 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEPTQ: A Simple and Effective Post-Training Quantization Paradigm for Large Language Models
Apr 11, 2026Large language models (LLMs) have shown remarkable performance in various domains, but they are constrained by massive computational and storage costs. Quantization, an effective technique for compressing models to fit resource-limited devices while preserving generative quality, encompasses two primary methods: quantization aware training (QAT) and post-training quantization (PTQ). QAT involves additional retraining or fine-tuning, thus inevitably resulting in high training cost and making it unsuitable for LLMs. Consequently, PTQ has become the research hotspot in recent quantization methods. However, existing PTQ methods usually rely on various complex computation procedures and suffer from considerable performance degradation under low-bit quantization settings. To alleviate the above issues, we propose a simple and effective post-training quantization paradigm for LLMs, named SEPTQ. Specifically, SEPTQ first calculates the importance score for each element in the weight matrix and determines the quantization locations in a static global manner. Then it utilizes the mask matrix which represents the important locations to quantize and update the associated weights column-by-column until the appropriate quantized weight matrix is obtained. Compared with previous methods, SEPTQ simplifies the post-training quantization procedure into only two steps, and considers the effectiveness and efficiency simultaneously. Experimental results on various datasets across a suite of models ranging from millions to billions in different quantization bit-levels demonstrate that SEPTQ significantly outperforms other strong baselines, especially in low-bit quantization scenarios.
RUQuant: Towards Refining Uniform Quantization for Large Language Models
Apr 05, 2026The increasing size and complexity of large language models (LLMs) have raised significant challenges in deployment efficiency, particularly under resource constraints. Post-training quantization (PTQ) has emerged as a practical solution by compressing models without requiring retraining. While existing methods focus on uniform quantization schemes for both weights and activations, they often suffer from substantial accuracy degradation due to the non-uniform nature of activation distributions. In this work, we revisit the activation quantization problem from a theoretical perspective grounded in the Lloyd-Max optimality conditions. We identify the core issue as the non-uniform distribution of activations within the quantization interval, which causes the optimal quantization point under the Lloyd-Max criterion to shift away from the midpoint of the interval. To address this issue, we propose a two-stage orthogonal transformation method, RUQuant. In the first stage, activations are divided into blocks. Each block is mapped to uniformly sampled target vectors using composite orthogonal matrices, which are constructed from Householder reflections and Givens rotations. In the second stage, a global Householder reflection is fine-tuned to further minimize quantization error using Transformer output discrepancies. Empirical results show that our method achieves near-optimal quantization performance without requiring model fine-tuning: RUQuant achieves 99.8% of full-precision accuracy with W6A6 and 97% with W4A4 quantization for a 13B LLM, within approximately one minute. A fine-tuned variant yields even higher accuracy, demonstrating the effectiveness and scalability of our approach.
Towards Effective Orchestration of AI x DB Workloads
Mar 04, 2026AI-driven analytics are increasingly crucial to data-centric decision-making. The practice of exporting data to machine learning runtimes incurs high overhead, limits robustness to data drift, and expands the attack surface, especially in multi-tenant, heterogeneous data systems. Integrating AI directly into database engines, while offering clear benefits, introduces challenges in managing joint query processing and model execution, optimizing end-to-end performance, coordinating execution under resource contention, and enforcing strong security and access-control guarantees. This paper discusses the challenges of joint DB-AI, or AIxDB, data management and query processing within AI-powered data systems. It presents various challenges that need to be addressed carefully, such as query optimization, execution scheduling, and distributed execution over heterogeneous hardware. Database components such as transaction management and access control need to be re-examined to support AI lifecycle management, mitigate data drift, and protect sensitive data from unauthorized AI operations. We present a design and preliminary results to demonstrate what may be key to the performance for serving AIxDB queries.
PLANET v2.0: A comprehensive Protein-Ligand Affinity Prediction Model Based on Mixture Density Network
Jan 12, 2026Drug discovery represents a time-consuming and financially intensive process, and virtual screening can accelerate it. Scoring functions, as one of the tools guiding virtual screening, have their precision closely tied to screening efficiency. In our previous study, we developed a graph neural network model called PLANET (Protein-Ligand Affinity prediction NETwork), but it suffers from the defect in representing protein-ligand contact maps. Incorrect binding modes inevitably lead to poor affinity predictions, so accurate prediction of the protein-ligand contact map is desired to improve PLANET. In this study, we have proposed PLANET v2.0 as an upgraded version. The model is trained via multi-objective training strategy and incorporates the Mixture Density Network to predict binding modes. Except for the probability density distributions of non-covalent interactions, we innovatively employ another Gaussian mixture model to describe the relationship between distance and energy of each interaction pair and predict protein-ligand affinity like calculating the mathematical expectation. As on the CASF-2016 benchmark, PLANET v2.0 demonstrates excellent scoring power, ranking power, and docking power. The screening power of PLANET v2.0 gets notably improved compared to PLANET and Glide SP and it demonstrates robust validation on a commercial ultra-large-scale dataset. Given its efficiency and accuracy, PLANET v2.0 can hopefully become one of the practical tools for virtual screening workflows. PLANET v2.0 is freely available at https://www.pdbbind-plus.org.cn/planetv2.
How Different from the Past? Spatio-Temporal Time Series Forecasting with Self-Supervised Deviation Learning
Oct 06, 2025



Spatio-temporal forecasting is essential for real-world applications such as traffic management and urban computing. Although recent methods have shown improved accuracy, they often fail to account for dynamic deviations between current inputs and historical patterns. These deviations contain critical signals that can significantly affect model performance. To fill this gap, we propose ST-SSDL, a Spatio-Temporal time series forecasting framework that incorporates a Self-Supervised Deviation Learning scheme to capture and utilize such deviations. ST-SSDL anchors each input to its historical average and discretizes the latent space using learnable prototypes that represent typical spatio-temporal patterns. Two auxiliary objectives are proposed to refine this structure: a contrastive loss that enhances inter-prototype discriminability and a deviation loss that regularizes the distance consistency between input representations and corresponding prototypes to quantify deviation. Optimized jointly with the forecasting objective, these components guide the model to organize its hidden space and improve generalization across diverse input conditions. Experiments on six benchmark datasets show that ST-SSDL consistently outperforms state-of-the-art baselines across multiple metrics. Visualizations further demonstrate its ability to adaptively respond to varying levels of deviation in complex spatio-temporal scenarios. Our code and datasets are available at https://github.com/Jimmy-7664/ST-SSDL.
COMET:Combined Matrix for Elucidating Targets
Dec 03, 2024



Identifying the interaction targets of bioactive compounds is a foundational element for deciphering their pharmacological effects. Target prediction algorithms equip researchers with an effective tool to rapidly scope and explore potential targets. Here, we introduce the COMET, a multi-technological modular target prediction tool that provides comprehensive predictive insights, including similar active compounds, three-dimensional predicted binding modes, and probability scores, all within an average processing time of less than 10 minutes per task. With meticulously curated data, the COMET database encompasses 990,944 drug-target interaction pairs and 45,035 binding pockets, enabling predictions for 2,685 targets, which span confirmed and exploratory therapeutic targets for human diseases. In comparative testing using datasets from ChEMBL and BindingDB, COMET outperformed five other well-known algorithms, offering nearly an 80% probability of accurately identifying at least one true target within the top 15 predictions for a given compound. COMET also features a user-friendly web server, accessible freely at https://www.pdbbind-plus.org.cn/comet.
NeurDB: On the Design and Implementation of an AI-powered Autonomous Database
Aug 06, 2024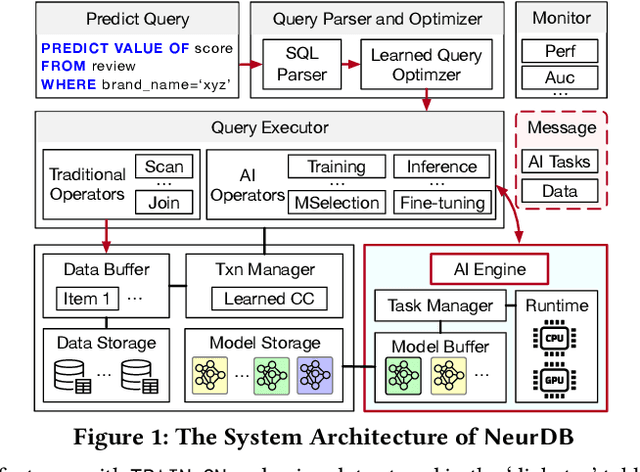
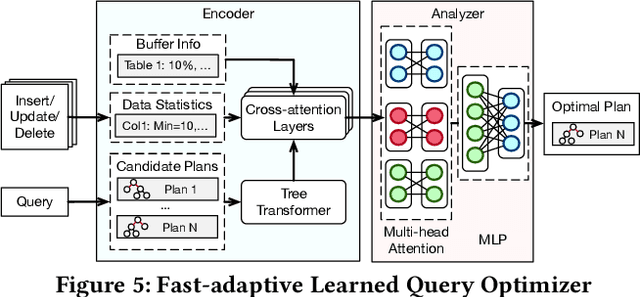
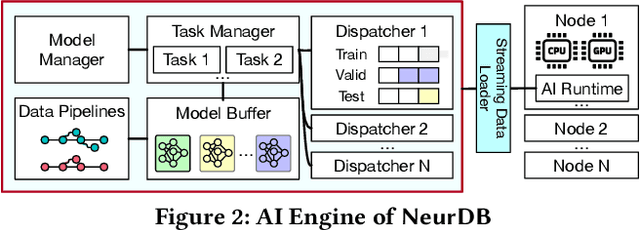
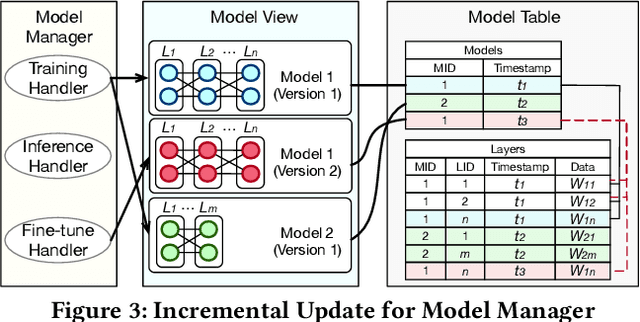
Databases are increasingly embracing AI to provide autonomous system optimization and intelligent in-database analytics, aiming to relieve end-user burdens across various industry sectors. Nonetheless, most existing approaches fail to account for the dynamic nature of databases, which renders them ineffective for real-world applications characterized by evolving data and workloads. This paper introduces NeurDB, an AI-powered autonomous database that deepens the fusion of AI and databases with adaptability to data and workload drift. NeurDB establishes a new in-database AI ecosystem that seamlessly integrates AI workflows within the database. This integration enables efficient and effective in-database AI analytics and fast-adaptive learned system components. Empirical evaluations demonstrate that NeurDB substantially outperforms existing solutions in managing AI analytics tasks, with the proposed learned components more effectively handling environmental dynamism than state-of-the-art approaches.
Heterogeneity-Informed Meta-Parameter Learning for Spatiotemporal Time Series Forecasting
May 17, 2024



Spatiotemporal time series forecasting plays a key role in a wide range of real-world applications. While significant progress has been made in this area, fully capturing and leveraging spatiotemporal heterogeneity remains a fundamental challenge. Therefore, we propose a novel Heterogeneity-Informed Meta-Parameter Learning scheme. Specifically, our approach implicitly captures spatiotemporal heterogeneity through learning spatial and temporal embeddings, which can be viewed as a clustering process. Then, a novel spatiotemporal meta-parameter learning paradigm is proposed to learn spatiotemporal-specific parameters from meta-parameter pools, which is informed by the captured heterogeneity. Based on these ideas, we develop a Heterogeneity-Informed Spatiotemporal Meta-Network (HimNet) for spatiotemporal time series forecasting. Extensive experiments on five widely-used benchmarks demonstrate our method achieves state-of-the-art performance while exhibiting superior interpretability. Our code is available at https://github.com/XDZhelheim/HimNet.
Spatio-Temporal-Decoupled Masked Pre-training for Traffic Forecasting
Dec 01, 2023



Accurate forecasting of multivariate traffic flow time series remains challenging due to substantial spatio-temporal heterogeneity and complex long-range correlative patterns. To address this, we propose Spatio-Temporal-Decoupled Masked Pre-training (STD-MAE), a novel framework that employs masked autoencoders to learn and encode complex spatio-temporal dependencies via pre-training. Specifically, we use two decoupled masked autoencoders to reconstruct the traffic data along spatial and temporal axes using a self-supervised pre-training approach. These mask reconstruction mechanisms capture the long-range correlations in space and time separately. The learned hidden representations are then used to augment the downstream spatio-temporal traffic predictor. A series of quantitative and qualitative evaluations on four widely-used traffic benchmarks (PEMS03, PEMS04, PEMS07, and PEMS08) are conducted to verify the state-of-the-art performance, with STD-MAE explicitly enhancing the downstream spatio-temporal models' ability to capture long-range intricate spatial and temporal patterns. Codes are available at https://github.com/Jimmy-7664/STD_MAE.