 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Decoupled Approach to Fast and Optimal Hardware-Software Co-Design of Neural Accelerators
Mar 25, 2022
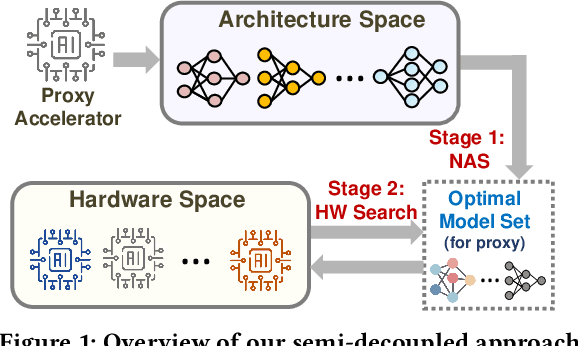
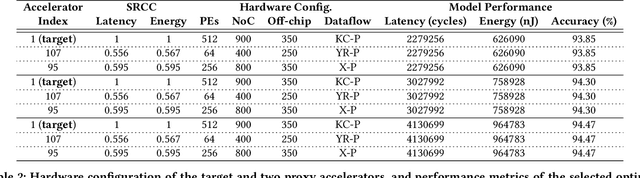
In view of the performance limitations of fully-decoupled designs for neural architectures and accelerators, hardware-software co-design has been emerging to fully reap the benefits of flexible design spaces and optimize neural network performance. Nonetheless, such co-design also enlarges the total search space to practically infinity and presents substantial challenges. While the prior studies have been focusing on improving the search efficiency (e.g., via reinforcement learning), they commonly rely on co-searches over the entire architecture-accelerator design space. In this paper, we propose a \emph{semi}-decoupled approach to reduce the size of the total design space by orders of magnitude, yet without losing optimality. We first perform neural architecture search to obtain a small set of optimal architectures for one accelerator candidate. Importantly, this is also the set of (close-to-)optimal architectures for other accelerator designs based on the property that neural architectures' ranking orders in terms of inference latency and energy consumption on different accelerator designs are highly similar. Then, instead of considering all the possible architectures, we optimize the accelerator design only in combination with this small set of architectures, thus significantly reducing the total search cost. We validate our approach by conducting experiments on various architecture spaces for accelerator designs with different dataflows. Our results highlight that we can obtain the optimal design by only navigating over the reduced search space. The source code of this work is at \url{https://github.com/Ren-Research/CoDesign}.
One Proxy Device Is Enough for Hardware-Aware Neural Architecture Search
Nov 03, 2021
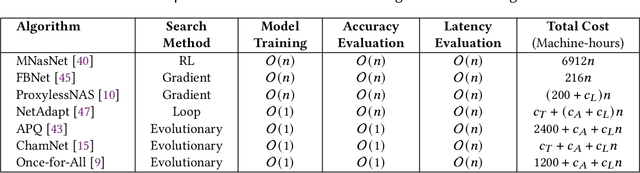
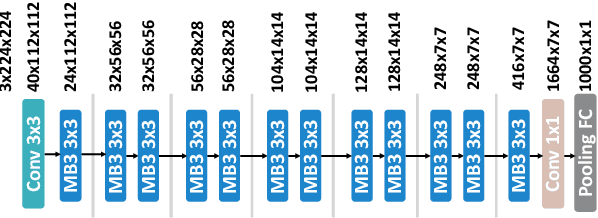

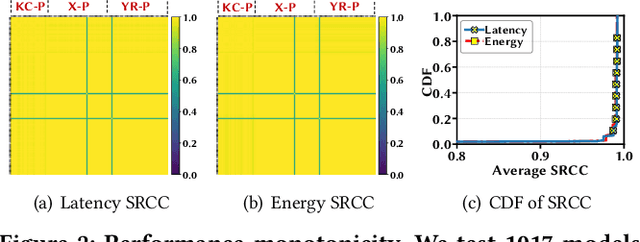
Convolutional neural networks (CNNs) are used in numerous real-world applications such as vision-based autonomous driving and video content analysis. To run CNN inference on various target devices, hardware-aware neural architecture search (NAS) is crucial. A key requirement of efficient hardware-aware NAS is the fast evaluation of inference latencies in order to rank different architectures. While building a latency predictor for each target device has been commonly used in state of the art, this is a very time-consuming process, lacking scalability in the presence of extremely diverse devices. In this work, we address the scalability challenge by exploiting latency monotonicity -- the architecture latency rankings on different devices are often correlated. When strong latency monotonicity exists, we can re-use architectures searched for one proxy device on new target devices, without losing optimality. In the absence of strong latency monotonicity, we propose an efficient proxy adaptation technique to significantly boost the latency monotonicity. Finally, we validate our approach and conduct experiments with devices of different platforms on multiple mainstream search spaces, including MobileNet-V2, MobileNet-V3, NAS-Bench-201, ProxylessNAS and FBNet. Our results highlight that, by using just one proxy device, we can find almost the same Pareto-optimal architectures as the existing per-device NAS, while avoiding the prohibitive cost of building a latency predictor for each device. GitHub: https://github.com/Ren-Research/OneProxy
* Accepted by the ACM SIGMETRICS 2022. Published in the Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 5, no. 3, Article 34, December 2021. GitHub: https://github.com/Ren-Research/OneProxy
Scaling Up Deep Neural Network Optimization for Edge Inference
Sep 17, 2020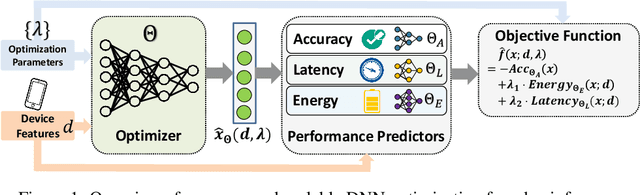
Deep neural networks (DNNs) have been increasingly deployed on and integrated with edge devices, such as mobile phones, drones, robots and wearables. To run DNN inference directly on edge devices (a.k.a. edge inference) with a satisfactory performance, optimizing the DNN design (e.g., network architecture and quantization policy) is crucial. While state-of-the-art DNN designs have leveraged performance predictors to speed up the optimization process, they are device-specific (i.e., each predictor for only one target device) and hence cannot scale well in the presence of extremely diverse edge devices. Moreover, even with performance predictors, the optimizer (e.g., search-based optimization) can still be time-consuming when optimizing DNNs for many different devices. In this work, we propose two approaches to scaling up DNN optimization. In the first approach, we reuse the performance predictors built on a proxy device, and leverage the performance monotonicity to scale up the DNN optimization without re-building performance predictors for each different device. In the second approach, we build scalable performance predictors that can estimate the resulting performance (e.g., inference accuracy/latency/energy) given a DNN-device pair, and use a neural network-based automated optimizer that takes both device features and optimization parameters as input and then directly outputs the optimal DNN design without going through a lengthy optimization process for each individual device.
A Note on Latency Variability of Deep Neural Networks for Mobile Inference
Feb 29, 2020

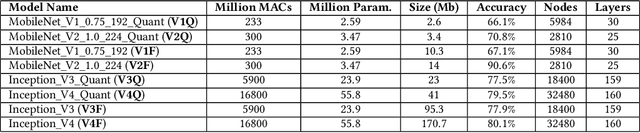
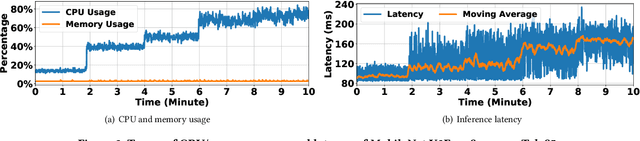
Running deep neural network (DNN) inference on mobile devices, i.e., mobile inference, has become a growing trend, making inference less dependent on network connections and keeping private data locally. The prior studies on optimizing DNNs for mobile inference typically focus on the metric of average inference latency, thus implicitly assuming that mobile inference exhibits little latency variability. In this note, we conduct a preliminary measurement study on the latency variability of DNNs for mobile inference. We show that the inference latency variability can become quite significant in the presence of CPU resource contention. More interestingly, unlike the common belief that the relative performance superiority of DNNs on one device can carry over to another device and/or another level of resource contention, we highlight that a DNN model with a better latency performance than another model can become outperformed by the other model when resource contention be more severe or running on another device. Thus, when optimizing DNN models for mobile inference, only measuring the average latency may not be adequate; instead, latency variability under various conditions should be accounted for, including but not limited to different devices and different levels of CPU resource contention considered in this note.