 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement in T-space for Faster and Distributed Training of Diffusion Models with Fewer Latent-states
Aug 20, 2025We challenge a fundamental assumption of diffusion models, namely, that a large number of latent-states or time-steps is required for training so that the reverse generative process is close to a Gaussian. We first show that with careful selection of a noise schedule, diffusion models trained over a small number of latent states (i.e. $T \sim 32$) match the performance of models trained over a much large number of latent states ($T \sim 1,000$). Second, we push this limit (on the minimum number of latent states required) to a single latent-state, which we refer to as complete disentanglement in T-space. We show that high quality samples can be easily generated by the disentangled model obtained by combining several independently trained single latent-state models. We provide extensive experiments to show that the proposed disentangled model provides 4-6$\times$ faster convergence measured across a variety of metrics on two different datasets.
Leveraging The Topological Consistencies of Learning in Deep Neural Networks
Nov 30, 2021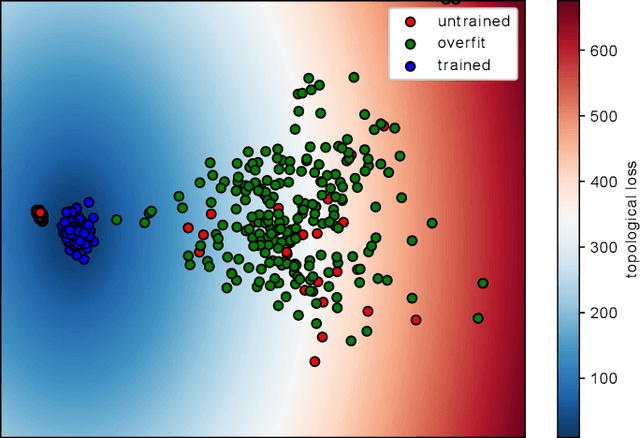

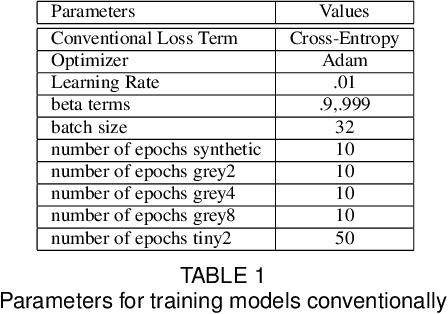
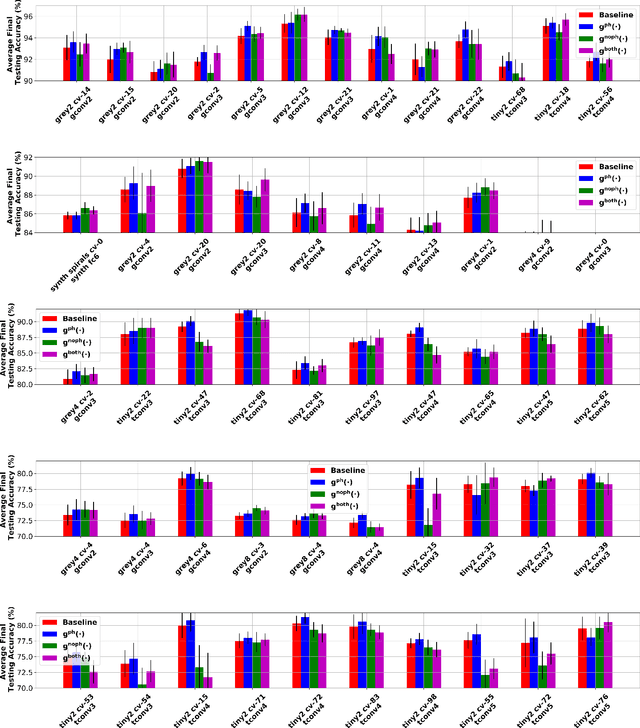
Recently, methods have been developed to accurately predict the testing performance of a Deep Neural Network (DNN) on a particular task, given statistics of its underlying topological structure. However, further leveraging this newly found insight for practical applications is intractable due to the high computational cost in terms of time and memory. In this work, we define a new class of topological features that accurately characterize the progress of learning while being quick to compute during running time. Additionally, our proposed topological features are readily equipped for backpropagation, meaning that they can be incorporated in end-to-end training. Our newly developed practical topological characterization of DNNs allows for an additional set of applications. We first show we can predict the performance of a DNN without a testing set and without the need for high-performance computing. We also demonstrate our topological characterization of DNNs is effective in estimating task similarity. Lastly, we show we can induce learning in DNNs by actively constraining the DNN's topological structure. This opens up new avenues in constricting the underlying structure of DNNs in a meta-learning framework.
Automatic selection of eye tracking variables in visual categorization in adults and infants
Oct 28, 2020



Visual categorization and learning of visual categories exhibit early onset, however the underlying mechanisms of early categorization are not well understood. The main limiting factor for examining these mechanisms is the limited duration of infant cooperation (10-15 minutes), which leaves little room for multiple test trials. With its tight link to visual attention, eye tracking is a promising method for getting access to the mechanisms of category learning. But how should researchers decide which aspects of the rich eye tracking data to focus on? To date, eye tracking variables are generally handpicked, which may lead to biases in the eye tracking data. Here, we propose an automated method for selecting eye tracking variables based on analyses of their usefulness to discriminate learners from non-learners of visual categories. We presented infants and adults with a category learning task and tracked their eye movements. We then extracted an over-complete set of eye tracking variables encompassing durations, probabilities, latencies, and the order of fixations and saccadic eye movements. We compared three statistical techniques for identifying those variables among this large set that are useful for discriminating learners form non-learners: ANOVA ranking, Bayes ranking, and L1 regularized logistic regression. We found remarkable agreement between these methods in identifying a small set of discriminant variables. Moreover, the same eye tracking variables allow us to classify category learners from non-learners among adults and 6- to 8-month-old infants with accuracies above 71%.
GANimation: Anatomically-aware Facial Animation from a Single Image
Aug 28, 2018
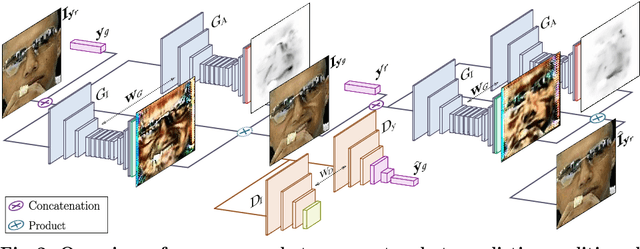
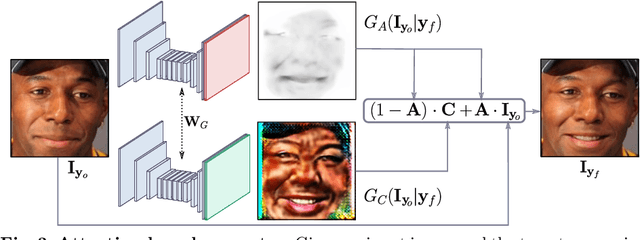

Recent advances in Generative Adversarial Networks (GANs) have shown impressive results for task of facial expression synthesis. The most successful architecture is StarGAN, that conditions GANs generation process with images of a specific domain, namely a set of images of persons sharing the same expression. While effective, this approach can only generate a discrete number of expressions, determined by the content of the dataset. To address this limitation, in this paper, we introduce a novel GAN conditioning scheme based on Action Units (AU) annotations, which describes in a continuous manifold the anatomical facial movements defining a human expression. Our approach allows controlling the magnitude of activation of each AU and combine several of them. Additionally, we propose a fully unsupervised strategy to train the model, that only requires images annotated with their activated AUs, and exploit attention mechanisms that make our network robust to changing backgrounds and lighting conditions. Extensive evaluation show that our approach goes beyond competing conditional generators both in the capability to synthesize a much wider range of expressions ruled by anatomically feasible muscle movements, as in the capacity of dealing with images in the wild.
Cross-Cultural and Cultural-Specific Production and Perception of Facial Expressions of Emotion in the Wild
Aug 13, 2018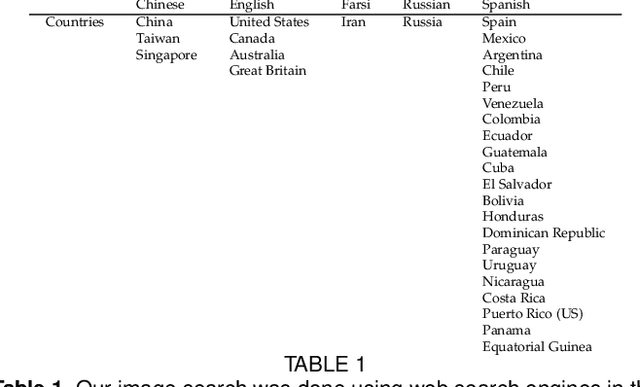
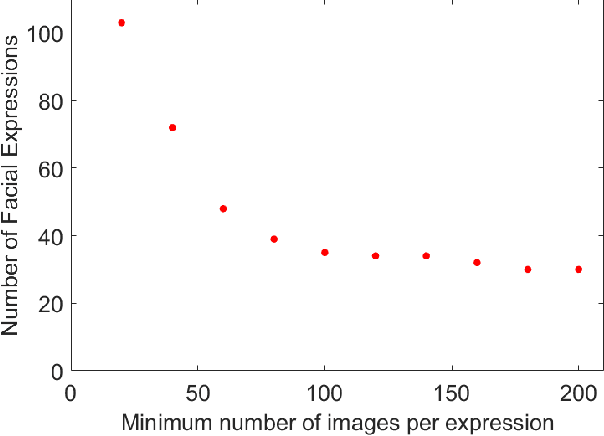

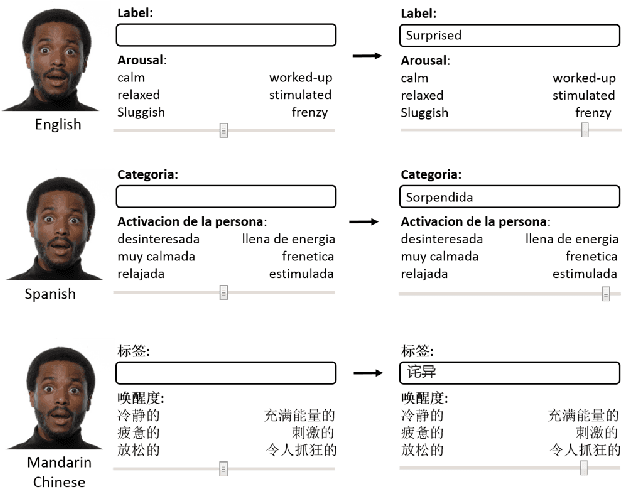
Automatic recognition of emotion from facial expressions is an intense area of research, with a potentially long list of important application. Yet, the study of emotion requires knowing which facial expressions are used within and across cultures in the wild, not in controlled lab conditions; but such studies do not exist. Which and how many cross-cultural and cultural-specific facial expressions do people commonly use? And, what affect variables does each expression communicate to observers? If we are to design technology that understands the emotion of users, we need answers to these two fundamental questions. In this paper, we present the first large-scale study of the production and visual perception of facial expressions of emotion in the wild. We find that of the 16,384 possible facial configurations that people can theoretically produce, only 35 are successfully used to transmit emotive information across cultures, and only 8 within a smaller number of cultures. Crucially, we find that visual analysis of cross-cultural expressions yields consistent perception of emotion categories and valence, but not arousal. In contrast, visual analysis of cultural-specific expressions yields consistent perception of valence and arousal, but not of emotion categories. Additionally, we find that the number of expressions used to communicate each emotion is also different, e.g., 17 expressions transmit happiness, but only 1 is used to convey disgust.
EmotioNet Challenge: Recognition of facial expressions of emotion in the wild
Mar 03, 2017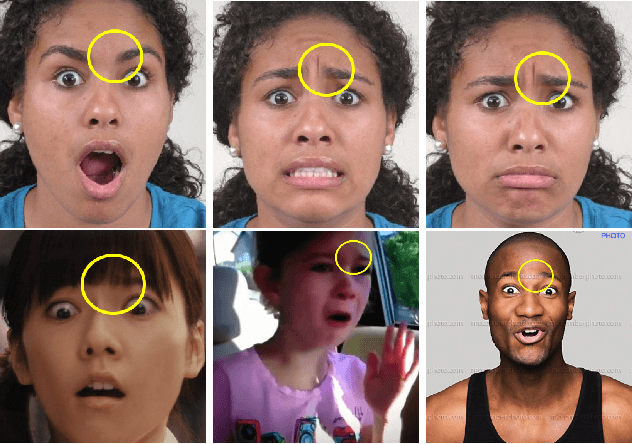
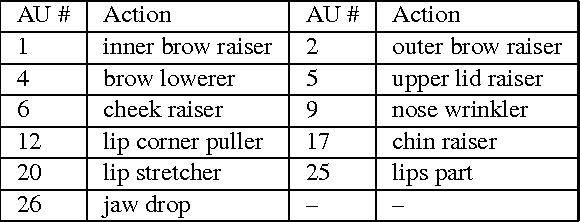
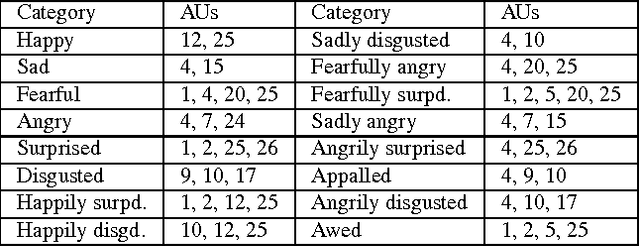

This paper details the methodology and results of the EmotioNet challenge. This challenge is the first to test the ability of computer vision algorithms in the automatic analysis of a large number of images of facial expressions of emotion in the wild. The challenge was divided into two tracks. The first track tested the ability of current computer vision algorithms in the automatic detection of action units (AUs). Specifically, we tested the detection of 11 AUs. The second track tested the algorithms' ability to recognize emotion categories in images of facial expressions. Specifically, we tested the recognition of 16 basic and compound emotion categories. The results of the challenge suggest that current computer vision and machine learning algorithms are unable to reliably solve these two tasks. The limitations of current algorithms are more apparent when trying to recognize emotion. We also show that current algorithms are not affected by mild resolution changes, small occluders, gender or age, but that 3D pose is a major limiting factor on performance. We provide an in-depth discussion of the points that need special attention moving forward.