 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrbax: Distributed Checkpointing with JAX
May 26, 2026In a landscape of high-performance distributed ML systems, JAX has emerged as a framework of choice. However, JAX's modular design philosophy leaves it without a standardized checkpointing solution. In this paper, we introduce Orbax, a modular, JAX-native checkpointing library that abstracts the complexities of distributed accelerator systems while also providing flexibility for user-friendly checkpoint manipulations throughout the ML model lifecycle. We demonstrate performance exceeding comparable PyTorch competitors by up to 3.5$\times$ for saving and 2$\times$ for loading. The library is available at https://github.com/google/orbax.
Cloning is as Hard as Learning for Stabilizer States
Apr 16, 2026The impossibility of simultaneously cloning non-orthogonal states lies at the foundations of quantum theory. Even when allowing for approximation errors, cloning an arbitrary unknown pure state requires as many initial copies as needed to fully learn the state. Rather than arbitrary unknown states, modern quantum learning theory often considers structured classes of states and exploits such structure to develop learning algorithms that outperform general-state tomography. This raises the question: How do the sample complexities of learning and cloning relate for such structured classes? We answer this question for an important class of states. Namely, for $n$-qubit stabilizer states, we show that the optimal sample complexity of cloning is $Θ(n)$. Thus, also for this structured class of states, cloning is as hard as learning. To prove these results, we use representation-theoretic tools in the recently proposed Abelian State Hidden Subgroup framework and a new structured version of the recently introduced random purification channel to relate stabilizer state cloning to a variant of the sample amplification problem for probability distributions that was recently introduced in classical learning theory. This allows us to obtain our cloning lower bounds by proving new sample amplification lower bounds for classes of distributions with an underlying linear structure. Our results provide a more fine-grained perspective on No-Cloning theorems, opening up connections from foundations to quantum learning theory and quantum cryptography.
Perseus: Removing Energy Bloat from Large Model Training
Dec 12, 2023Training large AI models on numerous GPUs consumes a massive amount of energy. We observe that not all energy consumed during training directly contributes to end-to-end training throughput, and a significant portion can be removed without slowing down training, which we call energy bloat. In this work, we identify two independent sources of energy bloat in large model training, intrinsic and extrinsic, and propose Perseus, a unified optimization framework that mitigates both. Perseus obtains the "iteration time-energy" Pareto frontier of any large model training job using an efficient iterative graph cut-based algorithm and schedules energy consumption of its forward and backward computations across time to remove intrinsic and extrinsic energy bloat. Evaluation on large models like GPT-3 and Bloom shows that Perseus reduces energy consumption of large model training by up to 30%, enabling savings otherwise unobtainable before.
DrawMon: A Distributed System for Detection of Atypical Sketch Content in Concurrent Pictionary Games
Nov 10, 2022



Pictionary, the popular sketch-based guessing game, provides an opportunity to analyze shared goal cooperative game play in restricted communication settings. However, some players occasionally draw atypical sketch content. While such content is occasionally relevant in the game context, it sometimes represents a rule violation and impairs the game experience. To address such situations in a timely and scalable manner, we introduce DrawMon, a novel distributed framework for automatic detection of atypical sketch content in concurrently occurring Pictionary game sessions. We build specialized online interfaces to collect game session data and annotate atypical sketch content, resulting in AtyPict, the first ever atypical sketch content dataset. We use AtyPict to train CanvasNet, a deep neural atypical content detection network. We utilize CanvasNet as a core component of DrawMon. Our analysis of post deployment game session data indicates DrawMon's effectiveness for scalable monitoring and atypical sketch content detection. Beyond Pictionary, our contributions also serve as a design guide for customized atypical content response systems involving shared and interactive whiteboards. Code and datasets are available at https://drawm0n.github.io.
Potential-Function Proofs for First-Order Methods
Dec 13, 2017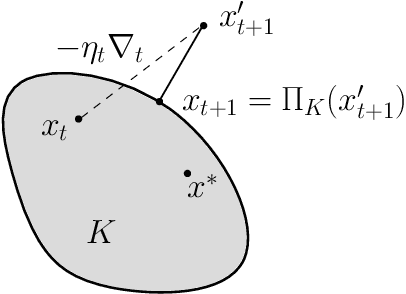
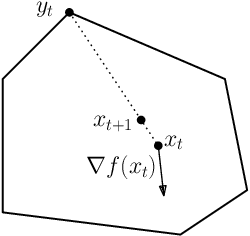
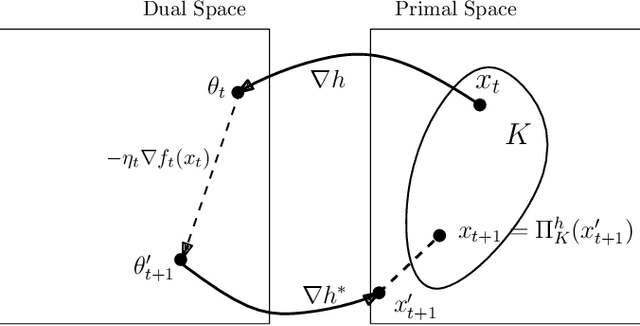
This note discusses proofs for convergence of first-order methods based on simple potential-function arguments. We cover methods like gradient descent (for both smooth and non-smooth settings), mirror descent, and some accelerated variants.