 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparison of Dynamic and Kinematic Model Driven Extended Kalman Filters (EKF) for the Localization of Autonomous Underwater Vehicles
May 26, 2021
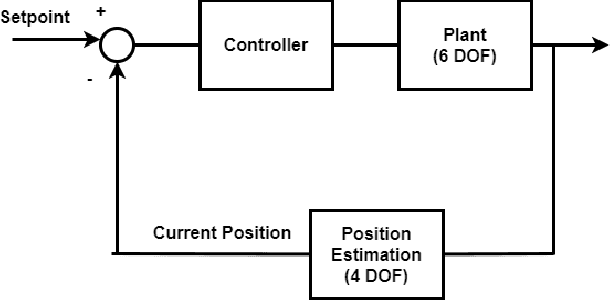
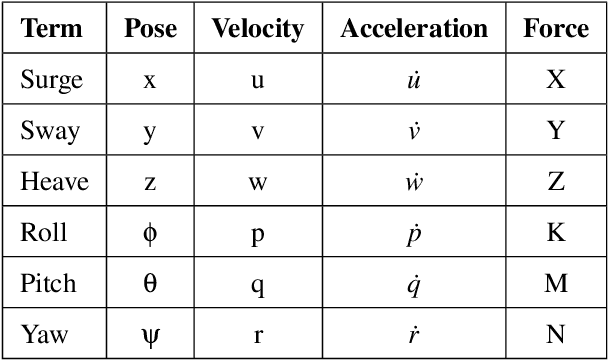
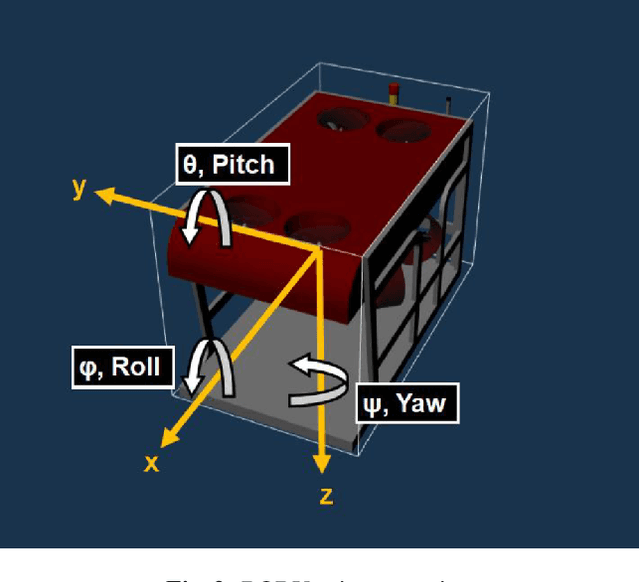
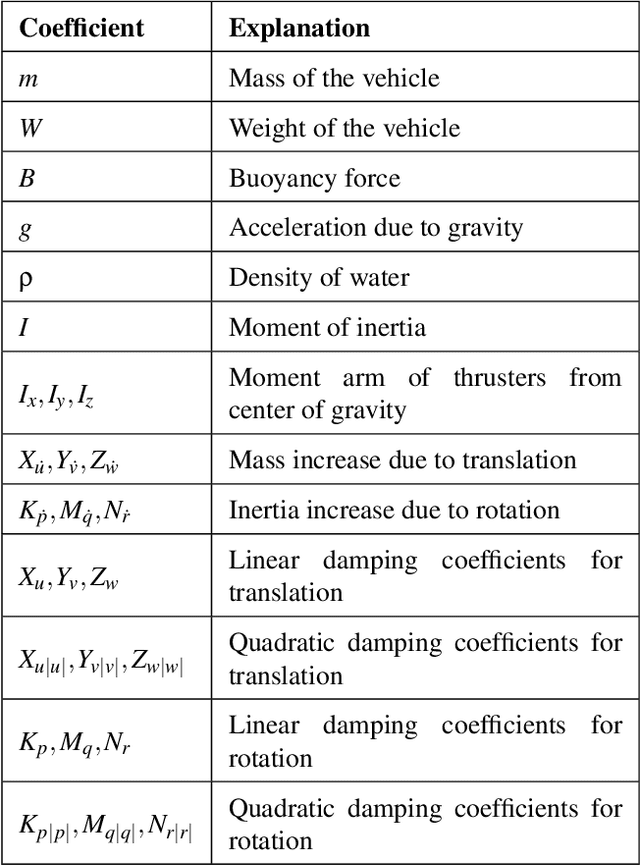
Autonomous Underwater Vehicles (AUVs) and Remotely Operated Vehicles (ROVs) are used for a wide variety of missions related to exploration and scientific research. Successful navigation by these systems requires a good localization system. Kalman filter based localization techniques have been prevalent since the early 1960s and extensive research has been carried out using them, both in development and in design. It has been found that the use of a dynamic model (instead of a kinematic model) in the Kalman filter can lead to more accurate predictions, as the dynamic model takes the forces acting on the AUV into account. Presented in this paper is a motion-predictive extended Kalman filter (EKF) for AUVs using a simplified dynamic model. The dynamic model is derived first and then it was simplified for a RexROV, a type of submarine vehicle used in simple underwater exploration, inspection of subsea structures, pipelines and shipwrecks. The filter was implemented with a simulated vehicle in an open-source marine vehicle simulator called UUV Simulator and the results were compared with the ground truth. The results show good prediction accuracy for the dynamic filter, though improvements are needed before the EKF can be used on real-time. Some perspective and discussion on practical implementation is presented to show the next steps needed for this concept.
Rapid COVID-19 Risk Screening by Eye-region Manifestations
Jun 12, 2021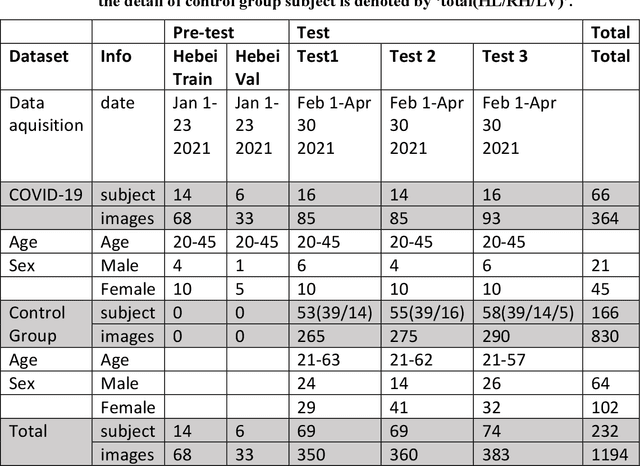

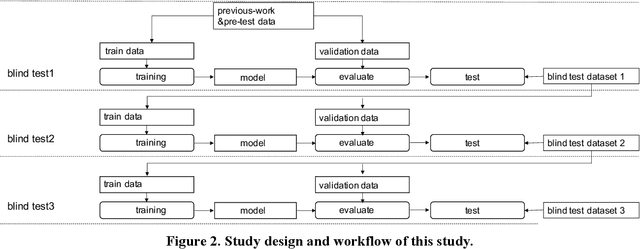
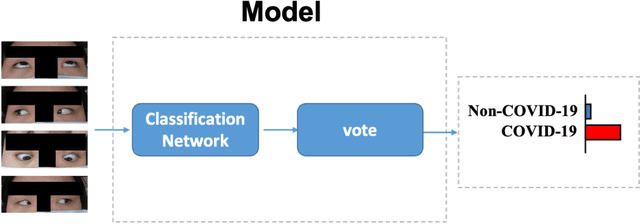
It is still nontrivial to develop a new fast COVID-19 screening method with the easier access and lower cost, due to the technical and cost limitations of the current testing methods in the medical resource-poor districts. On the other hand, there are more and more ocular manifestations that have been reported in the COVID-19 patients as growing clinical evidence[1]. This inspired this project. We have conducted the joint clinical research since January 2021 at the ShiJiaZhuang City, Heibei province, China, which approved by the ethics committee of The fifth hospital of ShiJiaZhuang of Hebei Medical University. We undertake several blind tests of COVID-19 patients by Union Hospital, Tongji Medical College, Huazhong University of Science and Technology, Wuhan, China. Meantime as an important part of the ongoing globally COVID-19 eye test program by AIMOMICS since February 2020, we propose a new fast screening method of analyzing the eye-region images, captured by common CCD and CMOS cameras. This could reliably make a rapid risk screening of COVID-19 with the sustainable stable high performance in different countries and races. Our model for COVID-19 rapid prescreening have the merits of the lower cost, fully self-performed, non-invasive, importantly real-time, and thus enables the continuous health surveillance. We further implement it as the open accessible APIs, and provide public service to the world. Our pilot experiments show that our model is ready to be usable to all kinds of surveillance scenarios, such as infrared temperature measurement device at airports and stations, or directly pushing to the target people groups smartphones as a packaged application.
Neural Weighted A*: Learning Graph Costs and Heuristics with Differentiable Anytime A*
May 04, 2021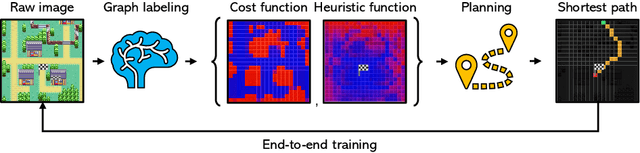

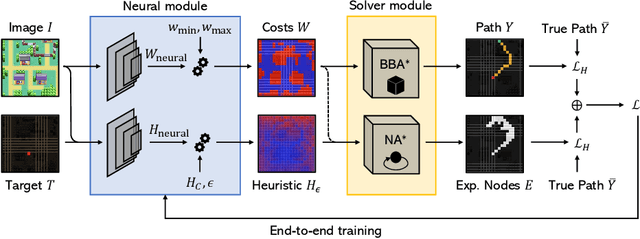

Recently, the trend of incorporating differentiable algorithms into deep learning architectures arose in machine learning research, as the fusion of neural layers and algorithmic layers has been beneficial for handling combinatorial data, such as shortest paths on graphs. Recent works related to data-driven planning aim at learning either cost functions or heuristic functions, but not both. We propose Neural Weighted A*, a differentiable anytime planner able to produce improved representations of planar maps as graph costs and heuristics. Training occurs end-to-end on raw images with direct supervision on planning examples, thanks to a differentiable A* solver integrated into the architecture. More importantly, the user can trade off planning accuracy for efficiency at run-time, using a single, real-valued parameter. The solution suboptimality is constrained within a linear bound equal to the optimal path cost multiplied by the tradeoff parameter. We experimentally show the validity of our claims by testing Neural Weighted A* against several baselines, introducing a novel, tile-based navigation dataset. We outperform similar architectures in planning accuracy and efficiency.
A Novel Apex-Time Network for Cross-Dataset Micro-Expression Recognition
Apr 10, 2019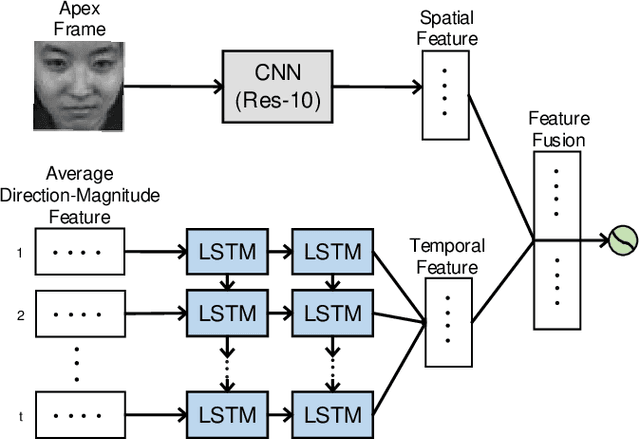
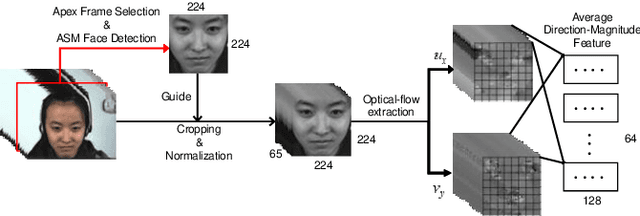
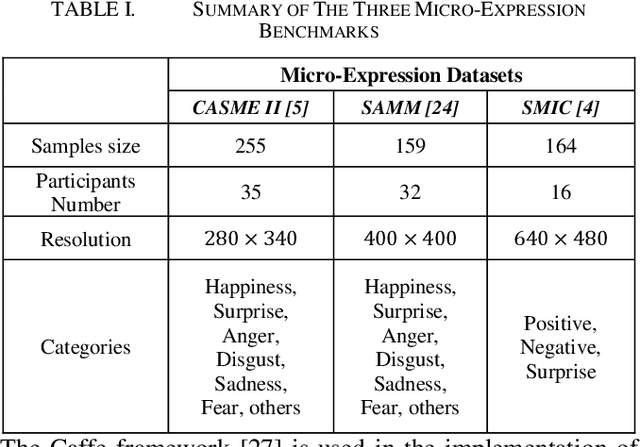
The automatic recognition of micro-expression has been boosted ever since the successful introduction of deep learning approaches. Whilst researchers working on such topics are more and more tending to learn from the nature of micro-expression, the practice of using deep learning techniques has evolved from processing the entire video clip of micro-expression to the recognition on apex frame. Using apex frame is able to get rid of redundant information but the temporal evidence of micro-expression would be thereby left out. In this paper, we propose to do the recognition based on the spatial information from apex frame as well as on the temporal information from respective-adjacent frames. As such, a novel Apex-Time Network (ATNet) is proposed. Through extensive experiments on three benchmarks, we demonstrate the improvement achieved by adding the temporal information learned from adjacent frames around the apex frame. Specially, the model with such temporal information is more robust in cross-dataset validations.
Uncertainty Surrogates for Deep Learning
Apr 16, 2021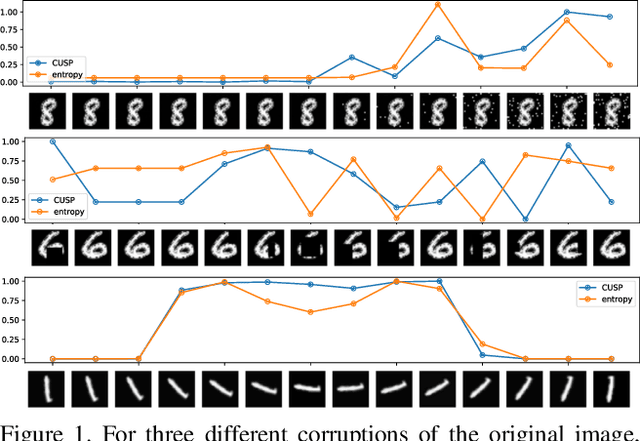


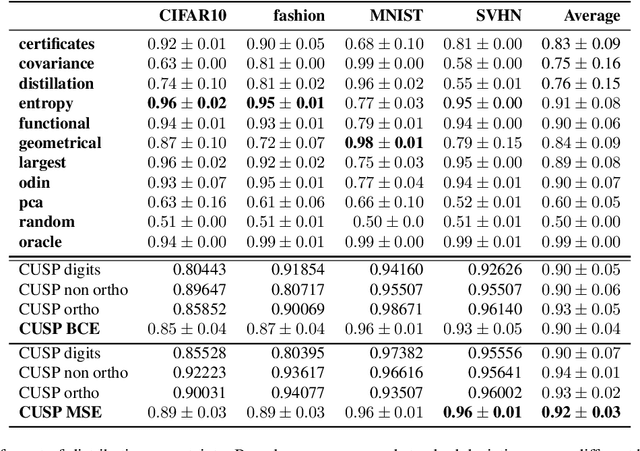
In this paper we introduce a novel way of estimating prediction uncertainty in deep networks through the use of uncertainty surrogates. These surrogates are features of the penultimate layer of a deep network that are forced to match predefined patterns. The patterns themselves can be, among other possibilities, a known visual symbol. We show how our approach can be used for estimating uncertainty in prediction and out-of-distribution detection. Additionally, the surrogates allow for interpretability of the ability of the deep network to learn and at the same time lend robustness against adversarial attacks. Despite its simplicity, our approach is superior to the state-of-the-art approaches on standard metrics as well as computational efficiency and ease of implementation. A wide range of experiments are performed on standard datasets to prove the efficacy of our approach.
XY Neural Networks
Mar 31, 2021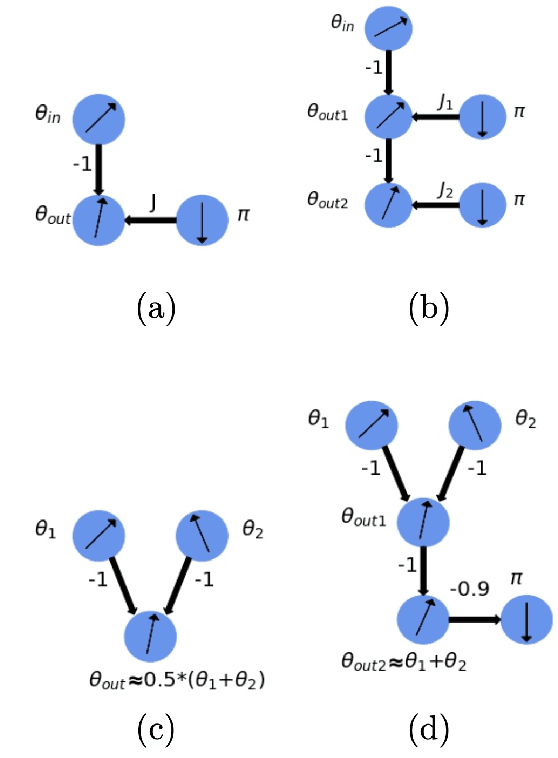
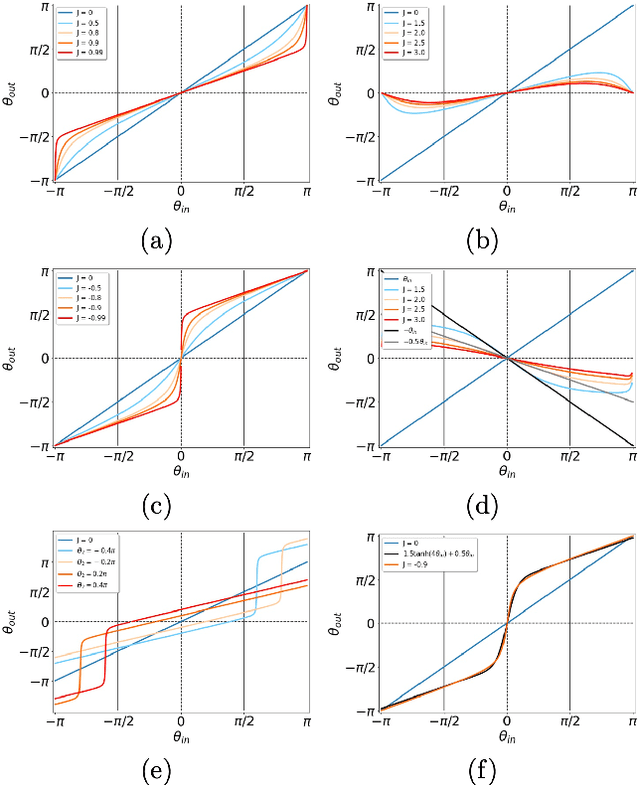
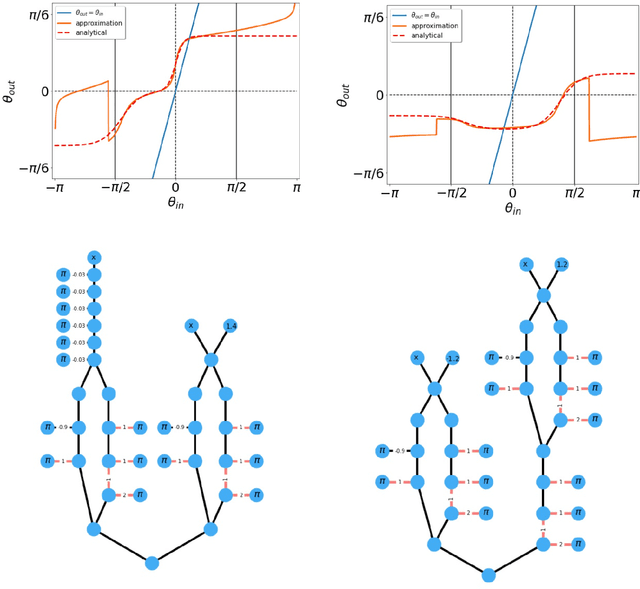
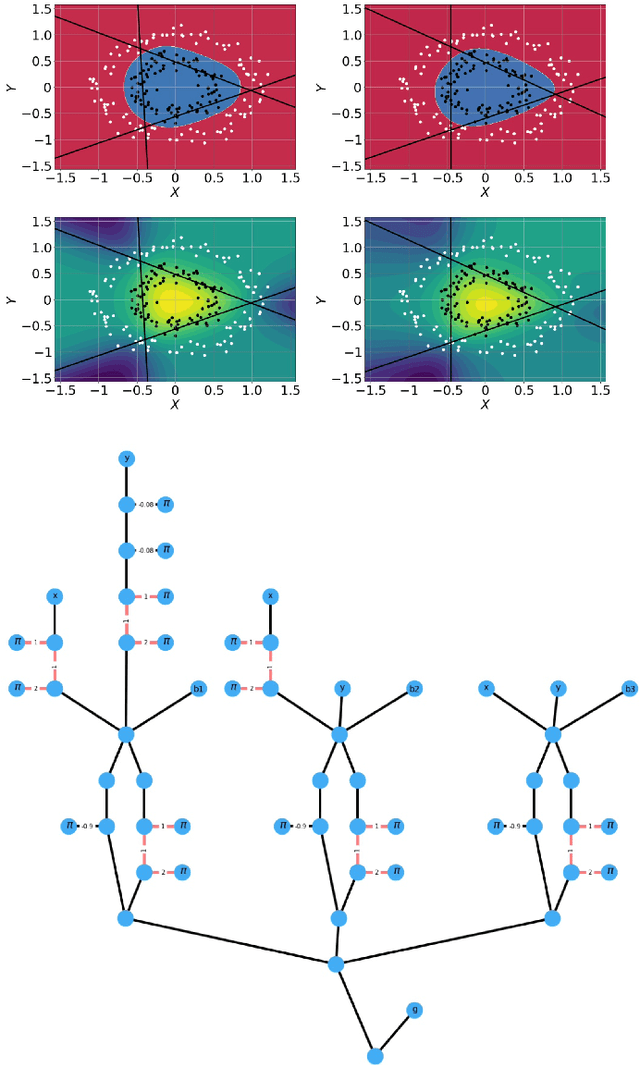
The classical XY model is a lattice model of statistical mechanics notable for its universality in the rich hierarchy of the optical, laser and condensed matter systems. We show how to build complex structures for machine learning based on the XY model's nonlinear blocks. The final target is to reproduce the deep learning architectures, which can perform complicated tasks usually attributed to such architectures: speech recognition, visual processing, or other complex classification types with high quality. We developed the robust and transparent approach for the construction of such models, which has universal applicability (i.e. does not strongly connect to any particular physical system), allows many possible extensions while at the same time preserving the simplicity of the methodology.
Equivalence of Correlation Filter and Convolution Filter in Visual Tracking
May 04, 2021(Discriminative) Correlation Filter has been successfully applied to visual tracking and has advanced the field significantly in recent years. Correlation filter-based trackers consider visual tracking as a problem of matching the feature template of the object and candidate regions in the detection sample, in which correlation filter provides the means to calculate the similarities. In contrast, convolution filter is usually used for blurring, sharpening, embossing, edge detection, etc in image processing. On the surface, correlation filter and convolution filter are usually used for different purposes. In this paper, however, we proves, for the first time, that correlation filter and convolution filter are equivalent in the sense that their minimum mean-square errors (MMSEs) in visual tracking are equal, under the condition that the optimal solutions exist and the ideal filter response is Gaussian and centrosymmetric. This result gives researchers the freedom to choose correlation or convolution in formulating their trackers. It also suggests that the explanation of the ideal response in terms of similarities is not essential.
DiSECt: A Differentiable Simulation Engine for Autonomous Robotic Cutting
May 25, 2021
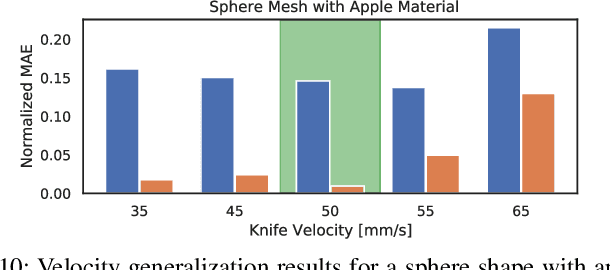
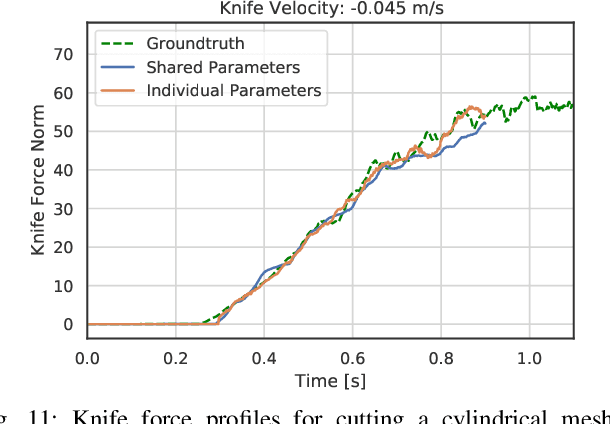
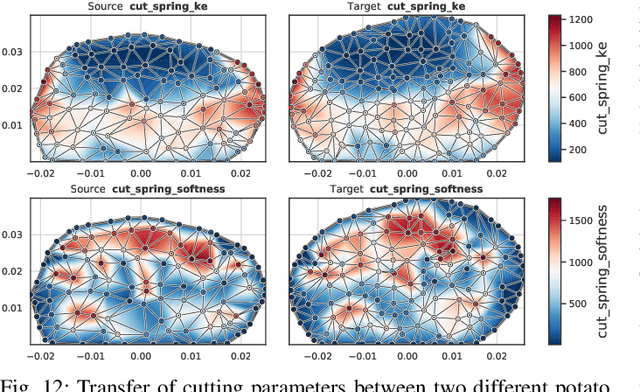
Robotic cutting of soft materials is critical for applications such as food processing, household automation, and surgical manipulation. As in other areas of robotics, simulators can facilitate controller verification, policy learning, and dataset generation. Moreover, differentiable simulators can enable gradient-based optimization, which is invaluable for calibrating simulation parameters and optimizing controllers. In this work, we present DiSECt: the first differentiable simulator for cutting soft materials. The simulator augments the finite element method (FEM) with a continuous contact model based on signed distance fields (SDF), as well as a continuous damage model that inserts springs on opposite sides of the cutting plane and allows them to weaken until zero stiffness, enabling crack formation. Through various experiments, we evaluate the performance of the simulator. We first show that the simulator can be calibrated to match resultant forces and deformation fields from a state-of-the-art commercial solver and real-world cutting datasets, with generality across cutting velocities and object instances. We then show that Bayesian inference can be performed efficiently by leveraging the differentiability of the simulator, estimating posteriors over hundreds of parameters in a fraction of the time of derivative-free methods. Finally, we illustrate that control parameters in the simulation can be optimized to minimize cutting forces via lateral slicing motions. We publish videos and additional results on our project website at https://diff-cutting-sim.github.io.
Scaling the Convex Barrier with Active Sets
Jan 14, 2021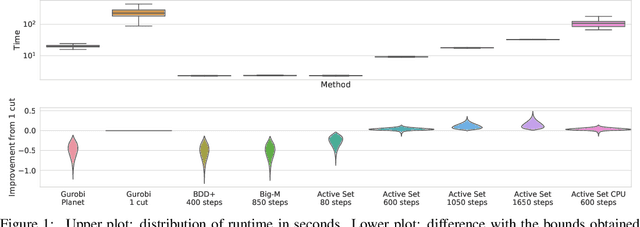
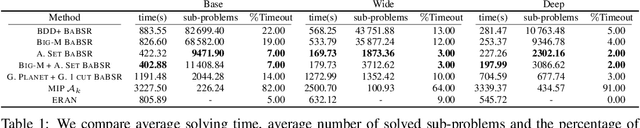
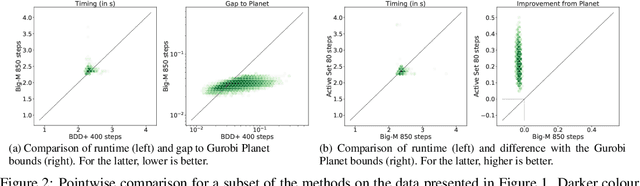
Tight and efficient neural network bounding is of critical importance for the scaling of neural network verification systems. A number of efficient specialised dual solvers for neural network bounds have been presented recently, but they are often too loose to verify more challenging properties. This lack of tightness is linked to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise linear activations exists, it comes at the cost of exponentially many constraints and thus currently lacks an efficient customised solver. We alleviate this deficiency via a novel dual algorithm that realises the full potential of the new relaxation by operating on a small active set of dual variables. Our method recovers the strengths of the new relaxation in the dual space: tightness and a linear separation oracle. At the same time, it shares the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we obtain better bounds than off-the-shelf solvers in only a fraction of their running time and recover the speed-accuracy trade-offs of looser dual solvers if the computational budget is small. We demonstrate that this results in significant formal verification speed-ups.
Language Detection Engine for Multilingual Texting on Mobile Devices
Jan 07, 2021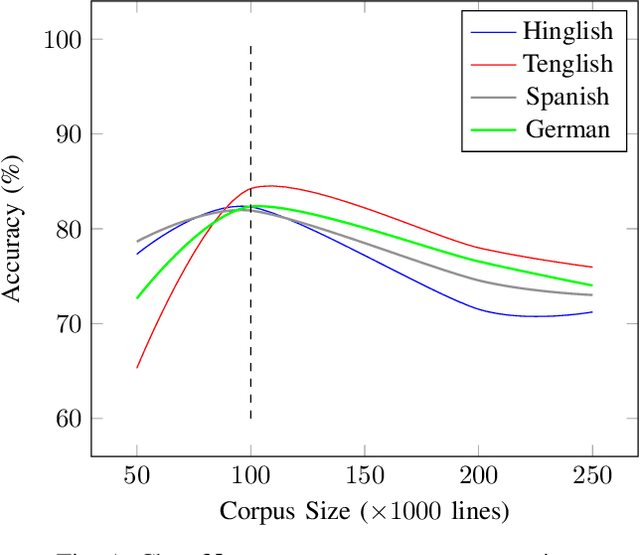
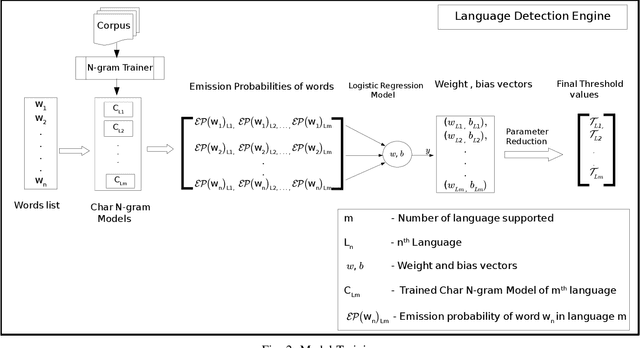
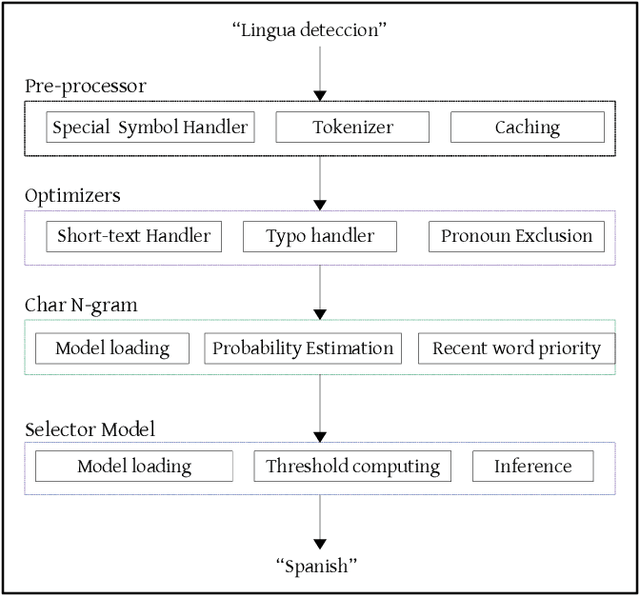
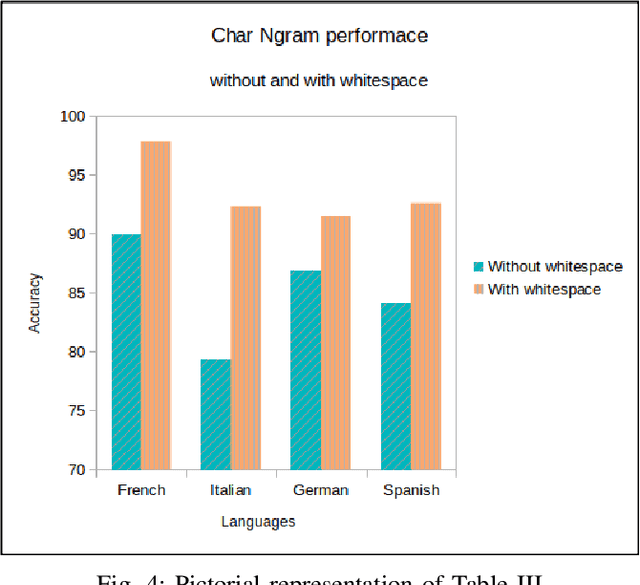
More than 2 billion mobile users worldwide type in multiple languages in the soft keyboard. On a monolingual keyboard, 38% of falsely auto-corrected words are valid in another language. This can be easily avoided by detecting the language of typed words and then validating it in its respective language. Language detection is a well-known problem in natural language processing. In this paper, we present a fast, light-weight and accurate Language Detection Engine (LDE) for multilingual typing that dynamically adapts to user intended language in real-time. We propose a novel approach where the fusion of character N-gram model and logistic regression based selector model is used to identify the language. Additionally, we present a unique method of reducing the inference time significantly by parameter reduction technique. We also discuss various optimizations fabricated across LDE to resolve ambiguity in input text among the languages with the same character pattern. Our method demonstrates an average accuracy of 94.5% for Indian languages in Latin script and that of 98% for European languages on the code-switched data. This model outperforms fastText by 60.39% and ML-Kit by 23.67% in F1 score for European languages. LDE is faster on mobile device with an average inference time of 25.91 microseconds.
* 2020 IEEE 14th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/9031474