 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuild on Priors: Vision--Language--Guided Neuro-Symbolic Imitation Learning for Data-Efficient Real-World Robot Manipulation
Apr 04, 2026Enabling robots to learn long-horizon manipulation tasks from a handful of demonstrations remains a central challenge in robotics. Existing neuro-symbolic approaches often rely on hand-crafted symbolic abstractions, semantically labeled trajectories or large demonstration datasets, limiting their scalability and real-world applicability. We present a scalable neuro-symbolic framework that autonomously constructs symbolic planning domains and data-efficient control policies from as few as one to thirty unannotated skill demonstrations, without requiring manual domain engineering. Our method segments demonstrations into skills and employs a Vision-Language Model (VLM) to classify skills and identify equivalent high-level states, enabling automatic construction of a state-transition graph. This graph is processed by an Answer Set Programming solver to synthesize a PDDL planning domain, which an oracle function exploits to isolate the minimal, task-relevant and target relative observation and action spaces for each skill policy. Policies are learned at the control reference level rather than at the raw actuator signal level, yielding a smoother and less noisy learning target. Known controllers can be leveraged for real-world data augmentation by projecting a single demonstration onto other objects in the scene, simultaneously enriching the graph construction process and the dataset for imitation learning. We validate our framework primarily on a real industrial forklift across statistically rigorous manipulation trials, and demonstrate cross-platform generality on a Kinova Gen3 robotic arm across two standard benchmarks. Our results show that grounding control learning, VLM-driven abstraction, and automated planning synthesis into a unified pipeline constitutes a practical path toward scalable, data-efficient, expert-free and interpretable neuro-symbolic robotics.
Can LLM-Reasoning Models Replace Classical Planning? A Benchmark Study
Jul 31, 2025Recent advancements in Large Language Models have sparked interest in their potential for robotic task planning. While these models demonstrate strong generative capabilities, their effectiveness in producing structured and executable plans remains uncertain. This paper presents a systematic evaluation of a broad spectrum of current state of the art language models, each directly prompted using Planning Domain Definition Language domain and problem files, and compares their planning performance with the Fast Downward planner across a variety of benchmarks. In addition to measuring success rates, we assess how faithfully the generated plans translate into sequences of actions that can actually be executed, identifying both strengths and limitations of using these models in this setting. Our findings show that while the models perform well on simpler planning tasks, they continue to struggle with more complex scenarios that require precise resource management, consistent state tracking, and strict constraint compliance. These results underscore fundamental challenges in applying language models to robotic planning in real world environments. By outlining the gaps that emerge during execution, we aim to guide future research toward combined approaches that integrate language models with classical planners in order to enhance the reliability and scalability of planning in autonomous robotics.
Health Index Estimation Through Integration of General Knowledge with Unsupervised Learning
May 08, 2024



Accurately estimating a Health Index (HI) from condition monitoring data (CM) is essential for reliable and interpretable prognostics and health management (PHM) in complex systems. In most scenarios, complex systems operate under varying operating conditions and can exhibit different fault modes, making unsupervised inference of an HI from CM data a significant challenge. Hybrid models combining prior knowledge about degradation with deep learning models have been proposed to overcome this challenge. However, previously suggested hybrid models for HI estimation usually rely heavily on system-specific information, limiting their transferability to other systems. In this work, we propose an unsupervised hybrid method for HI estimation that integrates general knowledge about degradation into the convolutional autoencoder's model architecture and learning algorithm, enhancing its applicability across various systems. The effectiveness of the proposed method is demonstrated in two case studies from different domains: turbofan engines and lithium batteries. The results show that the proposed method outperforms other competitive alternatives, including residual-based methods, in terms of HI quality and their utility for Remaining Useful Life (RUL) predictions. The case studies also highlight the comparable performance of our proposed method with a supervised model trained with HI labels.
Real-Time Model Calibration with Deep Reinforcement Learning
Jun 09, 2020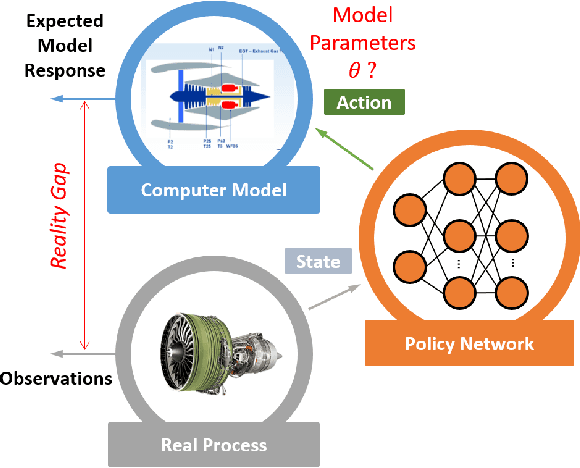
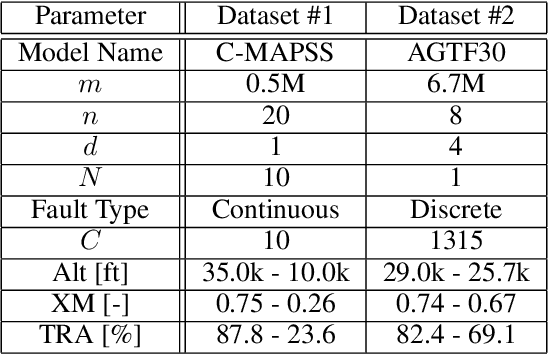
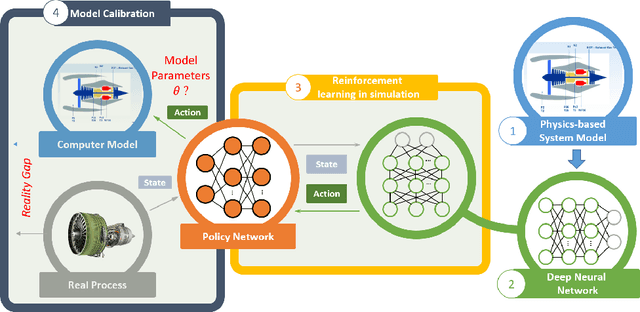
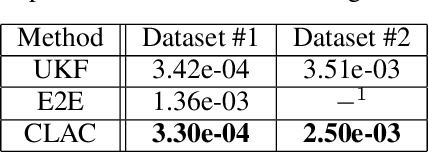
The dynamic, real-time, and accurate inference of model parameters from empirical data is of great importance in many scientific and engineering disciplines that use computational models (such as a digital twin) for the analysis and prediction of complex physical processes. However, fast and accurate inference for processes with large and high dimensional datasets cannot easily be achieved with state-of-the-art methods under noisy real-world conditions. The primary reason is that the inference of model parameters with traditional techniques based on optimisation or sampling often suffers from computational and statistical challenges, resulting in a trade-off between accuracy and deployment time. In this paper, we propose a novel framework for inference of model parameters based on reinforcement learning. The contribution of the paper is twofold: 1) We reformulate the inference problem as a tracking problem with the objective of learning a policy that forces the response of the physics-based model to follow the observations; 2) We propose the constrained Lyapunov-based actor-critic (CLAC) algorithm to enable the robust and accurate inference of physics-based model parameters in real time under noisy real-world conditions. The proposed methodology is demonstrated and evaluated on two model-based diagnostics test cases utilizing two different physics-based models of turbofan engines. The performance of the methodology is compared to that of two alternative approaches: a state update method (unscented Kalman filter) and a supervised end-to-end mapping with deep neural networks. The experimental results demonstrate that the proposed methodology outperforms all other tested methods in terms of speed and robustness, with high inference accuracy.