 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Affective Behaviour Analysis Using Pretrained Model with Facial Priori
Jul 24, 2022
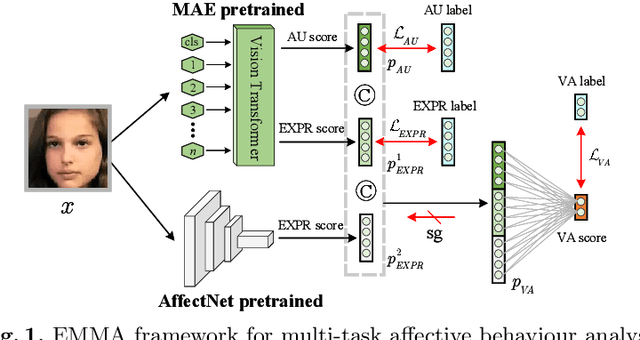
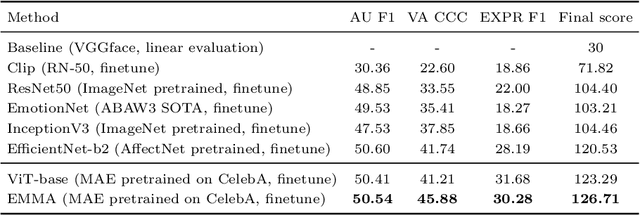
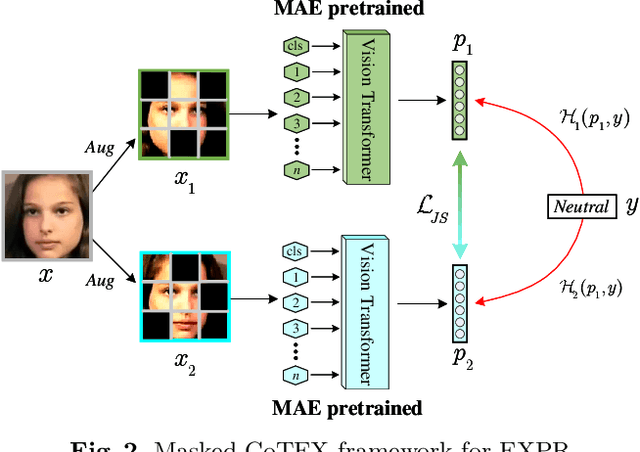

Affective behaviour analysis has aroused researchers' attention due to its broad applications. However, it is labor exhaustive to obtain accurate annotations for massive face images. Thus, we propose to utilize the prior facial information via Masked Auto-Encoder (MAE) pretrained on unlabeled face images. Furthermore, we combine MAE pretrained Vision Transformer (ViT) and AffectNet pretrained CNN to perform multi-task emotion recognition. We notice that expression and action unit (AU) scores are pure and intact features for valence-arousal (VA) regression. As a result, we utilize AffectNet pretrained CNN to extract expression scores concatenating with expression and AU scores from ViT to obtain the final VA features. Moreover, we also propose a co-training framework with two parallel MAE pretrained ViT for expression recognition tasks. In order to make the two views independent, we random mask most patches during the training process. Then, JS divergence is performed to make the predictions of the two views as consistent as possible. The results on ABAW4 show that our methods are effective.
Your "Attention" Deserves Attention: A Self-Diversified Multi-Channel Attention for Facial Action Analysis
Mar 23, 2022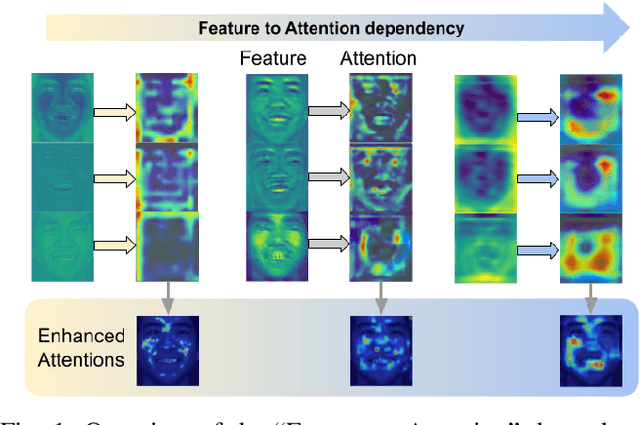
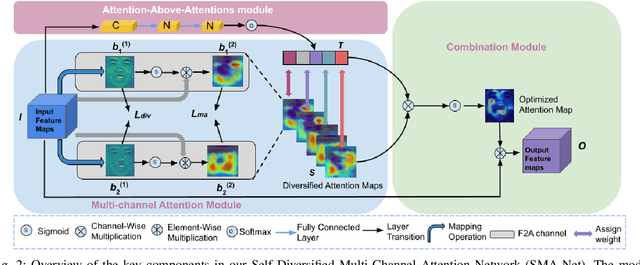
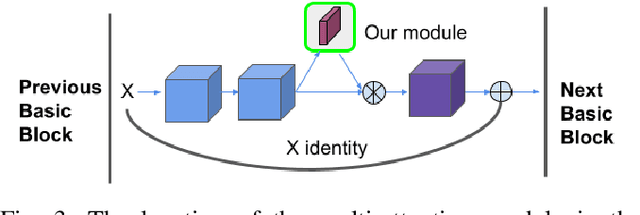
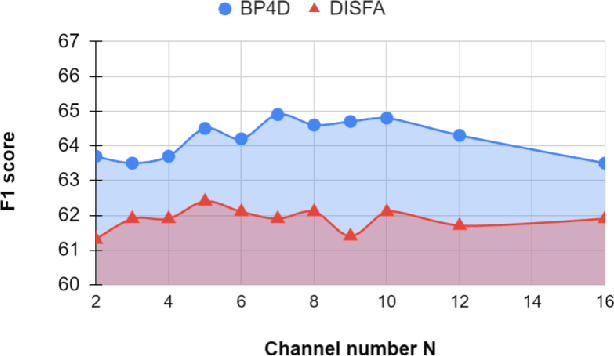
Visual attention has been extensively studied for learning fine-grained features in both facial expression recognition (FER) and Action Unit (AU) detection. A broad range of previous research has explored how to use attention modules to localize detailed facial parts (e,g. facial action units), learn discriminative features, and learn inter-class correlation. However, few related works pay attention to the robustness of the attention module itself. Through experiments, we found neural attention maps initialized with different feature maps yield diverse representations when learning to attend the identical Region of Interest (ROI). In other words, similar to general feature learning, the representational quality of attention maps also greatly affects the performance of a model, which means unconstrained attention learning has lots of randomnesses. This uncertainty lets conventional attention learning fall into sub-optimal. In this paper, we propose a compact model to enhance the representational and focusing power of neural attention maps and learn the "inter-attention" correlation for refined attention maps, which we term the "Self-Diversified Multi-Channel Attention Network (SMA-Net)". The proposed method is evaluated on two benchmark databases (BP4D and DISFA) for AU detection and four databases (CK+, MMI, BU-3DFE, and BP4D+) for facial expression recognition. It achieves superior performance compared to the state-of-the-art methods.
I am Only Happy When There is Light: The Impact of Environmental Changes on Affective Facial Expressions Recognition
Oct 28, 2022
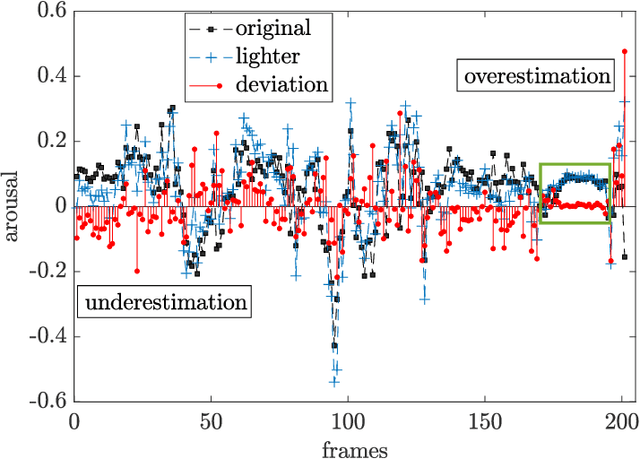
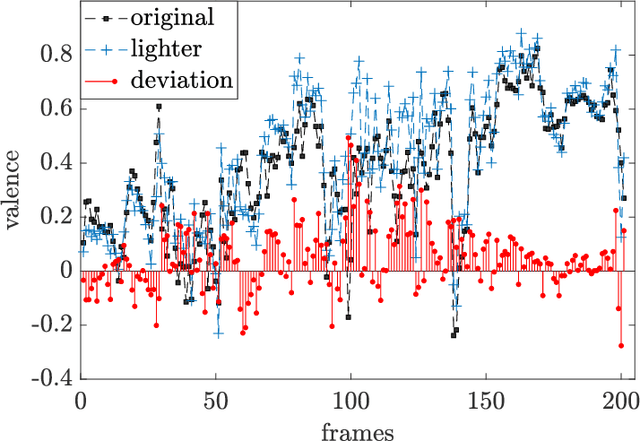
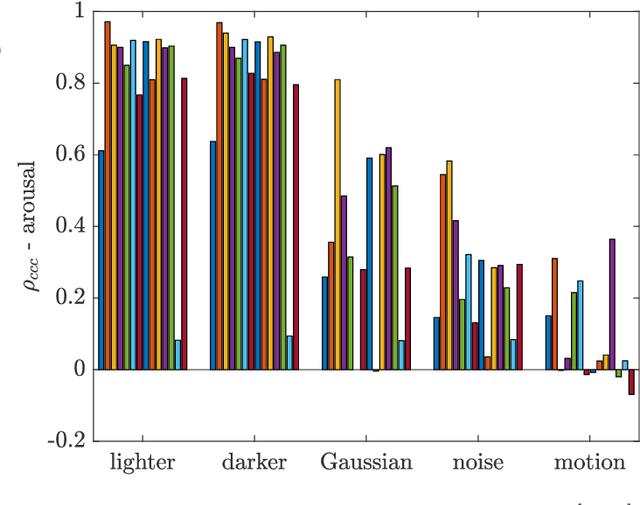
Human-robot interaction (HRI) benefits greatly from advances in the machine learning field as it allows researchers to employ high-performance models for perceptual tasks like detection and recognition. Especially deep learning models, either pre-trained for feature extraction or used for classification, are now established methods to characterize human behaviors in HRI scenarios and to have social robots that understand better those behaviors. As HRI experiments are usually small-scale and constrained to particular lab environments, the questions are how well can deep learning models generalize to specific interaction scenarios, and further, how good is their robustness towards environmental changes? These questions are important to address if the HRI field wishes to put social robotic companions into real environments acting consistently, i.e. changing lighting conditions or moving people should still produce the same recognition results. In this paper, we study the impact of different image conditions on the recognition of arousal and valence from human facial expressions using the FaceChannel framework \cite{Barro20}. Our results show how the interpretation of human affective states can differ greatly in either the positive or negative direction even when changing only slightly the image properties. We conclude the paper with important points to consider when employing deep learning models to ensure sound interpretation of HRI experiments.
Analysis of Semi-Supervised Methods for Facial Expression Recognition
Jul 31, 2022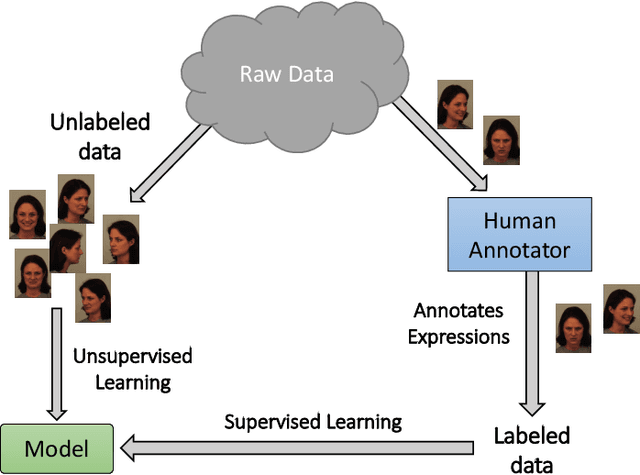
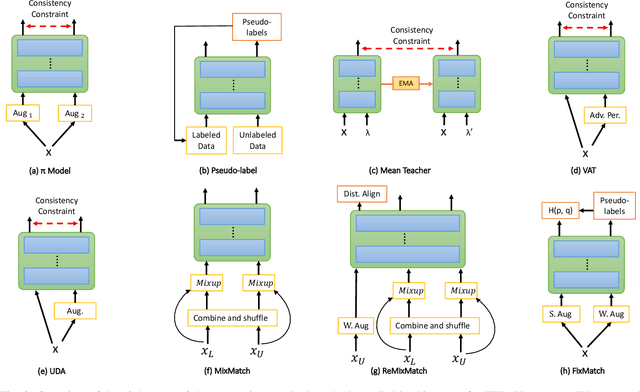


Training deep neural networks for image recognition often requires large-scale human annotated data. To reduce the reliance of deep neural solutions on labeled data, state-of-the-art semi-supervised methods have been proposed in the literature. Nonetheless, the use of such semi-supervised methods has been quite rare in the field of facial expression recognition (FER). In this paper, we present a comprehensive study on recently proposed state-of-the-art semi-supervised learning methods in the context of FER. We conduct comparative study on eight semi-supervised learning methods, namely Pi-Model, Pseudo-label, Mean-Teacher, VAT, MixMatch, ReMixMatch, UDA, and FixMatch, on three FER datasets (FER13, RAF-DB, and AffectNet), when various amounts of labeled samples are used. We also compare the performance of these methods against fully-supervised training. Our study shows that when training existing semi-supervised methods on as little as 250 labeled samples per class can yield comparable performances to that of fully-supervised methods trained on the full labeled datasets. To facilitate further research in this area, we make our code publicly available at: https://github.com/ShuvenduRoy/SSL_FER
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
Jan 12, 2023
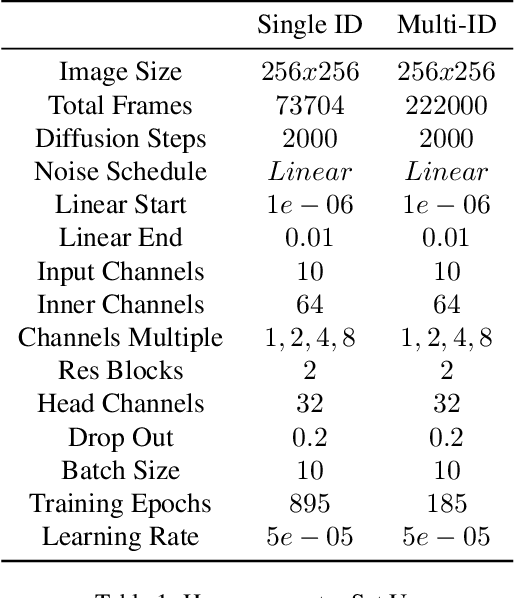
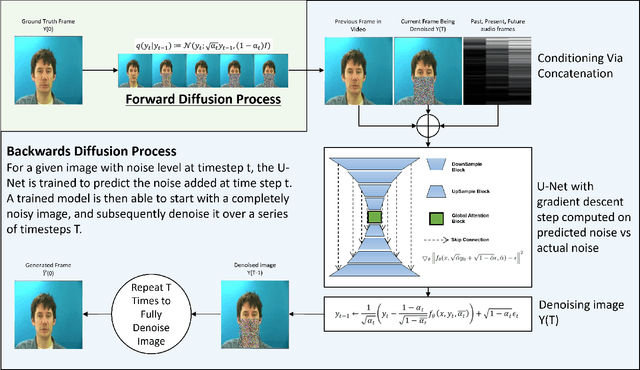
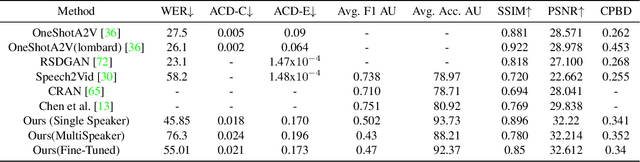
In this paper we propose a method for end-to-end speech driven video editing using a denoising diffusion model. Given a video of a person speaking, we aim to re-synchronise the lip and jaw motion of the person in response to a separate auditory speech recording without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model with audio spectral features to generate synchronised facial motion. We achieve convincing results on the task of unstructured single-speaker video editing, achieving a word error rate of 45% using an off the shelf lip reading model. We further demonstrate how our approach can be extended to the multi-speaker domain. To our knowledge, this is the first work to explore the feasibility of applying denoising diffusion models to the task of audio-driven video editing.
Facial Affect Analysis: Learning from Synthetic Data & Multi-Task Learning Challenges
Jul 20, 2022
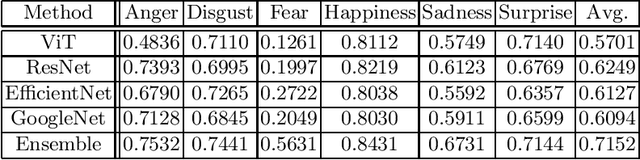
Facial affect analysis remains a challenging task with its setting transitioned from lab-controlled to in-the-wild situations. In this paper, we present novel frameworks to handle the two challenges in the 4th Affective Behavior Analysis In-The-Wild (ABAW) competition: i) Multi-Task-Learning (MTL) Challenge and ii) Learning from Synthetic Data (LSD) Challenge. For MTL challenge, we adopt the SMM-EmotionNet with a better ensemble strategy of feature vectors. For LSD challenge, we propose respective methods to combat the problems of single labels, imbalanced distribution, fine-tuning limitations, and choice of model architectures. Experimental results on the official validation sets from the competition demonstrated that our proposed approaches outperformed baselines by a large margin. The code is available at https://github.com/sylyoung/ABAW4-HUST-ANT.
LPFF: A Portrait Dataset for Face Generators Across Large Poses
Mar 25, 2023
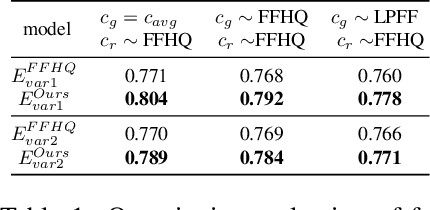

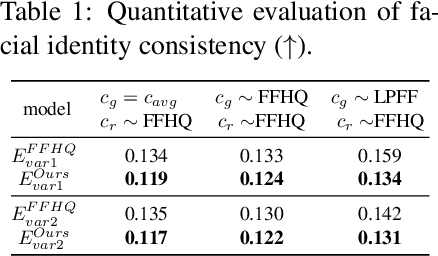
The creation of 2D realistic facial images and 3D face shapes using generative networks has been a hot topic in recent years. Existing face generators exhibit exceptional performance on faces in small to medium poses (with respect to frontal faces) but struggle to produce realistic results for large poses. The distorted rendering results on large poses in 3D-aware generators further show that the generated 3D face shapes are far from the distribution of 3D faces in reality. We find that the above issues are caused by the training dataset's pose imbalance. In this paper, we present LPFF, a large-pose Flickr face dataset comprised of 19,590 high-quality real large-pose portrait images. We utilize our dataset to train a 2D face generator that can process large-pose face images, as well as a 3D-aware generator that can generate realistic human face geometry. To better validate our pose-conditional 3D-aware generators, we develop a new FID measure to evaluate the 3D-level performance. Through this novel FID measure and other experiments, we show that LPFF can help 2D face generators extend their latent space and better manipulate the large-pose data, and help 3D-aware face generators achieve better view consistency and more realistic 3D reconstruction results.
StyleGANEX: StyleGAN-Based Manipulation Beyond Cropped Aligned Faces
Mar 10, 2023



Recent advances in face manipulation using StyleGAN have produced impressive results. However, StyleGAN is inherently limited to cropped aligned faces at a fixed image resolution it is pre-trained on. In this paper, we propose a simple and effective solution to this limitation by using dilated convolutions to rescale the receptive fields of shallow layers in StyleGAN, without altering any model parameters. This allows fixed-size small features at shallow layers to be extended into larger ones that can accommodate variable resolutions, making them more robust in characterizing unaligned faces. To enable real face inversion and manipulation, we introduce a corresponding encoder that provides the first-layer feature of the extended StyleGAN in addition to the latent style code. We validate the effectiveness of our method using unaligned face inputs of various resolutions in a diverse set of face manipulation tasks, including facial attribute editing, super-resolution, sketch/mask-to-face translation, and face toonification.
Feature Unlearning for Generative Models via Implicit Feedback
Mar 10, 2023
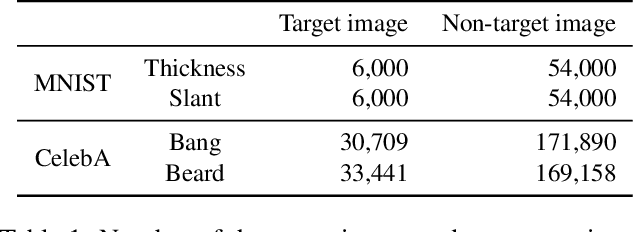
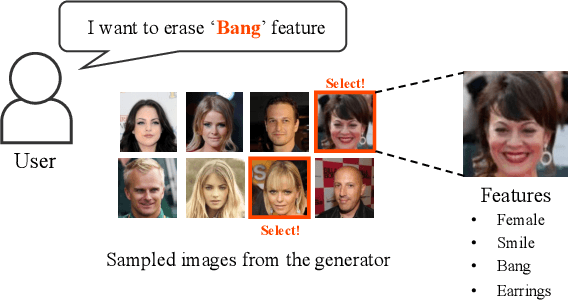
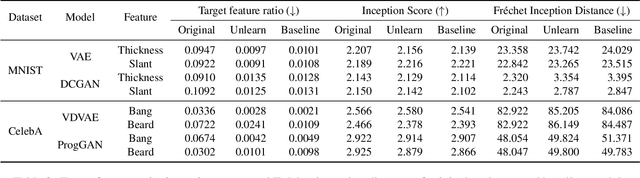
We tackle the problem of feature unlearning from a pretrained image generative model. Unlike a common unlearning task where an unlearning target is a subset of the training set, we aim to unlearn a specific feature, such as hairstyle from facial images, from the pretrained generative models. As the target feature is only presented in a local region of an image, unlearning the entire image from the pretrained model may result in losing other details in the remaining region of the image. To specify which features to unlearn, we develop an implicit feedback mechanism where a user can select images containing the target feature. From the implicit feedback, we identify a latent representation corresponding to the target feature and then use the representation to unlearn the generative model. Our framework is generalizable for the two well-known families of generative models: GANs and VAEs. Through experiments on MNIST and CelebA datasets, we show that target features are successfully removed while keeping the fidelity of the original models.
StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles
Jan 03, 2023
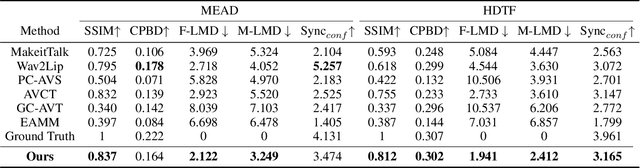
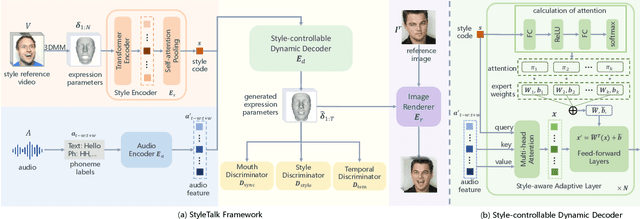
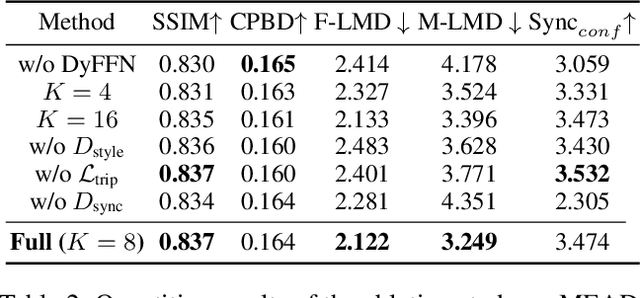
Different people speak with diverse personalized speaking styles. Although existing one-shot talking head methods have made significant progress in lip sync, natural facial expressions, and stable head motions, they still cannot generate diverse speaking styles in the final talking head videos. To tackle this problem, we propose a one-shot style-controllable talking face generation framework. In a nutshell, we aim to attain a speaking style from an arbitrary reference speaking video and then drive the one-shot portrait to speak with the reference speaking style and another piece of audio. Specifically, we first develop a style encoder to extract dynamic facial motion patterns of a style reference video and then encode them into a style code. Afterward, we introduce a style-controllable decoder to synthesize stylized facial animations from the speech content and style code. In order to integrate the reference speaking style into generated videos, we design a style-aware adaptive transformer, which enables the encoded style code to adjust the weights of the feed-forward layers accordingly. Thanks to the style-aware adaptation mechanism, the reference speaking style can be better embedded into synthesized videos during decoding. Extensive experiments demonstrate that our method is capable of generating talking head videos with diverse speaking styles from only one portrait image and an audio clip while achieving authentic visual effects. Project Page: https://github.com/FuxiVirtualHuman/styletalk.