 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adversarial Attacks on Optimization based Planners
Oct 30, 2020
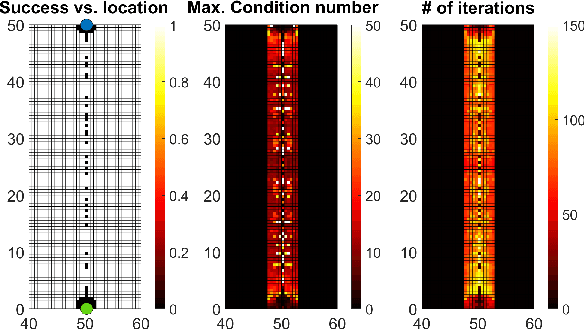

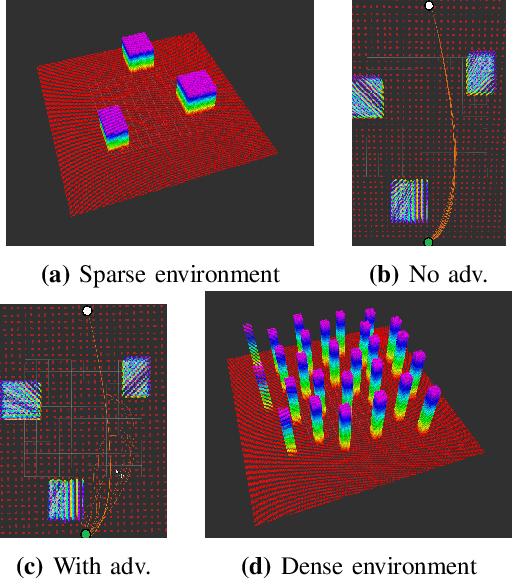

Trajectory planning is a key piece in the algorithmic architecture of a robot. Trajectory planners typically use iterative optimization schemes for generating smooth trajectories that avoid collisions and are optimal for tracking given the robot's physical specifications. Starting from an initial estimate, the planners iteratively refine the solution so as to satisfy the desired constraints. In this paper, we show that such iterative optimization based planners can be vulnerable to adversarial attacks that force the planner either to fail completely, or significantly increase the time required to find a solution. They key insight here is that an adversary in the environment can directly affect the optimization function of a planner. We demonstrate how the adversary can adjust its own state configurations to result in poorly conditioned eigenstructure of the objective leading to failures. We apply our method against two state of the art trajectory planners and demonstrate that an adversary can consistently exploit certain weaknesses of an iterative optimization scheme.
The Multimodal Driver Monitoring Database: A Naturalistic Corpus to Study Driver Attention
Dec 23, 2020
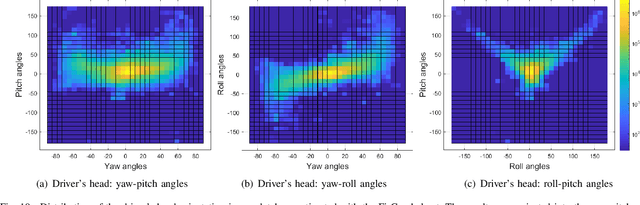
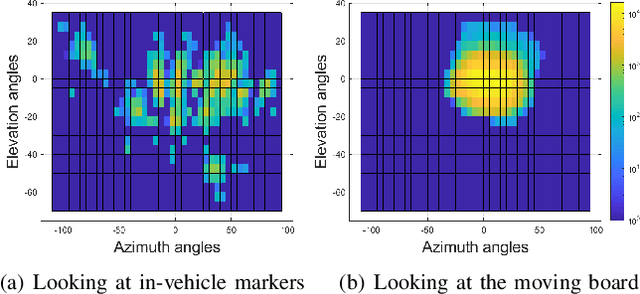

A smart vehicle should be able to monitor the actions and behaviors of the human driver to provide critical warnings or intervene when necessary. Recent advancements in deep learning and computer vision have shown great promise in monitoring human behaviors and activities. While these algorithms work well in a controlled environment, naturalistic driving conditions add new challenges such as illumination variations, occlusions and extreme head poses. A vast amount of in-domain data is required to train models that provide high performance in predicting driving related tasks to effectively monitor driver actions and behaviors. Toward building the required infrastructure, this paper presents the multimodal driver monitoring (MDM) dataset, which was collected with 59 subjects that were recorded performing various tasks. We use the Fi- Cap device that continuously tracks the head movement of the driver using fiducial markers, providing frame-based annotations to train head pose algorithms in naturalistic driving conditions. We ask the driver to look at predetermined gaze locations to obtain accurate correlation between the driver's facial image and visual attention. We also collect data when the driver performs common secondary activities such as navigation using a smart phone and operating the in-car infotainment system. All of the driver's activities are recorded with high definition RGB cameras and time-of-flight depth camera. We also record the controller area network-bus (CAN-Bus), extracting important information. These high quality recordings serve as the ideal resource to train various efficient algorithms for monitoring the driver, providing further advancements in the field of in-vehicle safety systems.
Towards Communication-efficient and Attack-Resistant Federated Edge Learning for Industrial Internet of Things
Dec 08, 2020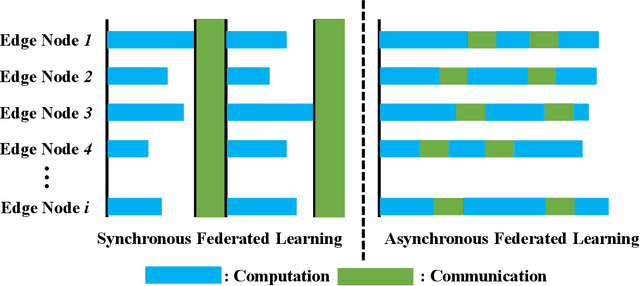
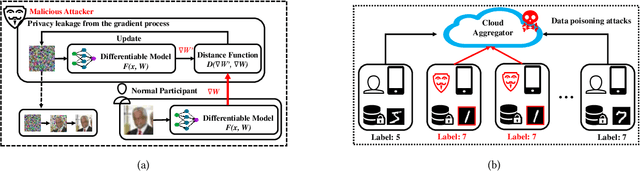
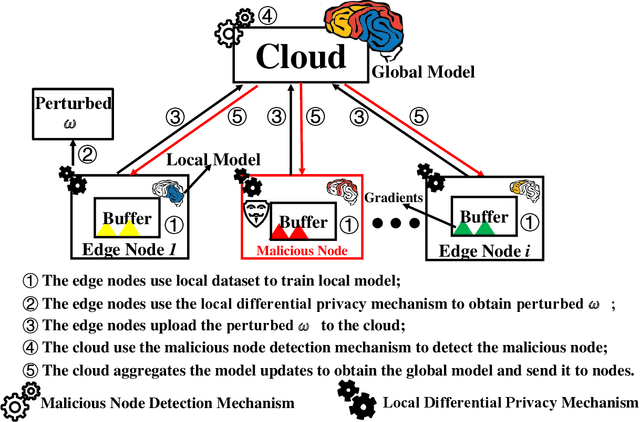
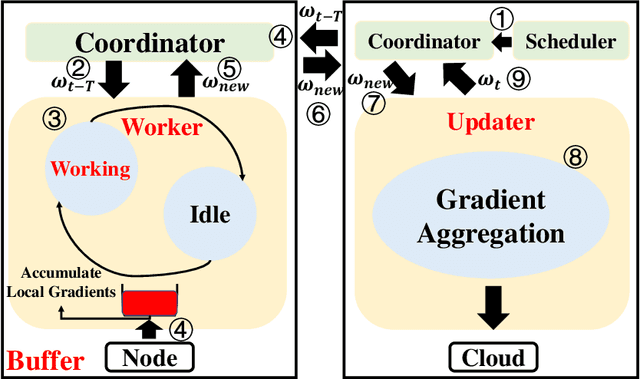
Federated Edge Learning (FEL) allows edge nodes to train a global deep learning model collaboratively for edge computing in the Industrial Internet of Things (IIoT), which significantly promotes the development of Industrial 4.0. However, FEL faces two critical challenges: communication overhead and data privacy. FEL suffers from expensive communication overhead when training large-scale multi-node models. Furthermore, due to the vulnerability of FEL to gradient leakage and label-flipping attacks, the training process of the global model is easily compromised by adversaries. To address these challenges, we propose a communication-efficient and privacy-enhanced asynchronous FEL framework for edge computing in IIoT. First, we introduce an asynchronous model update scheme to reduce the computation time that edge nodes wait for global model aggregation. Second, we propose an asynchronous local differential privacy mechanism, which improves communication efficiency and mitigates gradient leakage attacks by adding well-designed noise to the gradients of edge nodes. Third, we design a cloud-side malicious node detection mechanism to detect malicious nodes by testing the local model quality. Such a mechanism can avoid malicious nodes participating in training to mitigate label-flipping attacks. Extensive experimental studies on two real-world datasets demonstrate that the proposed framework can not only improve communication efficiency but also mitigate malicious attacks while its accuracy is comparable to traditional FEL frameworks.
Classification of Spot-welded Joints in Laser Thermography Data using Convolutional Neural Networks
Oct 24, 2020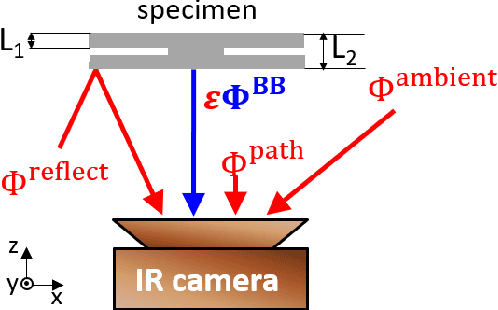
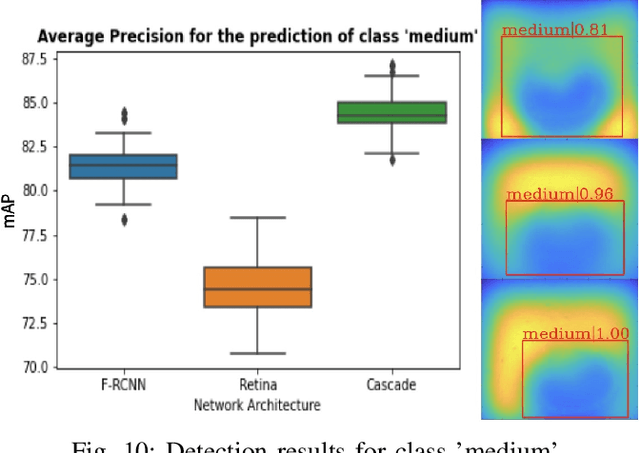
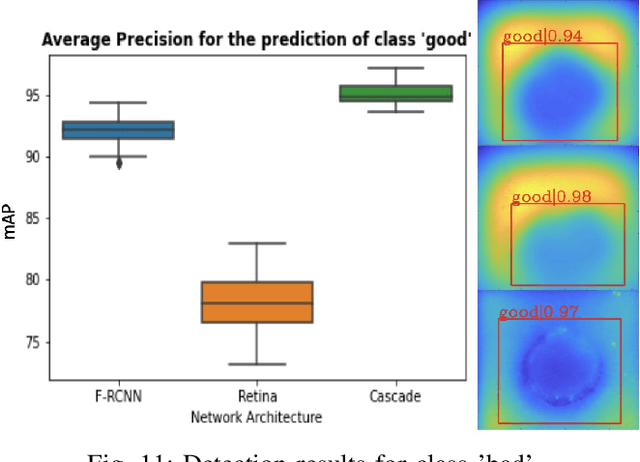

Spot welding is a crucial process step in various industries. However, classification of spot welding quality is still a tedious process due to the complexity and sensitivity of the test material, which drain conventional approaches to its limits. In this paper, we propose an approach for quality inspection of spot weldings using images from laser thermography data.We propose data preparation approaches based on the underlying physics of spot welded joints, heated with pulsed laser thermography by analyzing the intensity over time and derive dedicated data filters to generate training datasets. Subsequently, we utilize convolutional neural networks to classify weld quality and compare the performance of different models against each other. We achieve competitive results in terms of classifying the different welding quality classes compared to traditional approaches, reaching an accuracy of more than 95 percent. Finally, we explore the effect of different augmentation methods.
Training and Inference for Integer-Based Semantic Segmentation Network
Nov 30, 2020Semantic segmentation has been a major topic in research and industry in recent years. However, due to the computation complexity of pixel-wise prediction and backpropagation algorithm, semantic segmentation has been demanding in computation resources, resulting in slow training and inference speed and large storage space to store models. Existing schemes that speed up segmentation network change the network structure and come with noticeable accuracy degradation. However, neural network quantization can be used to reduce computation load while maintaining comparable accuracy and original network structure. Semantic segmentation networks are different from traditional deep convolutional neural networks (DCNNs) in many ways, and this topic has not been thoroughly explored in existing works. In this paper, we propose a new quantization framework for training and inference of segmentation networks, where parameters and operations are constrained to 8-bit integer-based values for the first time. Full quantization of the data flow and the removal of square and root operations in batch normalization give our framework the ability to perform inference on fixed-point devices. Our proposed framework is evaluated on mainstream semantic segmentation networks like FCN-VGG16 and DeepLabv3-ResNet50, achieving comparable accuracy against floating-point framework on ADE20K dataset and PASCAL VOC 2012 dataset.
End-to-End Video Instance Segmentation with Transformers
Nov 30, 2020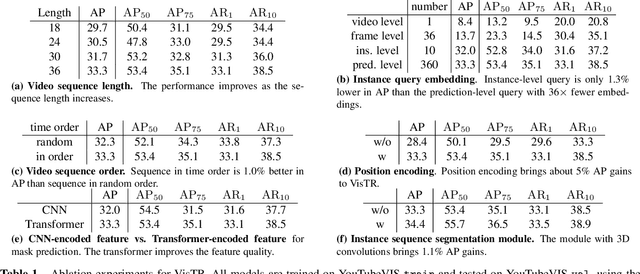
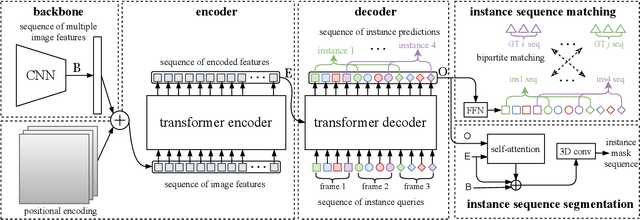
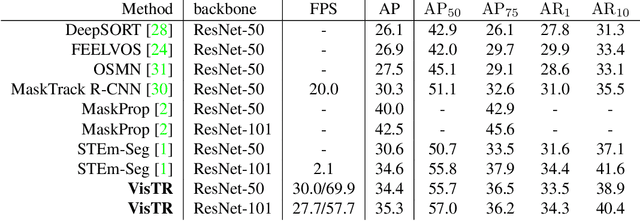

Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
Semantic SLAM with Autonomous Object-Level Data Association
Nov 20, 2020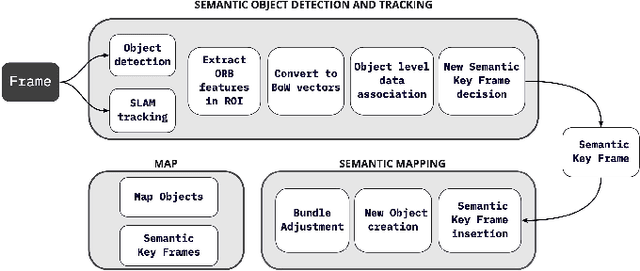



It is often desirable to capture and map semantic information of an environment during simultaneous localization and mapping (SLAM). Such semantic information can enable a robot to better distinguish places with similar low-level geometric and visual features and perform high-level tasks that use semantic information about objects to be manipulated and environments to be navigated. While semantic SLAM has gained increasing attention, there is little research on semanticlevel data association based on semantic objects, i.e., object-level data association. In this paper, we propose a novel object-level data association algorithm based on bag of words algorithm, formulated as a maximum weighted bipartite matching problem. With object-level data association solved, we develop a quadratic-programming-based semantic object initialization scheme using dual quadric and introduce additional constraints to improve the success rate of object initialization. The integrated semantic-level SLAM system can achieve high-accuracy object-level data association and real-time semantic mapping as demonstrated in the experiments. The online semantic map building and semantic-level localization capabilities facilitate semantic-level mapping and task planning in a priori unknown environment.
Energy Minimization in UAV-Aided Networks: Actor-Critic Learning for Constrained Scheduling Optimization
Jun 29, 2020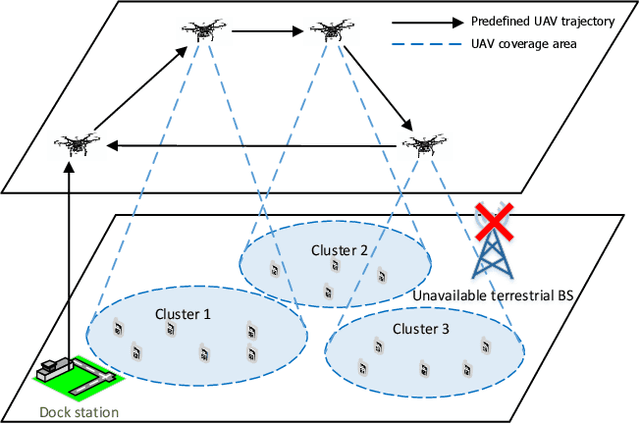
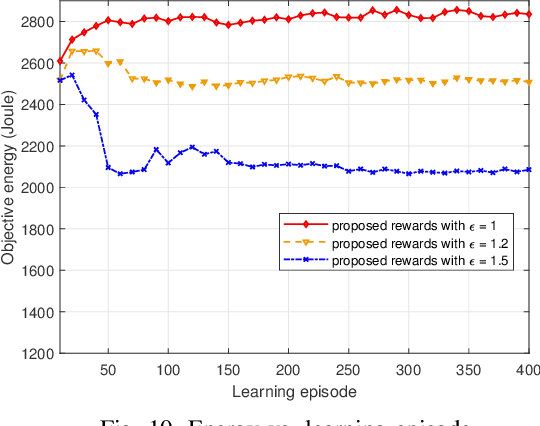
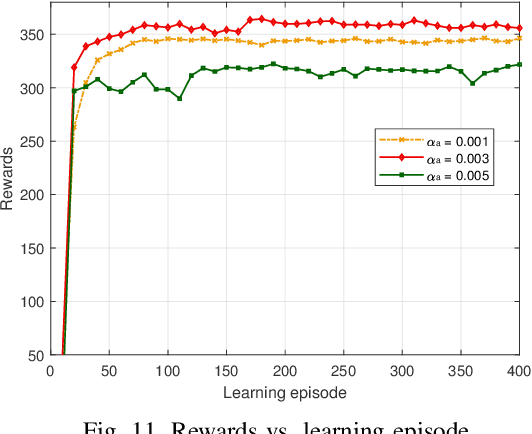
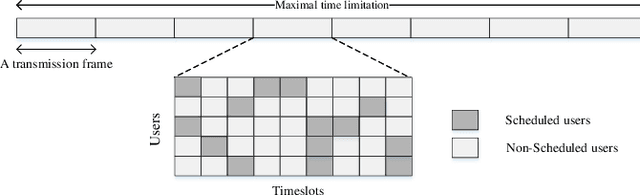
In unmanned aerial vehicle (UAV) applications, the UAV's limited energy supply and storage have triggered the development of intelligent energy-conserving scheduling solutions. In this paper, we investigate energy minimization for UAV-aided communication networks by jointly optimizing data-transmission scheduling and UAV hovering time. The formulated problem is combinatorial and non-convex with bilinear constraints. To tackle the problem, firstly, we provide an optimal relax-and-approximate solution and develop a near-optimal algorithm. Both the proposed solutions are served as offline performance benchmarks but might not be suitable for online operation. To this end, we develop a solution from a deep reinforcement learning (DRL) aspect. The conventional RL/DRL, e.g., deep Q-learning, however, is limited in dealing with two main issues in constrained combinatorial optimization, i.e., exponentially increasing action space and infeasible actions. The novelty of solution development lies in handling these two issues. To address the former, we propose an actor-critic-based deep stochastic online scheduling (AC-DSOS) algorithm and develop a set of approaches to confine the action space. For the latter, we design a tailored reward function to guarantee the solution feasibility. Numerical results show that, by consuming equal magnitude of time, AC-DSOS is able to provide feasible solutions and saves 29.94% energy compared with a conventional deep actor-critic method. Compared to the developed near-optimal algorithm, AC-DSOS consumes around 10% higher energy but reduces the computational time from minute-level to millisecond-level.
Cinematic-L1 Video Stabilization with a Log-Homography Model
Nov 20, 2020
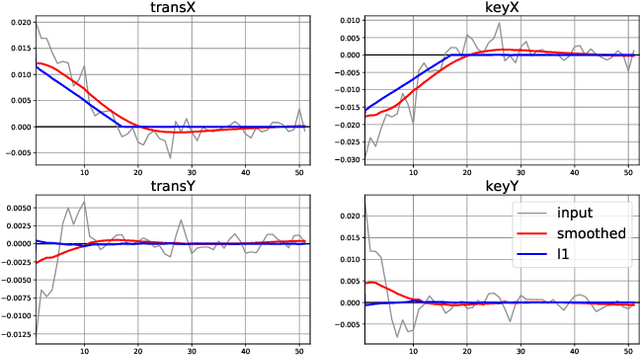
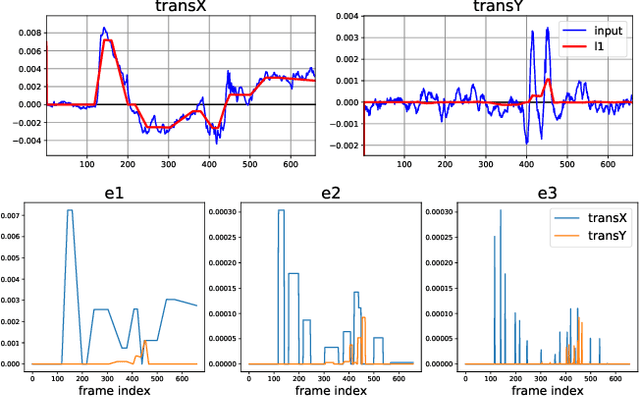
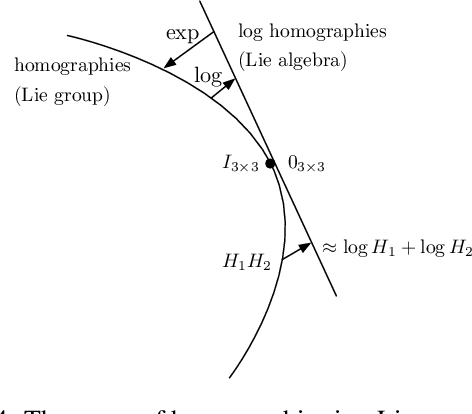
We present a method for stabilizing handheld video that simulates the camera motions cinematographers achieve with equipment like tripods, dollies, and Steadicams. We formulate a constrained convex optimization problem minimizing the $\ell_1$-norm of the first three derivatives of the stabilized motion. Our approach extends the work of Grundmann et al. [9] by solving with full homographies (rather than affinities) in order to correct perspective, preserving linearity by working in log-homography space. We also construct crop constraints that preserve field-of-view; model the problem as a quadratic (rather than linear) program to allow for an $\ell_2$ term encouraging fidelity to the original trajectory; and add constraints and objectives to reduce distortion. Furthermore, we propose new methods for handling salient objects via both inclusion constraints and centering objectives. Finally, we describe a windowing strategy to approximate the solution in linear time and bounded memory. Our method is computationally efficient, running at 300fps on an iPhone XS, and yields high-quality results, as we demonstrate with a collection of stabilized videos, quantitative and qualitative comparisons to [9] and other methods, and an ablation study.
Annotation-Efficient Untrimmed Video Action Recognition
Nov 30, 2020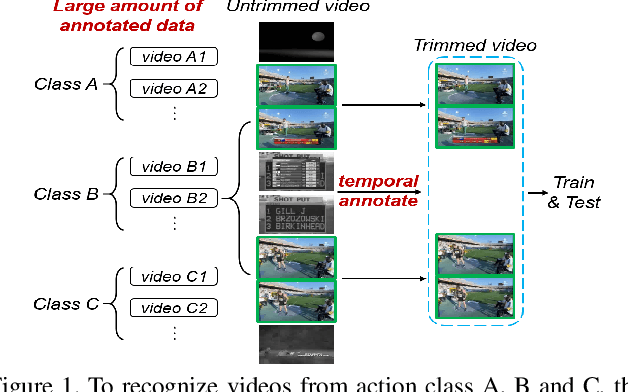

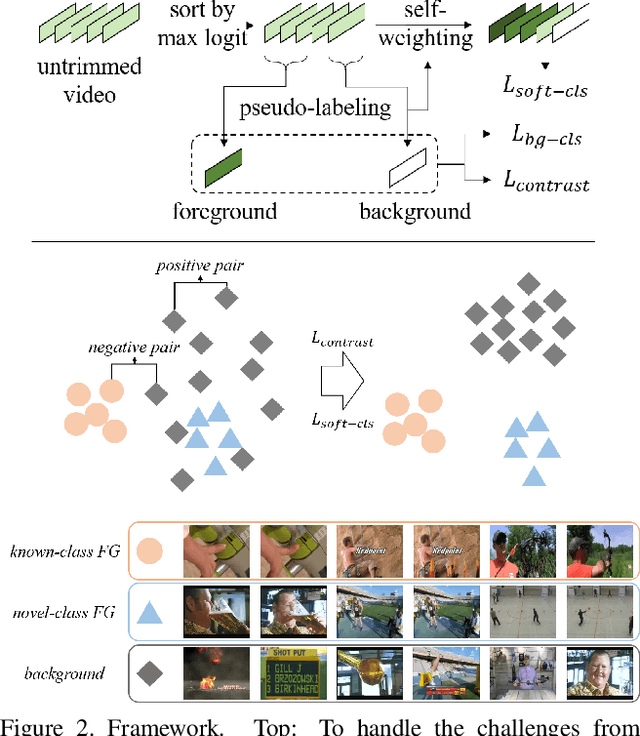
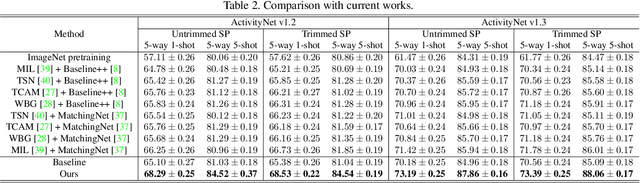
Deep learning has achieved great success in recognizing video actions, but the collection and annotation of training data are still laborious, which mainly lies in two aspects: (1) the amount of required annotated data is large; (2) temporally annotating the location of each action is time-consuming. Works such as few-shot learning or untrimmed video recognition have been proposed to handle either one aspect or the other. However, very few existing works can handle both aspects simultaneously. In this paper, we target a new problem, Annotation-Efficient Video Recognition, to reduce the requirement of annotations for both large amount of samples from different classes and the action locations. Challenges of this problem come from three folds: (1) action recognition from untrimmed videos, (2) weak supervision, and (3) novel classes with only a few training samples. To address the first two challenges, we propose a background pseudo-labeling method based on open-set detection. To tackle the third challenge, we propose a self-weighted classification mechanism and a contrastive learning method to separate background and foreground of the untrimmed videos. Extensive experiments on ActivityNet v1.2 and ActivityNet v1.3 verify the effectiveness of the proposed methods. Codes will be released online.