 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSP-SLAM++: A Unified Framework for Multi-Class, High-Fidelity Object SLAM in the Wild
Jun 24, 2026Existing object-aware SLAM systems force a trade-off between real-time performance, multi-class support, and the generation of high-fidelity, semantically coherent object models. To address this trade-off, we present DSP-SLAM++, which extends the DSP-SLAM framework with an asynchronous mapping pipeline for real-time performance and dedicated sensor fusion adaptations for a monocular fisheye-LiDAR suite. Experiments demonstrate that our system generates fine-grained, geometrically-complete shapes for multiple object classes while eliminating severe mapping thread bottlenecks by reducing maximum object processing latency by up to 70\% compared to the state-of-the-art baseline, enabling robust, real-time performance on a challenging 25 Hz multi-class datasets. This work makes high-fidelity, multi-class object SLAM more practical for real-world applications like autonomous driving and robotic manipulation by enabling its use on platforms with common fisheye-LiDAR sensor setups. The open-source code is available at: [github.com/AUBVRL/DSP-SLAMpp].
ADM-Fusion: Adaptive Deep Multi-Sensor Fusion for Robust Ego-Motion Estimation in Diverse Conditions
Jun 23, 2026Robust multi-sensor fusion is essential for reliable autonomy in diverse and degraded environments, where sensor reliability can fluctuate rapidly. Because different modalities fail in distinct ways, effective fusion should adaptively balance complementary cues rather than rely on fixed weighting. This adaptability is particularly important for ego-motion estimation, since accurate updates depend on the consistent integration of complementary sensor information. We propose ADM-Fusion, an end-to-end deep learning based multi-sensor fusion method designed to adapt to environmental changes and sensor degradation. ADM-Fusion employs an adaptive sensor mixture-of-experts framework with content-aware routing to dynamically assign weights to sensor inputs in real time. The system further incorporates separate translation and rotation branches, coupled through a cross-task attention mechanism to preserve task-specific specialization while enabling information sharing. ADM-Fusion is trained on the CARLA-LOC simulated dataset and subsequently fine-tuned on KITTI real-world data, demonstrating effective simulation-to-real transfer. Experiments show that ADM-Fusion remains robust under degraded conditions while maintaining competitive performance against existing methods.
Inline Photometrically Calibrated Hybrid Visual SLAM
Sep 25, 2024



This paper presents an integrated approach to Visual SLAM, merging online sequential photometric calibration within a Hybrid direct-indirect visual SLAM (H-SLAM). Photometric calibration helps normalize pixel intensity values under different lighting conditions, and thereby improves the direct component of our H-SLAM. A tangential benefit also results to the indirect component of H-SLAM given that the detected features are more stable across variable lighting conditions. Our proposed photometrically calibrated H-SLAM is tested on several datasets, including the TUM monoVO as well as on a dataset we created. Calibrated H-SLAM outperforms other state of the art direct, indirect, and hybrid Visual SLAM systems in all the experiments. Furthermore, in online SLAM tested at our site, it also significantly outperformed the other SLAM Systems.
MaskUno: Switch-Split Block For Enhancing Instance Segmentation
Jul 31, 2024



Instance segmentation is an advanced form of image segmentation which, beyond traditional segmentation, requires identifying individual instances of repeating objects in a scene. Mask R-CNN is the most common architecture for instance segmentation, and improvements to this architecture include steps such as benefiting from bounding box refinements, adding semantics, or backbone enhancements. In all the proposed variations to date, the problem of competing kernels (each class aims to maximize its own accuracy) persists when models try to synchronously learn numerous classes. In this paper, we propose mitigating this problem by replacing mask prediction with a Switch-Split block that processes refined ROIs, classifies them, and assigns them to specialized mask predictors. We name the method MaskUno and test it on various models from the literature, which are then trained on multiple classes using the benchmark COCO dataset. An increase in the mean Average Precision (mAP) of 2.03% was observed for the high-performing DetectoRS when trained on 80 classes. MaskUno proved to enhance the mAP of instance segmentation models regardless of the number and typ
H-SLAM: Hybrid Direct-Indirect Visual SLAM
Jun 12, 2023



The recent success of hybrid methods in monocular odometry has led to many attempts to generalize the performance gains to hybrid monocular SLAM. However, most attempts fall short in several respects, with the most prominent issue being the need for two different map representations (local and global maps), with each requiring different, computationally expensive, and often redundant processes to maintain. Moreover, these maps tend to drift with respect to each other, resulting in contradicting pose and scene estimates, and leading to catastrophic failure. In this paper, we propose a novel approach that makes use of descriptor sharing to generate a single inverse depth scene representation. This representation can be used locally, queried globally to perform loop closure, and has the ability to re-activate previously observed map points after redundant points are marginalized from the local map, eliminating the need for separate and redundant map maintenance processes. The maps generated by our method exhibit no drift between each other, and can be computed at a fraction of the computational cost and memory footprint required by other monocular SLAM systems. Despite the reduced resource requirements, the proposed approach maintains its robustness and accuracy, delivering performance comparable to state-of-the-art SLAM methods (e.g., LDSO, ORB-SLAM3) on the majority of sequences from well-known datasets like EuRoC, KITTI, and TUM VI. The source code is available at: https://github.com/AUBVRL/fslam_ros_docker.
OSPC: Online Sequential Photometric Calibration
May 28, 2023



Photometric calibration is essential to many computer vision applications. One of its key benefits is enhancing the performance of Visual SLAM, especially when it depends on a direct method for tracking, such as the standard KLT algorithm. Another advantage could be in retrieving the sensor irradiance values from measured intensities, as a pre-processing step for some vision algorithms, such as shape-from-shading. Current photometric calibration systems rely on a joint optimization problem and encounter an ambiguity in the estimates, which can only be resolved using ground truth information. We propose a novel method that solves for photometric parameters using a sequential estimation approach. Our proposed method achieves high accuracy in estimating all parameters; furthermore, the formulations are linear and convex, which makes the solution fast and suitable for online applications. Experiments on a Visual Odometry system validate the proposed method and demonstrate its advantages.
Human-Robot Interaction via a Joint-Initiative Supervised Autonomy (JISA) Framework
Sep 10, 2021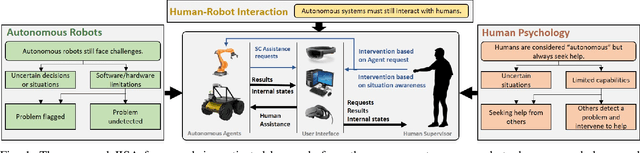
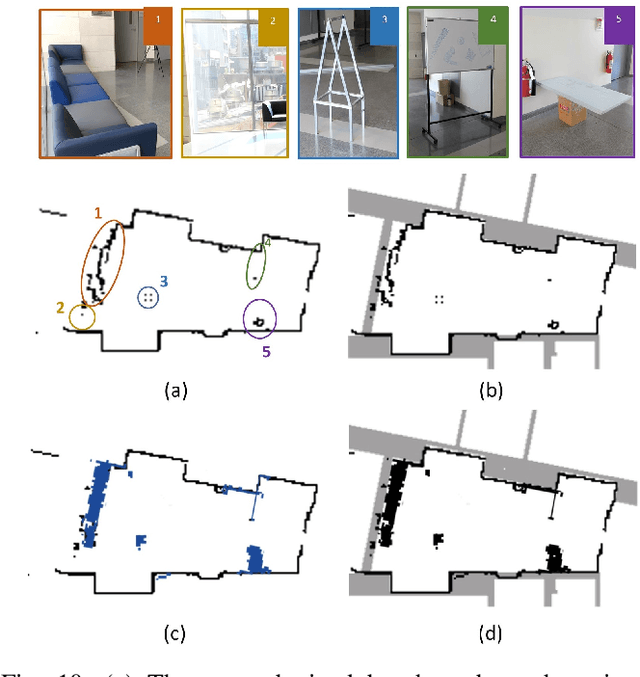
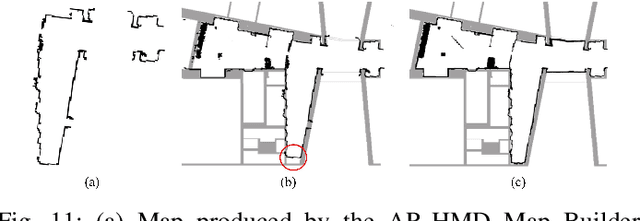

In this paper, we propose and validate a Joint-Initiative Supervised Autonomy (JISA) framework for Human-Robot Interaction (HRI), in which a robot maintains a measure of its self-confidence (SC) while performing a task, and only prompts the human supervisor for help when its SC drops. At the same time, during task execution, a human supervisor can intervene in the task being performed, based on his/her Situation Awareness (SA). To evaluate the applicability and utility of JISA, it is implemented on two different HRI tasks: grid-based collaborative simultaneous localization and mapping (SLAM) and automated jigsaw puzzle reconstruction. Augmented Reality (AR) (for SLAM) and two-dimensional graphical user interfaces (GUI) (for puzzle reconstruction) are custom-designed to enhance human SA and allow intuitive interaction between the human and the agent. The superiority of the JISA framework is demonstrated in experiments. In SLAM, the superior maps produced by JISA preclude the need for post processing of any SLAM stock maps; furthermore, JISA reduces the required mapping time by approximately 50 percent versus traditional approaches. In automated puzzle reconstruction, the JISA framework outperforms both fully autonomous solutions, as well as those resulting from on-demand human intervention prompted by the agent.
The benefits of synthetic data for action categorization
Jan 20, 2020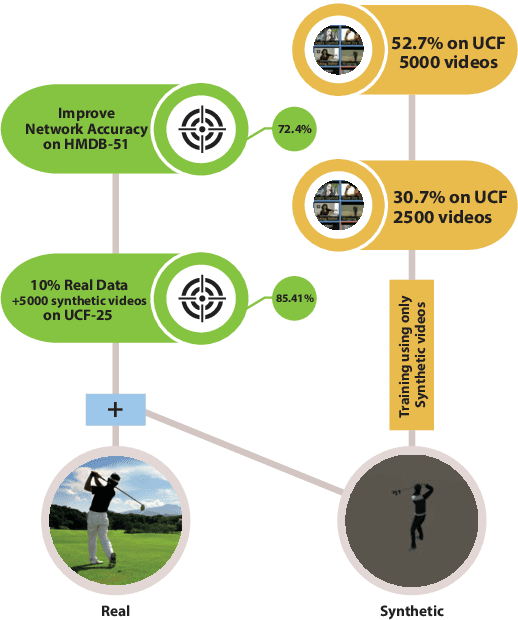

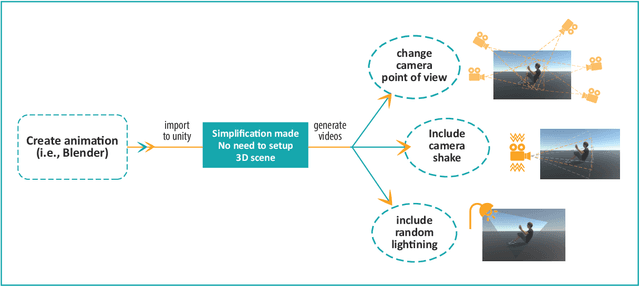
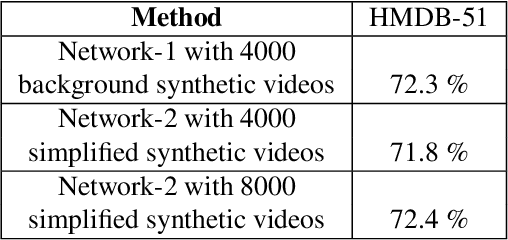
In this paper, we study the value of using synthetically produced videos as training data for neural networks used for action categorization. Motivated by the fact that texture and background of a video play little to no significant roles in optical flow, we generated simplified texture-less and background-less videos and utilized the synthetic data to train a Temporal Segment Network (TSN). The results demonstrated that augmenting TSN with simplified synthetic data improved the original network accuracy (68.5%), achieving 71.8% on HMDB-51 when adding 4,000 videos and 72.4% when adding 8,000 videos. Also, training using simplified synthetic videos alone on 25 classes of UCF-101 achieved 30.71% when trained on 2500 videos and 52.7% when trained on 5000 videos. Finally, results showed that when reducing the number of real videos of UCF-25 to 10% and combining them with synthetic videos, the accuracy drops to only 85.41%, compared to a drop to 77.4% when no synthetic data is added.
Change your singer: a transfer learning generative adversarial framework for song to song conversion
Nov 07, 2019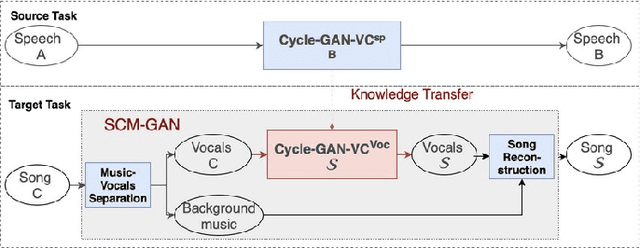
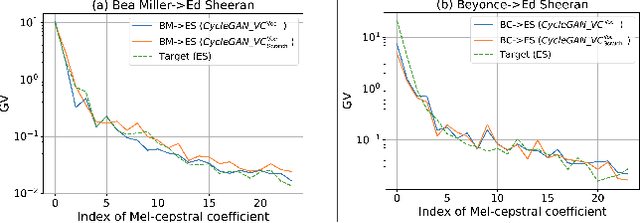
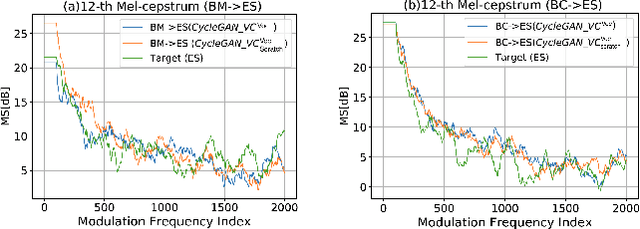
Have you ever wondered how a song might sound if performed by a different artist? In this work, we propose SCM-GAN, an end-to-end non-parallel song conversion system powered by generative adversarial and transfer learning that allows users to listen to a selected target singer singing any song. SCM-GAN first separates songs into vocals and instrumental music using a U-Net network, then converts the vocal segments to the target singer using advanced CycleGAN-VC, before merging the converted vocals with their corresponding background music. SCM-GAN is first initialized with feature representations learned from a state-of-the-art voice-to-voice conversion and then trained on a dataset of non-parallel songs. Furthermore, SCM-GAN is evaluated against a set of metrics including global variance GV and modulation spectra MS on the 24 Mel-cepstral coefficients (MCEPs). Transfer learning improves the GV by 35% and the MS by 13% on average. A subjective comparison is conducted to test the user satisfaction with the quality and the naturalness of the conversion. Results show above par similarity between SCM-GAN's output and the target (70\% on average) as well as great naturalness of the converted songs.
A Unified Formulation for Visual Odometry
Mar 11, 2019
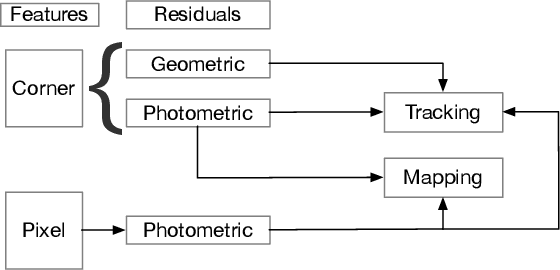
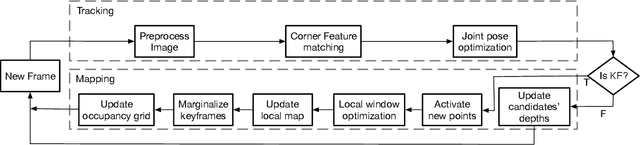

Monocular Odometry systems can be broadly categorized as being either Direct, Indirect, or a hybrid of both. While Indirect systems process an alternative image representation to compute geometric residuals, Direct methods process the image pixels directly to generate photometric residuals. Both paradigms have distinct but often complementary properties. This paper presents a Unified Formulation for Visual Odometry, referred to as UFVO, with the following key contributions: (1) a tight coupling of photometric (Direct) and geometric (Indirect) measurements using a joint multi-objective optimization, (2) the use of a utility function as a decision maker that incorporates prior knowledge on both paradigms, (3) descriptor sharing, where a feature can have more than one type of descriptor and its different descriptors are used for tracking and mapping, (4) the depth estimation of both corner features and pixel features within the same map using an inverse depth parametrization, and (5) a corner and pixel selection strategy that extracts both types of information, while promoting a uniform distribution over the image domain. Experiments show that our proposed system can handle large inter-frame motions, inherits the sub-pixel accuracy of direct methods, can run efficiently in real-time, can generate an Indirect map representation at a marginal computational cost when compared to traditional Indirect systems, all while outperforming state of the art in Direct, Indirect and hybrid systems.