 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable and Independent Learning of Nash Equilibrium Policies in $n$-Player Stochastic Games with Unknown Independent Chains
Dec 04, 2023

We study a subclass of $n$-player stochastic games, namely, stochastic games with independent chains and unknown transition matrices. In this class of games, players control their own internal Markov chains whose transitions do not depend on the states/actions of other players. However, players' decisions are coupled through their payoff functions. We assume players can receive only realizations of their payoffs, and that the players can not observe the states and actions of other players, nor do they know the transition probability matrices of their own Markov chain. Relying on a compact dual formulation of the game based on occupancy measures and the technique of confidence set to maintain high-probability estimates of the unknown transition matrices, we propose a fully decentralized mirror descent algorithm to learn an $\epsilon$-NE for this class of games. The proposed algorithm has the desired properties of independence, scalability, and convergence. Specifically, under no assumptions on the reward functions, we show the proposed algorithm converges in polynomial time in a weaker distance (namely, the averaged Nikaido-Isoda gap) to the set of $\epsilon$-NE policies with arbitrarily high probability. Moreover, assuming the existence of a variationally stable Nash equilibrium policy, we show that the proposed algorithm converges asymptotically to the stable $\epsilon$-NE policy with arbitrarily high probability. In addition to Markov potential games and linear-quadratic stochastic games, this work provides another subclass of $n$-player stochastic games that, under some mild assumptions, admit polynomial-time learning algorithms for finding their stationary $\epsilon$-NE policies.
Label Delay in Continual Learning
Dec 01, 2023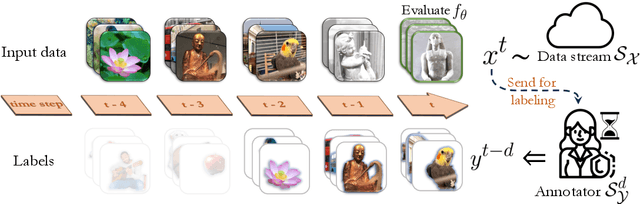
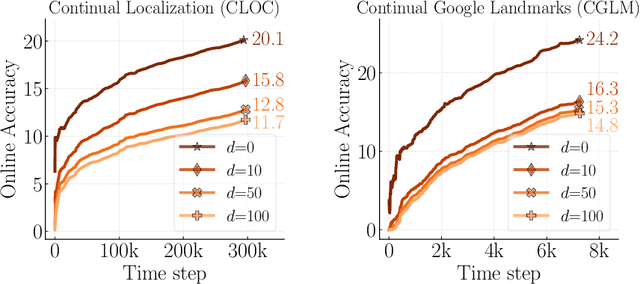
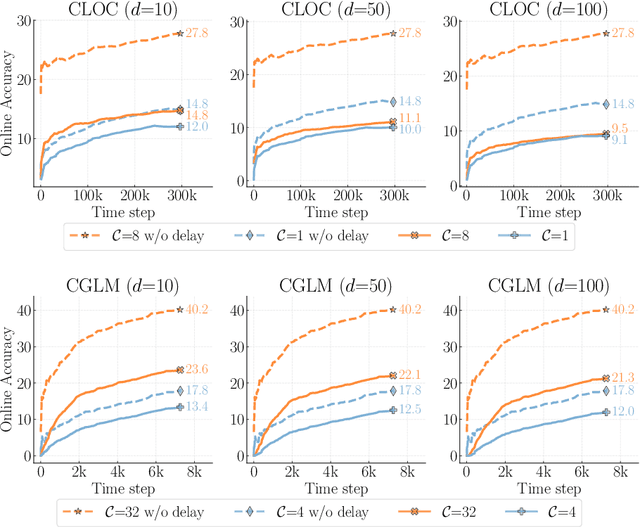
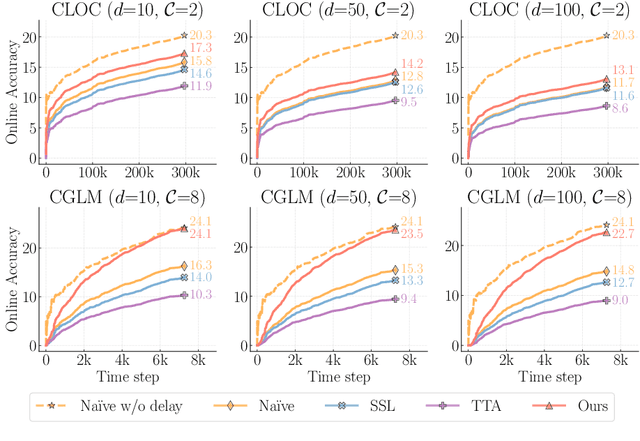
Online continual learning, the process of training models on streaming data, has gained increasing attention in recent years. However, a critical aspect often overlooked is the label delay, where new data may not be labeled due to slow and costly annotation processes. We introduce a new continual learning framework with explicit modeling of the label delay between data and label streams over time steps. In each step, the framework reveals both unlabeled data from the current time step $t$ and labels delayed with $d$ steps, from the time step $t-d$. In our extensive experiments amounting to 1060 GPU days, we show that merely augmenting the computational resources is insufficient to tackle this challenge. Our findings underline a notable performance decline when solely relying on labeled data when the label delay becomes significant. More surprisingly, when using state-of-the-art SSL and TTA techniques to utilize the newer, unlabeled data, they fail to surpass the performance of a na\"ive method that simply trains on the delayed supervised stream. To this end, we introduce a simple, efficient baseline that rehearses from the labeled memory samples that are most similar to the new unlabeled samples. This method bridges the accuracy gap caused by label delay without significantly increasing computational complexity. We show experimentally that our method is the least affected by the label delay factor and in some cases successfully recovers the accuracy of the non-delayed counterpart. We conduct various ablations and sensitivity experiments, demonstrating the effectiveness of our approach.
CityTFT: Temporal Fusion Transformer for Urban Building Energy Modeling
Dec 04, 2023Urban Building Energy Modeling (UBEM) is an emerging method to investigate urban design and energy systems against the increasing energy demand at urban and neighborhood levels. However, current UBEM methods are mostly physic-based and time-consuming in multiple climate change scenarios. This work proposes CityTFT, a data-driven UBEM framework, to accurately model the energy demands in urban environments. With the empowerment of the underlying TFT framework and an augmented loss function, CityTFT could predict heating and cooling triggers in unseen climate dynamics with an F1 score of 99.98 \% while RMSE of loads of 13.57 kWh.
HoVer-UNet: Accelerating HoVerNet with UNet-based multi-class nuclei segmentation via knowledge distillation
Dec 04, 2023We present HoVer-UNet, an approach to distill the knowledge of the multi-branch HoVerNet framework for nuclei instance segmentation and classification in histopathology. We propose a compact, streamlined single UNet network with a Mix Vision Transformer backbone, and equip it with a custom loss function to optimally encode the distilled knowledge of HoVerNet, reducing computational requirements without compromising performances. We show that our model achieved results comparable to HoVerNet on the public PanNuke and Consep datasets with a three-fold reduction in inference time. We make the code of our model publicly available at https://github.com/DIAGNijmegen/HoVer-UNet.
Spatio-Temporal-Decoupled Masked Pre-training for Traffic Forecasting
Dec 01, 2023Accurate forecasting of multivariate traffic flow time series remains challenging due to substantial spatio-temporal heterogeneity and complex long-range correlative patterns. To address this, we propose Spatio-Temporal-Decoupled Masked Pre-training (STD-MAE), a novel framework that employs masked autoencoders to learn and encode complex spatio-temporal dependencies via pre-training. Specifically, we use two decoupled masked autoencoders to reconstruct the traffic data along spatial and temporal axes using a self-supervised pre-training approach. These mask reconstruction mechanisms capture the long-range correlations in space and time separately. The learned hidden representations are then used to augment the downstream spatio-temporal traffic predictor. A series of quantitative and qualitative evaluations on four widely-used traffic benchmarks (PEMS03, PEMS04, PEMS07, and PEMS08) are conducted to verify the state-of-the-art performance, with STD-MAE explicitly enhancing the downstream spatio-temporal models' ability to capture long-range intricate spatial and temporal patterns. Codes are available at https://github.com/Jimmy-7664/STD_MAE.
RoboSync: OS for Social Robots with Customizable Behaviour
Dec 01, 2023Traditional robotic systems require complex implementations that are not always accessible or easy to use for Human-Robot Interaction (HRI) application developers. With the aim of simplifying the implementation of HRI applications, this paper introduces a novel real-time operating system (RTOS) designed for customizable HRI - RoboSync. By creating multi-level abstraction layers, the system enables users to define complex emotional and behavioral models without needing deep technical expertise. The system's modular architecture comprises a behavior modeling layer, a machine learning plugin configuration layer, a sensor checks customization layer, a scheduler that fits the need of HRI, and a communication and synchronization layer. This approach not only promotes ease of use without highly specialized skills but also ensures real-time responsiveness and adaptability. The primary functionality of the RTOS has been implemented for proof of concept and was tested on a CortexM4 microcontroller, demonstrating its potential for a wide range of lightweight simple-to-implement social robotics applications.
VREM-FL: Mobility-Aware Computation-Scheduling Co-Design for Vehicular Federated Learning
Nov 30, 2023Assisted and autonomous driving are rapidly gaining momentum, and will soon become a reality. Among their key enablers, artificial intelligence and machine learning are expected to play a prominent role, also thanks to the massive amount of data that smart vehicles will collect from their onboard sensors. In this domain, federated learning is one of the most effective and promising techniques for training global machine learning models, while preserving data privacy at the vehicles and optimizing communications resource usage. In this work, we propose VREM-FL, a computation-scheduling co-design for vehicular federated learning that leverages mobility of vehicles in conjunction with estimated 5G radio environment maps. VREM-FL jointly optimizes the global model learned at the server while wisely allocating communication resources. This is achieved by orchestrating local computations at the vehicles in conjunction with the transmission of their local model updates in an adaptive and predictive fashion, by exploiting radio channel maps. The proposed algorithm can be tuned to trade model training time for radio resource usage. Experimental results demonstrate the efficacy of utilizing radio maps. VREM-FL outperforms literature benchmarks for both a linear regression model (learning time reduced by 28%) and a deep neural network for a semantic image segmentation task (doubling the number of model updates within the same time window).
A Semi-Supervised Deep Learning Approach to Dataset Collection for Query-By-Humming Task
Dec 02, 2023Query-by-Humming (QbH) is a task that involves finding the most relevant song based on a hummed or sung fragment. Despite recent successful commercial solutions, implementing QbH systems remains challenging due to the lack of high-quality datasets for training machine learning models. In this paper, we propose a deep learning data collection technique and introduce Covers and Hummings Aligned Dataset (CHAD), a novel dataset that contains 18 hours of short music fragments, paired with time-aligned hummed versions. To expand our dataset, we employ a semi-supervised model training pipeline that leverages the QbH task as a specialized case of cover song identification (CSI) task. Starting with a model trained on the initial dataset, we iteratively collect groups of fragments of cover versions of the same song and retrain the model on the extended data. Using this pipeline, we collect over 308 hours of additional music fragments, paired with time-aligned cover versions. The final model is successfully applied to the QbH task and achieves competitive results on benchmark datasets. Our study shows that the proposed dataset and training pipeline can effectively facilitate the implementation of QbH systems.
FOCAL: Contrastive Learning for Multimodal Time-Series Sensing Signals in Factorized Orthogonal Latent Space
Oct 30, 2023This paper proposes a novel contrastive learning framework, called FOCAL, for extracting comprehensive features from multimodal time-series sensing signals through self-supervised training. Existing multimodal contrastive frameworks mostly rely on the shared information between sensory modalities, but do not explicitly consider the exclusive modality information that could be critical to understanding the underlying sensing physics. Besides, contrastive frameworks for time series have not handled the temporal information locality appropriately. FOCAL solves these challenges by making the following contributions: First, given multimodal time series, it encodes each modality into a factorized latent space consisting of shared features and private features that are orthogonal to each other. The shared space emphasizes feature patterns consistent across sensory modalities through a modal-matching objective. In contrast, the private space extracts modality-exclusive information through a transformation-invariant objective. Second, we propose a temporal structural constraint for modality features, such that the average distance between temporally neighboring samples is no larger than that of temporally distant samples. Extensive evaluations are performed on four multimodal sensing datasets with two backbone encoders and two classifiers to demonstrate the superiority of FOCAL. It consistently outperforms the state-of-the-art baselines in downstream tasks with a clear margin, under different ratios of available labels. The code and self-collected dataset are available at https://github.com/tomoyoshki/focal.
TiV-NeRF: Tracking and Mapping via Time-Varying Representation with Dynamic Neural Radiance Fields
Oct 29, 2023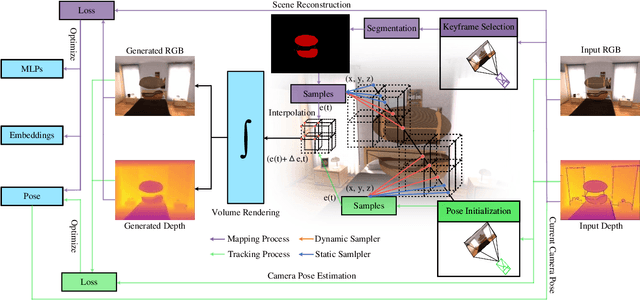
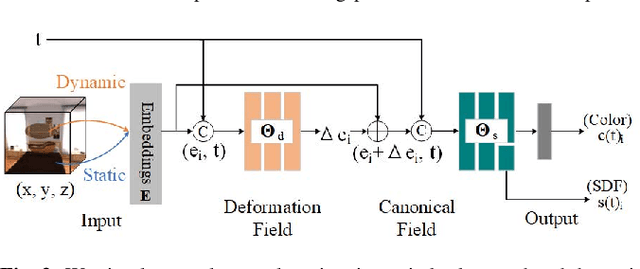


Previous attempts to integrate Neural Radiance Fields (NeRF) into Simultaneous Localization and Mapping (SLAM) framework either rely on the assumption of static scenes or treat dynamic objects as outliers. However, most of real-world scenarios is dynamic. In this paper, we propose a time-varying representation to track and reconstruct the dynamic scenes. Our system simultaneously maintains two processes, tracking process and mapping process. For tracking process, the entire input images are uniformly sampled and training of the RGB images are self-supervised. For mapping process, we leverage know masks to differentiate dynamic objects and static backgrounds, and we apply distinct sampling strategies for two types of areas. The parameters optimization for both processes are made up by two stages, the first stage associates time with 3D positions to convert the deformation field to the canonical field. And the second associates time with 3D positions in canonical field to obtain colors and Signed Distance Function (SDF). Besides, We propose a novel keyframe selection strategy based on the overlapping rate. We evaluate our approach on two publicly available synthetic datasets and validate that our method is more effective compared to current state-of-the-art dynamic mapping methods.