 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-Stance: A Dyadic Multimodal Corpus for Conversational Stance Analysis
Apr 24, 2026Social interactions dominate our perceptions of the world and shape our daily behavior by attaching social meaning to acts as simple and spontaneous as gestures, facial expressions, voice, and speech. People mimic and otherwise respond to each other's postures, facial expressions, mannerisms, and other verbal and nonverbal behavior, and form appraisals or evaluations in the process. Yet, no publicly-available dataset includes multimodal recordings and self-report measures of multiple persons in social interaction. Dyadic recordings and annotation are lacking. We present a new data corpus of multimodal dyadic interaction (45 dyads, 90 persons) that includes synchronized multi-modality behavior (2D face video, 3D face geometry, thermal spectrum dynamics, voice and speech behavior, physiology (PPG, EDA, heart-rate, blood pressure, and respiration), and self-reported affect of all participants in a communicative interaction scenario. Two types of dyads are included: persons with shared past history and strangers. Annotations include social signals, agreement, disagreement, and neutral stance. With a potent emotion induction, these multimodal data will enable novel modeling of multimodal interpersonal behavior. We present extensive experiments to evaluate multimodal dyadic communication of dyads with and without interpersonal history, and their affect. This new database will make multimodal modeling of social interaction never possible before. The dataset includes 20TB of multimodal data to share with the research community.
You Only Need One Stage: Novel-View Synthesis From A Single Blind Face Image
Mar 01, 2026We propose a novel one-stage method, NVB-Face, for generating consistent Novel-View images directly from a single Blind Face image. Existing approaches to novel-view synthesis for objects or faces typically require a high-resolution RGB image as input. When dealing with degraded images, the conventional pipeline follows a two-stage process: first restoring the image to high resolution, then synthesizing novel views from the restored result. However, this approach is highly dependent on the quality of the restored image, often leading to inaccuracies and inconsistencies in the final output. To address this limitation, we extract single-view features directly from the blind face image and introduce a feature manipulator that transforms these features into 3D-aware, multi-view latent representations. Leveraging the powerful generative capacity of a diffusion model, our framework synthesizes high-quality, consistent novel-view face images. Experimental results show that our method significantly outperforms traditional two-stage approaches in both consistency and fidelity.
Weakly-Supervised Text-driven Contrastive Learning for Facial Behavior Understanding
Mar 31, 2023Contrastive learning has shown promising potential for learning robust representations by utilizing unlabeled data. However, constructing effective positive-negative pairs for contrastive learning on facial behavior datasets remains challenging. This is because such pairs inevitably encode the subject-ID information, and the randomly constructed pairs may push similar facial images away due to the limited number of subjects in facial behavior datasets. To address this issue, we propose to utilize activity descriptions, coarse-grained information provided in some datasets, which can provide high-level semantic information about the image sequences but is often neglected in previous studies. More specifically, we introduce a two-stage Contrastive Learning with Text-Embeded framework for Facial behavior understanding (CLEF). The first stage is a weakly-supervised contrastive learning method that learns representations from positive-negative pairs constructed using coarse-grained activity information. The second stage aims to train the recognition of facial expressions or facial action units by maximizing the similarity between image and the corresponding text label names. The proposed CLEF achieves state-of-the-art performance on three in-the-lab datasets for AU recognition and three in-the-wild datasets for facial expression recognition.
A Transformer-based Deep Learning Algorithm to Auto-record Undocumented Clinical One-Lung Ventilation Events
Feb 16, 2023As a team studying the predictors of complications after lung surgery, we have encountered high missingness of data on one-lung ventilation (OLV) start and end times due to high clinical workload and cognitive overload during surgery. Such missing data limit the precision and clinical applicability of our findings. We hypothesized that available intraoperative mechanical ventilation and physiological time-series data combined with other clinical events could be used to accurately predict missing start and end times of OLV. Such a predictive model can recover existing miss-documented records and relieves the documentation burden by deploying it in clinical settings. To this end, we develop a deep learning model to predict the occurrence and timing of OLV based on routinely collected intraoperative data. Our approach combines the variables' spatial and frequency domain features, using Transformer encoders to model the temporal evolution and convolutional neural network to abstract frequency-of-interest from wavelet spectrum images. The performance of the proposed method is evaluated on a benchmark dataset curated from Massachusetts General Hospital (MGH) and Brigham and Women's Hospital (BWH). Experiments show our approach outperforms baseline methods significantly and produces a satisfactory accuracy for clinical use.
Multimodal Learning with Channel-Mixing and Masked Autoencoder on Facial Action Unit Detection
Sep 25, 2022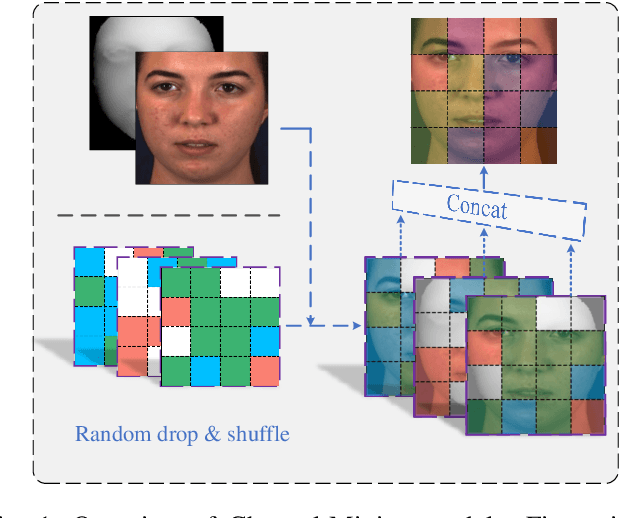
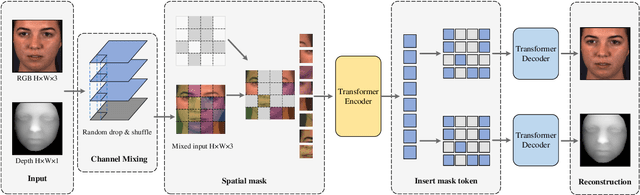
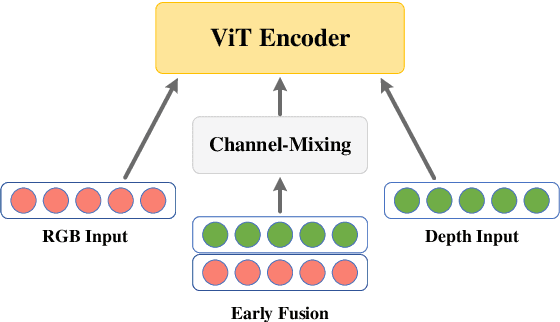

Recent studies utilizing multi-modal data aimed at building a robust model for facial Action Unit (AU) detection. However, due to the heterogeneity of multi-modal data, multi-modal representation learning becomes one of the main challenges. On one hand, it is difficult to extract the relevant features from multi-modalities by only one feature extractor, on the other hand, previous studies have not fully explored the potential of multi-modal fusion strategies. For example, early fusion usually required all modalities to be present during inference, while late fusion and middle fusion increased the network size for feature learning. In contrast to a large amount of work on late fusion, there are few works on early fusion to explore the channel information. This paper presents a novel multi-modal network called Multi-modal Channel-Mixing (MCM), as a pre-trained model to learn a robust representation in order to facilitate the multi-modal fusion. We evaluate the learned representation on a downstream task of automatic facial action units detection. Specifically, it is a single stream encoder network that uses a channel-mixing module in early fusion, requiring only one modality in the downstream detection task. We also utilize the masked ViT encoder to learn features from the fusion image and reconstruct back two modalities with two ViT decoders. We have conducted extensive experiments on two public datasets, known as BP4D and DISFA, to evaluate the effectiveness and robustness of the proposed multimodal framework. The results show our approach is comparable or superior to the state-of-the-art baseline methods.
Knowledge-Spreader: Learning Facial Action Unit Dynamics with Extremely Limited Labels
Mar 30, 2022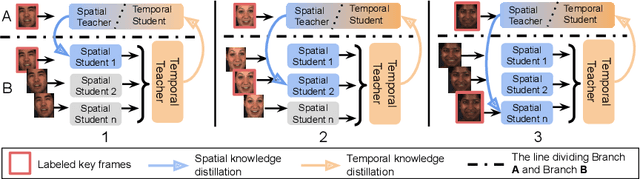
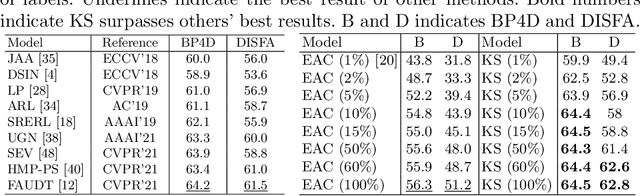
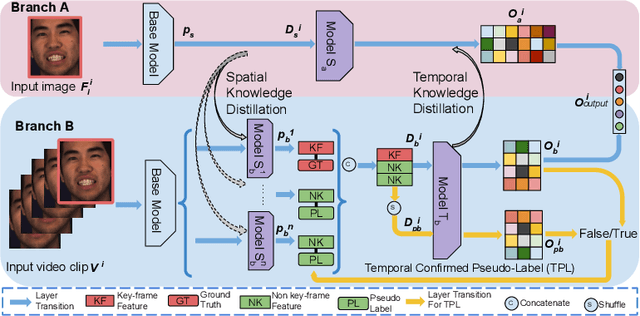

Recent studies on the automatic detection of facial action unit (AU) have extensively relied on large-sized annotations. However, manually AU labeling is difficult, time-consuming, and costly. Most existing semi-supervised works ignore the informative cues from the temporal domain, and are highly dependent on densely annotated videos, making the learning process less efficient. To alleviate these problems, we propose a deep semi-supervised framework Knowledge-Spreader (KS), which differs from conventional methods in two aspects. First, rather than only encoding human knowledge as constraints, KS also learns the Spatial-Temporal AU correlation knowledge in order to strengthen its out-of-distribution generalization ability. Second, we approach KS by applying consistency regularization and pseudo-labeling in multiple student networks alternately and dynamically. It spreads the spatial knowledge from labeled frames to unlabeled data, and completes the temporal information of partially labeled video clips. Thus, the design allows KS to learn AU dynamics from video clips with only one label allocated, which significantly reduce the requirements of using annotations. Extensive experiments demonstrate that the proposed KS achieves competitive performance as compared to the state of the arts under the circumstances of using only 2% labels on BP4D and 5% labels on DISFA. In addition, we test it on our newly developed large-scale comprehensive emotion database, which contains considerable samples across well-synchronized and aligned sensor modalities for easing the scarcity issue of annotations and identities in human affective computing. The new database will be released to the research community.
An EEG-Based Multi-Modal Emotion Database with Both Posed and Authentic Facial Actions for Emotion Analysis
Mar 29, 2022
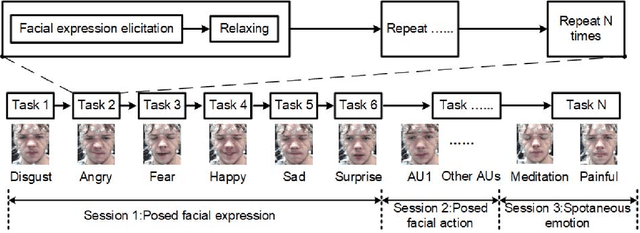
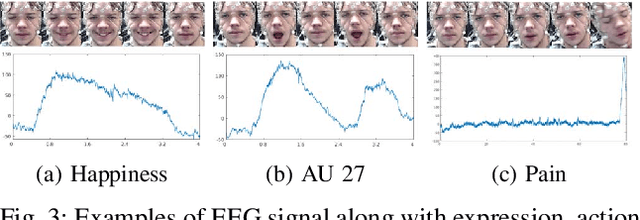
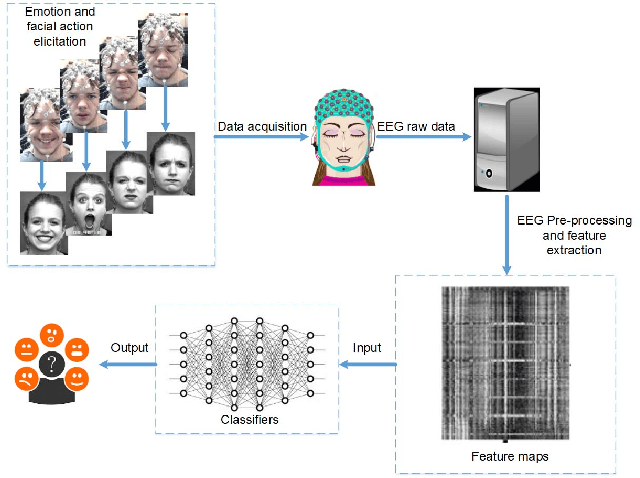
Emotion is an experience associated with a particular pattern of physiological activity along with different physiological, behavioral and cognitive changes. One behavioral change is facial expression, which has been studied extensively over the past few decades. Facial behavior varies with a person's emotion according to differences in terms of culture, personality, age, context, and environment. In recent years, physiological activities have been used to study emotional responses. A typical signal is the electroencephalogram (EEG), which measures brain activity. Most of existing EEG-based emotion analysis has overlooked the role of facial expression changes. There exits little research on the relationship between facial behavior and brain signals due to the lack of dataset measuring both EEG and facial action signals simultaneously. To address this problem, we propose to develop a new database by collecting facial expressions, action units, and EEGs simultaneously. We recorded the EEGs and face videos of both posed facial actions and spontaneous expressions from 29 participants with different ages, genders, ethnic backgrounds. Differing from existing approaches, we designed a protocol to capture the EEG signals by evoking participants' individual action units explicitly. We also investigated the relation between the EEG signals and facial action units. As a baseline, the database has been evaluated through the experiments on both posed and spontaneous emotion recognition with images alone, EEG alone, and EEG fused with images, respectively. The database will be released to the research community to advance the state of the art for automatic emotion recognition.
Your "Attention" Deserves Attention: A Self-Diversified Multi-Channel Attention for Facial Action Analysis
Mar 23, 2022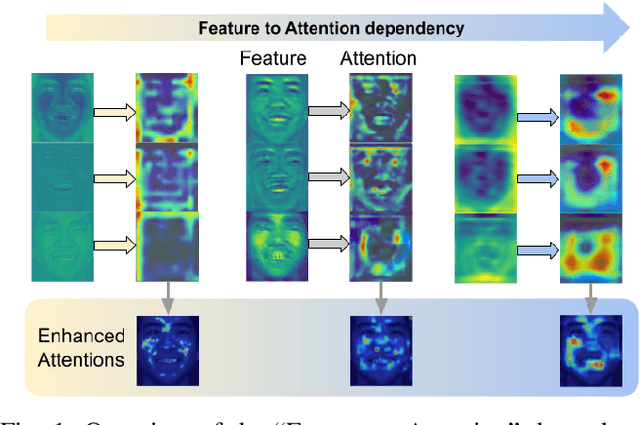
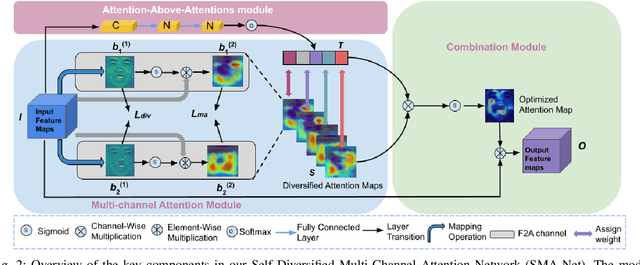
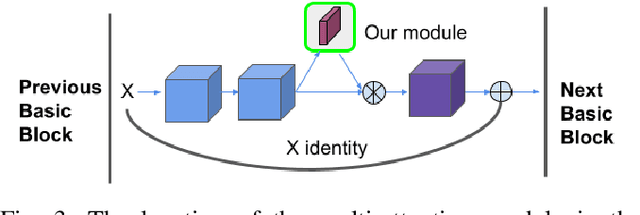
Visual attention has been extensively studied for learning fine-grained features in both facial expression recognition (FER) and Action Unit (AU) detection. A broad range of previous research has explored how to use attention modules to localize detailed facial parts (e,g. facial action units), learn discriminative features, and learn inter-class correlation. However, few related works pay attention to the robustness of the attention module itself. Through experiments, we found neural attention maps initialized with different feature maps yield diverse representations when learning to attend the identical Region of Interest (ROI). In other words, similar to general feature learning, the representational quality of attention maps also greatly affects the performance of a model, which means unconstrained attention learning has lots of randomnesses. This uncertainty lets conventional attention learning fall into sub-optimal. In this paper, we propose a compact model to enhance the representational and focusing power of neural attention maps and learn the "inter-attention" correlation for refined attention maps, which we term the "Self-Diversified Multi-Channel Attention Network (SMA-Net)". The proposed method is evaluated on two benchmark databases (BP4D and DISFA) for AU detection and four databases (CK+, MMI, BU-3DFE, and BP4D+) for facial expression recognition. It achieves superior performance compared to the state-of-the-art methods.
Multi-Modal Learning for AU Detection Based on Multi-Head Fused Transformers
Mar 22, 2022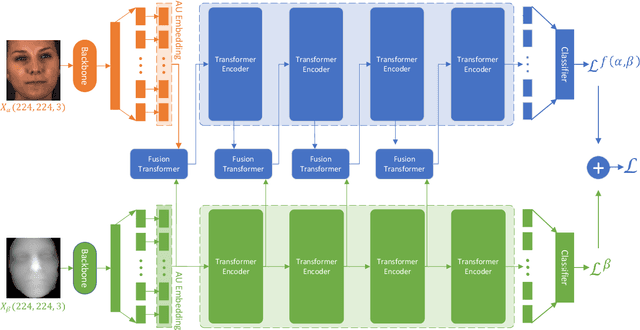
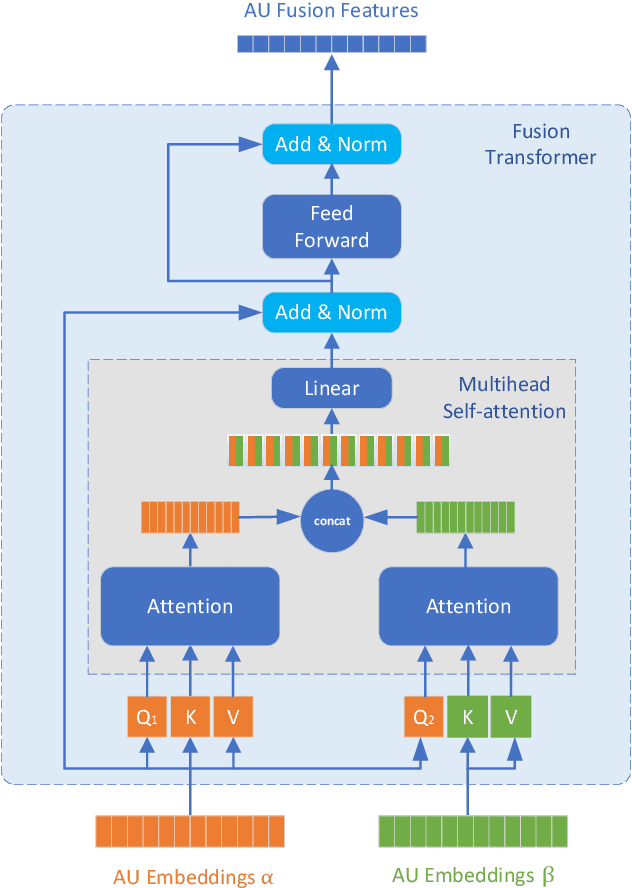
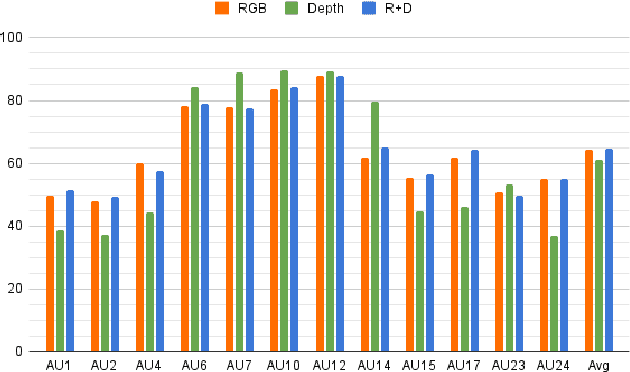
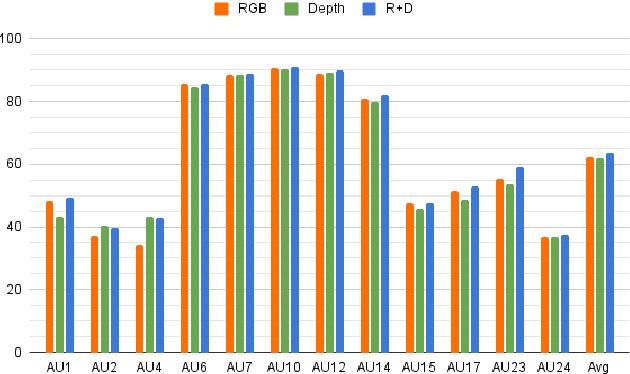
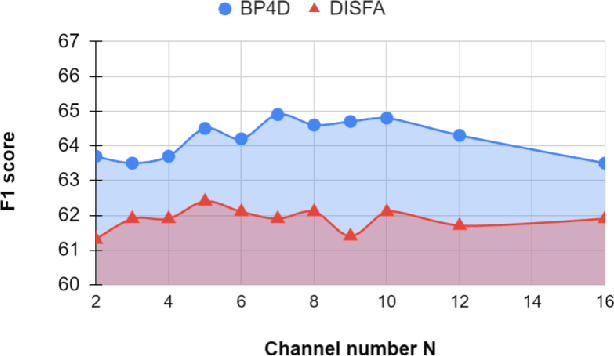
Multi-modal learning has been intensified in recent years, especially for applications in facial analysis and action unit detection whilst there still exist two main challenges in terms of 1) relevant feature learning for representation and 2) efficient fusion for multi-modalities. Recently, there are a number of works have shown the effectiveness in utilizing the attention mechanism for AU detection, however, most of them are binding the region of interest (ROI) with features but rarely apply attention between features of each AU. On the other hand, the transformer, which utilizes a more efficient self-attention mechanism, has been widely used in natural language processing and computer vision tasks but is not fully explored in AU detection tasks. In this paper, we propose a novel end-to-end Multi-Head Fused Transformer (MFT) method for AU detection, which learns AU encoding features representation from different modalities by transformer encoder and fuses modalities by another fusion transformer module. Multi-head fusion attention is designed in the fusion transformer module for the effective fusion of multiple modalities. Our approach is evaluated on two public multi-modal AU databases, BP4D, and BP4D+, and the results are superior to the state-of-the-art algorithms and baseline models. We further analyze the performance of AU detection from different modalities.
The First Vision For Vitals Challenge for Non-Contact Video-Based Physiological Estimation
Sep 22, 2021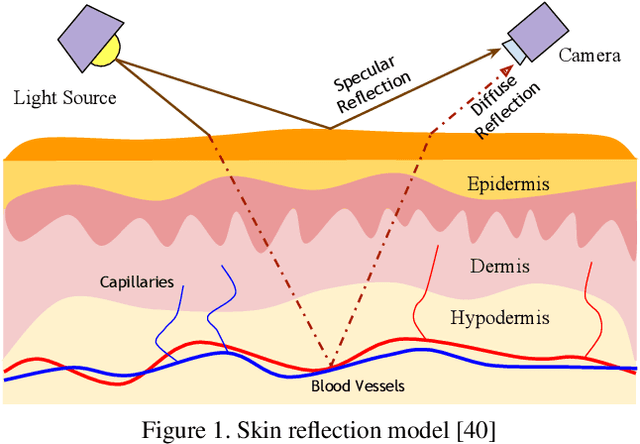
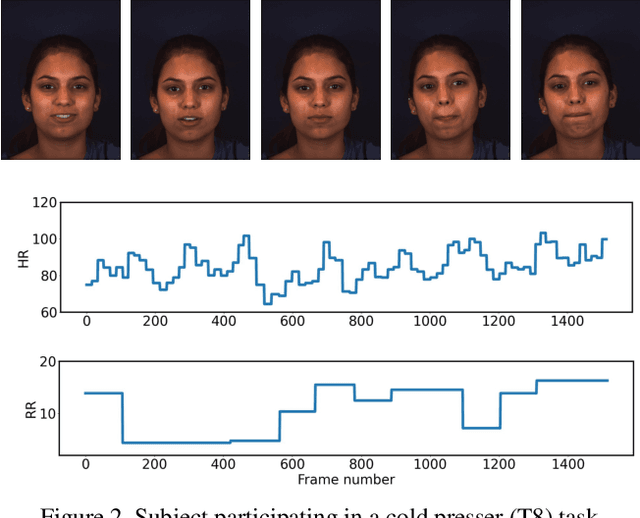
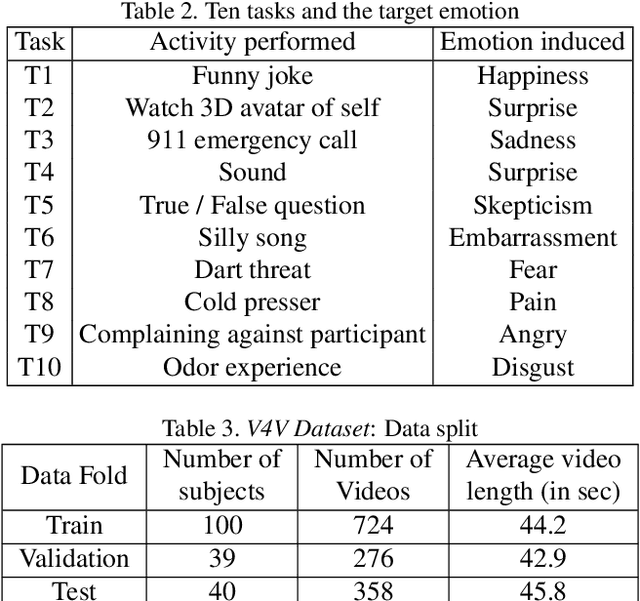
Telehealth has the potential to offset the high demand for help during public health emergencies, such as the COVID-19 pandemic. Remote Photoplethysmography (rPPG) - the problem of non-invasively estimating blood volume variations in the microvascular tissue from video - would be well suited for these situations. Over the past few years a number of research groups have made rapid advances in remote PPG methods for estimating heart rate from digital video and obtained impressive results. How these various methods compare in naturalistic conditions, where spontaneous behavior, facial expressions, and illumination changes are present, is relatively unknown. To enable comparisons among alternative methods, the 1st Vision for Vitals Challenge (V4V) presented a novel dataset containing high-resolution videos time-locked with varied physiological signals from a diverse population. In this paper, we outline the evaluation protocol, the data used, and the results. V4V is to be held in conjunction with the 2021 International Conference on Computer Vision.