 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
One Proxy Device Is Enough for Hardware-Aware Neural Architecture Search
Nov 03, 2021
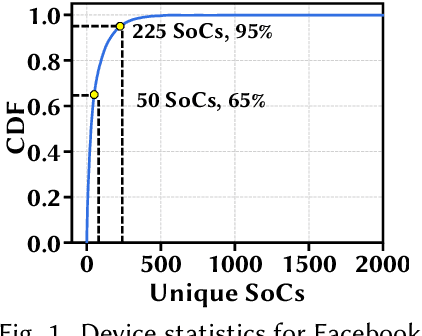
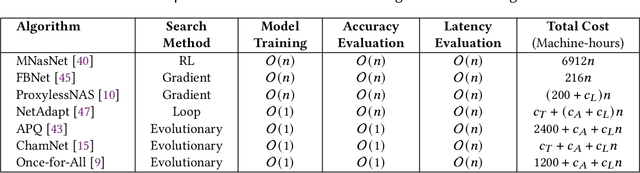
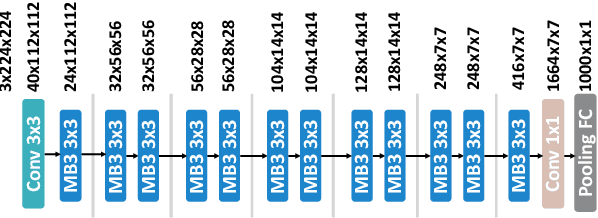

Convolutional neural networks (CNNs) are used in numerous real-world applications such as vision-based autonomous driving and video content analysis. To run CNN inference on various target devices, hardware-aware neural architecture search (NAS) is crucial. A key requirement of efficient hardware-aware NAS is the fast evaluation of inference latencies in order to rank different architectures. While building a latency predictor for each target device has been commonly used in state of the art, this is a very time-consuming process, lacking scalability in the presence of extremely diverse devices. In this work, we address the scalability challenge by exploiting latency monotonicity -- the architecture latency rankings on different devices are often correlated. When strong latency monotonicity exists, we can re-use architectures searched for one proxy device on new target devices, without losing optimality. In the absence of strong latency monotonicity, we propose an efficient proxy adaptation technique to significantly boost the latency monotonicity. Finally, we validate our approach and conduct experiments with devices of different platforms on multiple mainstream search spaces, including MobileNet-V2, MobileNet-V3, NAS-Bench-201, ProxylessNAS and FBNet. Our results highlight that, by using just one proxy device, we can find almost the same Pareto-optimal architectures as the existing per-device NAS, while avoiding the prohibitive cost of building a latency predictor for each device. GitHub: https://github.com/Ren-Research/OneProxy
* Accepted by the ACM SIGMETRICS 2022. Published in the Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 5, no. 3, Article 34, December 2021. GitHub: https://github.com/Ren-Research/OneProxy
VTBR: Semantic-based Pretraining for Person Re-Identification
Oct 11, 2021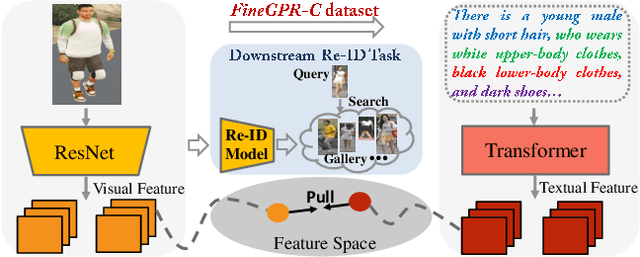
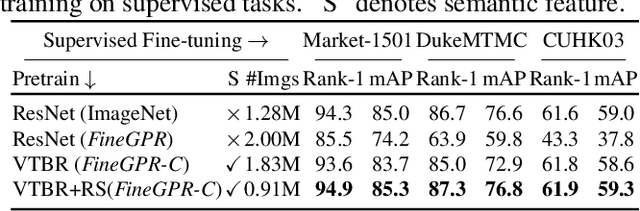
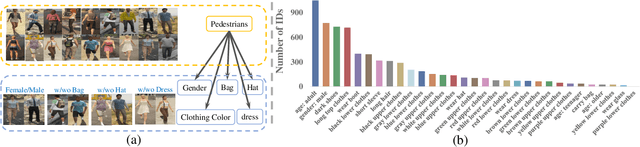

Pretraining is a dominant paradigm in computer vision. Generally, supervised ImageNet pretraining is commonly used to initialize the backbones of person re-identification (Re-ID) models. However, recent works show a surprising result that ImageNet pretraining has limited impacts on Re-ID system due to the large domain gap between ImageNet and person Re-ID data. To seek an alternative to traditional pretraining, we manually construct a diversified FineGPR-C caption dataset for the first time on person Re-ID events. Based on it, we propose a pure semantic-based pretraining approach named VTBR, which uses dense captions to learn visual representations with fewer images. Specifically, we train convolutional networks from scratch on the captions of FineGPR-C dataset, and transfer them to downstream Re-ID tasks. Comprehensive experiments conducted on benchmarks show that our VTBR can achieve competitive performance compared with ImageNet pretraining -- despite using up to 1.4x fewer images, revealing its potential in Re-ID pretraining.
The UCR Time Series Archive
Oct 17, 2018
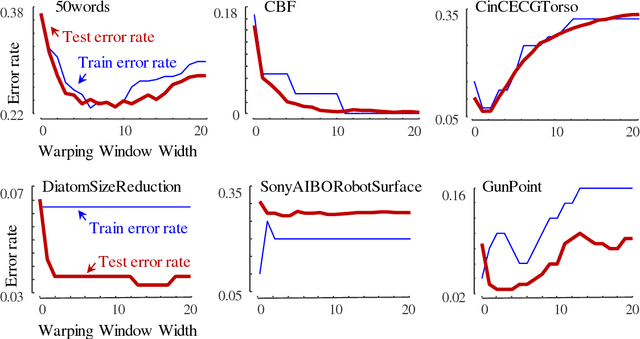
The UCR Time Series Archive - introduced in 2002, has become an important resource in the time series data mining community, with at least one thousand published papers making use of at least one dataset from the archive. The original incarnation of the archive had sixteen datasets but since that time, it has gone through periodic expansions. The last expansion took place in the summer of 2015 when the archive grew from 45 datasets to 85 datasets. This paper introduces and will focus on the new data expansion from 85 to 128 datasets. Beyond expanding this valuable resource, this paper offers pragmatic advice to anyone who may wish to evaluate a new algorithm on the archive. Finally, this paper makes a novel and yet actionable claim: of the hundreds of papers that show an improvement over the standard baseline (1-Nearest Neighbor classification), a large fraction may be misattributing the reasons for their improvement. Moreover, they may have been able to achieve the same improvement with a much simpler modification, requiring just a single line of code.
A hierarchical behavior prediction framework at signalized intersections
Oct 29, 2021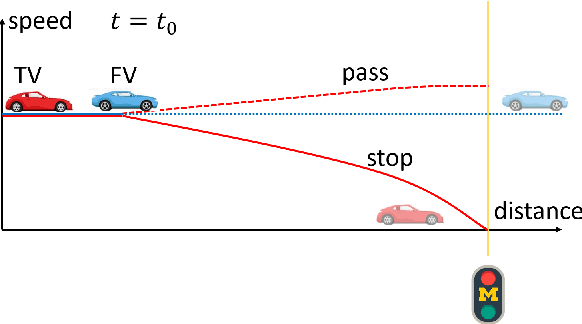
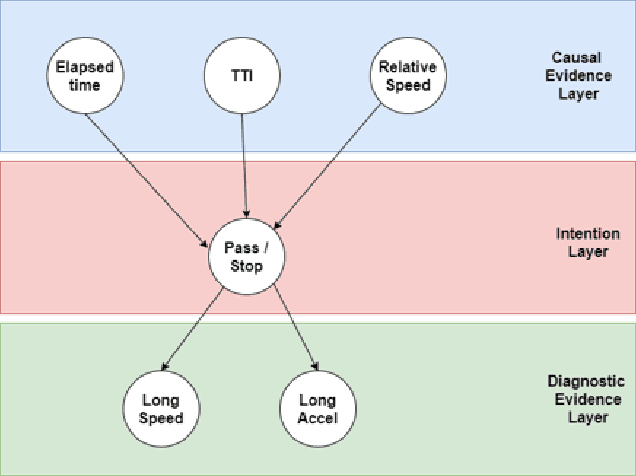
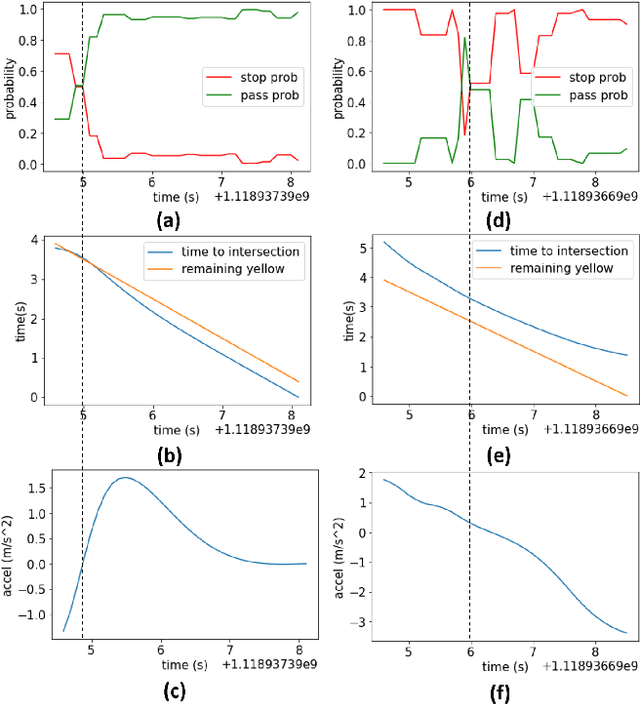
Road user behavior prediction is one of the most critical components in trajectory planning for autonomous driving, especially in urban scenarios involving traffic signals. In this paper, a hierarchical framework is proposed to predict vehicle behaviors at a signalized intersection, using the traffic signal information of the intersection. The framework is composed of two phases: a discrete intention prediction phase and a continuous trajectory prediction phase. In the discrete intention prediction phase, a Bayesian network is adopted to predict the vehicle's high-level intention, after that, maximum entropy inverse reinforcement learning is utilized to learn the human driving model offline; during the online trajectory prediction phase, a driver characteristic is designed and updated to capture the different driving preferences between human drivers. We applied the proposed framework to one of the most challenging scenarios in autonomous driving: the yellow light running scenario. Numerical experiment results are presented in the later part of the paper which show the viability of the method. The accuracy of the Bayesian network for discrete intention prediction is 91.1%, and the prediction results are getting more and more accurate as the yellow time elapses. The average Euclidean distance error in continuous trajectory prediction is only 0.85 m in the yellow light running scenario.
Exploring Deep Neural Networks on Edge TPU
Oct 17, 2021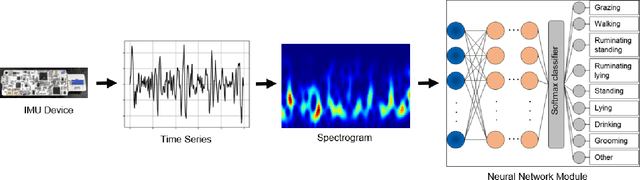
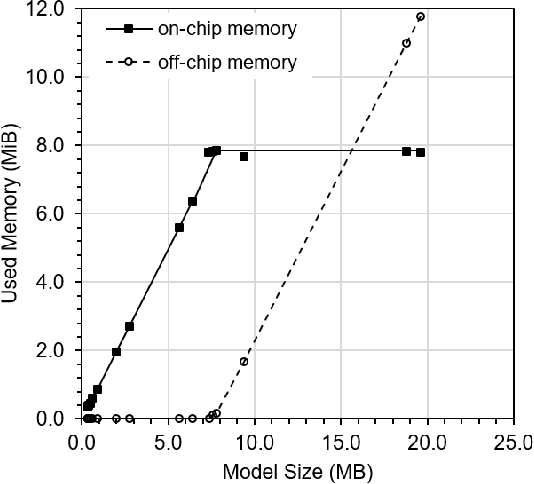
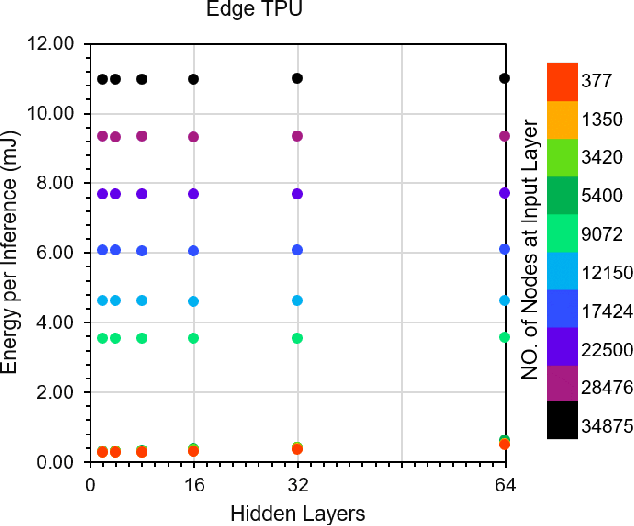
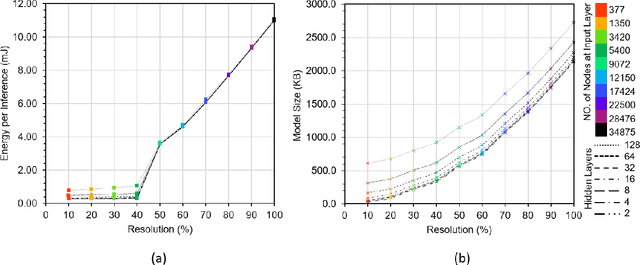
This paper explores the performance of Google's Edge TPU on feed forward neural networks. We consider Edge TPU as a hardware platform and explore different architectures of deep neural network classifiers, which traditionally has been a challenge to run on resource constrained edge devices. Based on the use of a joint-time-frequency data representation, also known as spectrogram, we explore the trade-off between classification performance and the energy consumed for inference. The energy efficiency of Edge TPU is compared with that of widely-used embedded CPU ARM Cortex-A53. Our results quantify the impact of neural network architectural specifications on the Edge TPU's performance, guiding decisions on the TPU's optimal operating point, where it can provide high classification accuracy with minimal energy consumption. Also, our evaluations highlight the crossover in performance between the Edge TPU and Cortex-A53, depending on the neural network specifications. Based on our analysis, we provide a decision chart to guide decisions on platform selection based on the model parameters and context.
Programmable FPGA-based Memory Controller
Aug 21, 2021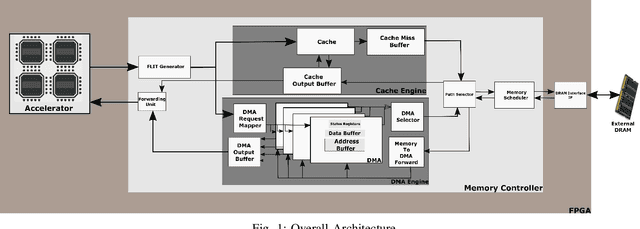
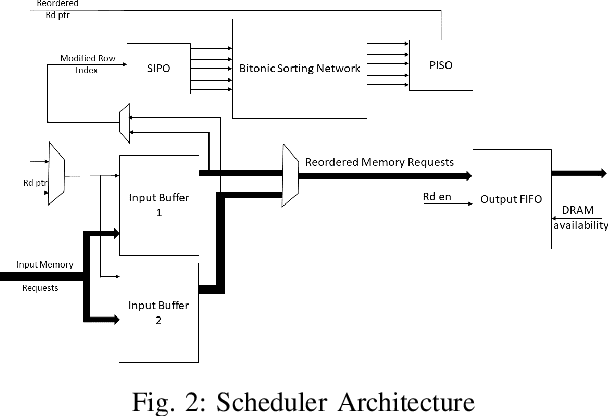
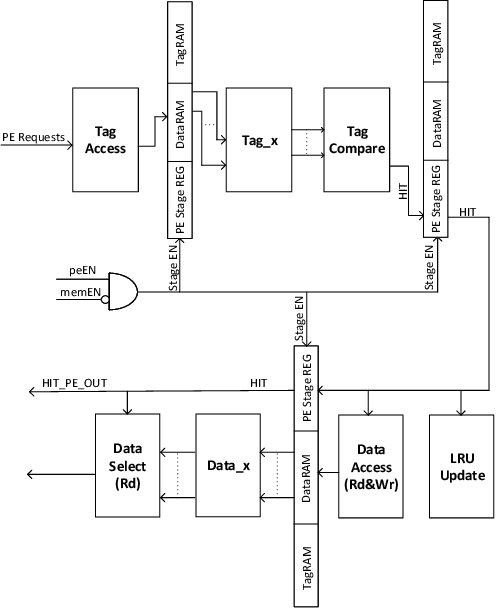
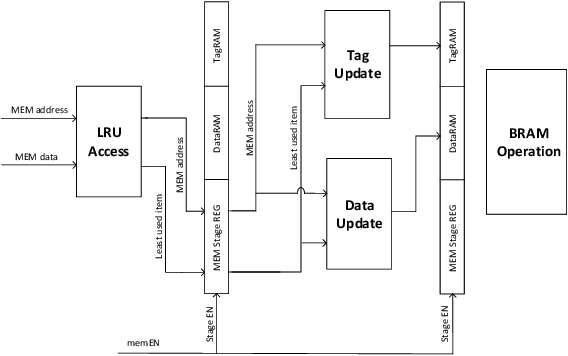
Even with generational improvements in DRAM technology, memory access latency still remains the major bottleneck for application accelerators, primarily due to limitations in memory interface IPs which cannot fully account for variations in target applications, the algorithms used, and accelerator architectures. Since developing memory controllers for different applications is time-consuming, this paper introduces a modular and programmable memory controller that can be configured for different target applications on available hardware resources. The proposed memory controller efficiently supports cache-line accesses along with bulk memory transfers. The user can configure the controller depending on the available logic resources on the FPGA, memory access pattern, and external memory specifications. The modular design supports various memory access optimization techniques including, request scheduling, internal caching, and direct memory access. These techniques contribute to reducing the overall latency while maintaining high sustained bandwidth. We implement the system on a state-of-the-art FPGA and evaluate its performance using two widely studied domains: graph analytics and deep learning workloads. We show improved overall memory access time up to 58% on CNN and GCN workloads compared with commercial memory controller IPs.
InfoGCL: Information-Aware Graph Contrastive Learning
Oct 28, 2021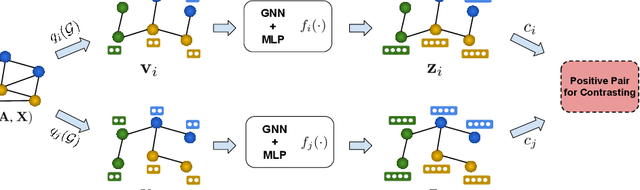
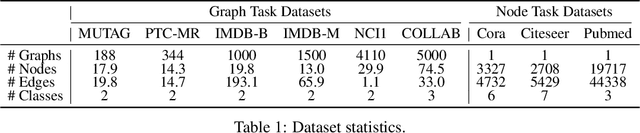
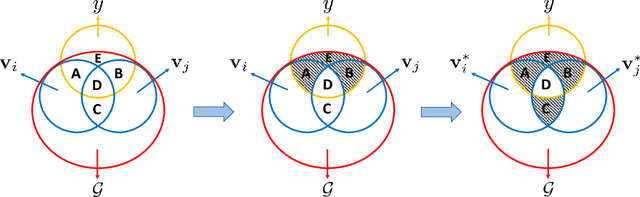
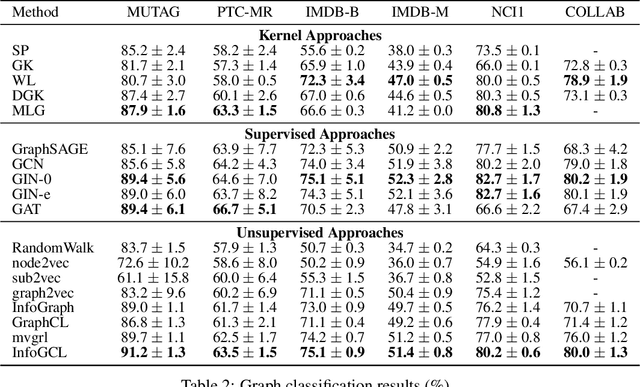
Various graph contrastive learning models have been proposed to improve the performance of learning tasks on graph datasets in recent years. While effective and prevalent, these models are usually carefully customized. In particular, although all recent researches create two contrastive views, they differ greatly in view augmentations, architectures, and objectives. It remains an open question how to build your graph contrastive learning model from scratch for particular graph learning tasks and datasets. In this work, we aim to fill this gap by studying how graph information is transformed and transferred during the contrastive learning process and proposing an information-aware graph contrastive learning framework called InfoGCL. The key point of this framework is to follow the Information Bottleneck principle to reduce the mutual information between contrastive parts while keeping task-relevant information intact at both the levels of the individual module and the entire framework so that the information loss during graph representation learning can be minimized. We show for the first time that all recent graph contrastive learning methods can be unified by our framework. We empirically validate our theoretical analysis on both node and graph classification benchmark datasets, and demonstrate that our algorithm significantly outperforms the state-of-the-arts.
The Emergence of Objectness: Learning Zero-Shot Segmentation from Videos
Nov 11, 2021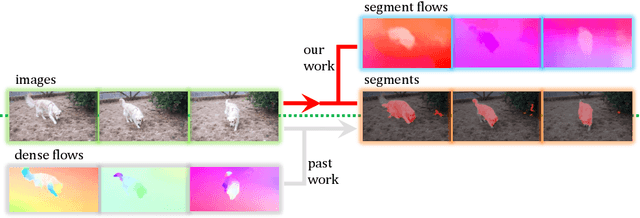

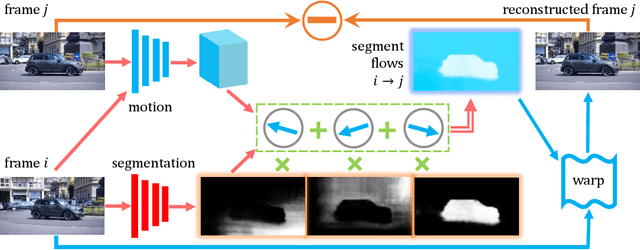

Humans can easily segment moving objects without knowing what they are. That objectness could emerge from continuous visual observations motivates us to model grouping and movement concurrently from unlabeled videos. Our premise is that a video has different views of the same scene related by moving components, and the right region segmentation and region flow would allow mutual view synthesis which can be checked from the data itself without any external supervision. Our model starts with two separate pathways: an appearance pathway that outputs feature-based region segmentation for a single image, and a motion pathway that outputs motion features for a pair of images. It then binds them in a conjoint representation called segment flow that pools flow offsets over each region and provides a gross characterization of moving regions for the entire scene. By training the model to minimize view synthesis errors based on segment flow, our appearance and motion pathways learn region segmentation and flow estimation automatically without building them up from low-level edges or optical flows respectively. Our model demonstrates the surprising emergence of objectness in the appearance pathway, surpassing prior works on zero-shot object segmentation from an image, moving object segmentation from a video with unsupervised test-time adaptation, and semantic image segmentation by supervised fine-tuning. Our work is the first truly end-to-end zero-shot object segmentation from videos. It not only develops generic objectness for segmentation and tracking, but also outperforms prevalent image-based contrastive learning methods without augmentation engineering.
Coordinate Linear Variance Reduction for Generalized Linear Programming
Nov 02, 2021
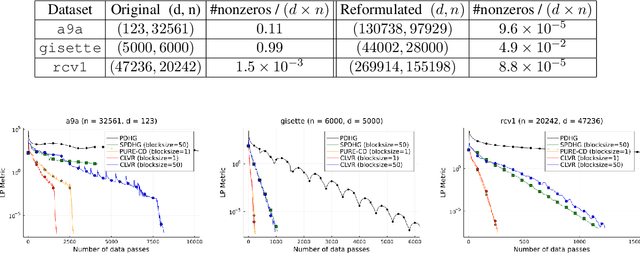
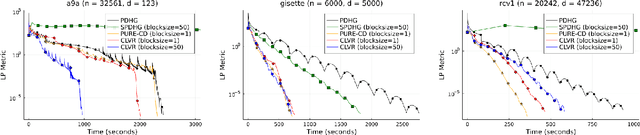
We study a class of generalized linear programs (GLP) in a large-scale setting, which includes possibly simple nonsmooth convex regularizer and simple convex set constraints. By reformulating GLP as an equivalent convex-concave min-max problem, we show that the linear structure in the problem can be used to design an efficient, scalable first-order algorithm, to which we give the name \emph{Coordinate Linear Variance Reduction} (\textsc{clvr}; pronounced ``clever''). \textsc{clvr} is an incremental coordinate method with implicit variance reduction that outputs an \emph{affine combination} of the dual variable iterates. \textsc{clvr} yields improved complexity results for (GLP) that depend on the max row norm of the linear constraint matrix in (GLP) rather than the spectral norm. When the regularization terms and constraints are separable, \textsc{clvr} admits an efficient lazy update strategy that makes its complexity bounds scale with the number of nonzero elements of the linear constraint matrix in (GLP) rather than the matrix dimensions. We show that Distributionally Robust Optimization (DRO) problems with ambiguity sets based on both $f$-divergence and Wasserstein metrics can be reformulated as (GLPs) by introducing sparsely connected auxiliary variables. We complement our theoretical guarantees with numerical experiments that verify our algorithm's practical effectiveness, both in terms of wall-clock time and number of data passes.
Differential Anomaly Detection for Facial Images
Oct 07, 2021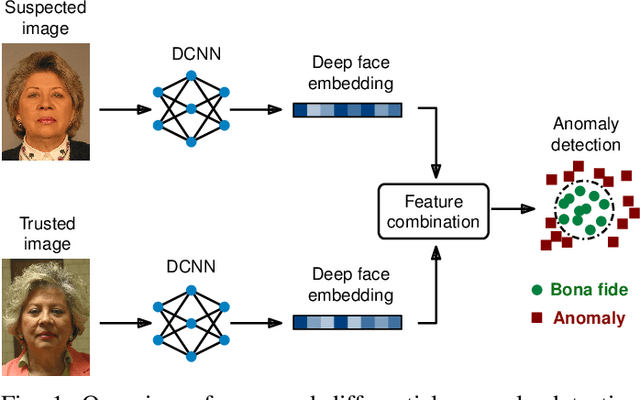


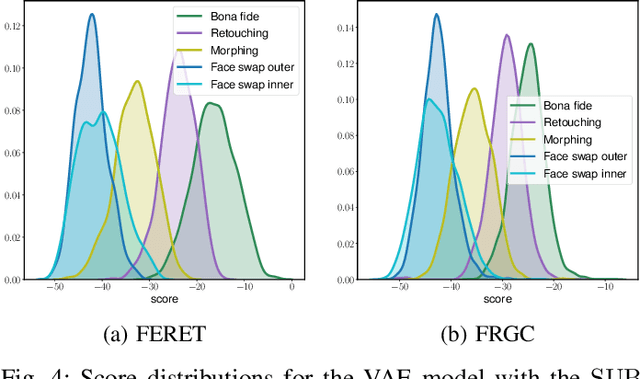
Due to their convenience and high accuracy, face recognition systems are widely employed in governmental and personal security applications to automatically recognise individuals. Despite recent advances, face recognition systems have shown to be particularly vulnerable to identity attacks (i.e., digital manipulations and attack presentations). Identity attacks pose a big security threat as they can be used to gain unauthorised access and spread misinformation. In this context, most algorithms for detecting identity attacks generalise poorly to attack types that are unknown at training time. To tackle this problem, we introduce a differential anomaly detection framework in which deep face embeddings are first extracted from pairs of images (i.e., reference and probe) and then combined for identity attack detection. The experimental evaluation conducted over several databases shows a high generalisation capability of the proposed method for detecting unknown attacks in both the digital and physical domains.