 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Risk Minimization with Shuffled SGD: A Primal-Dual Perspective and Improved Bounds
Jun 21, 2023Stochastic gradient descent (SGD) is perhaps the most prevalent optimization method in modern machine learning. Contrary to the empirical practice of sampling from the datasets without replacement and with (possible) reshuffling at each epoch, the theoretical counterpart of SGD usually relies on the assumption of sampling with replacement. It is only very recently that SGD with sampling without replacement -- shuffled SGD -- has been analyzed. For convex finite sum problems with $n$ components and under the $L$-smoothness assumption for each component function, there are matching upper and lower bounds, under sufficiently small -- $\mathcal{O}(\frac{1}{nL})$ -- step sizes. Yet those bounds appear too pessimistic -- in fact, the predicted performance is generally no better than for full gradient descent -- and do not agree with the empirical observations. In this work, to narrow the gap between the theory and practice of shuffled SGD, we sharpen the focus from general finite sum problems to empirical risk minimization with linear predictors. This allows us to take a primal-dual perspective and interpret shuffled SGD as a primal-dual method with cyclic coordinate updates on the dual side. Leveraging this perspective, we prove a fine-grained complexity bound that depends on the data matrix and is never worse than what is predicted by the existing bounds. Notably, our bound can predict much faster convergence than the existing analyses -- by a factor of the order of $\sqrt{n}$ in some cases. We empirically demonstrate that on common machine learning datasets our bound is indeed much tighter. We further show how to extend our analysis to convex nonsmooth problems, with similar improvements.
Accelerated Cyclic Coordinate Dual Averaging with Extrapolation for Composite Convex Optimization
Mar 28, 2023



Exploiting partial first-order information in a cyclic way is arguably the most natural strategy to obtain scalable first-order methods. However, despite their wide use in practice, cyclic schemes are far less understood from a theoretical perspective than their randomized counterparts. Motivated by a recent success in analyzing an extrapolated cyclic scheme for generalized variational inequalities, we propose an Accelerated Cyclic Coordinate Dual Averaging with Extrapolation (A-CODER) method for composite convex optimization, where the objective function can be expressed as the sum of a smooth convex function accessible via a gradient oracle and a convex, possibly nonsmooth, function accessible via a proximal oracle. We show that A-CODER attains the optimal convergence rate with improved dependence on the number of blocks compared to prior work. Furthermore, for the setting where the smooth component of the objective function is expressible in a finite sum form, we introduce a variance-reduced variant of A-CODER, VR-A-CODER, with state-of-the-art complexity guarantees. Finally, we demonstrate the effectiveness of our algorithms through numerical experiments.
Coordinate Linear Variance Reduction for Generalized Linear Programming
Nov 16, 2021
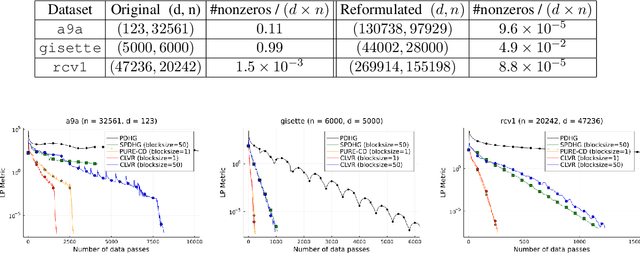
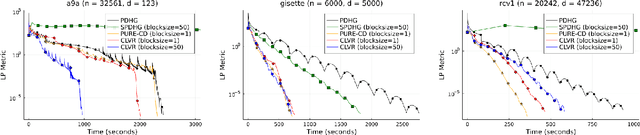
We study a class of generalized linear programs (GLP) in a large-scale setting, which includes possibly simple nonsmooth convex regularizer and simple convex set constraints. By reformulating GLP as an equivalent convex-concave min-max problem, we show that the linear structure in the problem can be used to design an efficient, scalable first-order algorithm, to which we give the name \emph{Coordinate Linear Variance Reduction} (\textsc{clvr}; pronounced "clever"). \textsc{clvr} is an incremental coordinate method with implicit variance reduction that outputs an \emph{affine combination} of the dual variable iterates. \textsc{clvr} yields improved complexity results for (GLP) that depend on the max row norm of the linear constraint matrix in (GLP) rather than the spectral norm. When the regularization terms and constraints are separable, \textsc{clvr} admits an efficient lazy update strategy that makes its complexity bounds scale with the number of nonzero elements of the linear constraint matrix in (GLP) rather than the matrix dimensions. We show that Distributionally Robust Optimization (DRO) problems with ambiguity sets based on both $f$-divergence and Wasserstein metrics can be reformulated as (GLPs) by introducing sparsely connected auxiliary variables. We complement our theoretical guarantees with numerical experiments that verify our algorithm's practical effectiveness, both in terms of wall-clock time and number of data passes.
Parameter-free Locally Accelerated Conditional Gradients
Feb 12, 2021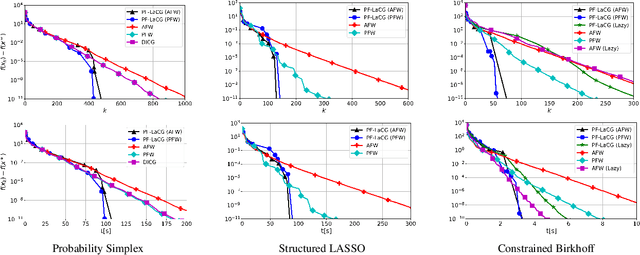
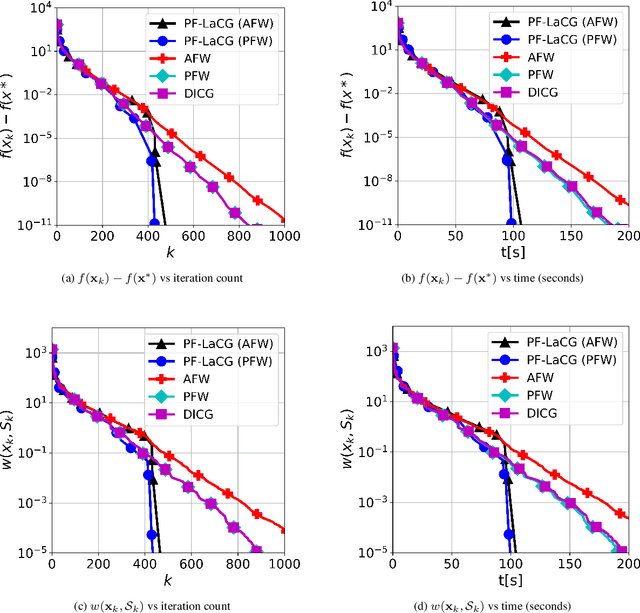
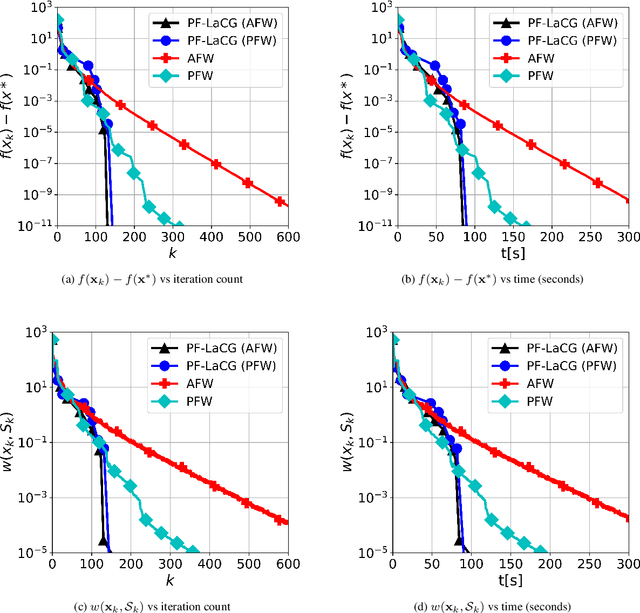
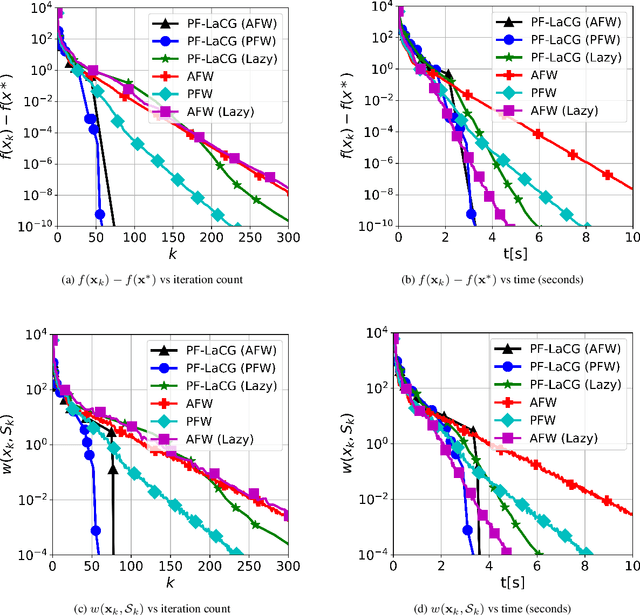
Projection-free conditional gradient (CG) methods are the algorithms of choice for constrained optimization setups in which projections are often computationally prohibitive but linear optimization over the constraint set remains computationally feasible. Unlike in projection-based methods, globally accelerated convergence rates are in general unattainable for CG. However, a very recent work on Locally accelerated CG (LaCG) has demonstrated that local acceleration for CG is possible for many settings of interest. The main downside of LaCG is that it requires knowledge of the smoothness and strong convexity parameters of the objective function. We remove this limitation by introducing a novel, Parameter-Free Locally accelerated CG (PF-LaCG) algorithm, for which we provide rigorous convergence guarantees. Our theoretical results are complemented by numerical experiments, which demonstrate local acceleration and showcase the practical improvements of PF-LaCG over non-accelerated algorithms, both in terms of iteration count and wall-clock time.