 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 10, 2021
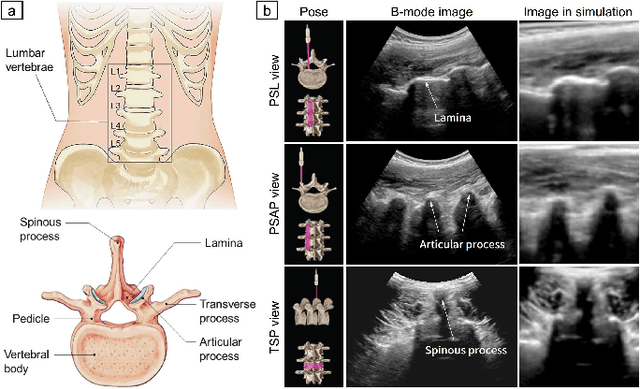
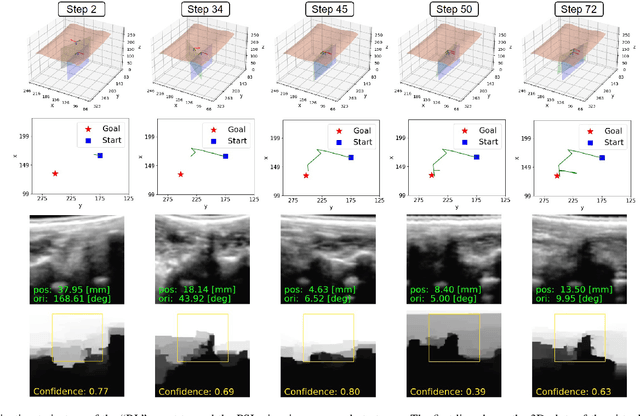
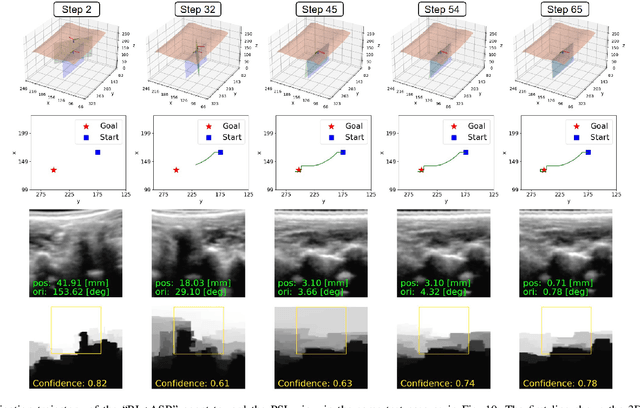
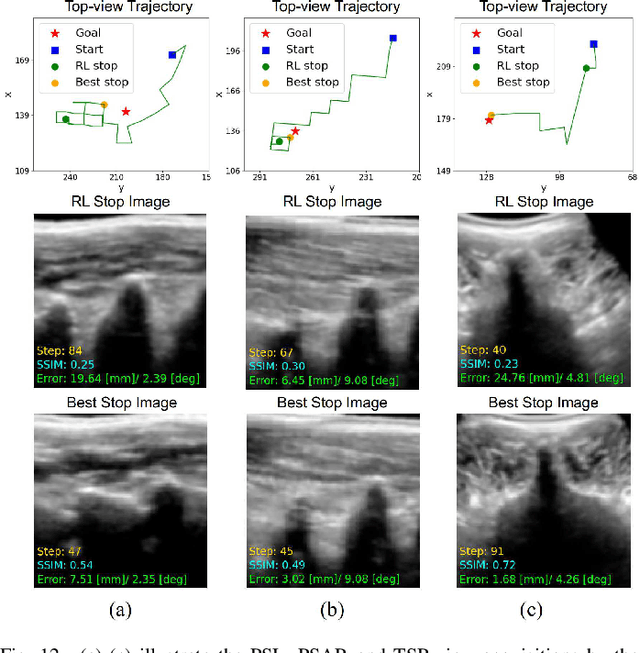
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from 17 volunteers. The average navigation accuracy toward different standard views achieves 5.18mm/5.25deg and 12.87mm/17.49deg in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.
Adding more data does not always help: A study in medical conversation summarization with PEGASUS
Nov 15, 2021
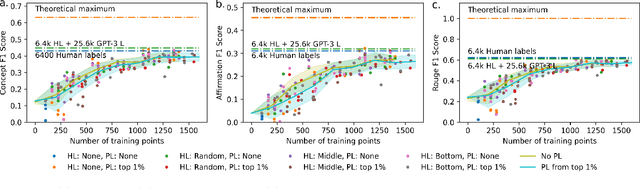
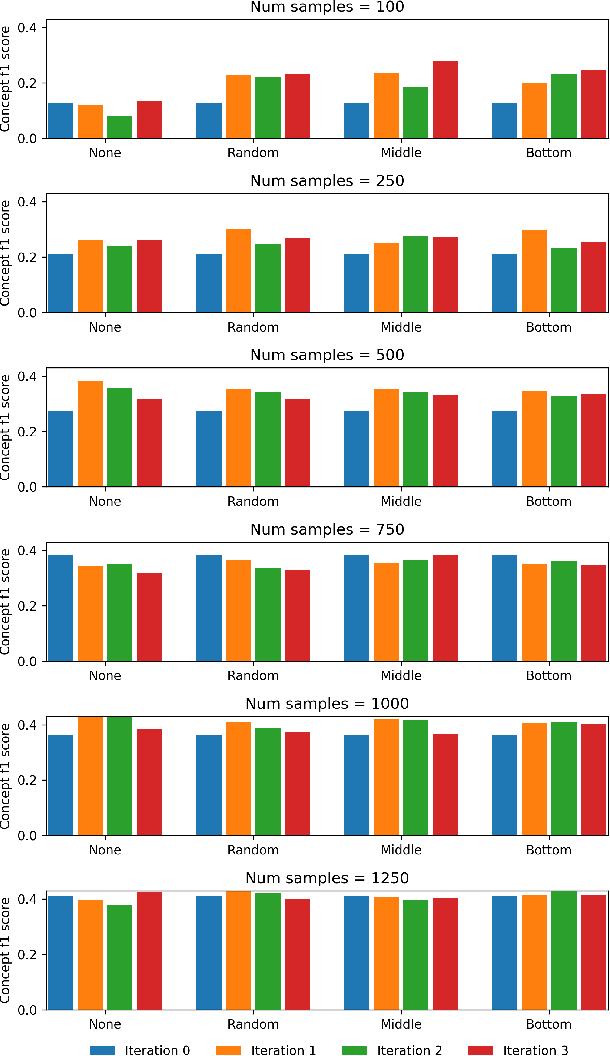
Medical conversation summarization is integral in capturing information gathered during interactions between patients and physicians. Summarized conversations are used to facilitate patient hand-offs between physicians, and as part of providing care in the future. Summaries, however, can be time-consuming to produce and require domain expertise. Modern pre-trained NLP models such as PEGASUS have emerged as capable alternatives to human summarization, reaching state-of-the-art performance on many summarization benchmarks. However, many downstream tasks still require at least moderately sized datasets to achieve satisfactory performance. In this work we (1) explore the effect of dataset size on transfer learning medical conversation summarization using PEGASUS and (2) evaluate various iterative labeling strategies in the low-data regime, following their success in the classification setting. We find that model performance saturates with increase in dataset size and that the various active-learning strategies evaluated all show equivalent performance consistent with simple dataset size increase. We also find that naive iterative pseudo-labeling is on-par or slightly worse than no pseudo-labeling. Our work sheds light on the successes and challenges of translating low-data regime techniques in classification to medical conversation summarization and helps guides future work in this space. Relevant code available at \url{https://github.com/curai/curai-research/tree/main/medical-summarization-ML4H-2021}.
Vaccine allocation policy optimization and budget sharing mechanism using Thompson sampling
Sep 21, 2021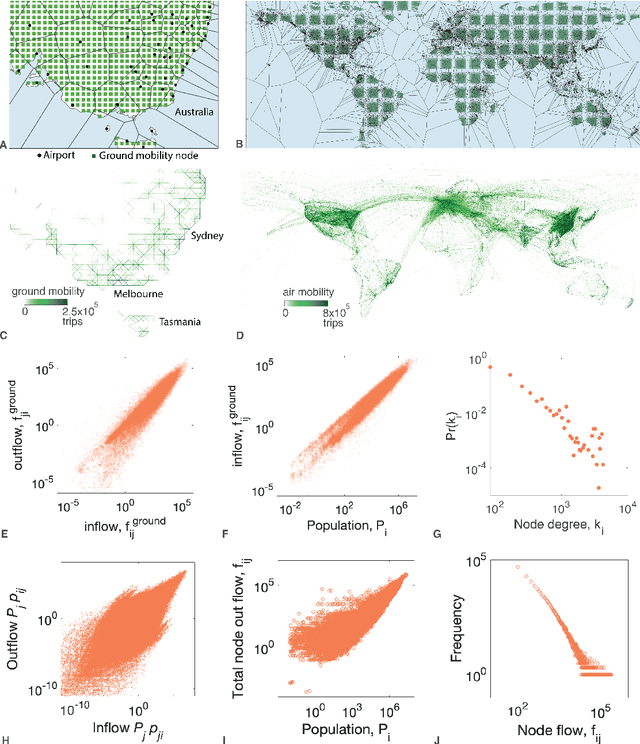
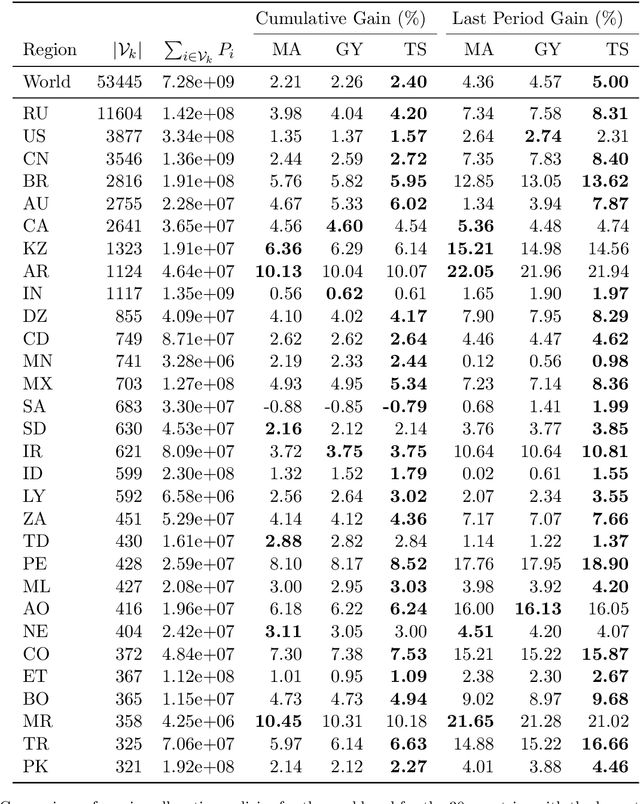
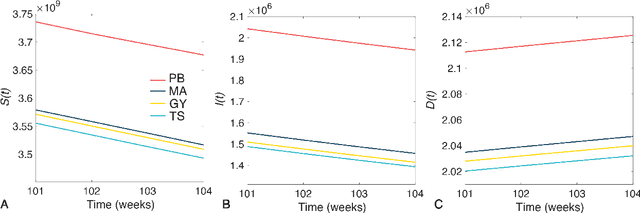
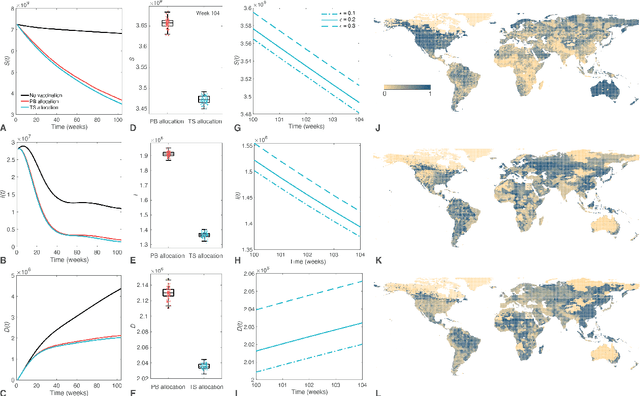
The optimal allocation of vaccines to population subgroups over time is a challenging health care management problem. In the context of a pandemic, the interaction between vaccination policies adopted by multiple agents and the cooperation (or lack thereof) creates a complex environment that affects the global transmission dynamics of the disease. In this study, we take the perspective of decision-making agents that aim to minimize the size of their susceptible populations and must allocate vaccine under limited supply. We assume that vaccine efficiency rates are unknown to agents and we propose an optimization policy based on Thompson sampling to learn mean vaccine efficiency rates over time. Furthermore, we develop a budget-balanced resource sharing mechanism to promote cooperation among agents. We apply the proposed framework to the COVID-19 pandemic. We use a raster model of the world where agents represent the main countries worldwide and interact in a global mobility network to generate multiple problem instances. Our numerical results show that the proposed vaccine allocation policy achieves a larger reduction in the number of susceptible individuals, infections and deaths globally compared to a population-based policy. In addition, we show that, under a fixed global vaccine allocation budget, most countries can reduce their national number of infections and deaths by sharing their budget with countries with which they have a relatively high mobility exchange. The proposed framework can be used to improve policy-making in health care management by national and global health authorities.
Dynamic Pricing and Demand Learning on a Large Network of Products: A PAC-Bayesian Approach
Nov 10, 2021We consider a seller offering a large network of $N$ products over a time horizon of $T$ periods. The seller does not know the parameters of the products' linear demand model, and can dynamically adjust product prices to learn the demand model based on sales observations. The seller aims to minimize its pseudo-regret, i.e., the expected revenue loss relative to a clairvoyant who knows the underlying demand model. We consider a sparse set of demand relationships between products to characterize various connectivity properties of the product network. In particular, we study three different sparsity frameworks: (1) $L_0$ sparsity, which constrains the number of connections in the network, and (2) off-diagonal sparsity, which constrains the magnitude of cross-product price sensitivities, and (3) a new notion of spectral sparsity, which constrains the asymptotic decay of a similarity metric on network nodes. We propose a dynamic pricing-and-learning policy that combines the optimism-in-the-face-of-uncertainty and PAC-Bayesian approaches, and show that this policy achieves asymptotically optimal performance in terms of $N$ and $T$. We also show that in the case of spectral and off-diagonal sparsity, the seller can have a pseudo-regret linear in $N$, even when the network is dense.
Rapid Model Architecture Adaption for Meta-Learning
Sep 10, 2021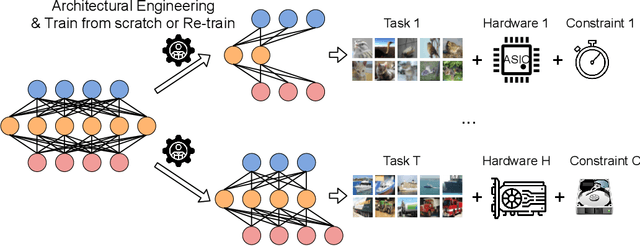

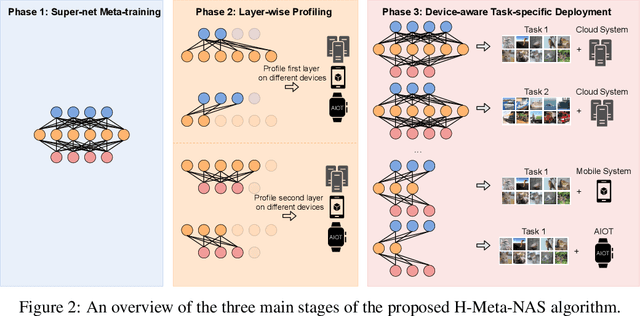

Network Architecture Search (NAS) methods have recently gathered much attention. They design networks with better performance and use a much shorter search time compared to traditional manual tuning. Despite their efficiency in model deployments, most NAS algorithms target a single task on a fixed hardware system. However, real-life few-shot learning environments often cover a great number of tasks (T ) and deployments on a wide variety of hardware platforms (H ). The combinatorial search complexity T times H creates a fundamental search efficiency challenge if one naively applies existing NAS methods to these scenarios. To overcome this issue, we show, for the first time, how to rapidly adapt model architectures to new tasks in a many-task many-hardware few-shot learning setup by integrating Model Agnostic Meta Learning (MAML) into the NAS flow. The proposed NAS method (H-Meta-NAS) is hardware-aware and performs optimisation in the MAML framework. H-Meta-NAS shows a Pareto dominance compared to a variety of NAS and manual baselines in popular few-shot learning benchmarks with various hardware platforms and constraints. In particular, on the 5-way 1-shot Mini-ImageNet classification task, the proposed method outperforms the best manual baseline by a large margin (5.21% in accuracy) using 60% less computation.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 15, 2021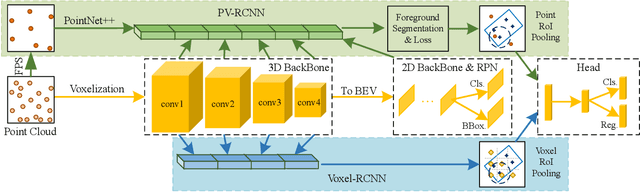
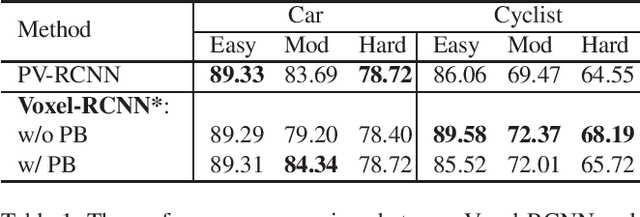

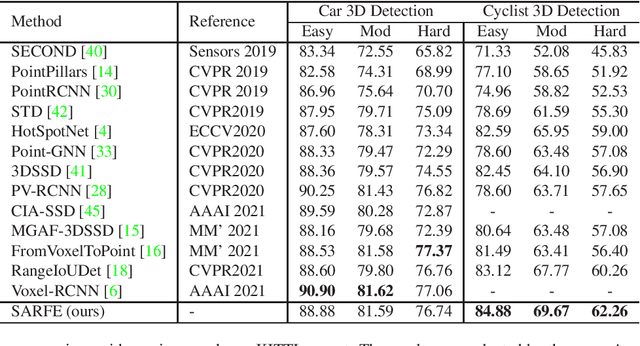
Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.
Continual Neural Mapping: Learning An Implicit Scene Representation from Sequential Observations
Aug 12, 2021
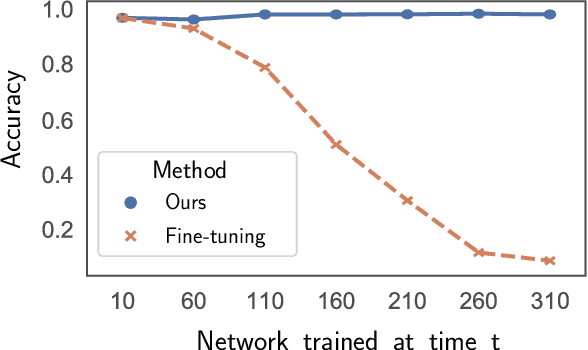
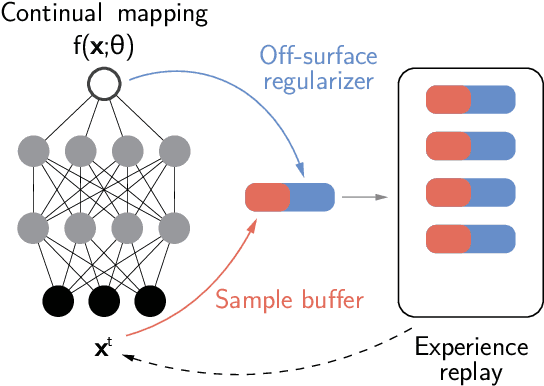
Recent advances have enabled a single neural network to serve as an implicit scene representation, establishing the mapping function between spatial coordinates and scene properties. In this paper, we make a further step towards continual learning of the implicit scene representation directly from sequential observations, namely Continual Neural Mapping. The proposed problem setting bridges the gap between batch-trained implicit neural representations and commonly used streaming data in robotics and vision communities. We introduce an experience replay approach to tackle an exemplary task of continual neural mapping: approximating a continuous signed distance function (SDF) from sequential depth images as a scene geometry representation. We show for the first time that a single network can represent scene geometry over time continually without catastrophic forgetting, while achieving promising trade-offs between accuracy and efficiency.
STALP: Style Transfer with Auxiliary Limited Pairing
Oct 20, 2021We present an approach to example-based stylization of images that uses a single pair of a source image and its stylized counterpart. We demonstrate how to train an image translation network that can perform real-time semantically meaningful style transfer to a set of target images with similar content as the source image. A key added value of our approach is that it considers also consistency of target images during training. Although those have no stylized counterparts, we constrain the translation to keep the statistics of neural responses compatible with those extracted from the stylized source. In contrast to concurrent techniques that use a similar input, our approach better preserves important visual characteristics of the source style and can deliver temporally stable results without the need to explicitly handle temporal consistency. We demonstrate its practical utility on various applications including video stylization, style transfer to panoramas, faces, and 3D models.
Human-Robot Interaction via a Joint-Initiative Supervised Autonomy (JISA) Framework
Sep 10, 2021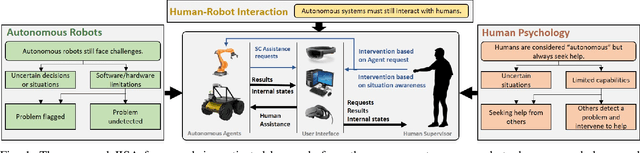
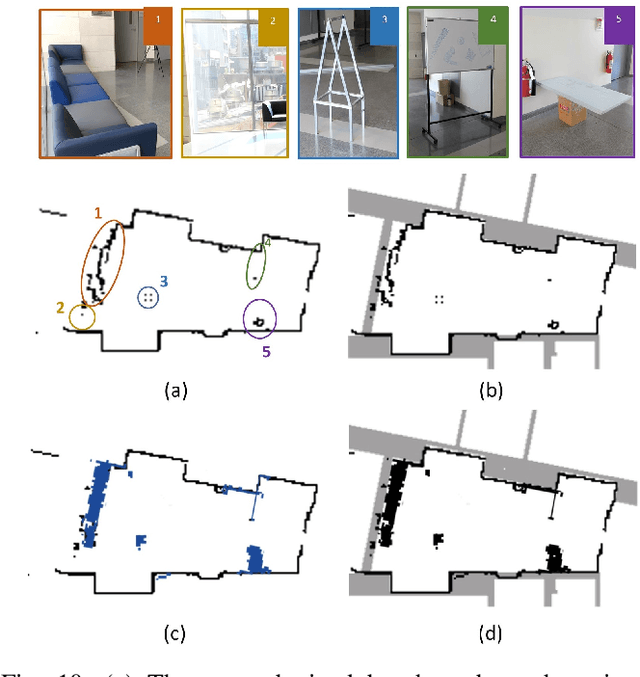
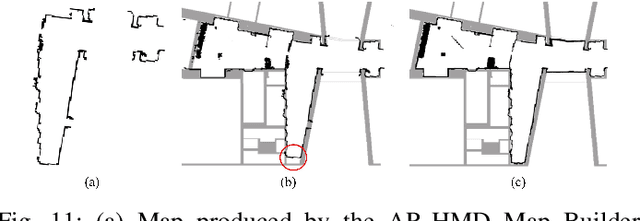

In this paper, we propose and validate a Joint-Initiative Supervised Autonomy (JISA) framework for Human-Robot Interaction (HRI), in which a robot maintains a measure of its self-confidence (SC) while performing a task, and only prompts the human supervisor for help when its SC drops. At the same time, during task execution, a human supervisor can intervene in the task being performed, based on his/her Situation Awareness (SA). To evaluate the applicability and utility of JISA, it is implemented on two different HRI tasks: grid-based collaborative simultaneous localization and mapping (SLAM) and automated jigsaw puzzle reconstruction. Augmented Reality (AR) (for SLAM) and two-dimensional graphical user interfaces (GUI) (for puzzle reconstruction) are custom-designed to enhance human SA and allow intuitive interaction between the human and the agent. The superiority of the JISA framework is demonstrated in experiments. In SLAM, the superior maps produced by JISA preclude the need for post processing of any SLAM stock maps; furthermore, JISA reduces the required mapping time by approximately 50 percent versus traditional approaches. In automated puzzle reconstruction, the JISA framework outperforms both fully autonomous solutions, as well as those resulting from on-demand human intervention prompted by the agent.
Balancing Value Underestimation and Overestimation with Realistic Actor-Critic
Nov 10, 2021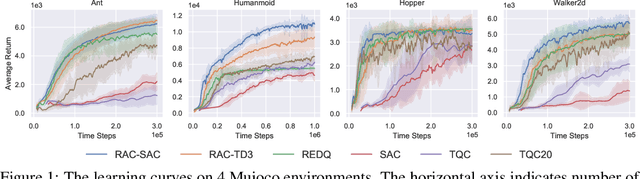

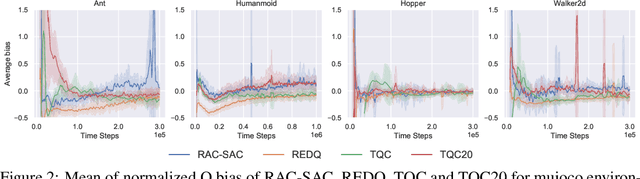
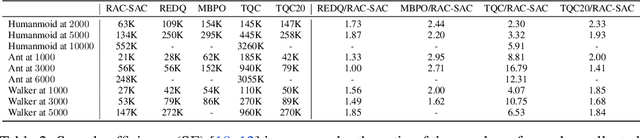
Model-free deep reinforcement learning (RL) has been successfully applied to challenging continuous control domains. However, poor sample efficiency prevents these methods from being widely used in real-world domains. We address this problem by proposing a novel model-free algorithm, Realistic Actor-Critic(RAC), which aims to solve trade-offs between value underestimation and overestimation by learning a policy family concerning various confidence-bounds of Q-function. We construct uncertainty punished Q-learning(UPQ), which uses uncertainty from the ensembling of multiple critics to control estimation bias of Q-function, making Q-functions smoothly shift from lower- to higher-confidence bounds. With the guide of these critics, RAC employs Universal Value Function Approximators (UVFA) to simultaneously learn many optimistic and pessimistic policies with the same neural network. Optimistic policies generate effective exploratory behaviors, while pessimistic policies reduce the risk of value overestimation to ensure stable updates of policies and Q-functions. The proposed method can be incorporated with any off-policy actor-critic RL algorithms. Our method achieve 10x sample efficiency and 25\% performance improvement compared to SAC on the most challenging Humanoid environment, obtaining the episode reward $11107\pm 475$ at $10^6$ time steps. All the source codes are available at https://github.com/ihuhuhu/RAC.