 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PL-VINS: Real-Time Monocular Visual-Inertial SLAM with Point and Line Features
Oct 11, 2020

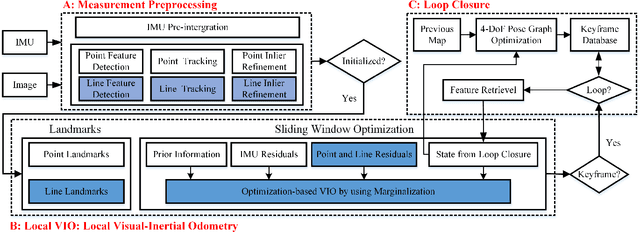

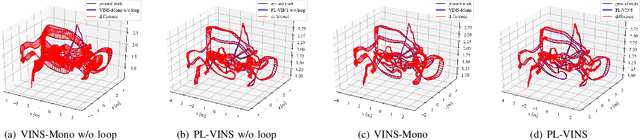
Leveraging line features to improve localization accuracy of point-based visual-inertial SLAM (VINS) is gaining interest as they provide additional constraints on scene structure. However, real-time performance when incorporating line features in VINS has not been addressed. This paper presents PL-VINS, a real-time optimization-based monocular VINS method with point and line features, developed based on the state-of-the-art point-based VINS-Mono \cite{vins}. We observe that current works use the LSD \cite{lsd} algorithm to extract line features; however, LSD is designed for scene shape representation instead of the pose estimation problem, which becomes the bottleneck for the real-time performance due to its high computational cost. In this paper, a modified LSD algorithm is presented by studying a hidden parameter tuning and length rejection strategy. The modified LSD can run at least three times as fast as LSD. Further, by representing space lines with the Pl\"{u}cker coordinates, the residual error in line estimation is modeled in terms of the point-to-line distance, which is then minimized by iteratively updating the minimum four-parameter orthonormal representation of the Pl\"{u}cker coordinates. Experiments in a public benchmark dataset show that the localization error of our method is 12-16\% less than that of VINS-Mono at the same pose update frequency. %For the benefit of the community, The source code of our method is available at: https://github.com/cnqiangfu/PL-VINS.
Integrated Multiscale Domain Adaptive YOLO
Feb 07, 2022
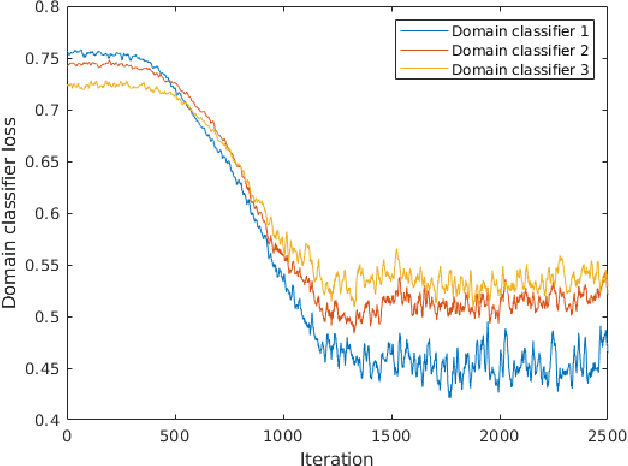
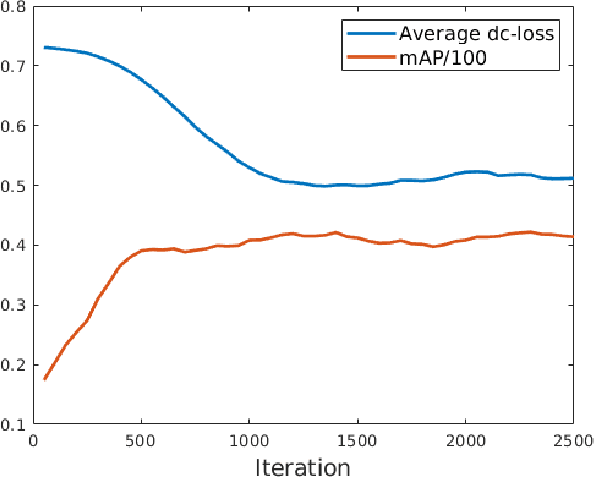
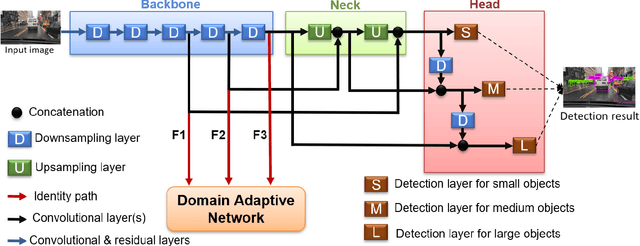
The area of domain adaptation has been instrumental in addressing the domain shift problem encountered by many applications. This problem arises due to the difference between the distributions of source data used for training in comparison with target data used during realistic testing scenarios. In this paper, we introduce a novel MultiScale Domain Adaptive YOLO (MS-DAYOLO) framework that employs multiple domain adaptation paths and corresponding domain classifiers at different scales of the recently introduced YOLOv4 object detector. Building on our baseline multiscale DAYOLO framework, we introduce three novel deep learning architectures for a Domain Adaptation Network (DAN) that generates domain-invariant features. In particular, we propose a Progressive Feature Reduction (PFR), a Unified Classifier (UC), and an Integrated architecture. We train and test our proposed DAN architectures in conjunction with YOLOv4 using popular datasets. Our experiments show significant improvements in object detection performance when training YOLOv4 using the proposed MS-DAYOLO architectures and when tested on target data for autonomous driving applications. Moreover, MS-DAYOLO framework achieves an order of magnitude real-time speed improvement relative to Faster R-CNN solutions while providing comparable object detection performance.
Coupling Online-Offline Learning for Multi-distributional Data Streams
Feb 12, 2022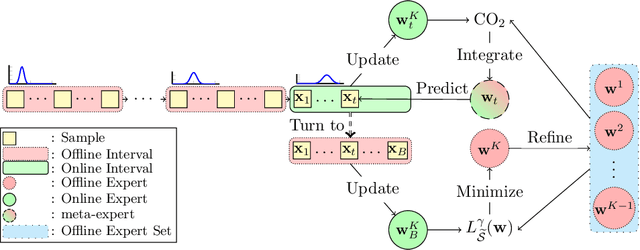
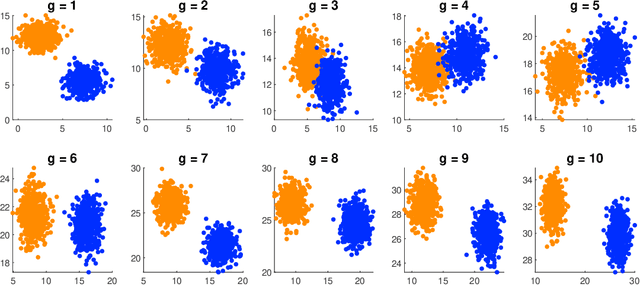
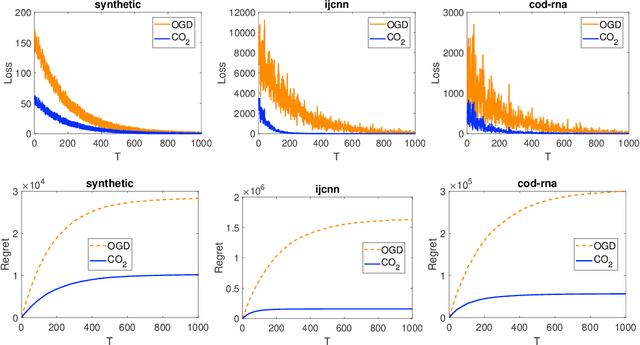
The distributions of real-life data streams are usually nonstationary, where one exciting setting is that a stream can be decomposed into several offline intervals with a fixed time horizon but different distributions and an out-of-distribution online interval. We call such data multi-distributional data streams, on which learning an on-the-fly expert for unseen samples with a desirable generalization is demanding yet highly challenging owing to the multi-distributional streaming nature, particularly when initially limited data is available for the online interval. To address these challenges, this work introduces a novel optimization method named coupling online-offline learning (CO$_2$) with theoretical guarantees about the knowledge transfer, the regret, and the generalization error. CO$_2$ extracts knowledge by training an offline expert for each offline interval and update an online expert by an off-the-shelf online optimization method in the online interval. CO$_2$ outputs a hypothesis for each sample by adaptively coupling both the offline experts and the underlying online expert through an expert-tracking strategy to adapt to the dynamic environment. To study the generalization performance of the output hypothesis, we propose a general theory to analyze its excess risk bound related to the loss function properties, the hypothesis class, the data distribution, and the regret.
Real-Time Model Calibration with Deep Reinforcement Learning
Jun 09, 2020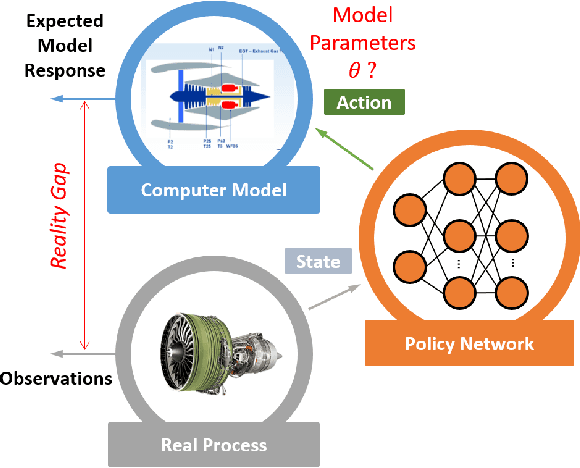
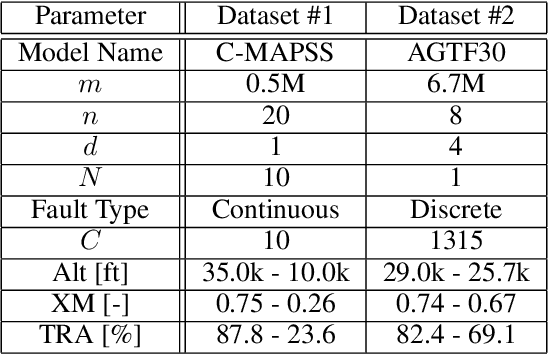
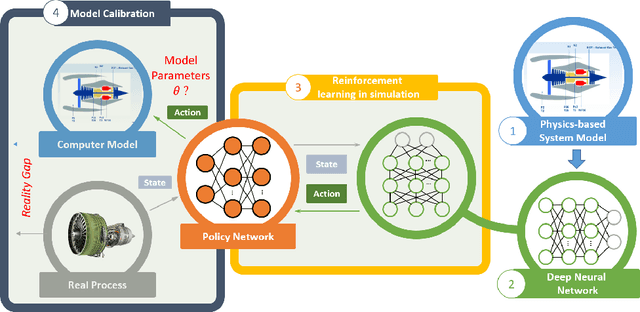
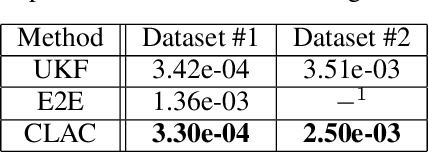
The dynamic, real-time, and accurate inference of model parameters from empirical data is of great importance in many scientific and engineering disciplines that use computational models (such as a digital twin) for the analysis and prediction of complex physical processes. However, fast and accurate inference for processes with large and high dimensional datasets cannot easily be achieved with state-of-the-art methods under noisy real-world conditions. The primary reason is that the inference of model parameters with traditional techniques based on optimisation or sampling often suffers from computational and statistical challenges, resulting in a trade-off between accuracy and deployment time. In this paper, we propose a novel framework for inference of model parameters based on reinforcement learning. The contribution of the paper is twofold: 1) We reformulate the inference problem as a tracking problem with the objective of learning a policy that forces the response of the physics-based model to follow the observations; 2) We propose the constrained Lyapunov-based actor-critic (CLAC) algorithm to enable the robust and accurate inference of physics-based model parameters in real time under noisy real-world conditions. The proposed methodology is demonstrated and evaluated on two model-based diagnostics test cases utilizing two different physics-based models of turbofan engines. The performance of the methodology is compared to that of two alternative approaches: a state update method (unscented Kalman filter) and a supervised end-to-end mapping with deep neural networks. The experimental results demonstrate that the proposed methodology outperforms all other tested methods in terms of speed and robustness, with high inference accuracy.
Cognitive Computing to Optimize IT Services
Dec 28, 2021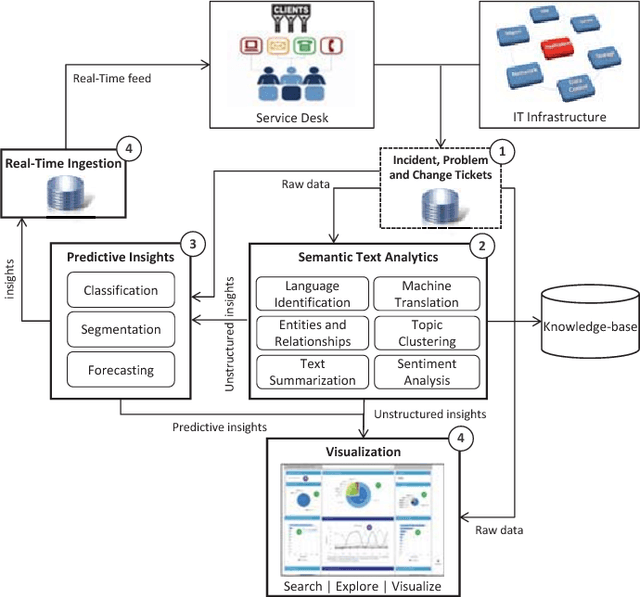
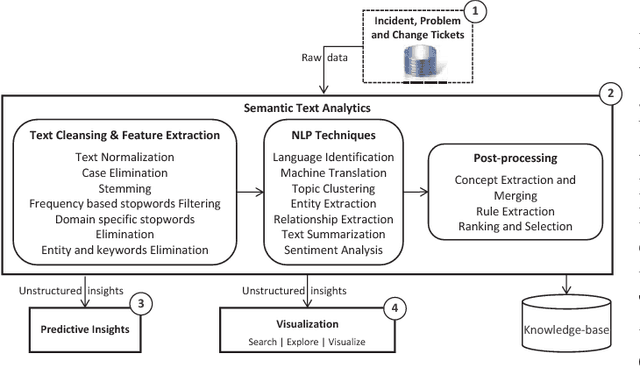
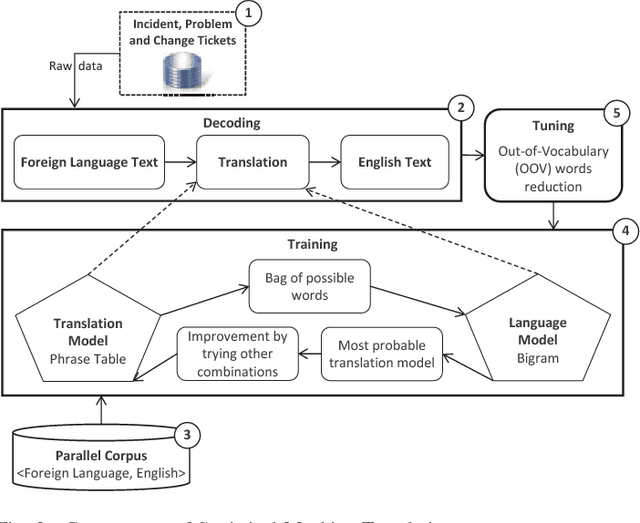
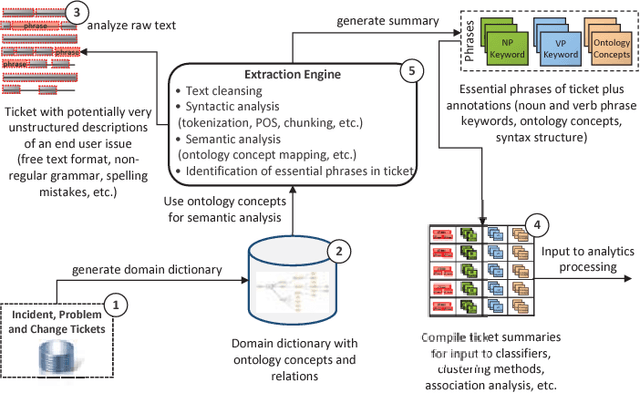
In this paper, the challenges of maintaining a healthy IT operational environment have been addressed by proactively analyzing IT Service Desk tickets, customer satisfaction surveys, and social media data. A Cognitive solution goes beyond the traditional structured data analysis by deep analyses of both structured and unstructured text. The salient features of the proposed platform include language identification, translation, hierarchical extraction of the most frequently occurring topics, entities and their relationships, text summarization, sentiments, and knowledge extraction from the unstructured text using Natural Language Processing techniques. Moreover, the insights from unstructured text combined with structured data allow the development of various classification, segmentation, and time-series forecasting use-cases on the incident, problem, and change datasets. Further, the text and predictive insights together with raw data are used for visualization and exploration of actionable insights on a rich and interactive dashboard. However, it is hard not only to find these insights using traditional structured data analysis but it might also take a very long time to discover them, especially while dealing with a massive amount of unstructured data. By taking action on these insights, organizations can benefit from a significant reduction of ticket volume, reduced operational costs, and increased customer satisfaction. In various experiments, on average, upto 18-25% of yearly ticket volume has been reduced using the proposed approach.
Adaptive Online Incremental Learning for Evolving Data Streams
Jan 05, 2022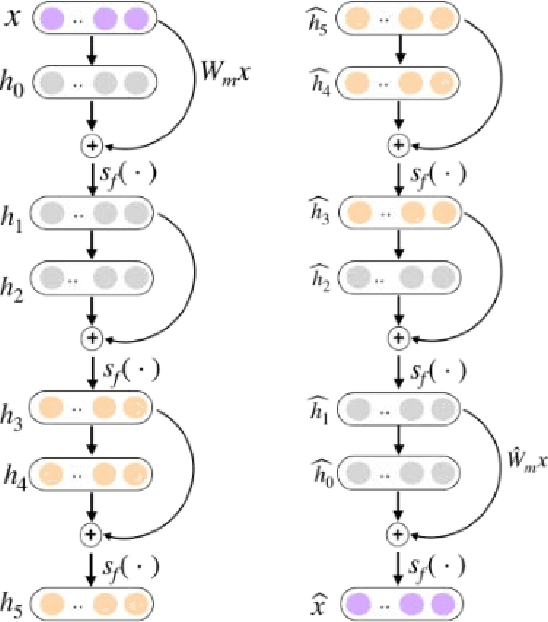
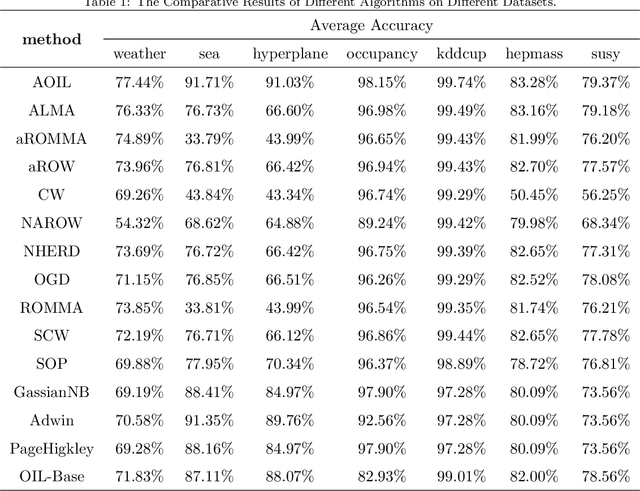
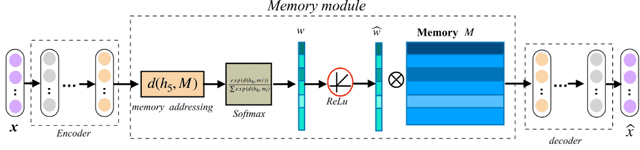
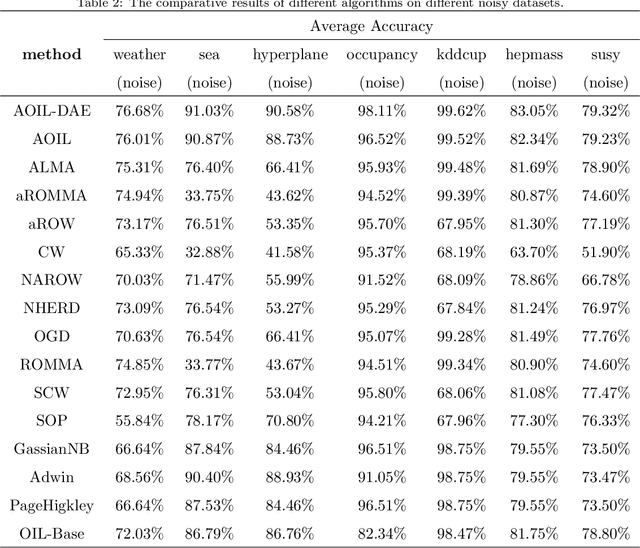
Recent years have witnessed growing interests in online incremental learning. However, there are three major challenges in this area. The first major difficulty is concept drift, that is, the probability distribution in the streaming data would change as the data arrives. The second major difficulty is catastrophic forgetting, that is, forgetting what we have learned before when learning new knowledge. The last one we often ignore is the learning of the latent representation. Only good latent representation can improve the prediction accuracy of the model. Our research builds on this observation and attempts to overcome these difficulties. To this end, we propose an Adaptive Online Incremental Learning for evolving data streams (AOIL). We use auto-encoder with the memory module, on the one hand, we obtained the latent features of the input, on the other hand, according to the reconstruction loss of the auto-encoder with memory module, we could successfully detect the existence of concept drift and trigger the update mechanism, adjust the model parameters in time. In addition, we divide features, which are derived from the activation of the hidden layers, into two parts, which are used to extract the common and private features respectively. By means of this approach, the model could learn the private features of the new coming instances, but do not forget what we have learned in the past (shared features), which reduces the occurrence of catastrophic forgetting. At the same time, to get the fusion feature vector we use the self-attention mechanism to effectively fuse the extracted features, which further improved the latent representation learning.
* 40 pages
Minimizing Entropy to Discover Good Solutions to Recurrent Mixed Integer Programs
Feb 07, 2022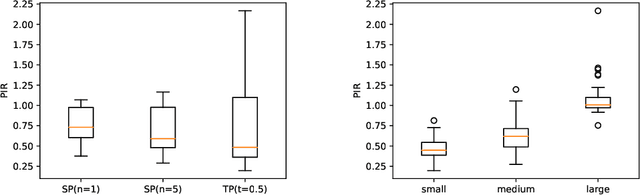
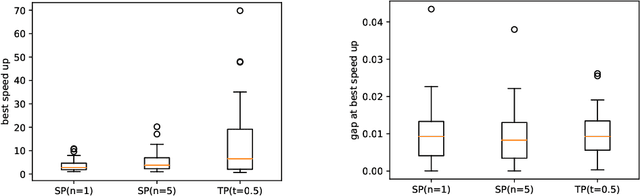
Current state-of-the-art solvers for mixed-integer programming (MIP) problems are designed to perform well on a wide range of problems. However, for many real-world use cases, problem instances come from a narrow distribution. This has motivated the development of specialized methods that can exploit the information in historical datasets to guide the design of heuristics. Recent works have shown that machine learning (ML) can be integrated with an MIP solver to inject domain knowledge and efficiently close the optimality gap. This hybridization is usually done with deep learning (DL), which requires a large dataset and extensive hyperparameter tuning to perform well. This paper proposes an online heuristic that uses the notion of entropy to efficiently build a model with minimal training data and tuning. We test our method on the locomotive assignment problem (LAP), a recurring real-world problem that is challenging to solve at scale. Experimental results show a speed up of an order of magnitude compared to a general purpose solver (CPLEX) with a relative gap of less than 2%. We also observe that for some instances our method can discover better solutions than CPLEX within the time limit.
Event-centric Query Suggestion for Online News
Jan 12, 2022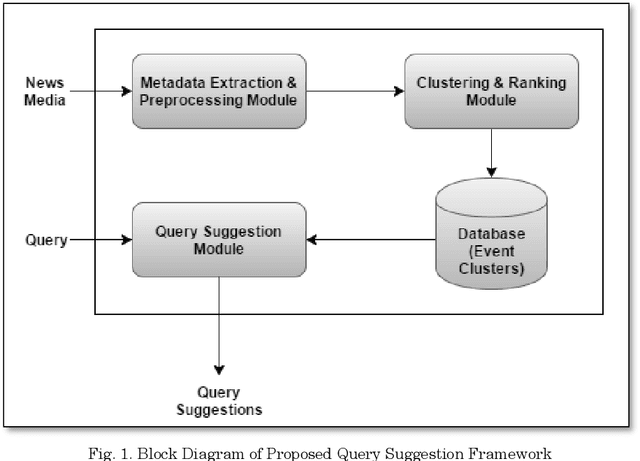
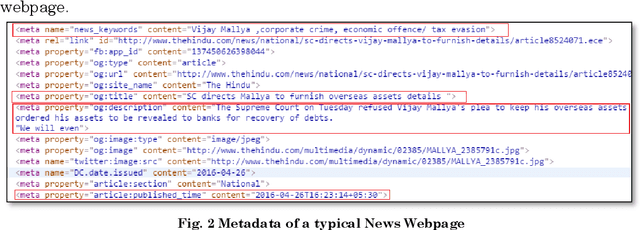
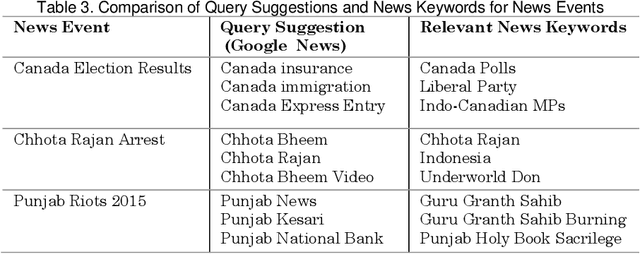
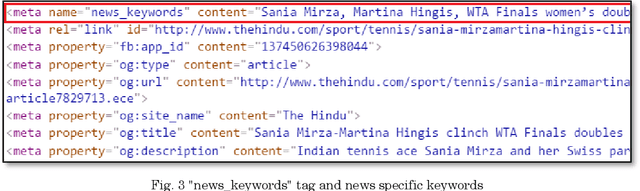
Query suggestion refers to the task of suggesting relevant and related queries to a search engine user to help in query formulation process and to expedite information retrieval with minimum amount of effort. It is highly useful in situations where the search requirements are not well understood and hence it has been widely adopted by search engines to guide users' search activity. For news websites, user queries have a time sensitive nature inherent in them. When some new event happens, there is a sudden burst in queries related to that event and such queries are sustained over a period of time before fading away with that event. In addition to this temporal aspect of search queries fired at news websites, they have an addition distinct quality, i.e., they are intended to get event related information majority of the times. Existing work on generating query suggestions involves analyzing query logs to suggest queries which are relevant and related to the search intent of the user. But in case of news websites, when there is a sudden burst in information related to a particular event, there are not enough search queries fired by other users which leads to lack of click data, and hence giving query suggestions related to some old event or even some irrelevant suggestions altogether. Another problem with query logs in the context of online news is that, they mostly contain queries related to popular events and hence fail to capture less popular events or events which got overshadowed by some other more sensational event. We propose a novel approach to generate event-centric query suggestions using metadata of news articles published by news media. We compared our proposed framework with existing state of the art query suggestion mechanisms provided by Google News, Bing News, Google Search and Bing Search on various parameters.
Corrupted Image Modeling for Self-Supervised Visual Pre-Training
Feb 07, 2022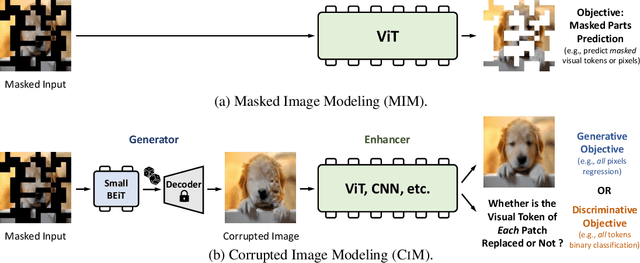

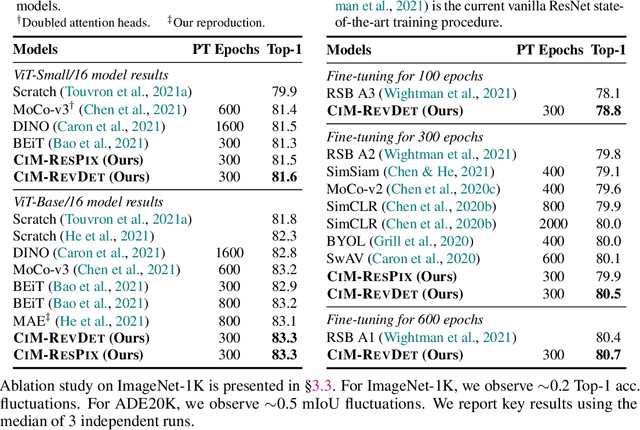

We introduce Corrupted Image Modeling (CIM) for self-supervised visual pre-training. CIM uses an auxiliary generator with a small trainable BEiT to corrupt the input image instead of using artificial mask tokens, where some patches are randomly selected and replaced with plausible alternatives sampled from the BEiT output distribution. Given this corrupted image, an enhancer network learns to either recover all the original image pixels, or predict whether each visual token is replaced by a generator sample or not. The generator and the enhancer are simultaneously trained and synergistically updated. After pre-training, the enhancer can be used as a high-capacity visual encoder for downstream tasks. CIM is a general and flexible visual pre-training framework that is suitable for various network architectures. For the first time, CIM demonstrates that both ViT and CNN can learn rich visual representations using a unified, non-Siamese framework. Experimental results show that our approach achieves compelling results in vision benchmarks, such as ImageNet classification and ADE20K semantic segmentation. For example, 300-epoch CIM pre-trained vanilla ViT-Base/16 and ResNet-50 obtain 83.3 and 80.6 Top-1 fine-tuning accuracy on ImageNet-1K image classification respectively.
Online Learning in Periodic Zero-Sum Games
Nov 05, 2021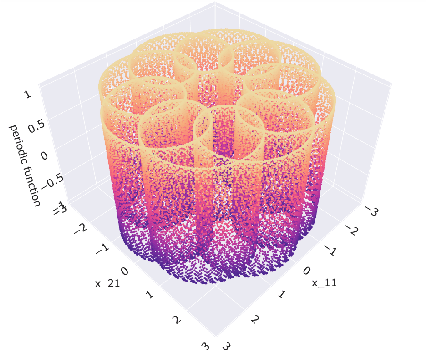
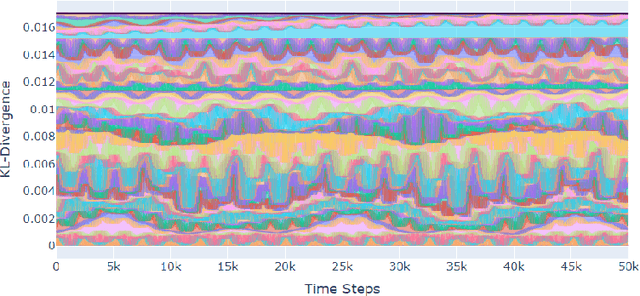

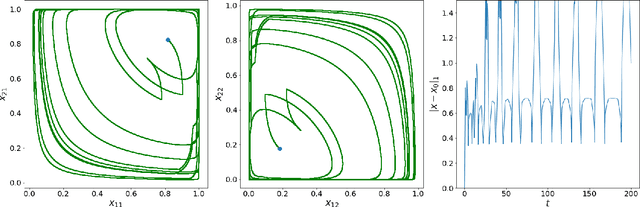
A seminal result in game theory is von Neumann's minmax theorem, which states that zero-sum games admit an essentially unique equilibrium solution. Classical learning results build on this theorem to show that online no-regret dynamics converge to an equilibrium in a time-average sense in zero-sum games. In the past several years, a key research direction has focused on characterizing the day-to-day behavior of such dynamics. General results in this direction show that broad classes of online learning dynamics are cyclic, and formally Poincar\'{e} recurrent, in zero-sum games. We analyze the robustness of these online learning behaviors in the case of periodic zero-sum games with a time-invariant equilibrium. This model generalizes the usual repeated game formulation while also being a realistic and natural model of a repeated competition between players that depends on exogenous environmental variations such as time-of-day effects, week-to-week trends, and seasonality. Interestingly, time-average convergence may fail even in the simplest such settings, in spite of the equilibrium being fixed. In contrast, using novel analysis methods, we show that Poincar\'{e} recurrence provably generalizes despite the complex, non-autonomous nature of these dynamical systems.