 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Few-shot Intent Classification and Slot Filling with Retrieved Examples
Apr 12, 2021
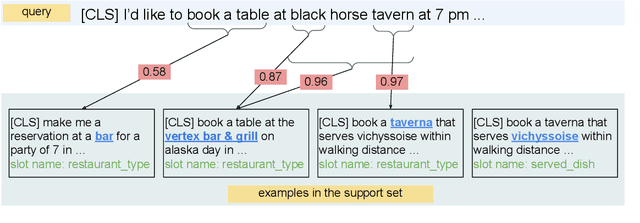
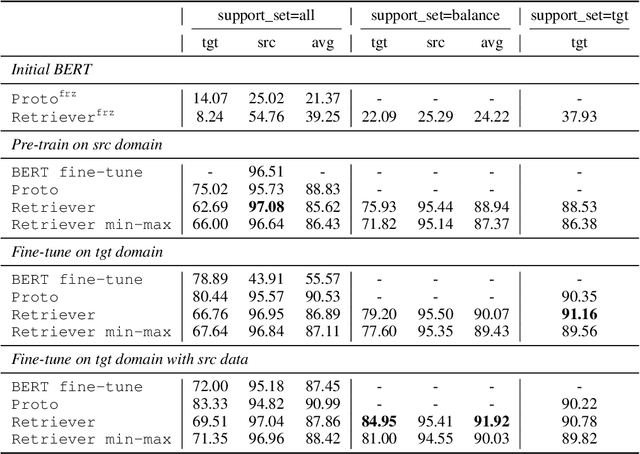
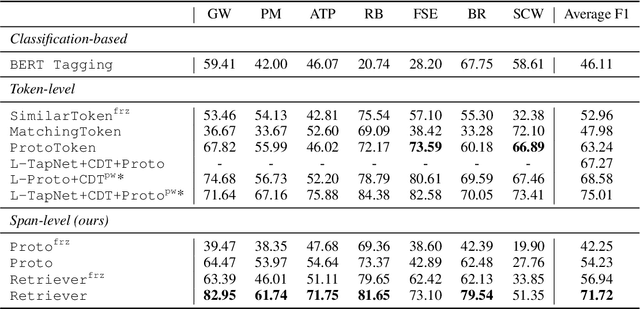

Few-shot learning arises in important practical scenarios, such as when a natural language understanding system needs to learn new semantic labels for an emerging, resource-scarce domain. In this paper, we explore retrieval-based methods for intent classification and slot filling tasks in few-shot settings. Retrieval-based methods make predictions based on labeled examples in the retrieval index that are similar to the input, and thus can adapt to new domains simply by changing the index without having to retrain the model. However, it is non-trivial to apply such methods on tasks with a complex label space like slot filling. To this end, we propose a span-level retrieval method that learns similar contextualized representations for spans with the same label via a novel batch-softmax objective. At inference time, we use the labels of the retrieved spans to construct the final structure with the highest aggregated score. Our method outperforms previous systems in various few-shot settings on the CLINC and SNIPS benchmarks.
Light-Weight RefineNet for Real-Time Semantic Segmentation
Oct 08, 2018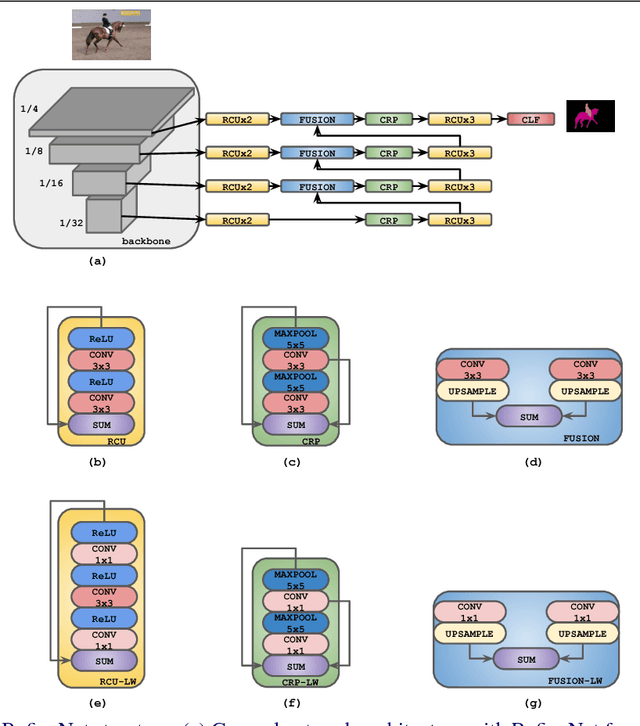

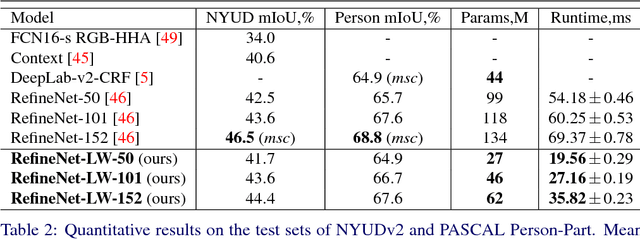

We consider an important task of effective and efficient semantic image segmentation. In particular, we adapt a powerful semantic segmentation architecture, called RefineNet, into the more compact one, suitable even for tasks requiring real-time performance on high-resolution inputs. To this end, we identify computationally expensive blocks in the original setup, and propose two modifications aimed to decrease the number of parameters and floating point operations. By doing that, we achieve more than twofold model reduction, while keeping the performance levels almost intact. Our fastest model undergoes a significant speed-up boost from 20 FPS to 55 FPS on a generic GPU card on 512x512 inputs with solid 81.1% mean iou performance on the test set of PASCAL VOC, while our slowest model with 32 FPS (from original 17 FPS) shows 82.7% mean iou on the same dataset. Alternatively, we showcase that our approach is easily mixable with light-weight classification networks: we attain 79.2% mean iou on PASCAL VOC using a model that contains only 3.3M parameters and performs only 9.3B floating point operations.
Causally interpretable multi-step time series forecasting: A new machine learning approach using simulated differential equations
Aug 27, 2019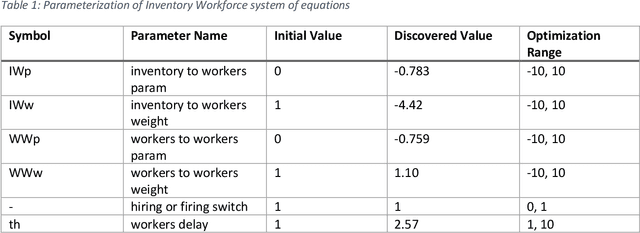
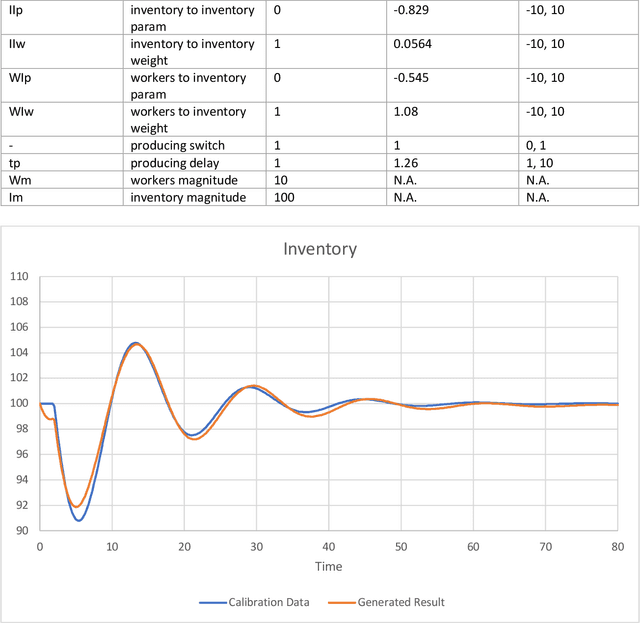
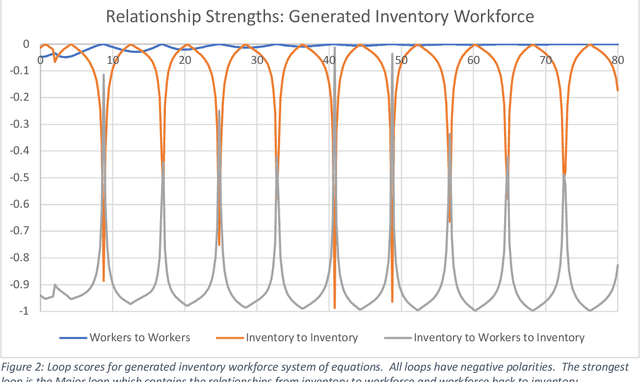
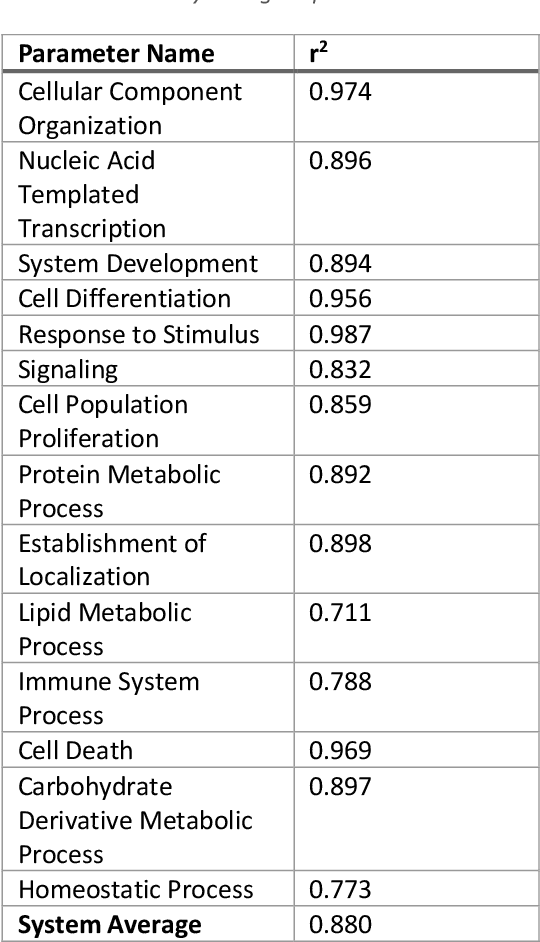
This work represents a new approach which generates then analyzes a highly non linear complex system of differential equations to do interpretable time series forecasting at a high level of accuracy. This approach provides insight and understanding into the mechanisms responsible for generating past and future behavior. Core to this method is the construction of a highly non linear complex system of differential equations that is then analyzed to determine the origins of behavior. This paper demonstrates the technique on Mass and Senge's two state Inventory Workforce model (1975) and then explores its application to the real world problem of organogenesis in mice. The organogenesis application consists of a fourteen state system where the generated set of equations reproduces observed behavior with a high level of accuracy (0.880 r^2) and when analyzed produces an interpretable and causally plausible explanation for the observed behavior.
ELSD: Efficient Line Segment Detector and Descriptor
Apr 29, 2021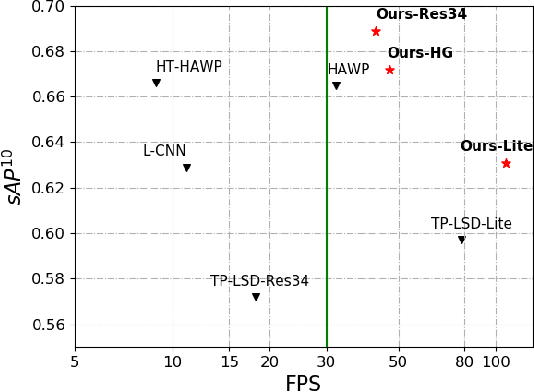
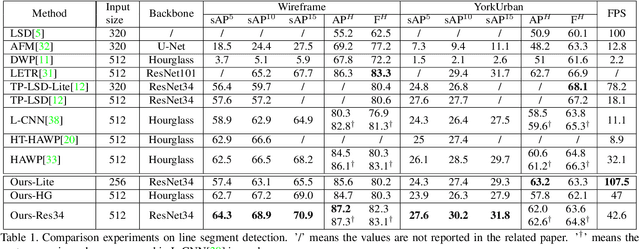
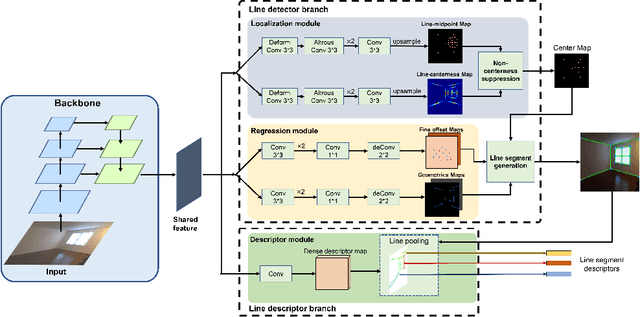
We present the novel Efficient Line Segment Detector and Descriptor (ELSD) to simultaneously detect line segments and extract their descriptors in an image. Unlike the traditional pipelines that conduct detection and description separately, ELSD utilizes a shared feature extractor for both detection and description, to provide the essential line features to the higher-level tasks like SLAM and image matching in real time. First, we design the one-stage compact model, and propose to use the mid-point, angle and length as the minimal representation of line segment, which also guarantees the center-symmetry. The non-centerness suppression is proposed to filter out the fragmented line segments caused by lines' intersections. The fine offset prediction is designed to refine the mid-point localization. Second, the line descriptor branch is integrated with the detector branch, and the two branches are jointly trained in an end-to-end manner. In the experiments, the proposed ELSD achieves the state-of-the-art performance on the Wireframe dataset and YorkUrban dataset, in both accuracy and efficiency. The line description ability of ELSD also outperforms the previous works on the line matching task.
PP-YOLOv2: A Practical Object Detector
Apr 21, 2021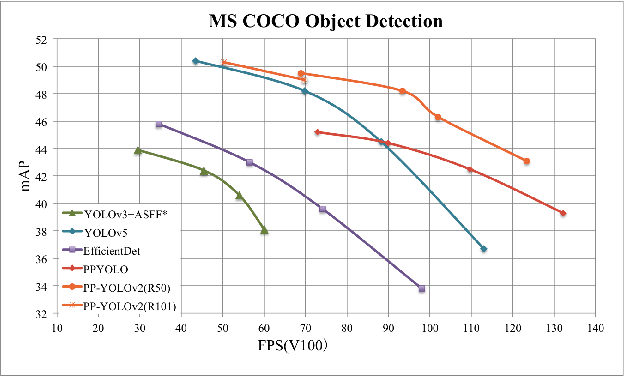

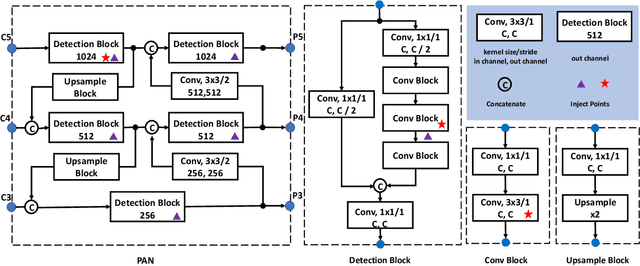
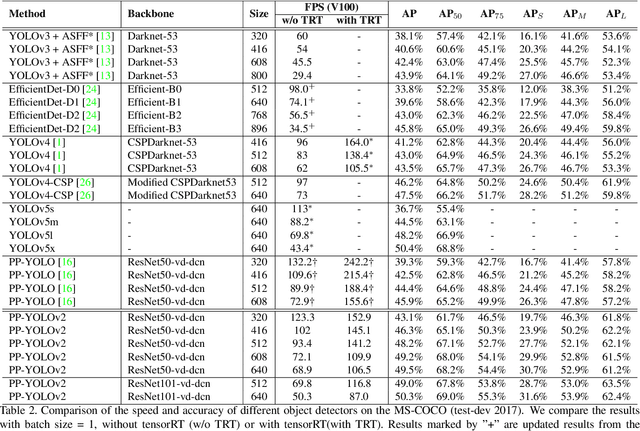
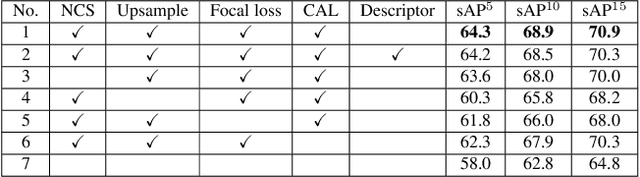
Being effective and efficient is essential to an object detector for practical use. To meet these two concerns, we comprehensively evaluate a collection of existing refinements to improve the performance of PP-YOLO while almost keep the infer time unchanged. This paper will analyze a collection of refinements and empirically evaluate their impact on the final model performance through incremental ablation study. Things we tried that didn't work will also be discussed. By combining multiple effective refinements, we boost PP-YOLO's performance from 45.9% mAP to 49.5% mAP on COCO2017 test-dev. Since a significant margin of performance has been made, we present PP-YOLOv2. In terms of speed, PP-YOLOv2 runs in 68.9FPS at 640x640 input size. Paddle inference engine with TensorRT, FP16-precision, and batch size = 1 further improves PP-YOLOv2's infer speed, which achieves 106.5 FPS. Such a performance surpasses existing object detectors with roughly the same amount of parameters (i.e., YOLOv4-CSP, YOLOv5l). Besides, PP-YOLOv2 with ResNet101 achieves 50.3% mAP on COCO2017 test-dev. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Optimization-Based Framework for Excavation Trajectory Generation
Oct 27, 2020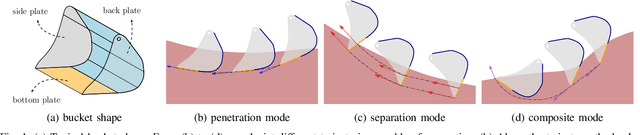
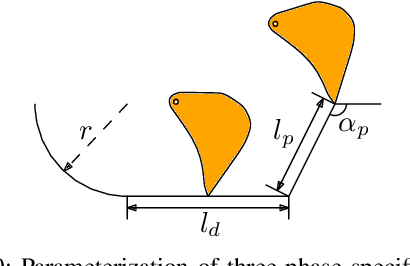
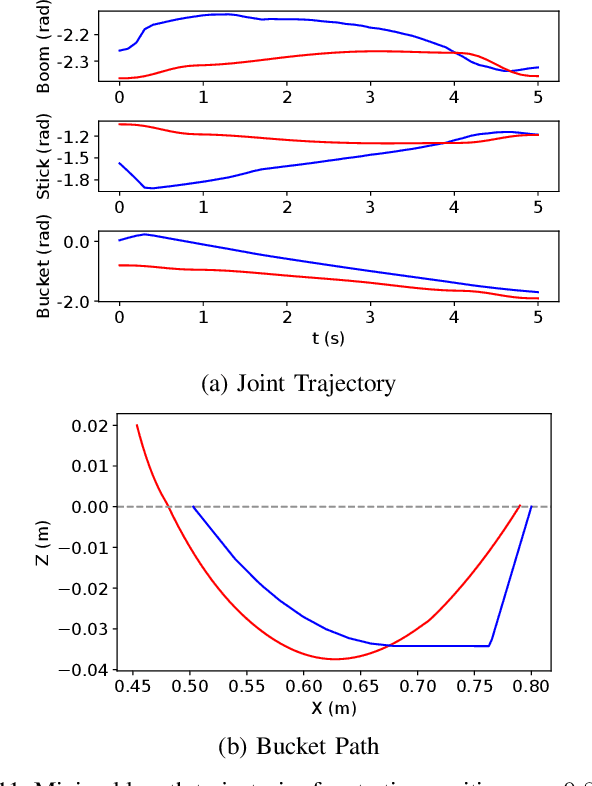
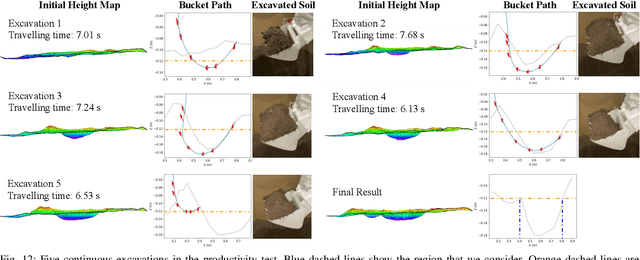
In this paper, we present a novel optimization-based framework for autonomous excavator trajectory generation under various objectives, including minimum joint displacement and minimum time. Traditional methods on excavation trajectory generation usually separate the excavation motion into a sequence of fixed phases, resulting in limited trajectory searching space. Our framework explores the space of all possible excavation trajectories represented with waypoints interpolated by a polynomial spline, thereby enabling optimization over a larger searching space. We formulate a generic task specification for excavation by constraining the instantaneous motion of the bucket and further add a target-oriented constraint, i.e. swept volume that indicates the estimated amount of excavated materials. To formulate time related objectives and constraints, we introduce time intervals between waypoints as variables into the optimization framework. We implement the proposed framework and evaluate its performance on a UR5 robotic arm. The experimental results demonstrate that the generated trajectories are able to excavate sufficient mass of soil for different terrain shapes and have 60% shorter minimal length than traditional excavation methods. We further compare our one-stage time optimal trajectory generation with the two-stage method. The result shows that trajectories generated by our one-stage method cost 18% less time on average.
VConstruct: Filling Gaps in Chl-a Data Using a Variational Autoencoder
Jan 25, 2021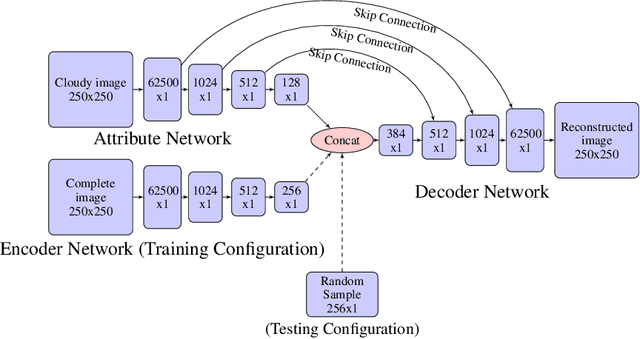
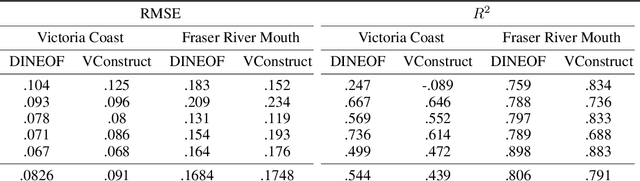
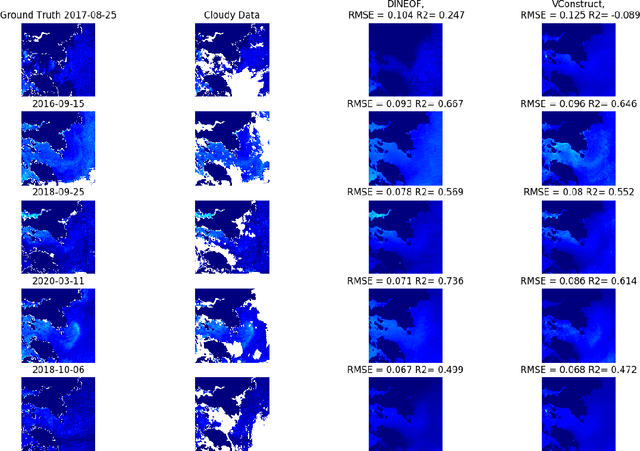
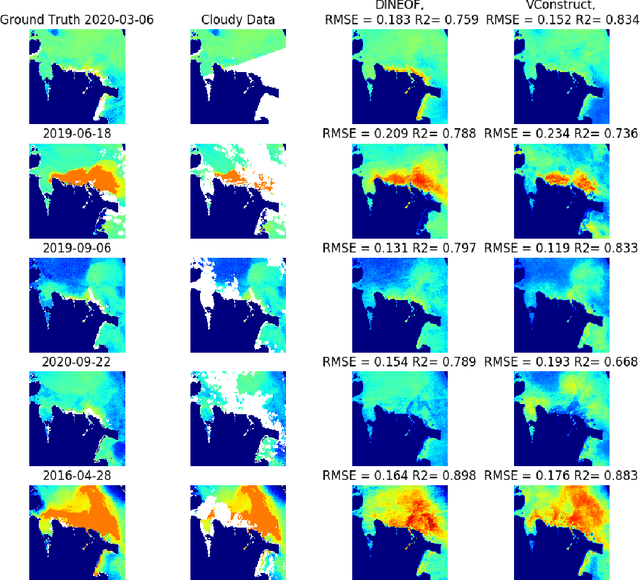
Remote sensing of Chlorophyll-a is vital in monitoring climate change. Chlorphyll-a measurements give us an idea of the algae concentrations in the ocean, which lets us monitor ocean health. However, a common problem is that the satellites used to gather the data are commonly obstructed by clouds and other artifacts. This means that time series data from satellites can suffer from spatial data loss. There are a number of algorithms that are able to reconstruct the missing parts of these images to varying degrees of accuracy, with Data INterpolating Empirical Orthogonal Functions (DINEOF) being the current standard. However, DINEOF is slow, suffers from accuracy loss in temporally homogenous waters, reliant on temporal data, and only able to generate a single potential reconstruction. We propose a machine learning approach to reconstruction of Chlorophyll-a data using a Variational Autoencoder (VAE). Our accuracy results to date are competitive with but slightly less accurate than DINEOF. We show the benefits of our method including vastly decreased computation time and ability to generate multiple potential reconstructions. Lastly, we outline our planned improvements and future work.
Adapting to Reward Progressivity via Spectral Reinforcement Learning
Apr 29, 2021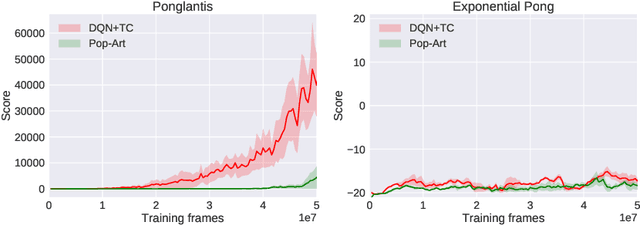
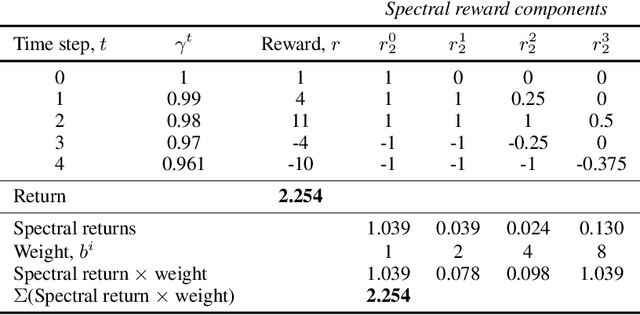


In this paper we consider reinforcement learning tasks with progressive rewards; that is, tasks where the rewards tend to increase in magnitude over time. We hypothesise that this property may be problematic for value-based deep reinforcement learning agents, particularly if the agent must first succeed in relatively unrewarding regions of the task in order to reach more rewarding regions. To address this issue, we propose Spectral DQN, which decomposes the reward into frequencies such that the high frequencies only activate when large rewards are found. This allows the training loss to be balanced so that it gives more even weighting across small and large reward regions. In two domains with extreme reward progressivity, where standard value-based methods struggle significantly, Spectral DQN is able to make much farther progress. Moreover, when evaluated on a set of six standard Atari games that do not overtly favour the approach, Spectral DQN remains more than competitive: While it underperforms one of the benchmarks in a single game, it comfortably surpasses the benchmarks in three games. These results demonstrate that the approach is not overfit to its target problem, and suggest that Spectral DQN may have advantages beyond addressing reward progressivity.
A Reinforcement Learning-based Economic Model Predictive Control Framework for Autonomous Operation of Chemical Reactors
May 06, 2021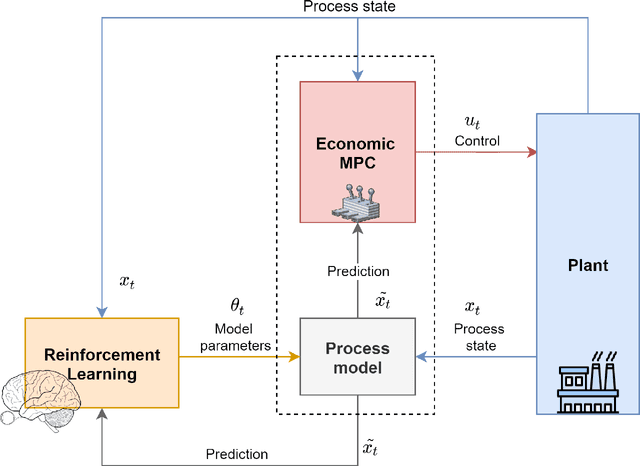

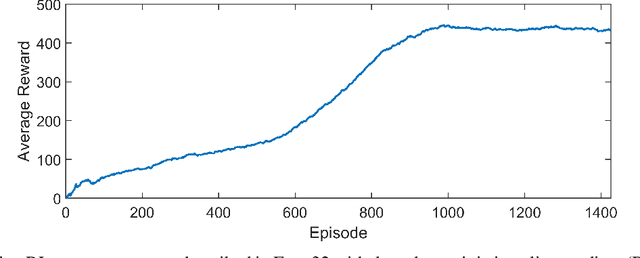
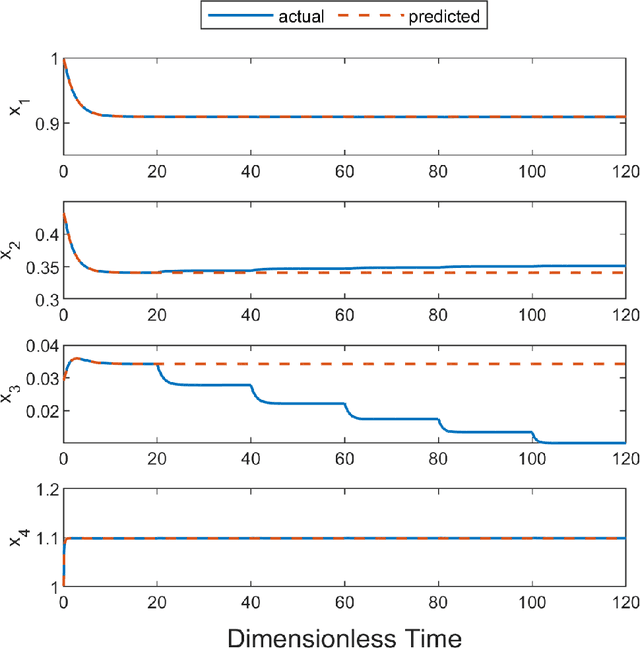
Economic model predictive control (EMPC) is a promising methodology for optimal operation of dynamical processes that has been shown to improve process economics considerably. However, EMPC performance relies heavily on the accuracy of the process model used. As an alternative to model-based control strategies, reinforcement learning (RL) has been investigated as a model-free control methodology, but issues regarding its safety and stability remain an open research challenge. This work presents a novel framework for integrating EMPC and RL for online model parameter estimation of a class of nonlinear systems. In this framework, EMPC optimally operates the closed loop system while maintaining closed loop stability and recursive feasibility. At the same time, to optimize the process, the RL agent continuously compares the measured state of the process with the model's predictions (nominal states), and modifies model parameters accordingly. The major advantage of this framework is its simplicity; state-of-the-art RL algorithms and EMPC schemes can be employed with minimal modifications. The performance of the proposed framework is illustrated on a network of reactions with challenging dynamics and practical significance. This framework allows control, optimization, and model correction to be performed online and continuously, making autonomous reactor operation more attainable.
Real-time Burst Photo Selection Using a Light-Head Adversarial Network
Mar 20, 2018
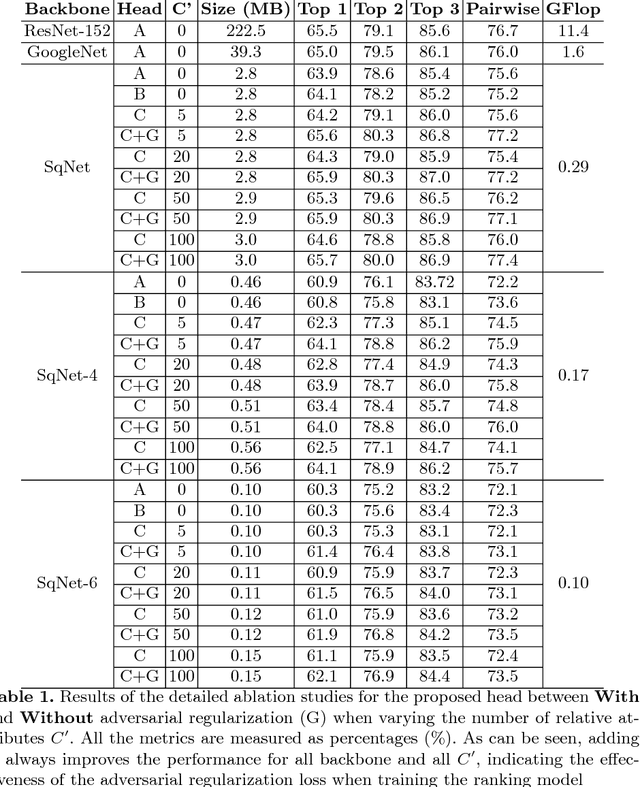
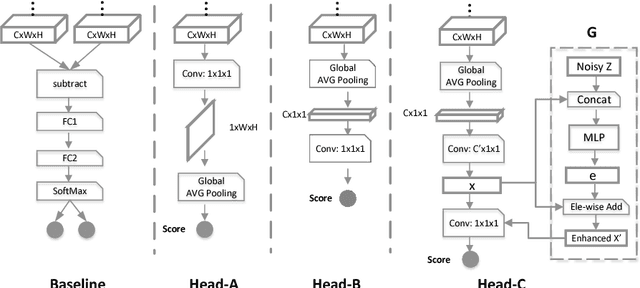
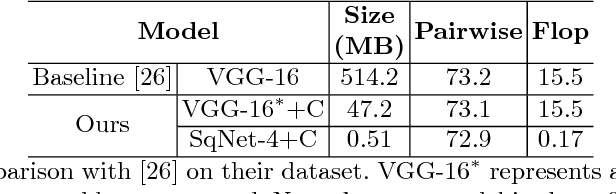
We present an automatic moment capture system that runs in real-time on mobile cameras. The system is designed to run in the viewfinder mode and capture a burst sequence of frames before and after the shutter is pressed. For each frame, the system predicts in real-time a "goodness" score, based on which the best moment in the burst can be selected immediately after the shutter is released, without any user interference. To solve the problem, we develop a highly efficient deep neural network ranking model, which implicitly learns a "latent relative attribute" space to capture subtle visual differences within a sequence of burst images. Then the overall goodness is computed as a linear aggregation of the goodnesses of all the latent attributes. The latent relative attributes and the aggregation function can be seamlessly integrated in one fully convolutional network and trained in an end-to-end fashion. To obtain a compact model which can run on mobile devices in real-time, we have explored and evaluated a wide range of network design choices, taking into account the constraints of model size, computational cost, and accuracy. Extensive studies show that the best frame predicted by our model hit users' top-1 (out of 11 on average) choice for $64.1\%$ cases and top-3 choices for $86.2\%$ cases. Moreover, the model(only 0.47M Bytes) can run in real time on mobile devices, e.g. only 13ms on iPhone 7 for one frame prediction.