 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Designing Multi-UAV aided Wireless Powered Dynamic Communication via Hierarchical Deep Reinforcement Learning
Dec 13, 2023
This paper proposes a novel design on the wireless powered communication network (WPCN) in dynamic environments under the assistance of multiple unmanned aerial vehicles (UAVs). Unlike the existing studies, where the low-power wireless nodes (WNs) often conform to the coherent harvest-then-transmit protocol, under our newly proposed double-threshold based WN type updating rule, each WN can dynamically and repeatedly update its WN type as an E-node for non-linear energy harvesting over time slots or an I-node for transmitting data over sub-slots. To maximize the total transmission data size of all the WNs over T slots, each of the UAVs individually determines its trajectory and binary wireless energy transmission (WET) decisions over times slots and its binary wireless data collection (WDC) decisions over sub-slots, under the constraints of each UAV's limited on-board energy and each WN's node type updating rule. However, due to the UAVs' tightly-coupled trajectories with their WET and WDC decisions, as well as each WN's time-varying battery energy, this problem is difficult to solve optimally. We then propose a new multi-agent based hierarchical deep reinforcement learning (MAHDRL) framework with two tiers to solve the problem efficiently, where the soft actor critic (SAC) policy is designed in tier-1 to determine each UAV's continuous trajectory and binary WET decision over time slots, and the deep-Q learning (DQN) policy is designed in tier-2 to determine each UAV's binary WDC decisions over sub-slots under the given UAV trajectory from tier-1. Both of the SAC policy and the DQN policy are executed distributively at each UAV. Finally, extensive simulation results are provided to validate the outweighed performance of the proposed MAHDRL approach over various state-of-the-art benchmarks.
Perseus: Removing Energy Bloat from Large Model Training
Dec 12, 2023Training large AI models on numerous GPUs consumes a massive amount of energy. We observe that not all energy consumed during training directly contributes to end-to-end training throughput, and a significant portion can be removed without slowing down training, which we call energy bloat. In this work, we identify two independent sources of energy bloat in large model training, intrinsic and extrinsic, and propose Perseus, a unified optimization framework that mitigates both. Perseus obtains the "iteration time-energy" Pareto frontier of any large model training job using an efficient iterative graph cut-based algorithm and schedules energy consumption of its forward and backward computations across time to remove intrinsic and extrinsic energy bloat. Evaluation on large models like GPT-3 and Bloom shows that Perseus reduces energy consumption of large model training by up to 30%, enabling savings otherwise unobtainable before.
Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models
Dec 13, 2023
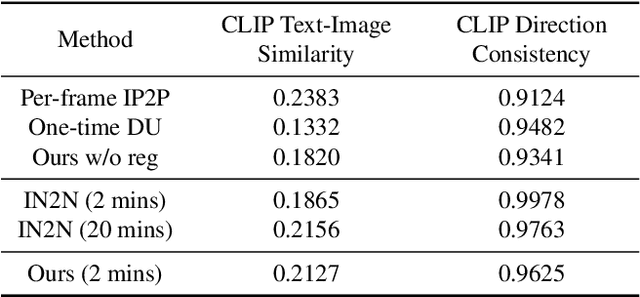
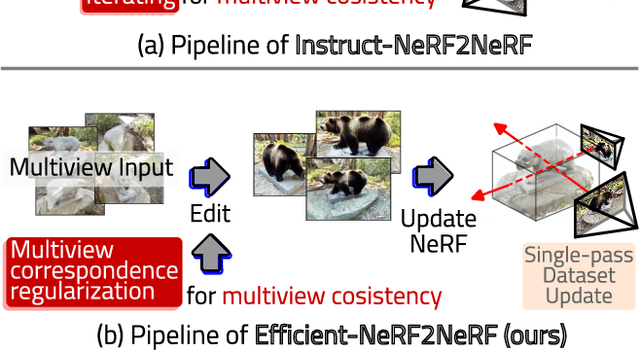
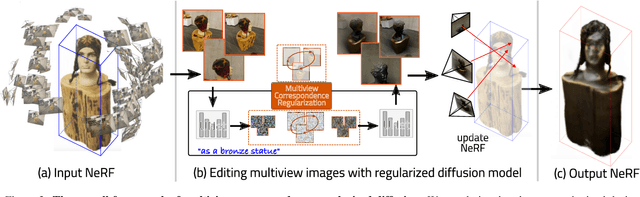
The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging this multiview consistency, we can edit 3D content at a much faster speed. In most scenarios, our proposed technique brings a 10$\times$ speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality.
Compact 3D Scene Representation via Self-Organizing Gaussian Grids
Dec 19, 20233D Gaussian Splatting has recently emerged as a highly promising technique for modeling of static 3D scenes. In contrast to Neural Radiance Fields, it utilizes efficient rasterization allowing for very fast rendering at high-quality. However, the storage size is significantly higher, which hinders practical deployment, e.g.~on resource constrained devices. In this paper, we introduce a compact scene representation organizing the parameters of 3D Gaussian Splatting (3DGS) into a 2D grid with local homogeneity, ensuring a drastic reduction in storage requirements without compromising visual quality during rendering. Central to our idea is the explicit exploitation of perceptual redundancies present in natural scenes. In essence, the inherent nature of a scene allows for numerous permutations of Gaussian parameters to equivalently represent it. To this end, we propose a novel highly parallel algorithm that regularly arranges the high-dimensional Gaussian parameters into a 2D grid while preserving their neighborhood structure. During training, we further enforce local smoothness between the sorted parameters in the grid. The uncompressed Gaussians use the same structure as 3DGS, ensuring a seamless integration with established renderers. Our method achieves a reduction factor of 8x to 26x in size for complex scenes with no increase in training time, marking a substantial leap forward in the domain of 3D scene distribution and consumption. Additional information can be found on our project page: https://fraunhoferhhi.github.io/Self-Organizing-Gaussians/
Xpert: Empowering Incident Management with Query Recommendations via Large Language Models
Dec 19, 2023Large-scale cloud systems play a pivotal role in modern IT infrastructure. However, incidents occurring within these systems can lead to service disruptions and adversely affect user experience. To swiftly resolve such incidents, on-call engineers depend on crafting domain-specific language (DSL) queries to analyze telemetry data. However, writing these queries can be challenging and time-consuming. This paper presents a thorough empirical study on the utilization of queries of KQL, a DSL employed for incident management in a large-scale cloud management system at Microsoft. The findings obtained underscore the importance and viability of KQL queries recommendation to enhance incident management. Building upon these valuable insights, we introduce Xpert, an end-to-end machine learning framework that automates KQL recommendation process. By leveraging historical incident data and large language models, Xpert generates customized KQL queries tailored to new incidents. Furthermore, Xpert incorporates a novel performance metric called Xcore, enabling a thorough evaluation of query quality from three comprehensive perspectives. We conduct extensive evaluations of Xpert, demonstrating its effectiveness in offline settings. Notably, we deploy Xpert in the real production environment of a large-scale incident management system in Microsoft, validating its efficiency in supporting incident management. To the best of our knowledge, this paper represents the first empirical study of its kind, and Xpert stands as a pioneering DSL query recommendation framework designed for incident management.
Parameterized Decision-making with Multi-modal Perception for Autonomous Driving
Dec 19, 2023Autonomous driving is an emerging technology that has advanced rapidly over the last decade. Modern transportation is expected to benefit greatly from a wise decision-making framework of autonomous vehicles, including the improvement of mobility and the minimization of risks and travel time. However, existing methods either ignore the complexity of environments only fitting straight roads, or ignore the impact on surrounding vehicles during optimization phases, leading to weak environmental adaptability and incomplete optimization objectives. To address these limitations, we propose a parameterized decision-making framework with multi-modal perception based on deep reinforcement learning, called AUTO. We conduct a comprehensive perception to capture the state features of various traffic participants around the autonomous vehicle, based on which we design a graph-based model to learn a state representation of the multi-modal semantic features. To distinguish between lane-following and lane-changing, we decompose an action of the autonomous vehicle into a parameterized action structure that first decides whether to change lanes and then computes an exact action to execute. A hybrid reward function takes into account aspects of safety, traffic efficiency, passenger comfort, and impact to guide the framework to generate optimal actions. In addition, we design a regularization term and a multi-worker paradigm to enhance the training. Extensive experiments offer evidence that AUTO can advance state-of-the-art in terms of both macroscopic and microscopic effectiveness.
Learning Flexible Body Collision Dynamics with Hierarchical Contact Mesh Transformer
Dec 19, 2023Recently, many mesh-based graph neural network (GNN) models have been proposed for modeling complex high-dimensional physical systems. Remarkable achievements have been made in significantly reducing the solving time compared to traditional numerical solvers. These methods are typically designed to i) reduce the computational cost in solving physical dynamics and/or ii) propose techniques to enhance the solution accuracy in fluid and rigid body dynamics. However, it remains under-explored whether they are effective in addressing the challenges of flexible body dynamics, where instantaneous collisions occur within a very short timeframe. In this paper, we present Hierarchical Contact Mesh Transformer (HCMT), which uses hierarchical mesh structures and can learn long-range dependencies (occurred by collisions) among spatially distant positions of a body -- two close positions in a higher-level mesh corresponds to two distant positions in a lower-level mesh. HCMT enables long-range interactions, and the hierarchical mesh structure quickly propagates collision effects to faraway positions. To this end, it consists of a contact mesh Transformer and a hierarchical mesh Transformer (CMT and HMT, respectively). Lastly, we propose a flexible body dynamics dataset, consisting of trajectories that reflect experimental settings frequently used in the display industry for product designs. We also compare the performance of several baselines using well-known benchmark datasets. Our results show that HCMT provides significant performance improvements over existing methods.
Revisiting the Entropy Semiring for Neural Speech Recognition
Dec 19, 2023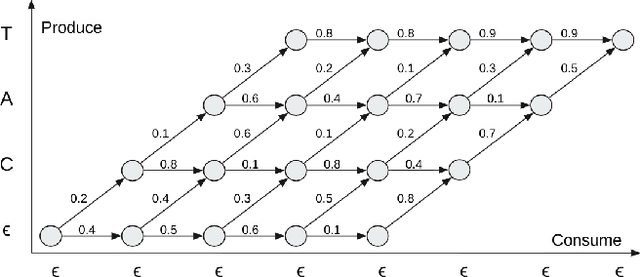
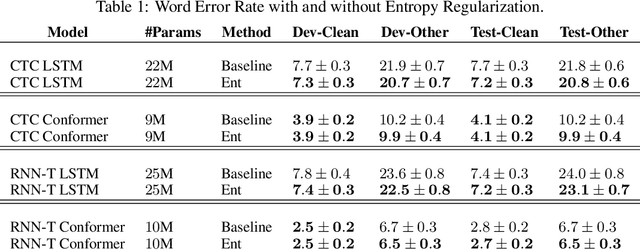

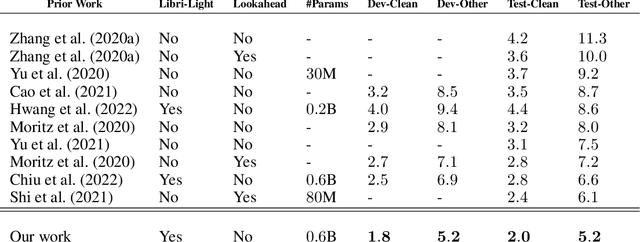
In streaming settings, speech recognition models have to map sub-sequences of speech to text before the full audio stream becomes available. However, since alignment information between speech and text is rarely available during training, models need to learn it in a completely self-supervised way. In practice, the exponential number of possible alignments makes this extremely challenging, with models often learning peaky or sub-optimal alignments. Prima facie, the exponential nature of the alignment space makes it difficult to even quantify the uncertainty of a model's alignment distribution. Fortunately, it has been known for decades that the entropy of a probabilistic finite state transducer can be computed in time linear to the size of the transducer via a dynamic programming reduction based on semirings. In this work, we revisit the entropy semiring for neural speech recognition models, and show how alignment entropy can be used to supervise models through regularization or distillation. We also contribute an open-source implementation of CTC and RNN-T in the semiring framework that includes numerically stable and highly parallel variants of the entropy semiring. Empirically, we observe that the addition of alignment distillation improves the accuracy and latency of an already well-optimized teacher-student distillation model, achieving state-of-the-art performance on the Librispeech dataset in the streaming scenario.
SEA++: Multi-Graph-based High-Order Sensor Alignment for Multivariate Time-Series Unsupervised Domain Adaptation
Nov 17, 2023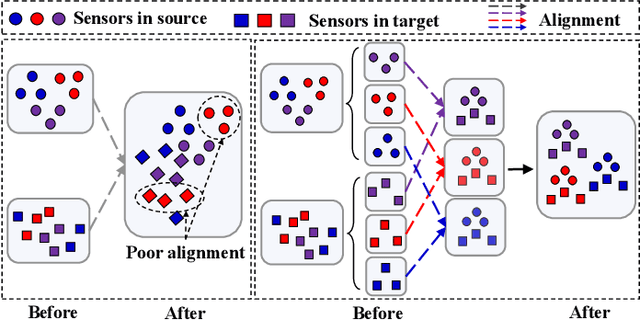

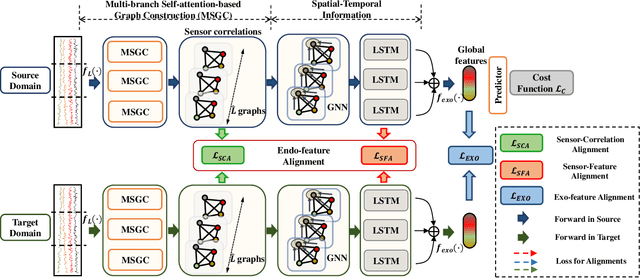
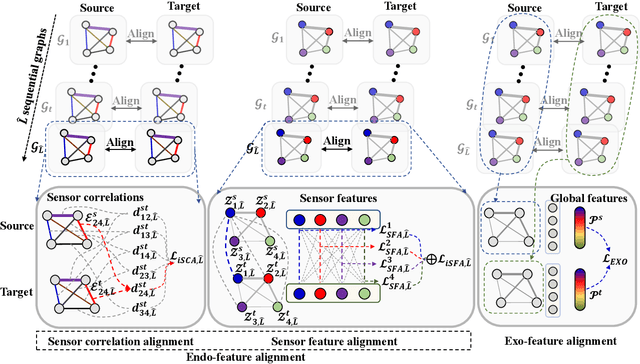
Unsupervised Domain Adaptation (UDA) methods have been successful in reducing label dependency by minimizing the domain discrepancy between a labeled source domain and an unlabeled target domain. However, these methods face challenges when dealing with Multivariate Time-Series (MTS) data. MTS data typically consist of multiple sensors, each with its own unique distribution. This characteristic makes it hard to adapt existing UDA methods, which mainly focus on aligning global features while overlooking the distribution discrepancies at the sensor level, to reduce domain discrepancies for MTS data. To address this issue, a practical domain adaptation scenario is formulated as Multivariate Time-Series Unsupervised Domain Adaptation (MTS-UDA). In this paper, we propose SEnsor Alignment (SEA) for MTS-UDA, aiming to reduce domain discrepancy at both the local and global sensor levels. At the local sensor level, we design endo-feature alignment, which aligns sensor features and their correlations across domains. To reduce domain discrepancy at the global sensor level, we design exo-feature alignment that enforces restrictions on global sensor features. We further extend SEA to SEA++ by enhancing the endo-feature alignment. Particularly, we incorporate multi-graph-based high-order alignment for both sensor features and their correlations. Extensive empirical results have demonstrated the state-of-the-art performance of our SEA and SEA++ on public MTS datasets for MTS-UDA.
READS-V: Real-time Automated Detection of Epileptic Seizures from Surveillance Videos via Skeleton-based Spatiotemporal ViG
Nov 24, 2023An accurate and efficient epileptic seizure onset detection system can significantly benefit patients. Traditional diagnostic methods, primarily relying on electroencephalograms (EEGs), often result in cumbersome and non-portable solutions, making continuous patient monitoring challenging. The video-based seizure detection system is expected to free patients from the constraints of scalp or implanted EEG devices and enable remote monitoring in residential settings. Previous video-based methods neither enable all-day monitoring nor provide short detection latency due to insufficient resources and ineffective patient action recognition techniques. Additionally, skeleton-based action recognition approaches remain limitations in identifying subtle seizure-related actions. To address these challenges, we propose a novel skeleton-based spatiotemporal vision graph neural network (STViG) for efficient, accurate, and timely REal-time Automated Detection of epileptic Seizures from surveillance Videos (READS-V). Our experimental results indicate STViG outperforms previous state-of-the-art action recognition models on our collected patients' video data with higher accuracy (5.9% error) and lower FLOPs (0.4G). Furthermore, by integrating a decision-making rule that combines output probabilities and an accumulative function, our READS-V system achieves a 5.1 s EEG onset detection latency, a 13.1 s advance in clinical onset detection, and zero false detection rate.