 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GDP: Stabilized Neural Network Pruning via Gates with Differentiable Polarization
Sep 08, 2021
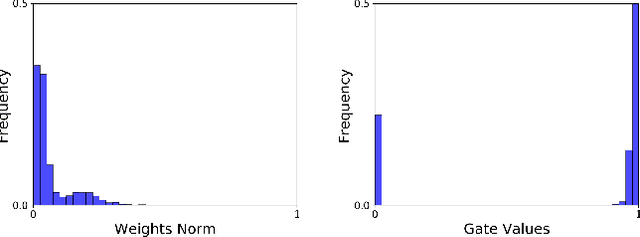

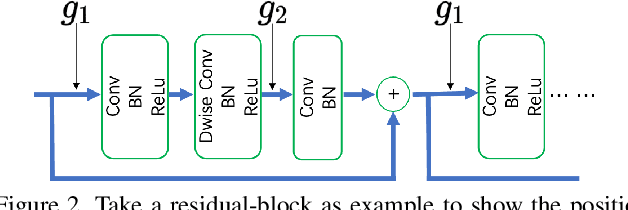
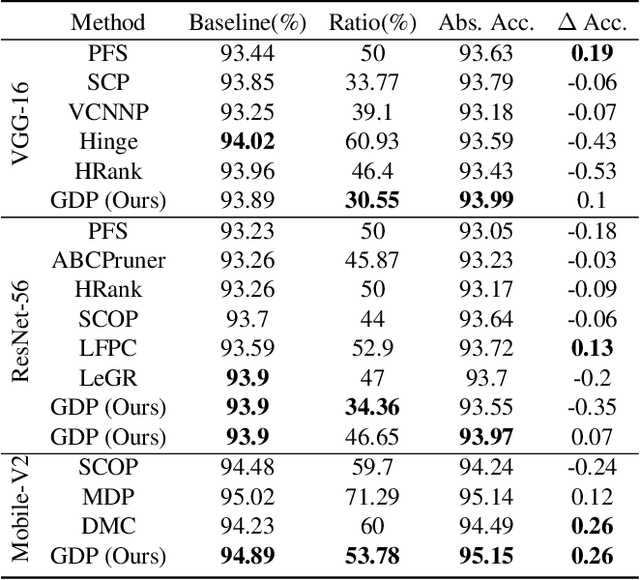
Model compression techniques are recently gaining explosive attention for obtaining efficient AI models for various real-time applications. Channel pruning is one important compression strategy and is widely used in slimming various DNNs. Previous gate-based or importance-based pruning methods aim to remove channels whose importance is smallest. However, it remains unclear what criteria the channel importance should be measured on, leading to various channel selection heuristics. Some other sampling-based pruning methods deploy sampling strategies to train sub-nets, which often causes the training instability and the compressed model's degraded performance. In view of the research gaps, we present a new module named Gates with Differentiable Polarization (GDP), inspired by principled optimization ideas. GDP can be plugged before convolutional layers without bells and whistles, to control the on-and-off of each channel or whole layer block. During the training process, the polarization effect will drive a subset of gates to smoothly decrease to exact zero, while other gates gradually stay away from zero by a large margin. When training terminates, those zero-gated channels can be painlessly removed, while other non-zero gates can be absorbed into the succeeding convolution kernel, causing completely no interruption to training nor damage to the trained model. Experiments conducted over CIFAR-10 and ImageNet datasets show that the proposed GDP algorithm achieves the state-of-the-art performance on various benchmark DNNs at a broad range of pruning ratios. We also apply GDP to DeepLabV3Plus-ResNet50 on the challenging Pascal VOC segmentation task, whose test performance sees no drop (even slightly improved) with over 60% FLOPs saving.
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 10, 2020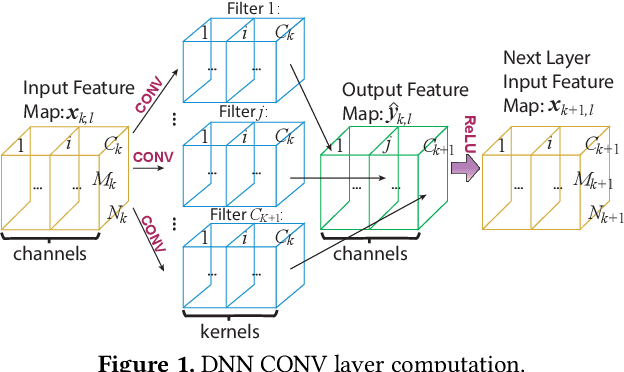
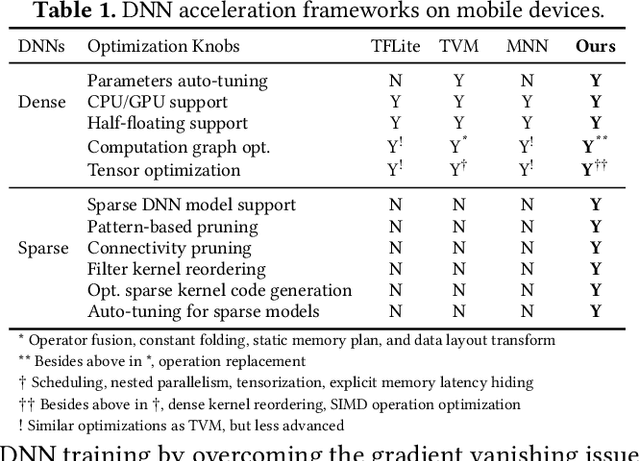
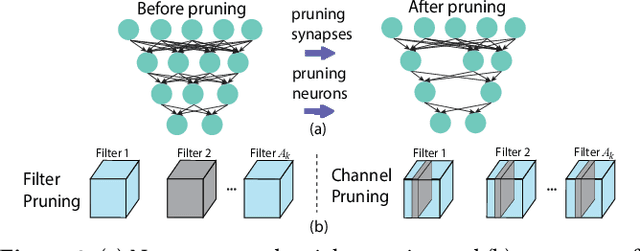
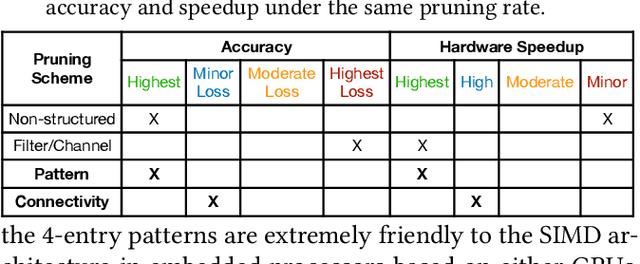
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
On Observability and Identifiability of Tightly-coupled Ultrawideband-aided Inertial Localization
Jul 29, 2021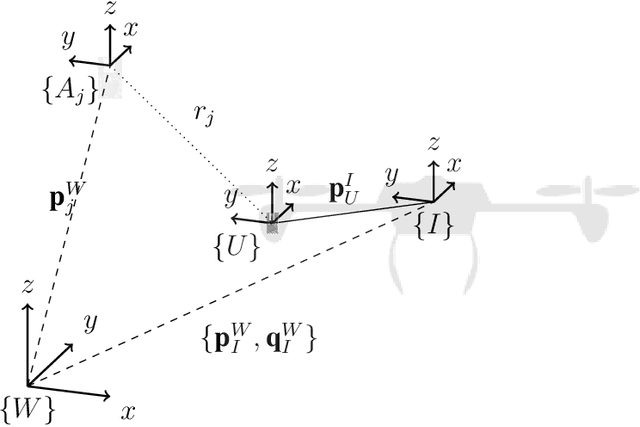
The combination of ultrawideband (UWB) radios and inertial measurement units (IMU) can provide accurate positioning. To ensure reliable communication, the radios are generally mounted at the extremities of a mobile system whereas the IMUs are located closer to the center of gravity for use in control, resulting in a spatial offset between the IMU and the UWB radio. Additionally, data from heterogeneous sensors can arrive at different time instants. The systematic fusion of data from multiple sources requires the temporal offset and spatial offset between the sensors to be known. An important aspect of calibration is the observability of the system state and identifiability of the system parameters. Estimating the state or parameters of a system that is otherwise unobservable or unidentifiable, can result in poor estimates. In this report, the local weak observability of the state and the identifiability of the temporal offset for a tightly-coupled UWB-aided inertial localization system is studied.
Memory Efficient Meta-Learning with Large Images
Jul 02, 2021
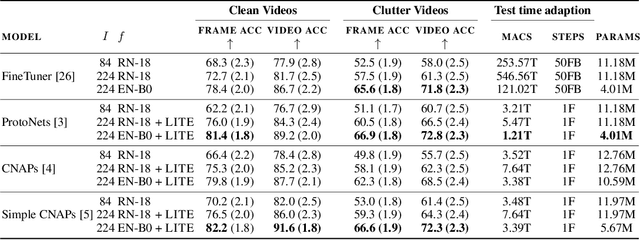
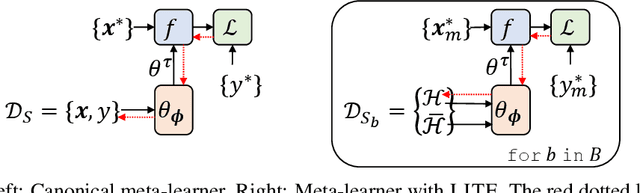
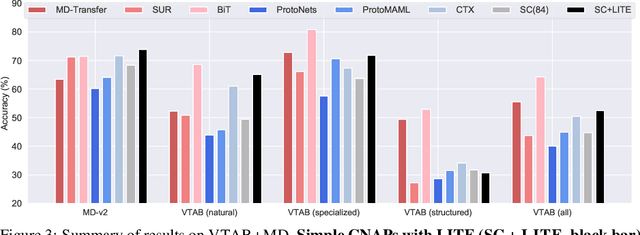
Meta learning approaches to few-shot classification are computationally efficient at test time requiring just a few optimization steps or single forward pass to learn a new task, but they remain highly memory-intensive to train. This limitation arises because a task's entire support set, which can contain up to 1000 images, must be processed before an optimization step can be taken. Harnessing the performance gains offered by large images thus requires either parallelizing the meta-learner across multiple GPUs, which may not be available, or trade-offs between task and image size when memory constraints apply. We improve on both options by proposing LITE, a general and memory efficient episodic training scheme that enables meta-training on large tasks composed of large images on a single GPU. We achieve this by observing that the gradients for a task can be decomposed into a sum of gradients over the task's training images. This enables us to perform a forward pass on a task's entire training set but realize significant memory savings by back-propagating only a random subset of these images which we show is an unbiased approximation of the full gradient. We use LITE to train meta-learners and demonstrate new state-of-the-art accuracy on the real-world ORBIT benchmark and 3 of the 4 parts of the challenging VTAB+MD benchmark relative to leading meta-learners. LITE also enables meta-learners to be competitive with transfer learning approaches but at a fraction of the test-time computational cost, thus serving as a counterpoint to the recent narrative that transfer learning is all you need for few-shot classification.
Experimental Study of Outdoor UAV Localization and Tracking using Passive RF Sensing
Sep 03, 2021

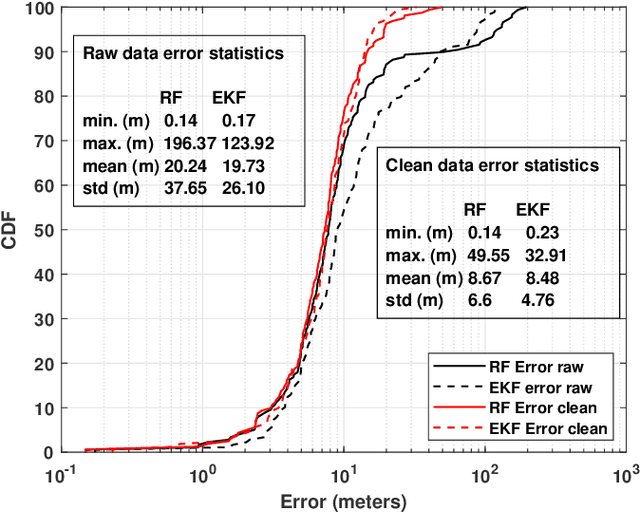
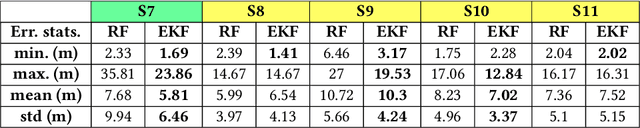
Extensive use of unmanned aerial vehicles (UAVs) is expected to raise privacy and security concerns among individuals and communities. In this context, the detection and localization of UAVs will be critical for maintaining safe and secure airspace in the future. In this work, Keysight N6854A radio frequency (RF) sensors are used to detect and locate a UAV by passively monitoring the signals emitted from the UAV. First, the Keysight sensor detects the UAV by comparing the received RF signature with various other UAVs' RF signatures in the Keysight database using an envelope detection algorithm. Afterward, time difference of arrival (TDoA) based localization is performed by a central controller using the sensor data, and the drone is localized with some error. To mitigate the localization error, implementation of an extended Kalman filter~(EKF) is proposed in this study. The performance of the proposed approach is evaluated on a realistic experimental dataset. EKF requires basic assumptions on the type of motion throughout the trajectory, i.e., the movement of the object is assumed to fit some motion model~(MM) such as constant velocity (CV), constant acceleration (CA), and constant turn (CT). In the experiments, an arbitrary trajectory is followed, therefore it is not feasible to fit the whole trajectory into a single MM. Consequently, the trajectory is segmented into sub-parts and a different MM is assumed in each segment while building the EKF model. Simulation results demonstrate an improvement in error statistics when EKF is used if the MM assumption aligns with the real motion.
Continuous Prediction of Lower-Limb Kinematics From Multi-Modal Biomedical Signals
Mar 22, 2021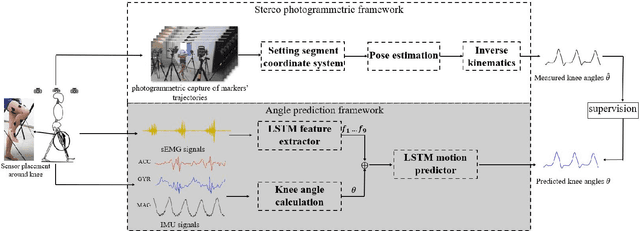
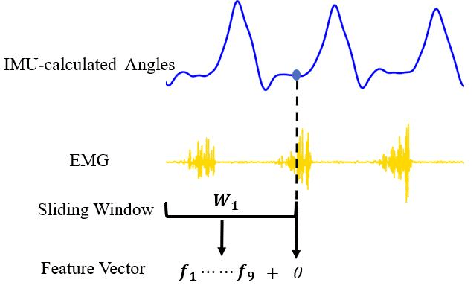
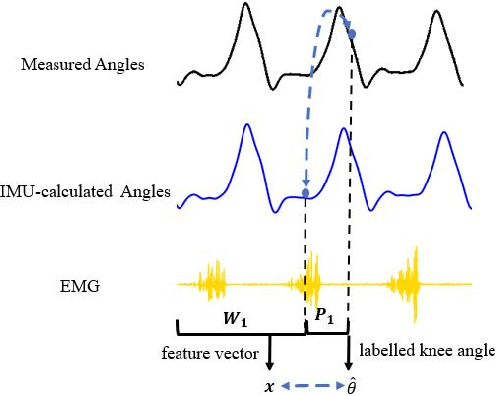
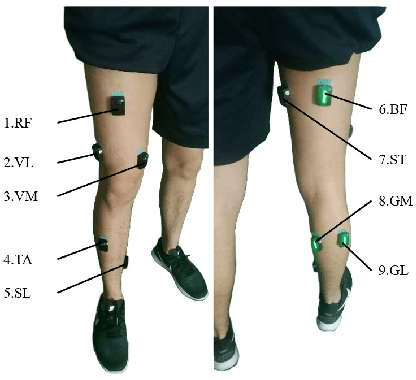
The fast-growing techniques of measuring and fusing multi-modal biomedical signals enable advanced motor intent decoding schemes of lowerlimb exoskeletons, meeting the increasing demand for rehabilitative or assistive applications of take-home healthcare. Challenges of exoskeletons motor intent decoding schemes remain in making a continuous prediction to compensate for the hysteretic response caused by mechanical transmission. In this paper, we solve this problem by proposing an ahead of time continuous prediction of lower limb kinematics, with the prediction of knee angles during level walking as a case study. Firstly, an end-to-end kinematics prediction network(KinPreNet), consisting of a feature extractor and an angle predictor, is proposed and experimentally compared with features and methods traditionally used in ahead-of-time prediction of gait phases. Secondly, inspired by the electromechanical delay(EMD), we further explore our algorithm's capability of compensating response delay of mechanical transmission by validating the performance of the different sections of prediction time. And we experimentally reveal the time boundary of compensating the hysteretic response. Thirdly, a comparison of employing EMG signals or not is performed to reveal the EMG and kinematic signals collaborated contributions to the continuous prediction. During the experiments, EMG signals of nine muscles and knee angles calculated from inertial measurement unit (IMU) signals are recorded from ten healthy subjects. To the best of our knowledge, this is the first study of continuously predicting lower-limb kinematics in an ahead-of-time manner based on the electromechanical delay (EMD).
A good body is all you need: avoiding catastrophic interference via agent architecture search
Aug 18, 2021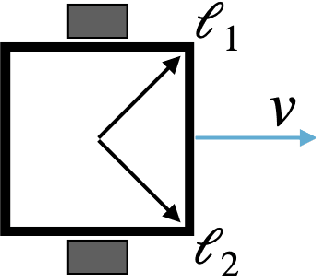
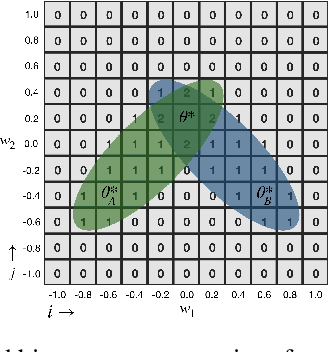
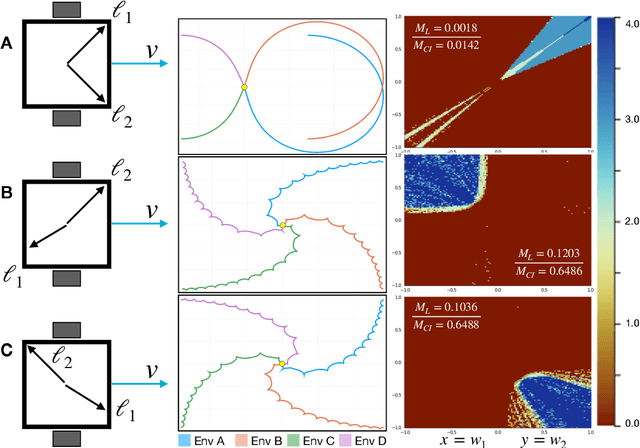
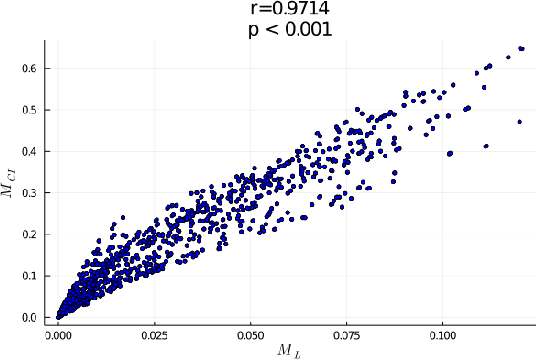
In robotics, catastrophic interference continues to restrain policy training across environments. Efforts to combat catastrophic interference to date focus on novel neural architectures or training methods, with a recent emphasis on policies with good initial settings that facilitate training in new environments. However, none of these methods to date have taken into account how the physical architecture of the robot can obstruct or facilitate catastrophic interference, just as the choice of neural architecture can. In previous work we have shown how aspects of a robot's physical structure (specifically, sensor placement) can facilitate policy learning by increasing the fraction of optimal policies for a given physical structure. Here we show for the first time that this proxy measure of catastrophic interference correlates with sample efficiency across several search methods, proving that favorable loss landscapes can be induced by the correct choice of physical structure. We show that such structures can be found via co-optimization -- optimization of a robot's structure and control policy simultaneously -- yielding catastrophic interference resistant robot structures and policies, and that this is more efficient than control policy optimization alone. Finally, we show that such structures exhibit sensor homeostasis across environments and introduce this as the mechanism by which certain robots overcome catastrophic interference.
Neural Fixed-Point Acceleration for Convex Optimization
Jul 21, 2021

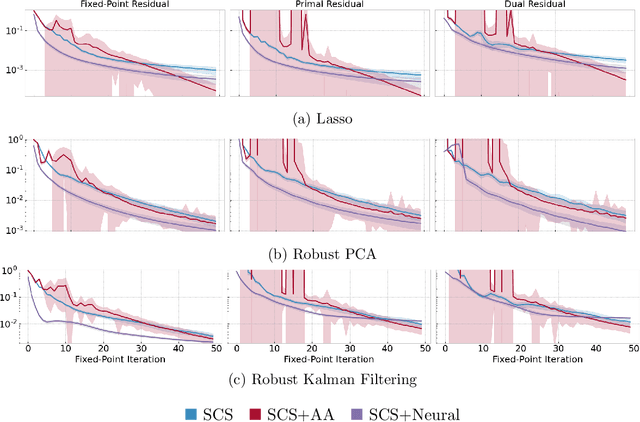

Fixed-point iterations are at the heart of numerical computing and are often a computational bottleneck in real-time applications, which typically instead need a fast solution of moderate accuracy. Classical acceleration methods for fixed-point problems focus on designing algorithms with theoretical guarantees that apply to any fixed-point problem. We present neural fixed-point acceleration, a framework to automatically learn to accelerate convex fixed-point problems that are drawn from a distribution, using ideas from meta-learning and classical acceleration algorithms. We apply our framework to SCS, the state-of-the-art solver for convex cone programming, and design models and loss functions to overcome the challenges of learning over unrolled optimization and acceleration instabilities. Our work brings neural acceleration into any optimization problem expressible with CVXPY. The source code behind this paper is available at https://github.com/facebookresearch/neural-scs
Learning Neural Models for Natural Language Processing in the Face of Distributional Shift
Sep 03, 2021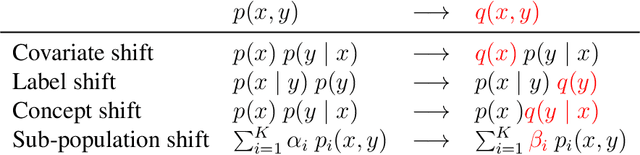
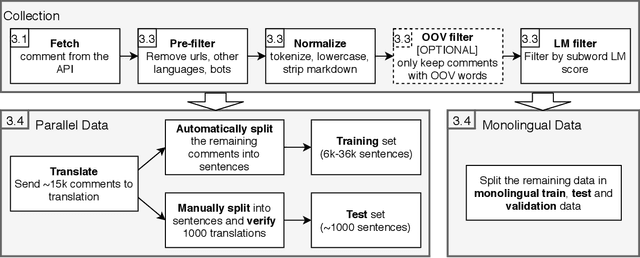
The dominating NLP paradigm of training a strong neural predictor to perform one task on a specific dataset has led to state-of-the-art performance in a variety of applications (eg. sentiment classification, span-prediction based question answering or machine translation). However, it builds upon the assumption that the data distribution is stationary, ie. that the data is sampled from a fixed distribution both at training and test time. This way of training is inconsistent with how we as humans are able to learn from and operate within a constantly changing stream of information. Moreover, it is ill-adapted to real-world use cases where the data distribution is expected to shift over the course of a model's lifetime. The first goal of this thesis is to characterize the different forms this shift can take in the context of natural language processing, and propose benchmarks and evaluation metrics to measure its effect on current deep learning architectures. We then proceed to take steps to mitigate the effect of distributional shift on NLP models. To this end, we develop methods based on parametric reformulations of the distributionally robust optimization framework. Empirically, we demonstrate that these approaches yield more robust models as demonstrated on a selection of realistic problems. In the third and final part of this thesis, we explore ways of efficiently adapting existing models to new domains or tasks. Our contribution to this topic takes inspiration from information geometry to derive a new gradient update rule which alleviate catastrophic forgetting issues during adaptation.
Universal Cross-Domain Retrieval: Generalizing Across Classes and Domains
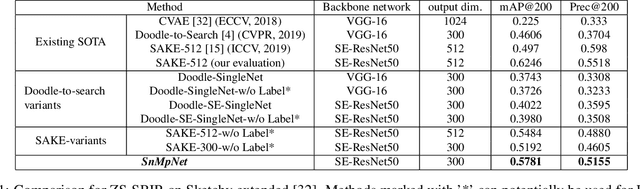
Aug 18, 2021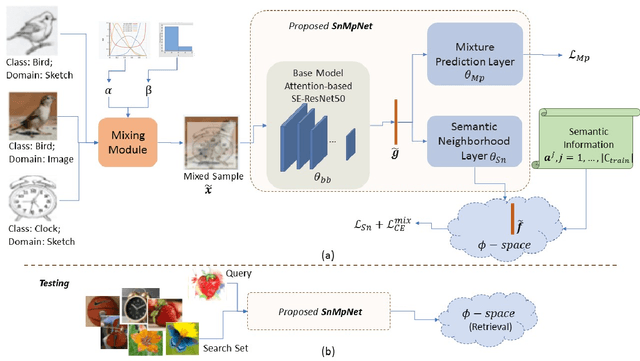
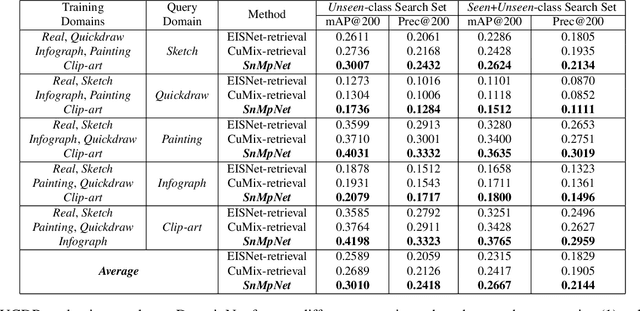

In this work, for the first time, we address the problem of universal cross-domain retrieval, where the test data can belong to classes or domains which are unseen during training. Due to dynamically increasing number of categories and practical constraint of training on every possible domain, which requires large amounts of data, generalizing to both unseen classes and domains is important. Towards that goal, we propose SnMpNet (Semantic Neighbourhood and Mixture Prediction Network), which incorporates two novel losses to account for the unseen classes and domains encountered during testing. Specifically, we introduce a novel Semantic Neighborhood loss to bridge the knowledge gap between seen and unseen classes and ensure that the latent space embedding of the unseen classes is semantically meaningful with respect to its neighboring classes. We also introduce a mix-up based supervision at image-level as well as semantic-level of the data for training with the Mixture Prediction loss, which helps in efficient retrieval when the query belongs to an unseen domain. These losses are incorporated on the SE-ResNet50 backbone to obtain SnMpNet. Extensive experiments on two large-scale datasets, Sketchy Extended and DomainNet, and thorough comparisons with state-of-the-art justify the effectiveness of the proposed model.