 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems
Jun 28, 2021
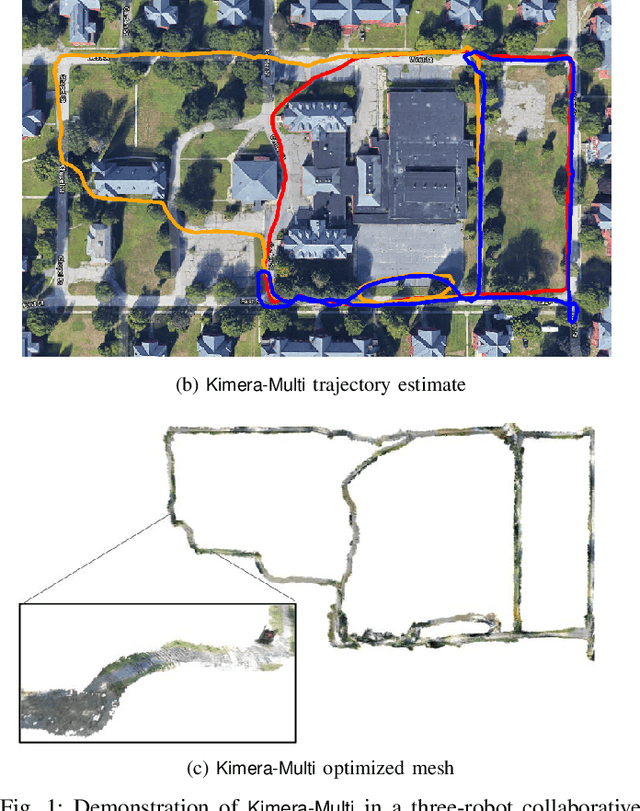
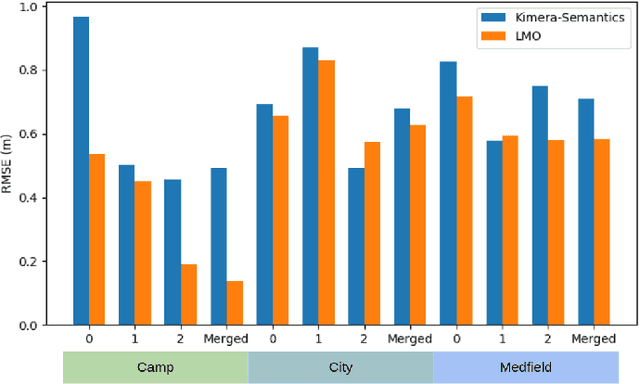
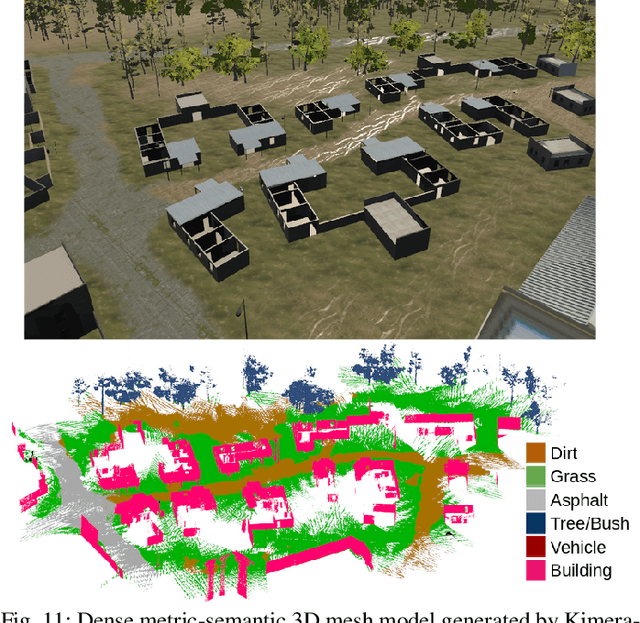

This paper presents Kimera-Multi, the first multi-robot system that (i) is robust and capable of identifying and rejecting incorrect inter and intra-robot loop closures resulting from perceptual aliasing, (ii) is fully distributed and only relies on local (peer-to-peer) communication to achieve distributed localization and mapping, and (iii) builds a globally consistent metric-semantic 3D mesh model of the environment in real-time, where faces of the mesh are annotated with semantic labels. Kimera-Multi is implemented by a team of robots equipped with visual-inertial sensors. Each robot builds a local trajectory estimate and a local mesh using Kimera. When communication is available, robots initiate a distributed place recognition and robust pose graph optimization protocol based on a novel distributed graduated non-convexity algorithm. The proposed protocol allows the robots to improve their local trajectory estimates by leveraging inter-robot loop closures while being robust to outliers. Finally, each robot uses its improved trajectory estimate to correct the local mesh using mesh deformation techniques. We demonstrate Kimera-Multi in photo-realistic simulations, SLAM benchmarking datasets, and challenging outdoor datasets collected using ground robots. Both real and simulated experiments involve long trajectories (e.g., up to 800 meters per robot). The experiments show that Kimera-Multi (i) outperforms the state of the art in terms of robustness and accuracy, (ii) achieves estimation errors comparable to a centralized SLAM system while being fully distributed, (iii) is parsimonious in terms of communication bandwidth, (iv) produces accurate metric-semantic 3D meshes, and (v) is modular and can be also used for standard 3D reconstruction (i.e., without semantic labels) or for trajectory estimation (i.e., without reconstructing a 3D mesh).
An Upper Confidence Bound for Simultaneous Exploration and Exploitation in Heterogeneous Multi-Robot Systems
May 13, 2021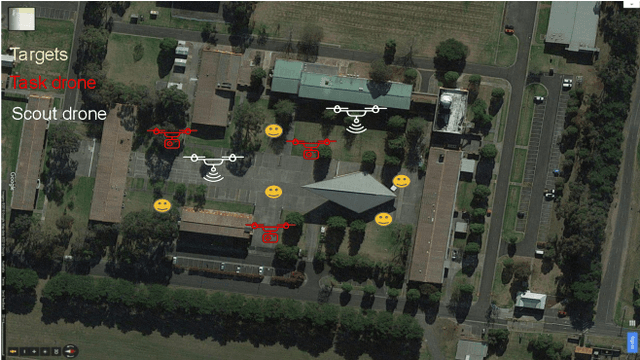
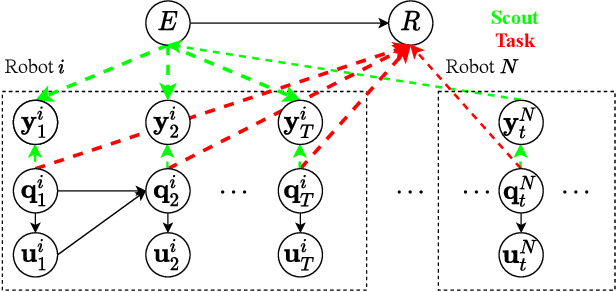
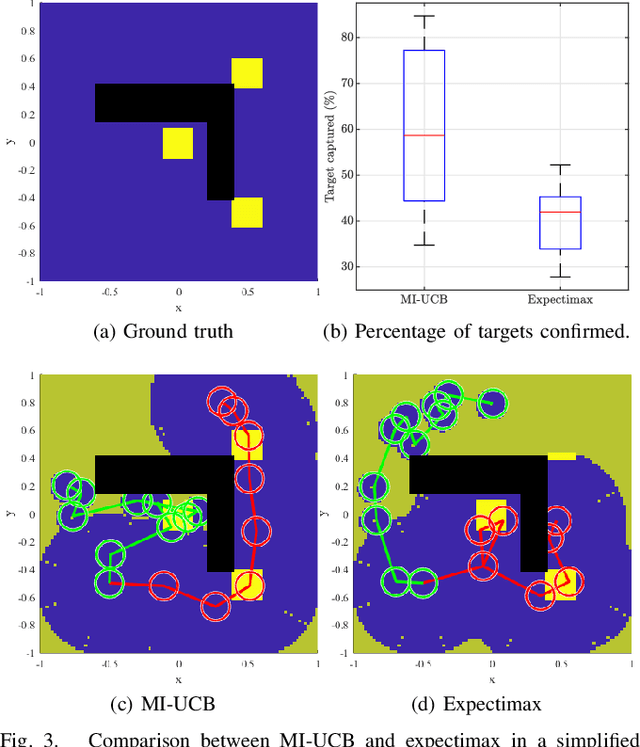
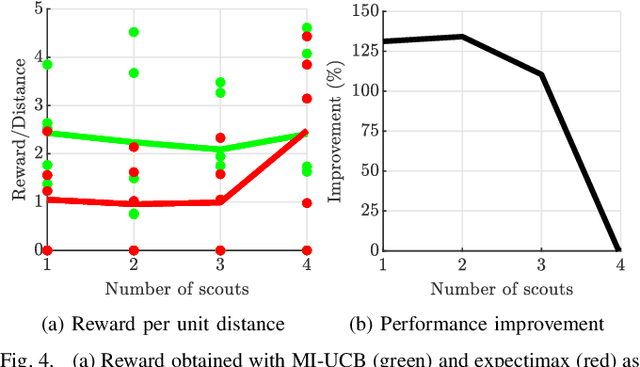
Heterogeneous multi-robot systems are advantageous for operations in unknown environments because functionally specialised robots can gather environmental information, while others perform tasks. We define this decomposition as the scout-task robot architecture and show how it avoids the need to explicitly balance exploration and exploitation~by permitting the system to do both simultaneously. The challenge is to guide exploration in a way that improves overall performance for time-limited tasks. We derive a novel upper confidence bound for simultaneous exploration and exploitation based on mutual information and present a general solution for scout-task coordination using decentralised Monte Carlo tree search. We evaluate the performance of our algorithms in a multi-drone surveillance scenario in which scout robots are equipped with low-resolution, long-range sensors and task robots capture detailed information using short-range sensors. The results address a new class of coordination problem for heterogeneous teams that has many practical applications.
Fair and Optimal Cohort Selection for Linear Utilities
Feb 15, 2021The rise of algorithmic decision-making has created an explosion of research around the fairness of those algorithms. While there are many compelling notions of individual fairness, beginning with the work of Dwork et al., these notions typically do not satisfy desirable composition properties. To this end, Dwork and Ilvento introduced the fair cohort selection problem, which captures a specific application where a single fair classifier is composed with itself to pick a group of candidates of size exactly $k$. In this work we introduce a specific instance of cohort selection where the goal is to choose a cohort maximizing a linear utility function. We give approximately optimal polynomial-time algorithms for this problem in both an offline setting where the entire fair classifier is given at once, or an online setting where candidates arrive one at a time and are classified as they arrive.
Data-Driven MPC for Quadrotors
Feb 10, 2021
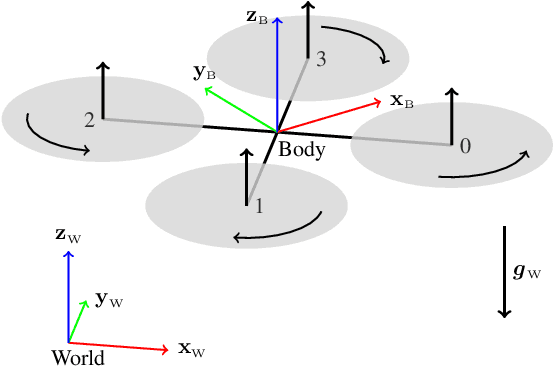
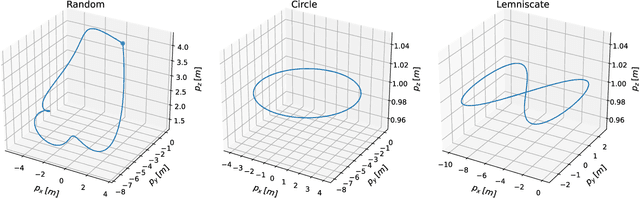
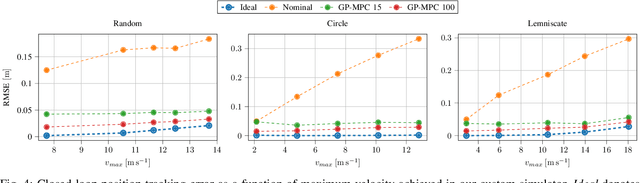
Aerodynamic forces render accurate high-speed trajectory tracking with quadrotors extremely challenging. These complex aerodynamic effects become a significant disturbance at high speeds, introducing large positional tracking errors, and are extremely difficult to model. To fly at high speeds, feedback control must be able to account for these aerodynamic effects in real-time. This necessitates a modelling procedure that is both accurate and efficient to evaluate. Therefore, we present an approach to model aerodynamic effects using Gaussian Processes, which we incorporate into a Model Predictive Controller to achieve efficient and precise real-time feedback control, leading to up to 70% reduction in trajectory tracking error at high speeds. We verify our method by extensive comparison to a state-of-the-art linear drag model in synthetic and real-world experiments at speeds of up to 14m/s and accelerations beyond 4g.
* 8 pages
Facility Reallocation on the Line
Mar 23, 2021
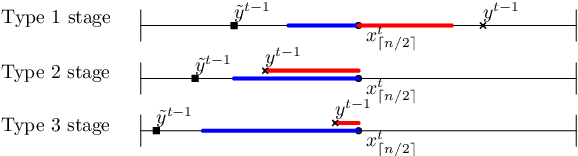
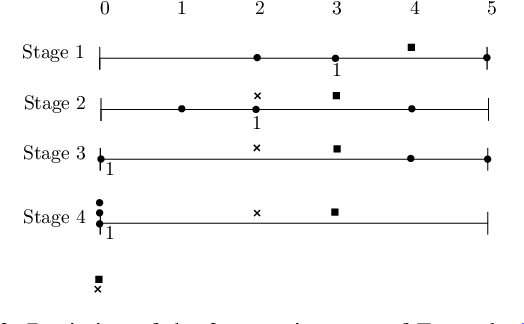
We consider a multi-stage facility reallocation problems on the real line, where a facility is being moved between time stages based on the locations reported by $n$ agents. The aim of the reallocation algorithm is to minimise the social cost, i.e., the sum over the total distance between the facility and all agents at all stages, plus the cost incurred for moving the facility. We study this problem both in the offline setting and online setting. In the offline case the algorithm has full knowledge of the agent locations in all future stages, and in the online setting the algorithm does not know these future locations and must decide the location of the facility on a stage-per-stage basis. We derive the optimal algorithm in both cases. For the online setting we show that its competitive ratio is $(n+2)/(n+1)$. As neither of these algorithms turns out to yield a strategy-proof mechanism, we propose another strategy-proof mechanism which has a competitive ratio of $(n+3)/(n+1)$ for odd $n$ and $(n+4)/n$ for even $n$, which we conjecture to be the best possible. We also consider a generalisation with multiple facilities and weighted agents, for which we show that the optimum can be computed in polynomial time for a fixed number of facilities.
Faster Kernel Interpolation for Gaussian Processes
Jan 28, 2021
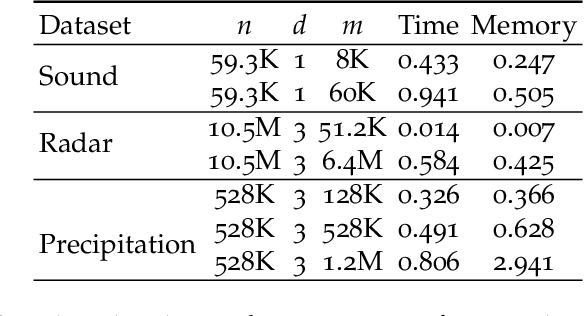

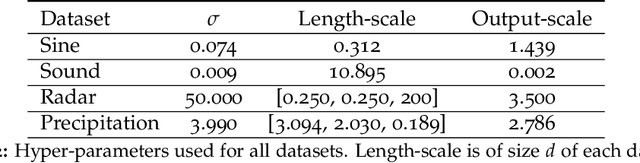
A key challenge in scaling Gaussian Process (GP) regression to massive datasets is that exact inference requires computation with a dense n x n kernel matrix, where n is the number of data points. Significant work focuses on approximating the kernel matrix via interpolation using a smaller set of m inducing points. Structured kernel interpolation (SKI) is among the most scalable methods: by placing inducing points on a dense grid and using structured matrix algebra, SKI achieves per-iteration time of O(n + m log m) for approximate inference. This linear scaling in n enables inference for very large data sets; however the cost is per-iteration, which remains a limitation for extremely large n. We show that the SKI per-iteration time can be reduced to O(m log m) after a single O(n) time precomputation step by reframing SKI as solving a natural Bayesian linear regression problem with a fixed set of m compact basis functions. With per-iteration complexity independent of the dataset size n for a fixed grid, our method scales to truly massive data sets. We demonstrate speedups in practice for a wide range of m and n and apply the method to GP inference on a three-dimensional weather radar dataset with over 100 million points.
On Explaining Random Forests with SAT
May 21, 2021
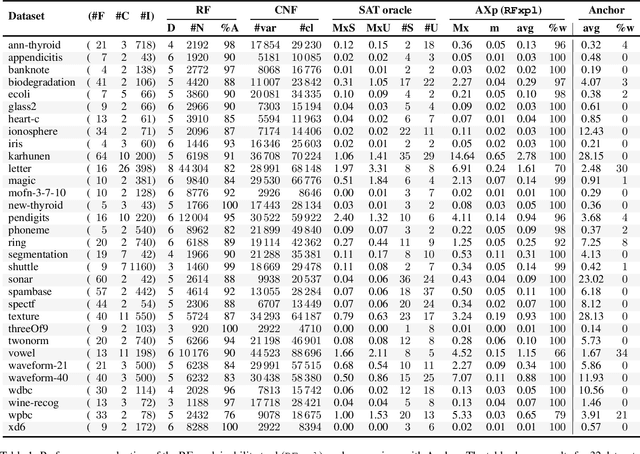
Random Forest (RFs) are among the most widely used Machine Learning (ML) classifiers. Even though RFs are not interpretable, there are no dedicated non-heuristic approaches for computing explanations of RFs. Moreover, there is recent work on polynomial algorithms for explaining ML models, including naive Bayes classifiers. Hence, one question is whether finding explanations of RFs can be solved in polynomial time. This paper answers this question negatively, by proving that computing one PI-explanation of an RF is D^P-complete. Furthermore, the paper proposes a propositional encoding for computing explanations of RFs, thus enabling finding PI-explanations with a SAT solver. This contrasts with earlier work on explaining boosted trees (BTs) and neural networks (NNs), which requires encodings based on SMT/MILP. Experimental results, obtained on a wide range of publicly available datasets, demontrate that the proposed SAT-based approach scales to RFs of sizes common in practical applications. Perhaps more importantly, the experimental results demonstrate that, for the vast majority of examples considered, the SAT-based approach proposed in this paper significantly outperforms existing heuristic approaches.
VisioRed: A Visualisation Tool for Interpretable Predictive Maintenance
Mar 31, 2021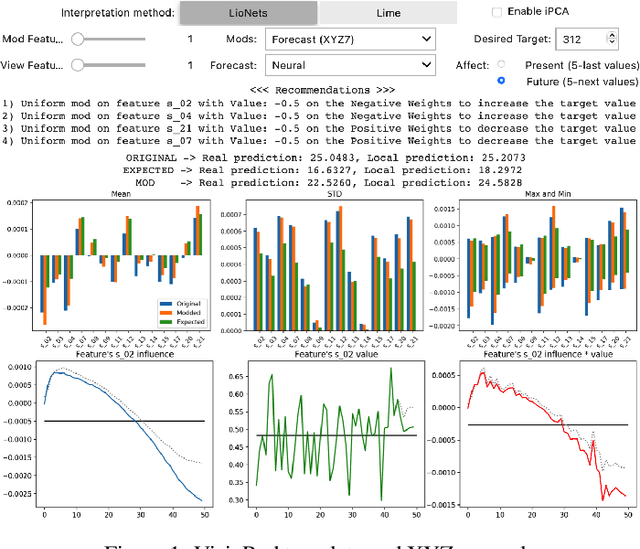
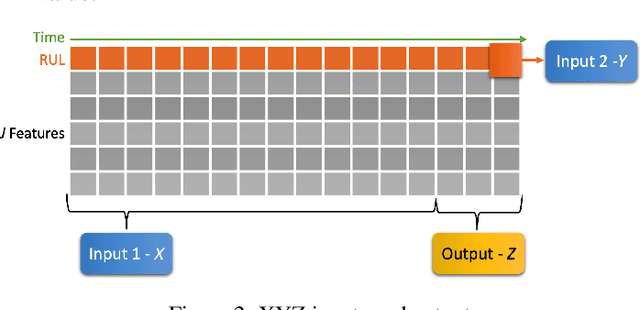
The use of machine learning rapidly increases in high-risk scenarios where decisions are required, for example in healthcare or industrial monitoring equipment. In crucial situations, a model that can offer meaningful explanations of its decision-making is essential. In industrial facilities, the equipment's well-timed maintenance is vital to ensure continuous operation to prevent money loss. Using machine learning, predictive and prescriptive maintenance attempt to anticipate and prevent eventual system failures. This paper introduces a visualisation tool incorporating interpretations to display information derived from predictive maintenance models, trained on time-series data.
Combining Coarse and Fine Physics for Manipulation using Parallel-in-Time Integration
Mar 20, 2019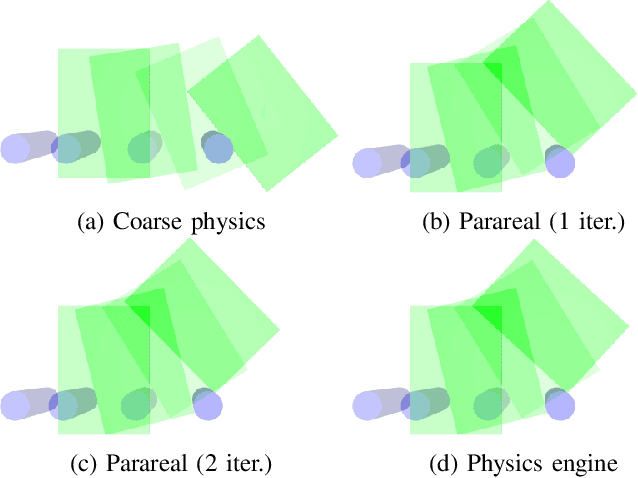

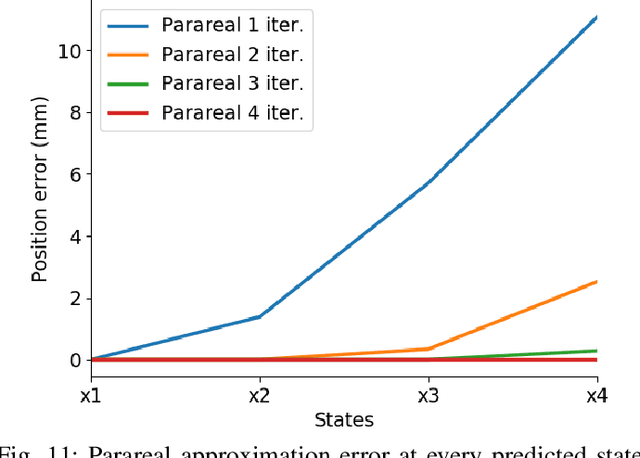
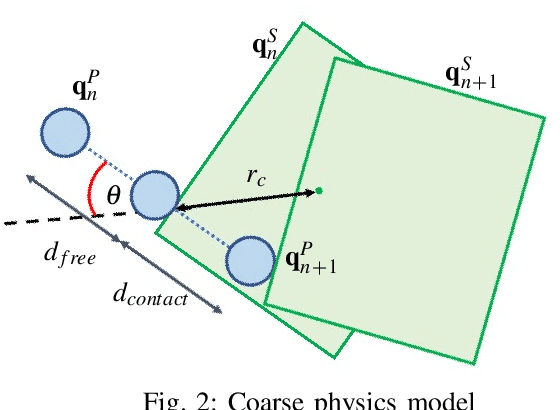
We present a method for fast and accurate physics-based predictions during non-prehensile manipulation planning and control. Given an initial state and a sequence of controls, the problem of predicting the resulting sequence of states is a key component of a variety of model-based planning and control algorithms. We propose combining a coarse (i.e. computationally cheap but not very accurate) predictive physics model, with a fine (i.e. computationally expensive but accurate) predictive physics model, to generate a hybrid model that is at the required speed and accuracy for a given manipulation task. Our approach is based on the Parareal algorithm, a parallel-in-time integration method used for computing numerical solutions for general systems of ordinary differential equations. We use Parareal to combine a coarse pushing model with an off-the-shelf physics engine to deliver physics-based predictions that are as accurate as the physics engine but runs in substantially less wall-clock time, thanks to Parareal being amenable to parallelization. We use these physics-based predictions in a model-predictive-control framework based on trajectory optimization, to plan pushing actions that avoid an obstacle and reach a goal location. We show that by combining the two physics models, we can achieve the same success rates as the planner that uses the off-the-shelf physics engine directly, but significantly faster. We present experiments in simulation and on a real robotic setup.
Graph Deep Factors for Forecasting
Oct 14, 2020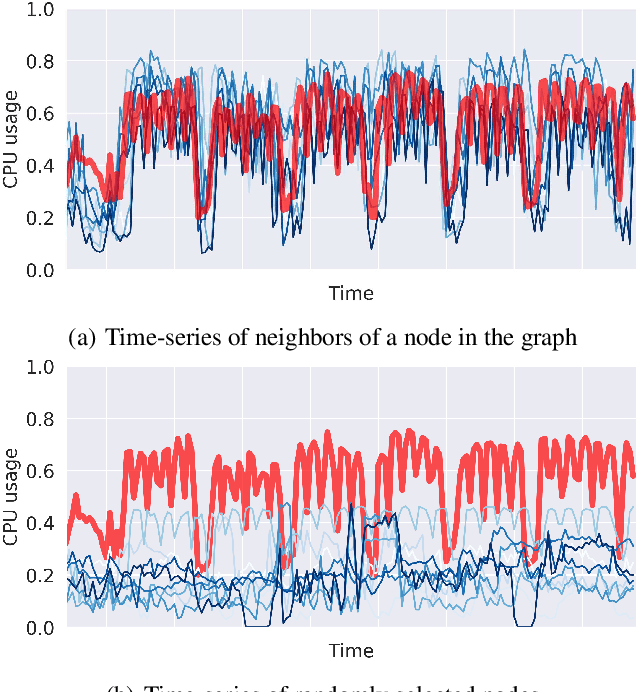
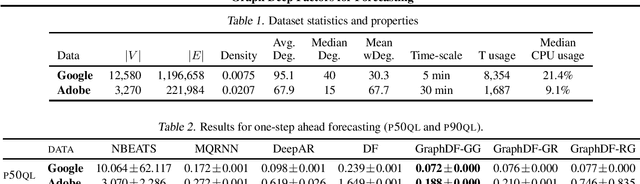

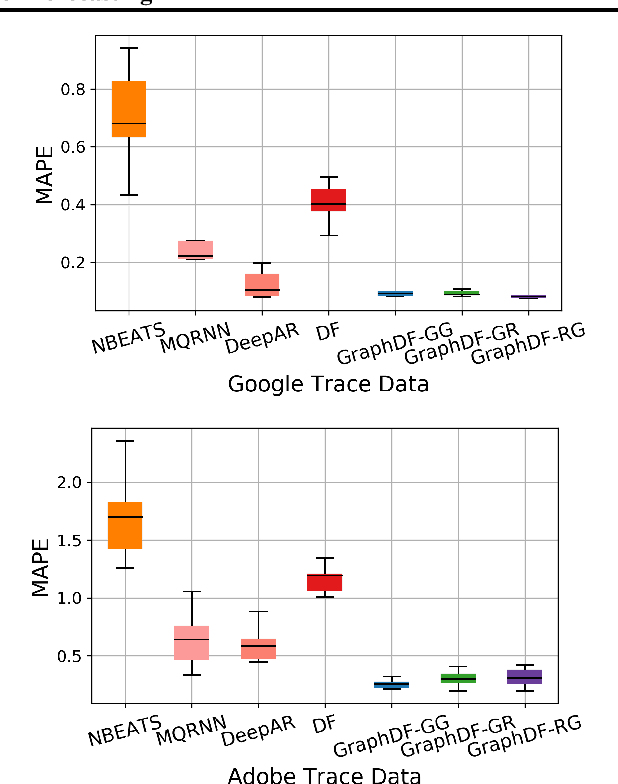
Deep probabilistic forecasting techniques have recently been proposed for modeling large collections of time-series. However, these techniques explicitly assume either complete independence (local model) or complete dependence (global model) between time-series in the collection. This corresponds to the two extreme cases where every time-series is disconnected from every other time-series in the collection or likewise, that every time-series is related to every other time-series resulting in a completely connected graph. In this work, we propose a deep hybrid probabilistic graph-based forecasting framework called Graph Deep Factors (GraphDF) that goes beyond these two extremes by allowing nodes and their time-series to be connected to others in an arbitrary fashion. GraphDF is a hybrid forecasting framework that consists of a relational global and relational local model. In particular, we propose a relational global model that learns complex non-linear time-series patterns globally using the structure of the graph to improve both forecasting accuracy and computational efficiency. Similarly, instead of modeling every time-series independently, we learn a relational local model that not only considers its individual time-series but also the time-series of nodes that are connected in the graph. The experiments demonstrate the effectiveness of the proposed deep hybrid graph-based forecasting model compared to the state-of-the-art methods in terms of its forecasting accuracy, runtime, and scalability. Our case study reveals that GraphDF can successfully generate cloud usage forecasts and opportunistically schedule workloads to increase cloud cluster utilization by 47.5% on average.