 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evolving Hierarchical Memory-Prediction Machines in Multi-Task Reinforcement Learning
Jun 23, 2021
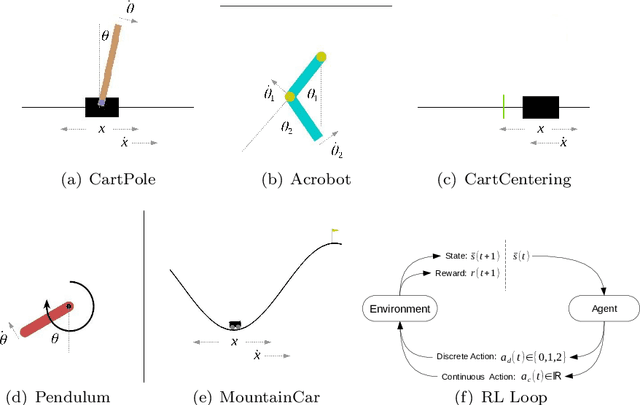

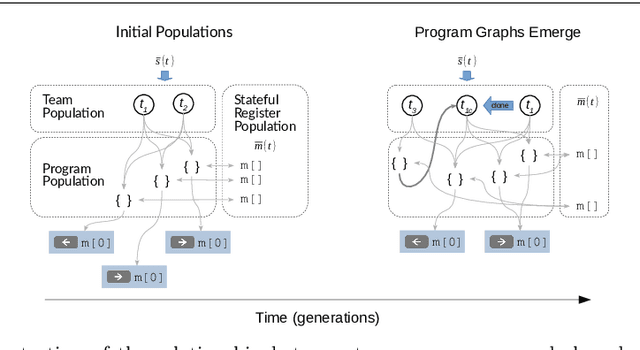
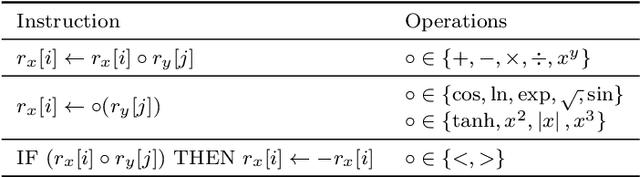
A fundamental aspect of behaviour is the ability to encode salient features of experience in memory and use these memories, in combination with current sensory information, to predict the best action for each situation such that long-term objectives are maximized. The world is highly dynamic, and behavioural agents must generalize across a variety of environments and objectives over time. This scenario can be modeled as a partially-observable multi-task reinforcement learning problem. We use genetic programming to evolve highly-generalized agents capable of operating in six unique environments from the control literature, including OpenAI's entire Classic Control suite. This requires the agent to support discrete and continuous actions simultaneously. No task-identification sensor inputs are provided, thus agents must identify tasks from the dynamics of state variables alone and define control policies for each task. We show that emergent hierarchical structure in the evolving programs leads to multi-task agents that succeed by performing a temporal decomposition and encoding of the problem environments in memory. The resulting agents are competitive with task-specific agents in all six environments. Furthermore, the hierarchical structure of programs allows for dynamic run-time complexity, which results in relatively efficient operation.
Normal Learning in Videos with Attention Prototype Network
Aug 25, 2021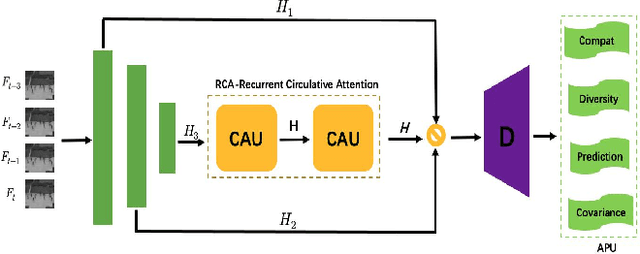
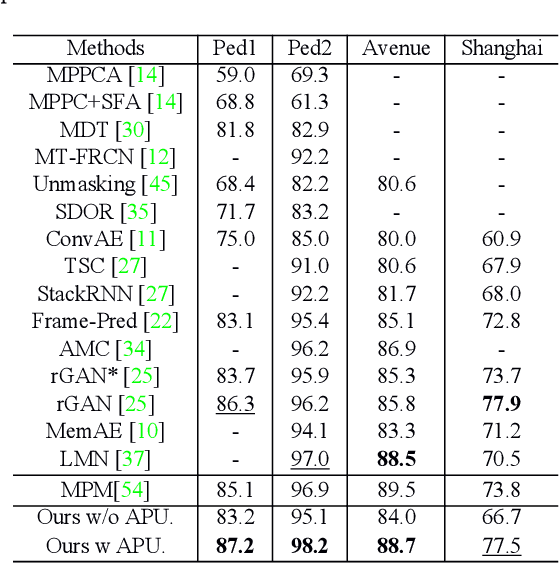
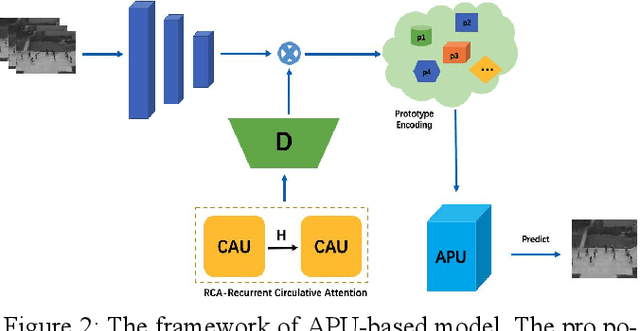
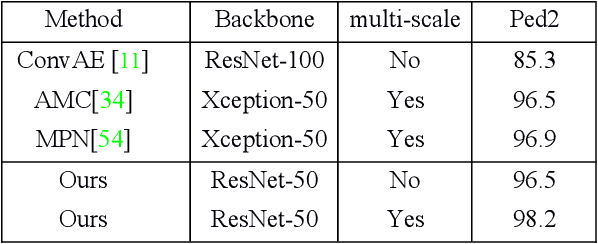
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a self-attention prototype unit (APU) to encode the normal latent space as prototypes in real time, free from extra memory cost. In addition, we introduce circulative attention mechanism to our backbone to form a novel feature extracting learner, namely Circulative Attention Unit (CAU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method. Our code is available at https://github.com/huchao-AI/APN/.
Comparative Validation of Machine Learning Algorithms for Surgical Workflow and Skill Analysis with the HeiChole Benchmark
Sep 30, 2021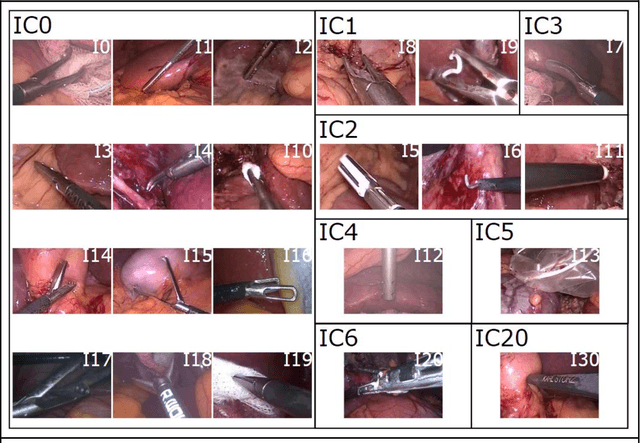
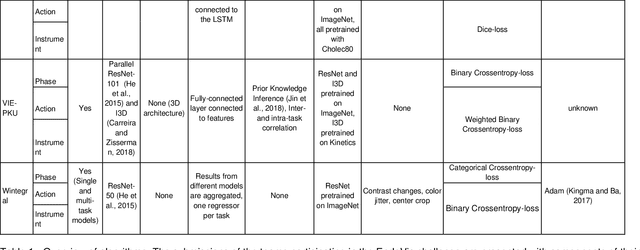
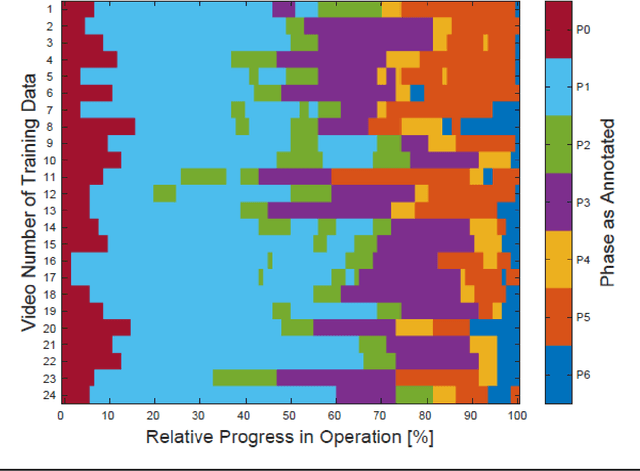
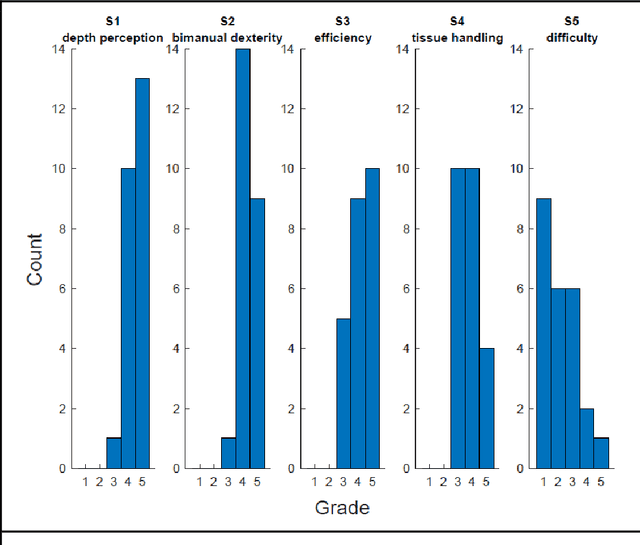
PURPOSE: Surgical workflow and skill analysis are key technologies for the next generation of cognitive surgical assistance systems. These systems could increase the safety of the operation through context-sensitive warnings and semi-autonomous robotic assistance or improve training of surgeons via data-driven feedback. In surgical workflow analysis up to 91% average precision has been reported for phase recognition on an open data single-center dataset. In this work we investigated the generalizability of phase recognition algorithms in a multi-center setting including more difficult recognition tasks such as surgical action and surgical skill. METHODS: To achieve this goal, a dataset with 33 laparoscopic cholecystectomy videos from three surgical centers with a total operation time of 22 hours was created. Labels included annotation of seven surgical phases with 250 phase transitions, 5514 occurences of four surgical actions, 6980 occurences of 21 surgical instruments from seven instrument categories and 495 skill classifications in five skill dimensions. The dataset was used in the 2019 Endoscopic Vision challenge, sub-challenge for surgical workflow and skill analysis. Here, 12 teams submitted their machine learning algorithms for recognition of phase, action, instrument and/or skill assessment. RESULTS: F1-scores were achieved for phase recognition between 23.9% and 67.7% (n=9 teams), for instrument presence detection between 38.5% and 63.8% (n=8 teams), but for action recognition only between 21.8% and 23.3% (n=5 teams). The average absolute error for skill assessment was 0.78 (n=1 team). CONCLUSION: Surgical workflow and skill analysis are promising technologies to support the surgical team, but are not solved yet, as shown by our comparison of algorithms. This novel benchmark can be used for comparable evaluation and validation of future work.
Multi-output Bus Travel Time Prediction with Convolutional LSTM Neural Network
Mar 07, 2019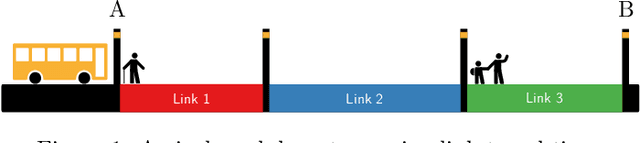

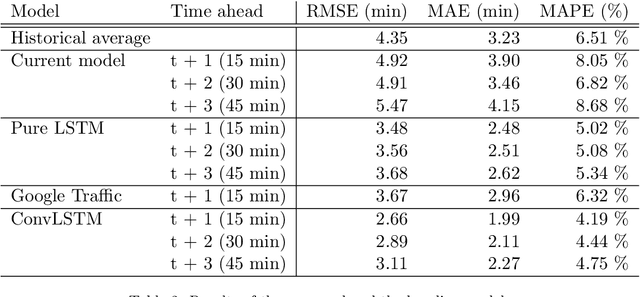
Accurate and reliable travel time predictions in public transport networks are essential for delivering an attractive service that is able to compete with other modes of transport in urban areas. The traditional application of this information, where arrival and departure predictions are displayed on digital boards, is highly visible in the city landscape of most modern metropolises. More recently, the same information has become critical as input for smart-phone trip planners in order to alert passengers about unreachable connections, alternative route choices and prolonged travel times. More sophisticated Intelligent Transport Systems (ITS) include the predictions of connection assurance, i.e. to hold back services in case a connecting service is delayed. In order to operate such systems, and to ensure the confidence of passengers in the systems, the information provided must be accurate and reliable. Traditional methods have trouble with this as congestion, and thus travel time variability, increases in cities, consequently making travel time predictions in urban areas a non-trivial task. This paper presents a system for bus travel time prediction that leverages the non-static spatio-temporal correlations present in urban bus networks, allowing the discovery of complex patterns not captured by traditional methods. The underlying model is a multi-output, multi-time-step, deep neural network that uses a combination of convolutional and long short-term memory (LSTM) layers. The method is empirically evaluated and compared to other popular approaches for link travel time prediction and currently available services, including the currently deployed model in Copenhagen, Denmark. We find that the proposed model significantly outperforms all the other methods we compare with, and is able to detect small irregular peaks in bus travel times very quickly.
RoboCoDraw: Robotic Avatar Drawing with GAN-based Style Transfer and Time-efficient Path Optimization
Dec 11, 2019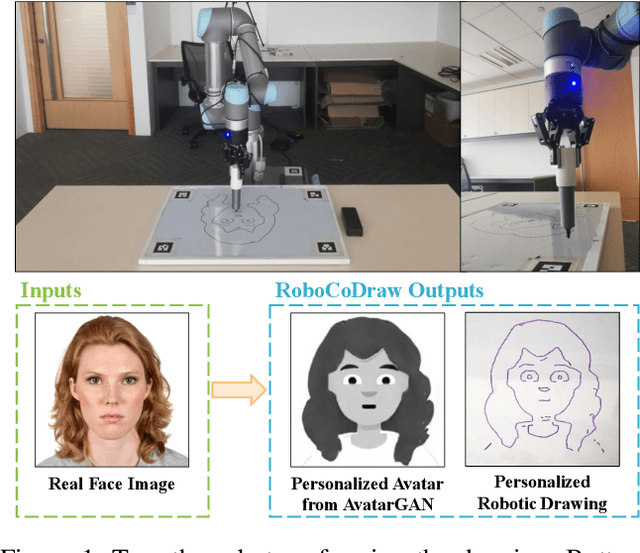
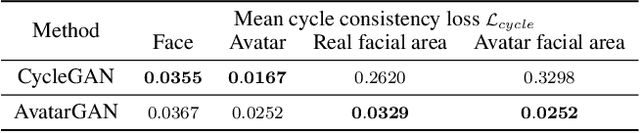

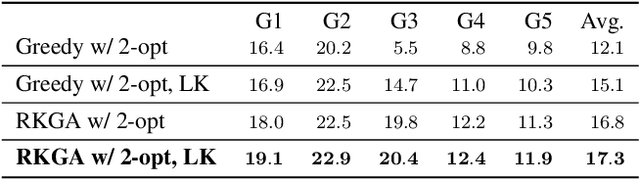
Robotic drawing has become increasingly popular as an entertainment and interactive tool. In this paper we present RoboCoDraw, a real-time collaborative robot-based drawing system that draws stylized human face sketches interactively in front of human users, by using the Generative Adversarial Network (GAN)-based style transfer and a Random-Key Genetic Algorithm (RKGA)-based path optimization. The proposed RoboCoDraw system takes a real human face image as input, converts it to a stylized avatar, then draws it with a robotic arm. A core component in this system is the Avatar-GAN proposed by us, which generates a cartoon avatar face image from a real human face. AvatarGAN is trained with unpaired face and avatar images only and can generate avatar images of much better likeness with human face images in comparison with the vanilla CycleGAN. After the avatar image is generated, it is fed to a line extraction algorithm and converted to sketches. An RKGA-based path optimization algorithm is applied to find a time-efficient robotic drawing path to be executed by the robotic arm. We demonstrate the capability of RoboCoDraw on various face images using a lightweight, safe collaborative robot UR5.
Dropout's Dream Land: Generalization from Learned Simulators to Reality
Sep 17, 2021

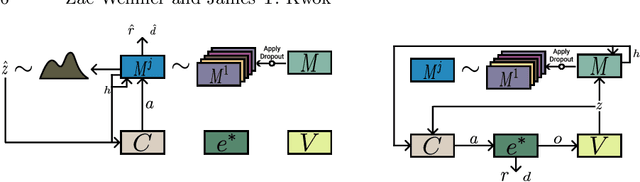

A World Model is a generative model used to simulate an environment. World Models have proven capable of learning spatial and temporal representations of Reinforcement Learning environments. In some cases, a World Model offers an agent the opportunity to learn entirely inside of its own dream environment. In this work we explore improving the generalization capabilities from dream environments to real environments (Dream2Real). We present a general approach to improve a controller's ability to transfer from a neural network dream environment to reality at little additional cost. These improvements are gained by drawing on inspiration from Domain Randomization, where the basic idea is to randomize as much of a simulator as possible without fundamentally changing the task at hand. Generally, Domain Randomization assumes access to a pre-built simulator with configurable parameters but oftentimes this is not available. By training the World Model using dropout, the dream environment is capable of creating a nearly infinite number of different dream environments. Previous use cases of dropout either do not use dropout at inference time or averages the predictions generated by multiple sampled masks (Monte-Carlo Dropout). Dropout's Dream Land leverages each unique mask to create a diverse set of dream environments. Our experimental results show that Dropout's Dream Land is an effective technique to bridge the reality gap between dream environments and reality. Furthermore, we additionally perform an extensive set of ablation studies.
Deep Transfer Learning Based Intrusion Detection System for Electric Vehicular Networks
Jul 12, 2021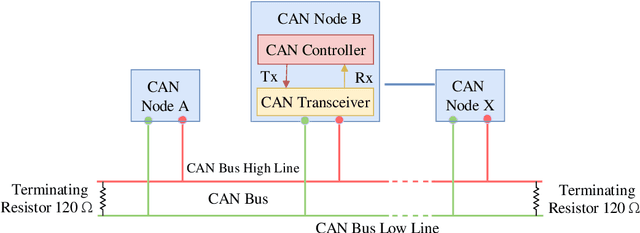
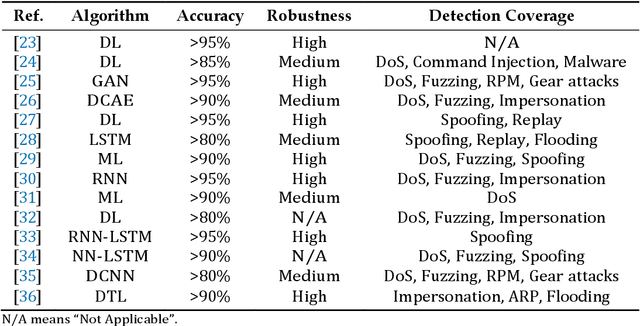
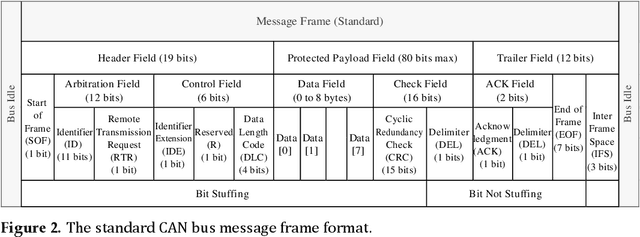

The Controller Area Network (CAN) bus works as an important protocol in the real-time In-Vehicle Network (IVN) systems for its simple, suitable, and robust architecture. The risk of IVN devices has still been insecure and vulnerable due to the complex data-intensive architectures which greatly increase the accessibility to unauthorized networks and the possibility of various types of cyberattacks. Therefore, the detection of cyberattacks in IVN devices has become a growing interest. With the rapid development of IVNs and evolving threat types, the traditional machine learning-based IDS has to update to cope with the security requirements of the current environment. Nowadays, the progression of deep learning, deep transfer learning, and its impactful outcome in several areas has guided as an effective solution for network intrusion detection. This manuscript proposes a deep transfer learning-based IDS model for IVN along with improved performance in comparison to several other existing models. The unique contributions include effective attribute selection which is best suited to identify malicious CAN messages and accurately detect the normal and abnormal activities, designing a deep transfer learning-based LeNet model, and evaluating considering real-world data. To this end, an extensive experimental performance evaluation has been conducted. The architecture along with empirical analyses shows that the proposed IDS greatly improves the detection accuracy over the mainstream machine learning, deep learning, and benchmark deep transfer learning models and has demonstrated better performance for real-time IVN security.
* 23 Pages, 14 Figures, 6 Tables with Appendix
Variance Reduction in Training Forecasting Models with Subgroup Sampling
Mar 02, 2021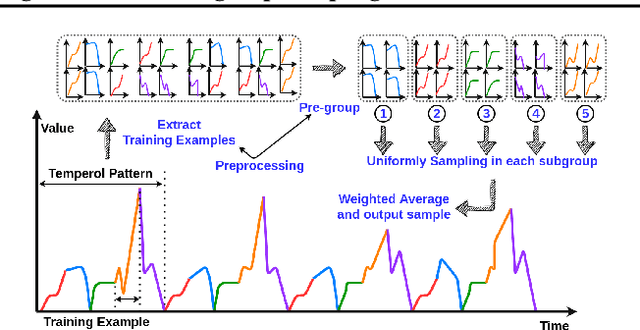
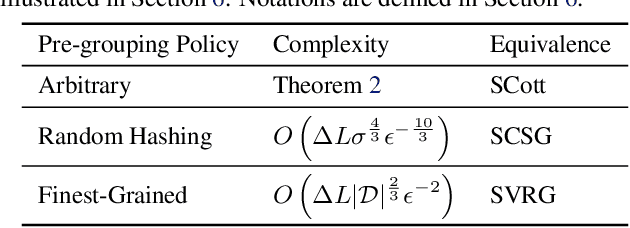
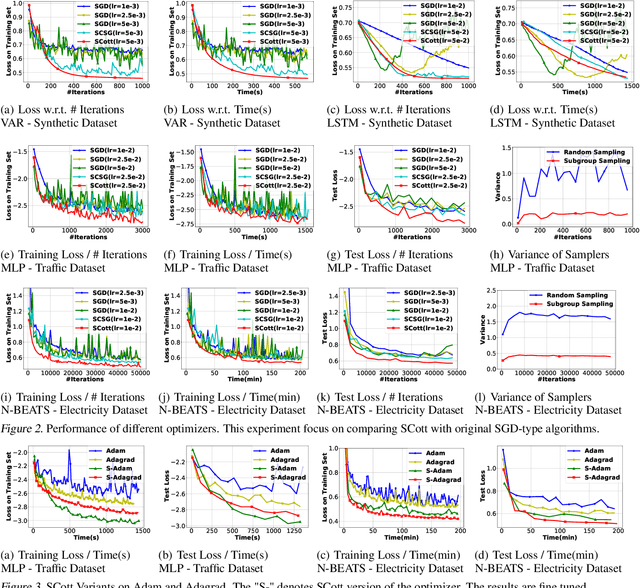
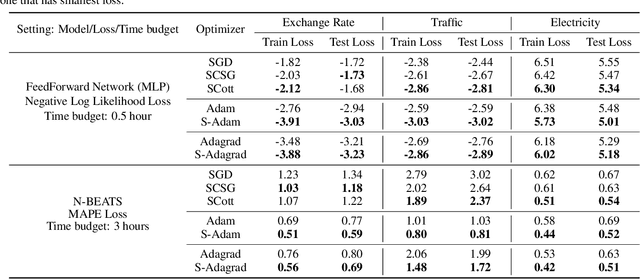
In real-world applications of large-scale time series, one often encounters the situation where the temporal patterns of time series, while drifting over time, differ from one another in the same dataset. In this paper, we provably show under such heterogeneity, training a forecasting model with commonly used stochastic optimizers (e.g. SGD) potentially suffers large gradient variance, and thus requires long time training. To alleviate this issue, we propose a sampling strategy named Subgroup Sampling, which mitigates the large variance via sampling over pre-grouped time series. We further introduce SCott, a variance reduced SGD-style optimizer that co-designs subgroup sampling with the control variate method. In theory, we provide the convergence guarantee of SCott on smooth non-convex objectives. Empirically, we evaluate SCott and other baseline optimizers on both synthetic and real-world time series forecasting problems, and show SCott converges faster with respect to both iterations and wall clock time. Additionally, we show two SCott variants that can speed up Adam and Adagrad without compromising generalization of forecasting models.
One-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

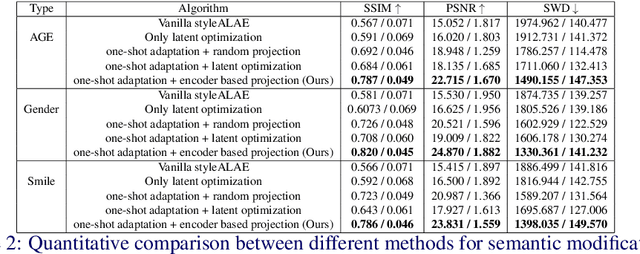

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
Dynamically Context-Sensitive Time-Decay Attention for Dialogue Modeling
Nov 01, 2018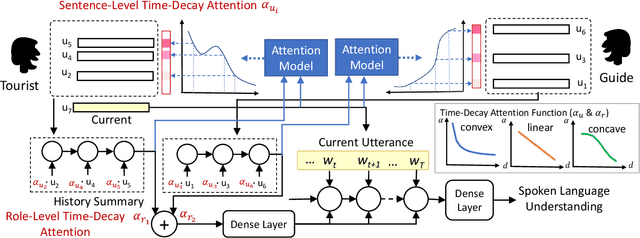
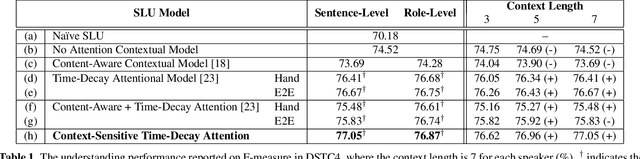
Spoken language understanding (SLU) is an essential component in conversational systems. Considering that contexts provide informative cues for better understanding, history can be leveraged for contextual SLU. However, most prior work only paid attention to the related content in history utterances and ignored the temporal information. In dialogues, it is intuitive that the most recent utterances are more important than the least recent ones, and time-aware attention should be in a decaying manner. Therefore, this paper allows the model to automatically learn a time-decay attention function where the attentional weights can be dynamically decided based on the content of each role's contexts, which effectively integrates both content-aware and time-aware perspectives and demonstrates remarkable flexibility to complex dialogue contexts. The experiments on the benchmark Dialogue State Tracking Challenge (DSTC4) dataset show that the proposed dynamically context-sensitive time-decay attention mechanisms significantly improve the state-of-the-art model for contextual understanding performance.