 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCBench: A Streaming Counting Benchmark for Spatial-Temporal State Maintenance in Long Videos
Mar 13, 2026Video understanding requires models to continuously track and update world state during playback. While existing benchmarks have advanced video understanding evaluation across multiple dimensions, the observation of how models maintain world state remains insufficient. We propose VCBench, a streaming counting benchmark that repositions counting as a minimal probe for diagnosing world state maintenance capability. We decompose this capability into object counting (tracking currently visible objects vs.\ tracking cumulative unique identities) and event counting (detecting instantaneous actions vs.\ tracking complete activity cycles), forming 8 fine-grained subcategories. VCBench contains 406 videos with frame-by-frame annotations of 10,071 event occurrence moments and object state change moments, generating 1,000 streaming QA pairs with 4,576 query points along timelines. By observing state maintenance trajectories through streaming multi-point queries, we design three complementary metrics to diagnose numerical precision, trajectory consistency, and temporal awareness. Evaluation on mainstream video-language models shows that current models still exhibit significant deficiencies in spatial-temporal state maintenance, particularly struggling with tasks like periodic event counting. VCBench provides a diagnostic framework for measuring and improving state maintenance in video understanding systems.
Structure Information is the Key: Self-Attention RoI Feature Extractor in 3D Object Detection
Nov 15, 2021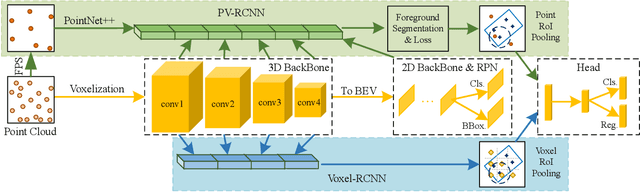
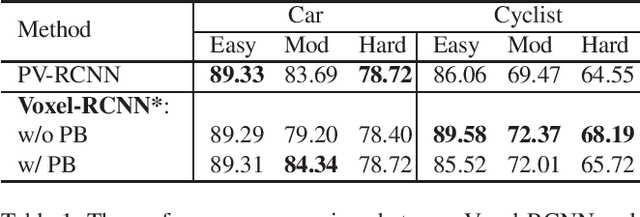

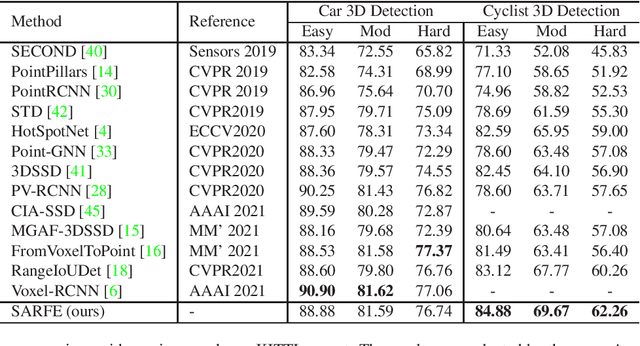
Unlike 2D object detection where all RoI features come from grid pixels, the RoI feature extraction of 3D point cloud object detection is more diverse. In this paper, we first compare and analyze the differences in structure and performance between the two state-of-the-art models PV-RCNN and Voxel-RCNN. Then, we find that the performance gap between the two models does not come from point information, but structural information. The voxel features contain more structural information because they do quantization instead of downsampling to point cloud so that they can contain basically the complete information of the whole point cloud. The stronger structural information in voxel features makes the detector have higher performance in our experiments even if the voxel features don't have accurate location information. Then, we propose that structural information is the key to 3D object detection. Based on the above conclusion, we propose a Self-Attention RoI Feature Extractor (SARFE) to enhance structural information of the feature extracted from 3D proposals. SARFE is a plug-and-play module that can be easily used on existing 3D detectors. Our SARFE is evaluated on both KITTI dataset and Waymo Open dataset. With the newly introduced SARFE, we improve the performance of the state-of-the-art 3D detectors by a large margin in cyclist on KITTI dataset while keeping real-time capability.