learning rate to slowly approach the center of the local minimum previously found. We compared the proposed approach with commonly used adaptive learning rate schedules such as Adam, RMSProp, and Adagrad. Our experiments showed that TASO outperformed all competing methods in both optimal (i.e., performing hyperparameter validation) and suboptimal (i.e., using default hyperparameters) scenarios.
KutralNet: A Portable Deep Learning Model for Fire Recognition
Aug 16, 2020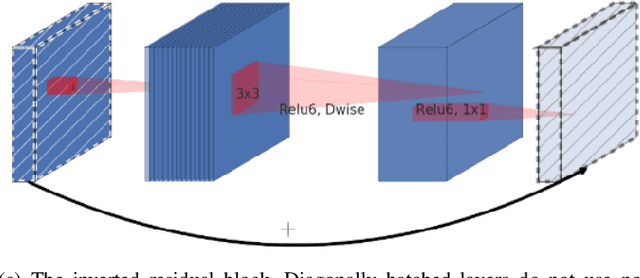
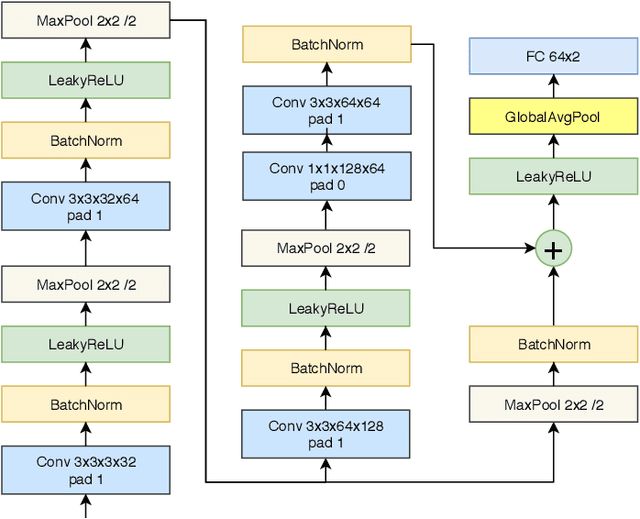
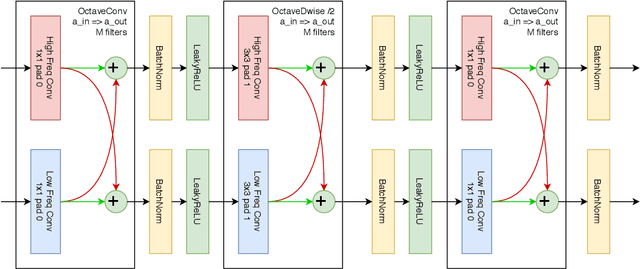
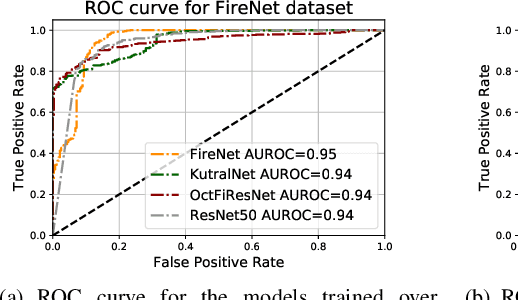
Most of the automatic fire alarm systems detect the fire presence through sensors like thermal, smoke, or flame. One of the new approaches to the problem is the use of images to perform the detection. The image approach is promising since it does not need specific sensors and can be easily embedded in different devices. However, besides the high performance, the computational cost of the used deep learning methods is a challenge to their deployment in portable devices. In this work, we propose a new deep learning architecture that requires fewer floating-point operations (flops) for fire recognition. Additionally, we propose a portable approach for fire recognition and the use of modern techniques such as inverted residual block, convolutions like depth-wise, and octave, to reduce the model's computational cost. The experiments show that our model keeps high accuracy while substantially reducing the number of parameters and flops. One of our models presents 71\% fewer parameters than FireNet, while still presenting competitive accuracy and AUROC performance. The proposed methods are evaluated on FireNet and FiSmo datasets. The obtained results are promising for the implementation of the model in a mobile device, considering the reduced number of flops and parameters acquired.
Neural Networks Out-of-Distribution Detection: Hyperparameter-Free Isotropic Maximization Loss, The Principle of Maximum Entropy, Cold Training, and Branched Inferences
Jun 07, 2020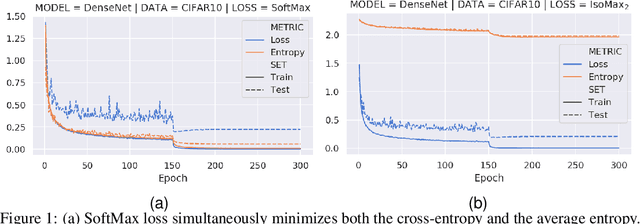
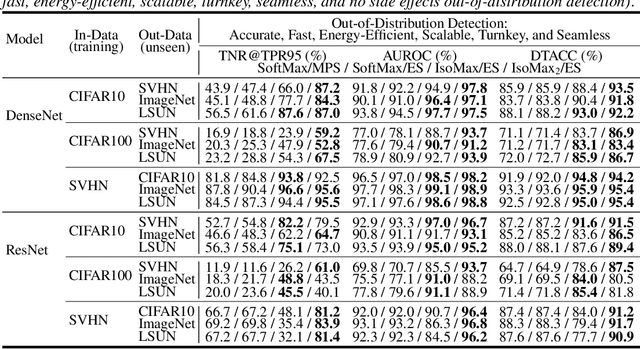
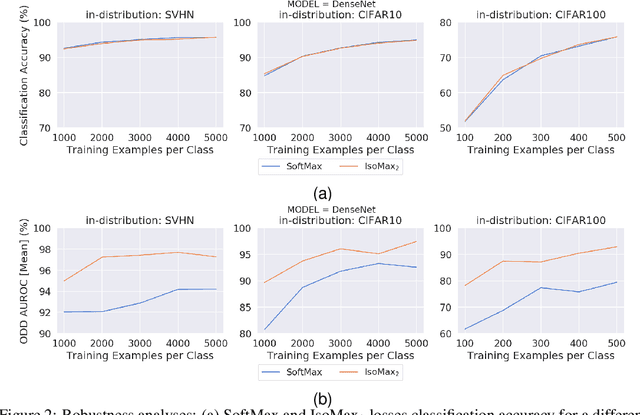
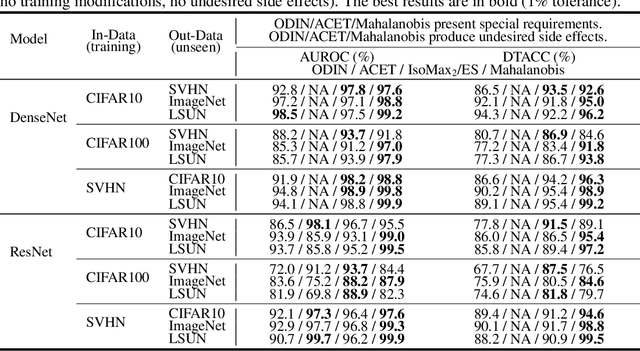
Current out-of-distribution detection (ODD) approaches present severe drawbacks that make impracticable their large scale adoption in real-world applications. In this paper, we propose a novel loss called Hyperparameter-Free IsoMax that overcomes these limitations. We modified the original IsoMax loss to improve ODD performance while maintaining benefits such as high classification accuracy, fast and energy-efficient inference, and scalability. The global hyperparameter is replaced by learnable parameters to increase performance. Additionally, a theoretical motivation to explain the high ODD performance of the proposed loss is presented. Finally, to keep high classification performance, slightly different inference mathematical expressions for classification and ODD are developed. No access to out-of-distribution samples is required, as there is no hyperparameter to tune. Our solution works as a straightforward SoftMax loss drop-in replacement that can be incorporated without relying on adversarial training or validation, model structure chances, ensembles methods, or generative approaches. The experiments showed that our approach is competitive against state-of-the-art solutions while avoiding their additional requirements and undesired side effects.
Distantly-Supervised Neural Relation Extraction with Side Information using BERT
May 10, 2020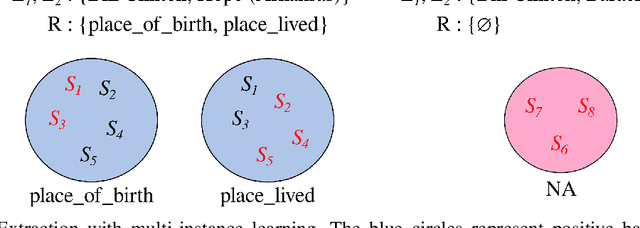
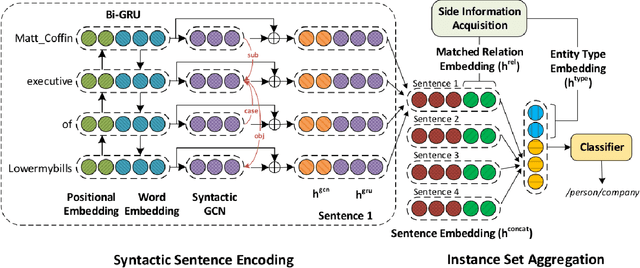
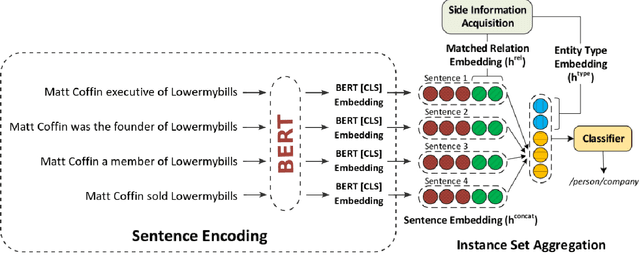
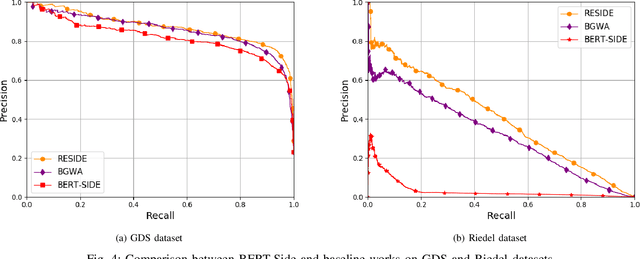
Relation extraction (RE) consists in categorizing the relationship between entities in a sentence. A recent paradigm to develop relation extractors is Distant Supervision (DS), which allows the automatic creation of new datasets by taking an alignment between a text corpus and a Knowledge Base (KB). KBs can sometimes also provide additional information to the RE task. One of the methods that adopt this strategy is the RESIDE model, which proposes a distantly-supervised neural relation extraction using side information from KBs. Considering that this method outperformed state-of-the-art baselines, in this paper, we propose a related approach to RESIDE also using additional side information, but simplifying the sentence encoding with BERT embeddings. Through experiments, we show the effectiveness of the proposed method in Google Distant Supervision and Riedel datasets concerning the BGWA and RESIDE baseline methods. Although Area Under the Curve is decreased because of unbalanced datasets, P@N results have shown that the use of BERT as sentence encoding allows superior performance to baseline methods.
A Fast Fully Octave Convolutional Neural Network for Document Image Segmentation
Apr 03, 2020



The Know Your Customer (KYC) and Anti Money Laundering (AML) are worldwide practices to online customer identification based on personal identification documents, similarity and liveness checking, and proof of address. To answer the basic regulation question: are you whom you say you are? The customer needs to upload valid identification documents (ID). This task imposes some computational challenges since these documents are diverse, may present different and complex backgrounds, some occlusion, partial rotation, poor quality, or damage. Advanced text and document segmentation algorithms were used to process the ID images. In this context, we investigated a method based on U-Net to detect the document edges and text regions in ID images. Besides the promising results on image segmentation, the U-Net based approach is computationally expensive for a real application, since the image segmentation is a customer device task. We propose a model optimization based on Octave Convolutions to qualify the method to situations where storage, processing, and time resources are limited, such as in mobile and robotic applications. We conducted the evaluation experiments in two new datasets CDPhotoDataset and DTDDataset, which are composed of real ID images of Brazilian documents. Our results showed that the proposed models are efficient to document segmentation tasks and portable.
* This paper was accepted for IJCNN 2020 Conference
AM-MobileNet1D: A Portable Model for Speaker Recognition
Mar 31, 2020



Speaker Recognition and Speaker Identification are challenging tasks with essential applications such as automation, authentication, and security. Deep learning approaches like SincNet and AM-SincNet presented great results on these tasks. The promising performance took these models to real-world applications that becoming fundamentally end-user driven and mostly mobile. The mobile computation requires applications with reduced storage size, non-processing and memory intensive and efficient energy-consuming. The deep learning approaches, in contrast, usually are energy expensive, demanding storage, processing power, and memory. To address this demand, we propose a portable model called Additive Margin MobileNet1D (AM-MobileNet1D) to Speaker Identification on mobile devices. We evaluated the proposed approach on TIMIT and MIT datasets obtaining equivalent or better performances concerning the baseline methods. Additionally, the proposed model takes only 11.6 megabytes on disk storage against 91.2 from SincNet and AM-SincNet architectures, making the model seven times faster, with eight times fewer parameters.