 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Convergence Analysis of Network-GIANT: An approximate Hessian-based fully distributed optimization algorithm
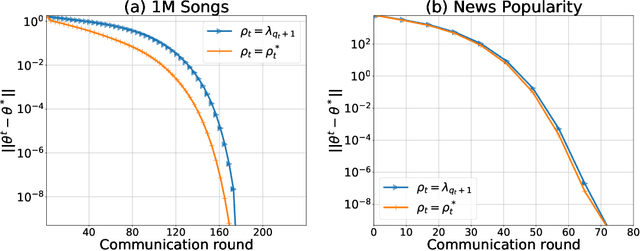
Feb 16, 2026In this paper, we present a detailed convergence analysis of a recently developed approximate Newton-type fully distributed optimization method for smooth, strongly convex local loss functions, called Network-GIANT, which has been empirically illustrated to show faster linear convergence properties while having the same communication complexity (per iteration) as its first order distributed counterparts. By using consensus based parameter updates, and a local Hessian based descent direction at the individual nodes with gradient tracking, we first explicitly characterize a global linear convergence rate for Network-GIANT, which can be computed as the spectral radius of a $3 \times 3$ matrix dependent on the Lipschitz continuity ($L$) and strong convexity ($μ$) parameters of the objective functions, and the spectral norm ($σ$) of the underlying undirected graph represented by a doubly stochastic consensus matrix. We provide an explicit bound on the step size parameter $η$, below which this spectral radius is guaranteed to be less than $1$. Furthermore, we derive a mixed linear-quadratic inequality based upper bound for the optimality gap norm, which allows us to conclude that, under small step size values, asymptotically, as the algorithm approaches the global optimum, it achieves a locally linear convergence rate of $1-η(1 -\fracγμ)$ for Network-GIANT, provided the Hessian approximation error $γ$ (between the harmonic mean of the local Hessians and the global hessian (the arithmetic mean of the local Hessians) is smaller than $μ$. This asymptotically linear convergence rate of $\approx 1-η$ explains the faster convergence rate of Network-GIANT for the first time. Numerical experiments are carried out with a reduced CovType dataset for binary logistic regression over a variety of graphs to illustrate the above theoretical results.
HBNET-GIANT: A communication-efficient accelerated Newton-type fully distributed optimization algorithm
Nov 17, 2025This article presents a second-order fully distributed optimization algorithm, HBNET-GIANT, driven by heavy-ball momentum, for $L$-smooth and $μ$-strongly convex objective functions. A rigorous convergence analysis is performed, and we demonstrate global linear convergence under certain sufficient conditions. Through extensive numerical experiments, we show that HBNET-GIANT with heavy-ball momentum achieves acceleration, and the corresponding rate of convergence is strictly faster than its non-accelerated version, NETWORK-GIANT. Moreover, we compare HBNET-GIANT with several state-of-the-art algorithms, both momentum-based and without momentum, and report significant performance improvement in convergence to the optimum. We believe that this work lays the groundwork for a broader class of second-order Newton-type algorithms with momentum and motivates further investigation into open problems, including an analytical proof of local acceleration in the fully distributed setting for convex optimization problems.
Stochastic Approximation with Delayed Updates: Finite-Time Rates under Markovian Sampling
Feb 19, 2024

Motivated by applications in large-scale and multi-agent reinforcement learning, we study the non-asymptotic performance of stochastic approximation (SA) schemes with delayed updates under Markovian sampling. While the effect of delays has been extensively studied for optimization, the manner in which they interact with the underlying Markov process to shape the finite-time performance of SA remains poorly understood. In this context, our first main contribution is to show that under time-varying bounded delays, the delayed SA update rule guarantees exponentially fast convergence of the \emph{last iterate} to a ball around the SA operator's fixed point. Notably, our bound is \emph{tight} in its dependence on both the maximum delay $\tau_{max}$, and the mixing time $\tau_{mix}$. To achieve this tight bound, we develop a novel inductive proof technique that, unlike various existing delayed-optimization analyses, relies on establishing uniform boundedness of the iterates. As such, our proof may be of independent interest. Next, to mitigate the impact of the maximum delay on the convergence rate, we provide the first finite-time analysis of a delay-adaptive SA scheme under Markovian sampling. In particular, we show that the exponent of convergence of this scheme gets scaled down by $\tau_{avg}$, as opposed to $\tau_{max}$ for the vanilla delayed SA rule; here, $\tau_{avg}$ denotes the average delay across all iterations. Moreover, the adaptive scheme requires no prior knowledge of the delay sequence for step-size tuning. Our theoretical findings shed light on the finite-time effects of delays for a broad class of algorithms, including TD learning, Q-learning, and stochastic gradient descent under Markovian sampling.
VREM-FL: Mobility-Aware Computation-Scheduling Co-Design for Vehicular Federated Learning
Nov 30, 2023



Assisted and autonomous driving are rapidly gaining momentum, and will soon become a reality. Among their key enablers, artificial intelligence and machine learning are expected to play a prominent role, also thanks to the massive amount of data that smart vehicles will collect from their onboard sensors. In this domain, federated learning is one of the most effective and promising techniques for training global machine learning models, while preserving data privacy at the vehicles and optimizing communications resource usage. In this work, we propose VREM-FL, a computation-scheduling co-design for vehicular federated learning that leverages mobility of vehicles in conjunction with estimated 5G radio environment maps. VREM-FL jointly optimizes the global model learned at the server while wisely allocating communication resources. This is achieved by orchestrating local computations at the vehicles in conjunction with the transmission of their local model updates in an adaptive and predictive fashion, by exploiting radio channel maps. The proposed algorithm can be tuned to trade model training time for radio resource usage. Experimental results demonstrate the efficacy of utilizing radio maps. VREM-FL outperforms literature benchmarks for both a linear regression model (learning time reduced by 28%) and a deep neural network for a semantic image segmentation task (doubling the number of model updates within the same time window).
FedZeN: Towards superlinear zeroth-order federated learning via incremental Hessian estimation
Sep 29, 2023Federated learning is a distributed learning framework that allows a set of clients to collaboratively train a model under the orchestration of a central server, without sharing raw data samples. Although in many practical scenarios the derivatives of the objective function are not available, only few works have considered the federated zeroth-order setting, in which functions can only be accessed through a budgeted number of point evaluations. In this work we focus on convex optimization and design the first federated zeroth-order algorithm to estimate the curvature of the global objective, with the purpose of achieving superlinear convergence. We take an incremental Hessian estimator whose error norm converges linearly, and we adapt it to the federated zeroth-order setting, sampling the random search directions from the Stiefel manifold for improved performance. In particular, both the gradient and Hessian estimators are built at the central server in a communication-efficient and privacy-preserving way by leveraging synchronized pseudo-random number generators. We provide a theoretical analysis of our algorithm, named FedZeN, proving local quadratic convergence with high probability and global linear convergence up to zeroth-order precision. Numerical simulations confirm the superlinear convergence rate and show that our algorithm outperforms the federated zeroth-order methods available in the literature.
Visibility-Constrained Control of Multirotor via Reference Governor
Aug 10, 2023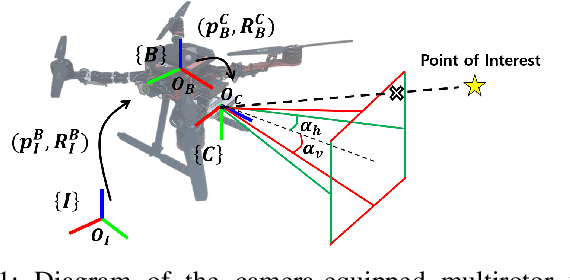
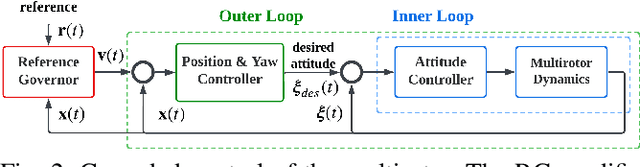
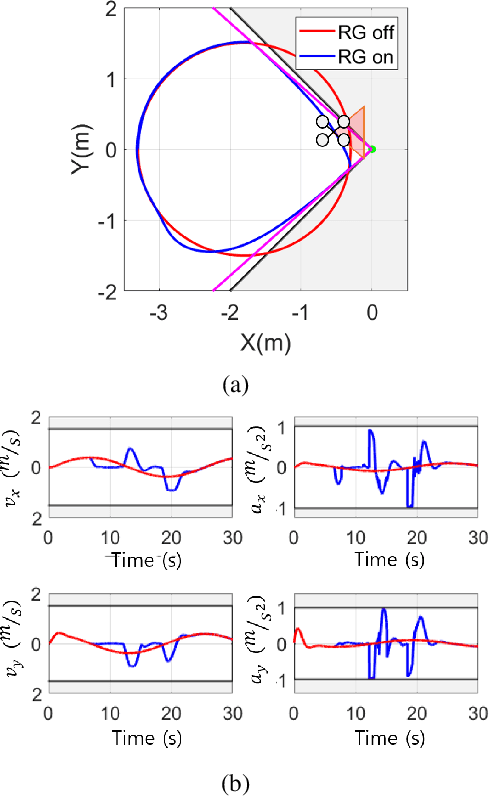
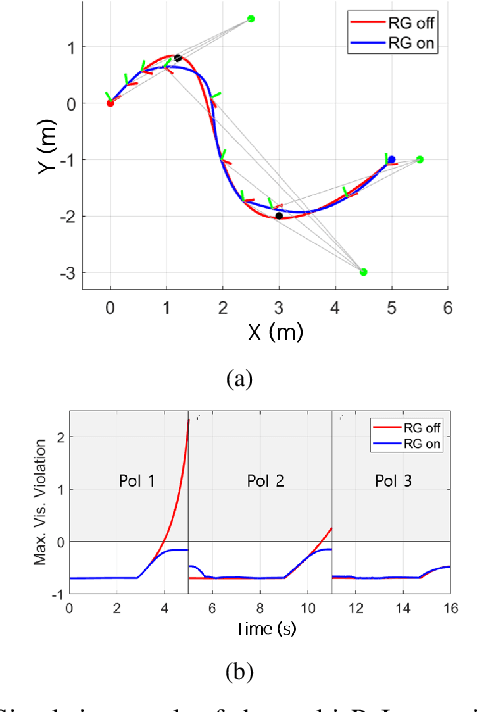
For safe vision-based control applications, perception-related constraints have to be satisfied in addition to other state constraints. In this paper, we deal with the problem where a multirotor equipped with a camera needs to maintain the visibility of a point of interest while tracking a reference given by a high-level planner. We devise a method based on reference governor that, differently from existing solutions, is able to enforce control-level visibility constraints with theoretically assured feasibility. To this end, we design a new type of reference governor for linear systems with polynomial constraints which is capable of handling time-varying references. The proposed solution is implemented online for the real-time multirotor control with visibility constraints and validated with simulations and an actual hardware experiment.
Q-SHED: Distributed Optimization at the Edge via Hessian Eigenvectors Quantization
May 18, 2023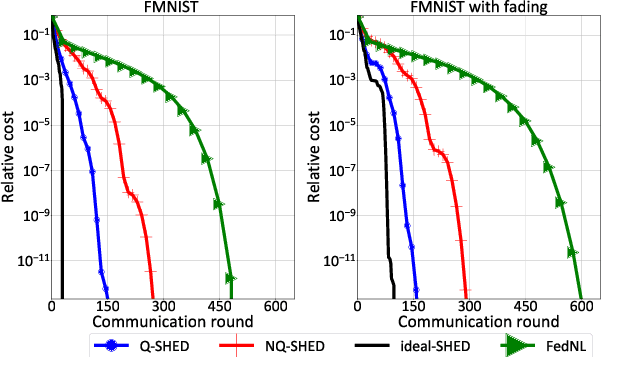
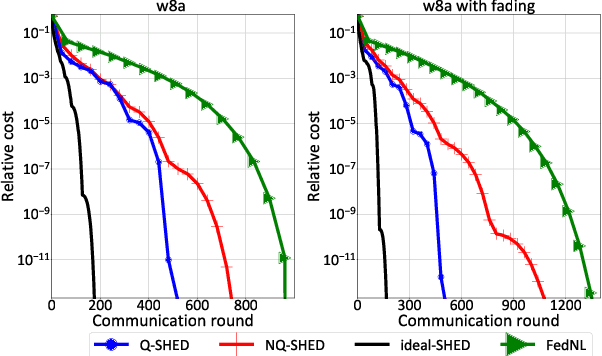
Edge networks call for communication efficient (low overhead) and robust distributed optimization (DO) algorithms. These are, in fact, desirable qualities for DO frameworks, such as federated edge learning techniques, in the presence of data and system heterogeneity, and in scenarios where internode communication is the main bottleneck. Although computationally demanding, Newton-type (NT) methods have been recently advocated as enablers of robust convergence rates in challenging DO problems where edge devices have sufficient computational power. Along these lines, in this work we propose Q-SHED, an original NT algorithm for DO featuring a novel bit-allocation scheme based on incremental Hessian eigenvectors quantization. The proposed technique is integrated with the recent SHED algorithm, from which it inherits appealing features like the small number of required Hessian computations, while being bandwidth-versatile at a bit-resolution level. Our empirical evaluation against competing approaches shows that Q-SHED can reduce by up to 60% the number of communication rounds required for convergence.
Network-GIANT: Fully distributed Newton-type optimization via harmonic Hessian consensus
May 13, 2023
This paper considers the problem of distributed multi-agent learning, where the global aim is to minimize a sum of local objective (empirical loss) functions through local optimization and information exchange between neighbouring nodes. We introduce a Newton-type fully distributed optimization algorithm, Network-GIANT, which is based on GIANT, a Federated learning algorithm that relies on a centralized parameter server. The Network-GIANT algorithm is designed via a combination of gradient-tracking and a Newton-type iterative algorithm at each node with consensus based averaging of local gradient and Newton updates. We prove that our algorithm guarantees semi-global and exponential convergence to the exact solution over the network assuming strongly convex and smooth loss functions. We provide empirical evidence of the superior convergence performance of Network-GIANT over other state-of-art distributed learning algorithms such as Network-DANE and Newton-Raphson Consensus.
Can Competition Outperform Collaboration? The Role of Malicious Agents
Jul 04, 2022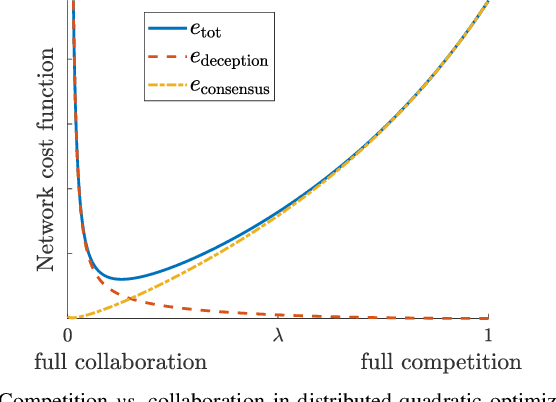
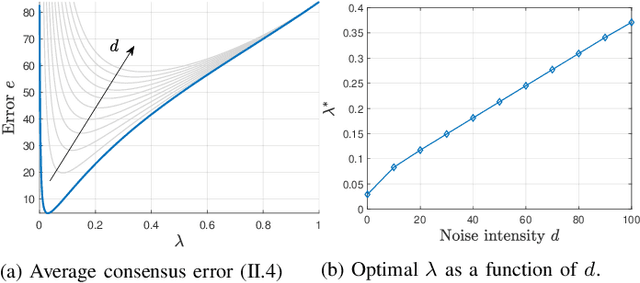
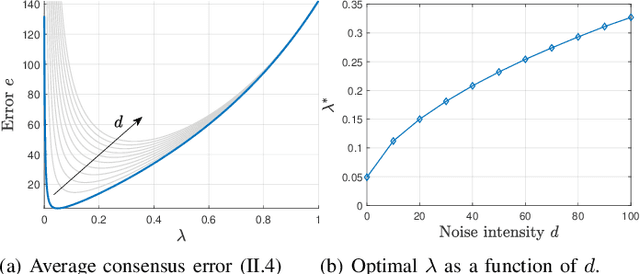
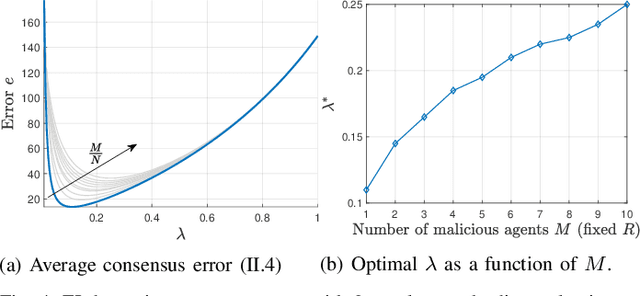
We investigate a novel approach to resilient distributed optimization with quadratic costs in a Networked Control System prone to exogenous attacks that make agents misbehave. In contrast with commonly adopted filtering strategies, we draw inspiration from a game-theoretic formulation of the consensus problem and argue that adding competition to the mix can improve resilience in the presence of malicious agents. Our intuition is corroborated by analytical and numerical results showing that (i) our strategy reveals a nontrivial performance trade-off between full collaboration and full competition, and (ii) such competitionbased approach can outperform state-of-the-art algorithms based on Mean Subsequence Reduced. Finally, we study impact of communication topology and connectivity on performance, pointing out insights to robust network design.
A Newton-type algorithm for federated learning based on incremental Hessian eigenvector sharing
Feb 11, 2022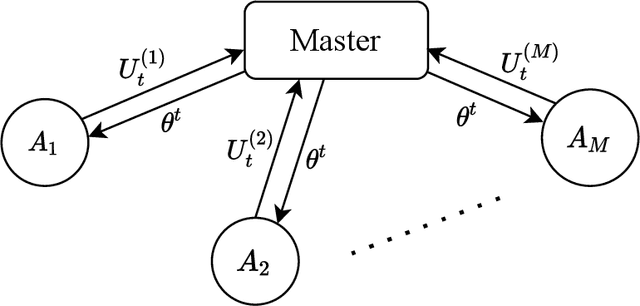
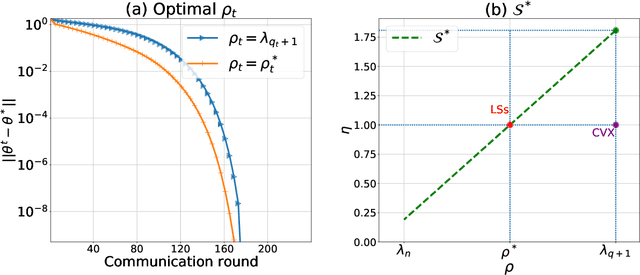
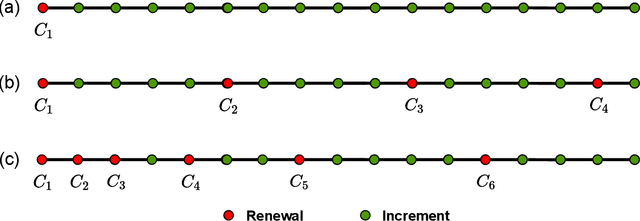
There is a growing interest in the decentralized optimization framework that goes under the name of Federated Learning (FL). In particular, much attention is being turned to FL scenarios where the network is strongly heterogeneous in terms of communication resources (e.g., bandwidth) and data distribution. In these cases, communication between local machines (agents) and the central server (Master) is a main consideration. In this work, we present an original communication-constrained Newton-type (NT) algorithm designed to accelerate FL in such heterogeneous scenarios. The algorithm is by design robust to non i.i.d. data distributions, handles heterogeneity of agents' communication resources (CRs), only requires sporadic Hessian computations, and achieves super-linear convergence. This is possible thanks to an incremental strategy, based on a singular value decomposition (SVD) of the local Hessian matrices, which exploits (possibly) outdated second-order information. The proposed solution is thoroughly validated on real datasets by assessing (i) the number of communication rounds required for convergence, (ii) the overall amount of data transmitted and (iii) the number of local Hessian computations required. For all these metrics, the proposed approach shows superior performance against state-of-the art techniques like GIANT and FedNL.