 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVNDUQE: Information-Theoretic Novelty Detection using Deep Variational Information Bottleneck
May 12, 2026Detecting out-of-distribution (OOD) samples is critical for safe deployment of neural networks in safety-critical applications. While maximum softmax probability (MSP) provides a simple baseline, it lacks theoretical grounding and suffers from miscalibration. We propose VNDUQE (VIB-based Novelty Detection and Uncertainty Quantification for Nondestructive Evaluation), which investigates novelty detection through the Deep Variational Information Bottleneck (VIB), which explicitly constrains information flow through learned representations. We train VIB models on MNIST with held-out digit classes and evaluate OOD detection using information-theoretic metrics: KL divergence and prediction entropy. Our results reveal complementary detection signals: KL divergence achieves perfect detection (100\% AUROC on noise) on far-OOD samples (noise, domain shift), while prediction entropy excels at near-OOD detection (94.7\% AUROC on novel digit classes). A parallel detection strategy combining both metrics achieves 95.3\% average AUROC and 92\% true positive rate at 5\% false positive rate, which is a 32 percentage point improvement over baseline MSP (85.0\% AUROC, 60.1\% TPR). Compression via the information bottleneck principle ($β=10^{-3}$) reduces Expected Calibration Error by 38\%, demonstrating that information-theoretic constraints produce fundamentally more reliable uncertainty estimates. These findings directly support active learning with expensive computational oracles, where well-calibrated novelty detection enables principled threshold selection for oracle queries.
MUSDA: Multi-source Multi-modality Unsupervised Domain Adaptive 3D Object Detection for Autonomous Driving
May 11, 2026With the advancement of autonomous driving, numerous annotated multi-modality datasets have become available. This presents an opportunity to develop domain-adaptive 3D object detectors for new environments without relying on labor-intensive manual annotations. However, traditional domain adaptation methods typically focus on a single source domain or a single modality, limiting their effectiveness in multi-source, multi-modality scenarios. In this paper, we propose a novel framework for multi-source, multi-modality unsupervised domain adaptation in 3D object detection for autonomous driving. Given multiple labeled source domains and one unlabeled target domain, our framework first introduces hierarchical spatially-conditioned (HSC) domain classifiers, which jointly align features from both camera and LiDAR modalities at two distinct levels for each source-target domain pair. To effectively leverage information from multiple source domains, we construct a prototype graph between each pair of domains. Based on this, we develop a prototype graph weighted (PGW) multi-source fusion strategy to aggregate predictions from multiple source detection heads. Experimental results on three widely used 3D object detection datasets - Waymo, nuScenes, and Lyft - demonstrate that our proposed framework effectively integrates information across both modalities and source domains, consistently outperforming state-of-the-art methods.
DALI: Domain Adaptive LiDAR Object Detection via Distribution-level and Instance-level Pseudo Label Denoising
Dec 11, 2024



Object detection using LiDAR point clouds relies on a large amount of human-annotated samples when training the underlying detectors' deep neural networks. However, generating 3D bounding box annotation for a large-scale dataset could be costly and time-consuming. Alternatively, unsupervised domain adaptation (UDA) enables a given object detector to operate on a novel new data, with unlabeled training dataset, by transferring the knowledge learned from training labeled \textit{source domain} data to the new unlabeled \textit{target domain}. Pseudo label strategies, which involve training the 3D object detector using target-domain predicted bounding boxes from a pre-trained model, are commonly used in UDA. However, these pseudo labels often introduce noise, impacting performance. In this paper, we introduce the Domain Adaptive LIdar (DALI) object detection framework to address noise at both distribution and instance levels. Firstly, a post-training size normalization (PTSN) strategy is developed to mitigate bias in pseudo label size distribution by identifying an unbiased scale after network training. To address instance-level noise between pseudo labels and corresponding point clouds, two pseudo point clouds generation (PPCG) strategies, ray-constrained and constraint-free, are developed to generate pseudo point clouds for each instance, ensuring the consistency between pseudo labels and pseudo points during training. We demonstrate the effectiveness of our method on the publicly available and popular datasets KITTI, Waymo, and nuScenes. We show that the proposed DALI framework achieves state-of-the-art results and outperforms leading approaches on most of the domain adaptation tasks. Our code is available at \href{https://github.com/xiaohulugo/T-RO2024-DALI}{https://github.com/xiaohulugo/T-RO2024-DALI}.
Optical Lens Attack on Monocular Depth Estimation for Autonomous Driving
Oct 31, 2024



Monocular Depth Estimation (MDE) is a pivotal component of vision-based Autonomous Driving (AD) systems, enabling vehicles to estimate the depth of surrounding objects using a single camera image. This estimation guides essential driving decisions, such as braking before an obstacle or changing lanes to avoid collisions. In this paper, we explore vulnerabilities of MDE algorithms in AD systems, presenting LensAttack, a novel physical attack that strategically places optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We first develop a mathematical model that outlines the parameters of the attack, followed by simulations and real-world evaluations to assess its efficacy on state-of-the-art MDE models. Additionally, we adopt an attack optimization method to further enhance the attack success rate by optimizing the attack focal length. To better evaluate the implications of LensAttack on AD, we conduct comprehensive end-to-end system simulations using the CARLA platform. The results reveal that LensAttack can significantly disrupt the depth estimation processes in AD systems, posing a serious threat to their reliability and safety. Finally, we discuss some potential defense methods to mitigate the effects of the proposed attack.
Optical Lens Attack on Deep Learning Based Monocular Depth Estimation
Sep 25, 2024



Monocular Depth Estimation (MDE) plays a crucial role in vision-based Autonomous Driving (AD) systems. It utilizes a single-camera image to determine the depth of objects, facilitating driving decisions such as braking a few meters in front of a detected obstacle or changing lanes to avoid collision. In this paper, we investigate the security risks associated with monocular vision-based depth estimation algorithms utilized by AD systems. By exploiting the vulnerabilities of MDE and the principles of optical lenses, we introduce LensAttack, a physical attack that involves strategically placing optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We begin by constructing a mathematical model of our attack, incorporating various attack parameters. Subsequently, we simulate the attack and evaluate its real-world performance in driving scenarios to demonstrate its effect on state-of-the-art MDE models. The results highlight the significant impact of LensAttack on the accuracy of depth estimation in AD systems.
ScAR: Scaling Adversarial Robustness for LiDAR Object Detection
Dec 05, 2023The adversarial robustness of a model is its ability to resist adversarial attacks in the form of small perturbations to input data. Universal adversarial attack methods such as Fast Sign Gradient Method (FSGM) and Projected Gradient Descend (PGD) are popular for LiDAR object detection, but they are often deficient compared to task-specific adversarial attacks. Additionally, these universal methods typically require unrestricted access to the model's information, which is difficult to obtain in real-world applications. To address these limitations, we present a black-box Scaling Adversarial Robustness (ScAR) method for LiDAR object detection. By analyzing the statistical characteristics of 3D object detection datasets such as KITTI, Waymo, and nuScenes, we have found that the model's prediction is sensitive to scaling of 3D instances. We propose three black-box scaling adversarial attack methods based on the available information: model-aware attack, distribution-aware attack, and blind attack. We also introduce a strategy for generating scaling adversarial examples to improve the model's robustness against these three scaling adversarial attacks. Comparison with other methods on public datasets under different 3D object detection architectures demonstrates the effectiveness of our proposed method.
Strong-Weak Integrated Semi-supervision for Unsupervised Single and Multi Target Domain Adaptation
Sep 12, 2023



Unsupervised domain adaptation (UDA) focuses on transferring knowledge learned in the labeled source domain to the unlabeled target domain. Despite significant progress that has been achieved in single-target domain adaptation for image classification in recent years, the extension from single-target to multi-target domain adaptation is still a largely unexplored problem area. In general, unsupervised domain adaptation faces a major challenge when attempting to learn reliable information from a single unlabeled target domain. Increasing the number of unlabeled target domains further exacerbate the problem rather significantly. In this paper, we propose a novel strong-weak integrated semi-supervision (SWISS) learning strategy for image classification using unsupervised domain adaptation that works well for both single-target and multi-target scenarios. Under the proposed SWISS-UDA framework, a strong representative set with high confidence but low diversity target domain samples and a weak representative set with low confidence but high diversity target domain samples are updated constantly during the training process. Both sets are fused to generate an augmented strong-weak training batch with pseudo-labels to train the network during every iteration. The extension from single-target to multi-target domain adaptation is accomplished by exploring the class-wise distance relationship between domains and replacing the strong representative set with much stronger samples from peer domains via peer scaffolding. Moreover, a novel adversarial logit loss is proposed to reduce the intra-class divergence between source and target domains, which is back-propagated adversarially with a gradient reverse layer between the classifier and the rest of the network. Experimental results based on three benchmarks, Office-31, Office-Home, and DomainNet, show the effectiveness of the proposed SWISS framework.
TransCAR: Transformer-based Camera-And-Radar Fusion for 3D Object Detection
Apr 30, 2023Despite radar's popularity in the automotive industry, for fusion-based 3D object detection, most existing works focus on LiDAR and camera fusion. In this paper, we propose TransCAR, a Transformer-based Camera-And-Radar fusion solution for 3D object detection. Our TransCAR consists of two modules. The first module learns 2D features from surround-view camera images and then uses a sparse set of 3D object queries to index into these 2D features. The vision-updated queries then interact with each other via transformer self-attention layer. The second module learns radar features from multiple radar scans and then applies transformer decoder to learn the interactions between radar features and vision-updated queries. The cross-attention layer within the transformer decoder can adaptively learn the soft-association between the radar features and vision-updated queries instead of hard-association based on sensor calibration only. Finally, our model estimates a bounding box per query using set-to-set Hungarian loss, which enables the method to avoid non-maximum suppression. TransCAR improves the velocity estimation using the radar scans without temporal information. The superior experimental results of our TransCAR on the challenging nuScenes datasets illustrate that our TransCAR outperforms state-of-the-art Camera-Radar fusion-based 3D object detection approaches.
Integrated Multiscale Domain Adaptive YOLO
Feb 10, 2022
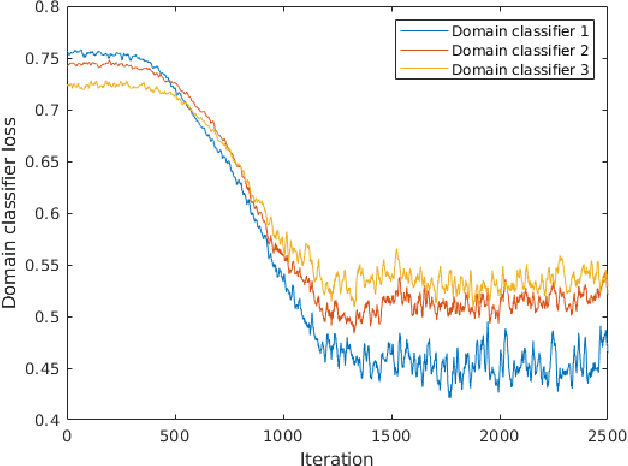
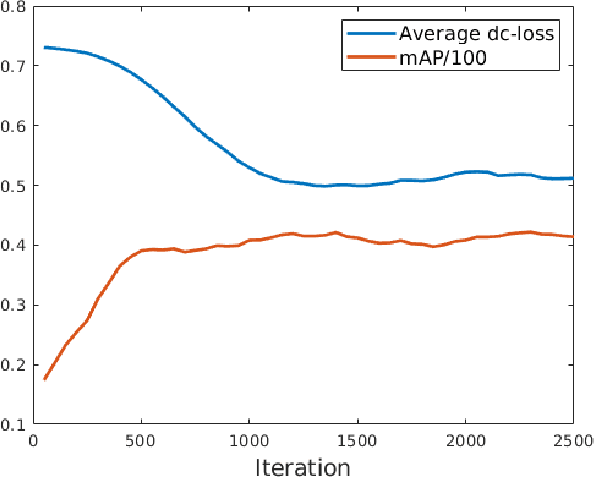
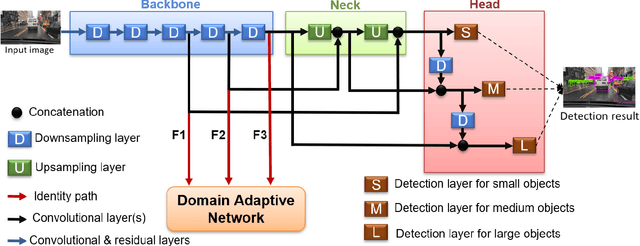
The area of domain adaptation has been instrumental in addressing the domain shift problem encountered by many applications. This problem arises due to the difference between the distributions of source data used for training in comparison with target data used during realistic testing scenarios. In this paper, we introduce a novel MultiScale Domain Adaptive YOLO (MS-DAYOLO) framework that employs multiple domain adaptation paths and corresponding domain classifiers at different scales of the recently introduced YOLOv4 object detector. Building on our baseline multiscale DAYOLO framework, we introduce three novel deep learning architectures for a Domain Adaptation Network (DAN) that generates domain-invariant features. In particular, we propose a Progressive Feature Reduction (PFR), a Unified Classifier (UC), and an Integrated architecture. We train and test our proposed DAN architectures in conjunction with YOLOv4 using popular datasets. Our experiments show significant improvements in object detection performance when training YOLOv4 using the proposed MS-DAYOLO architectures and when tested on target data for autonomous driving applications. Moreover, MS-DAYOLO framework achieves an order of magnitude real-time speed improvement relative to Faster R-CNN solutions while providing comparable object detection performance.
Multiscale Domain Adaptive YOLO for Cross-Domain Object Detection
Jun 02, 2021
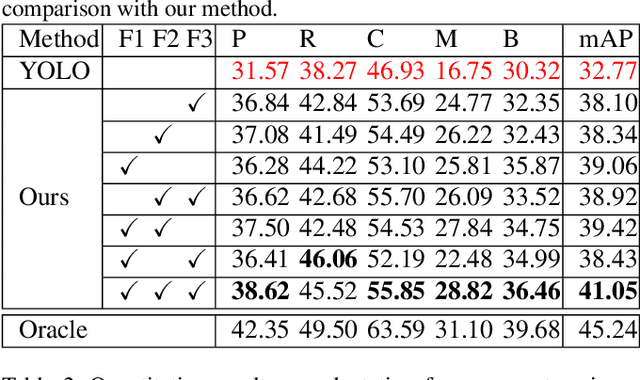
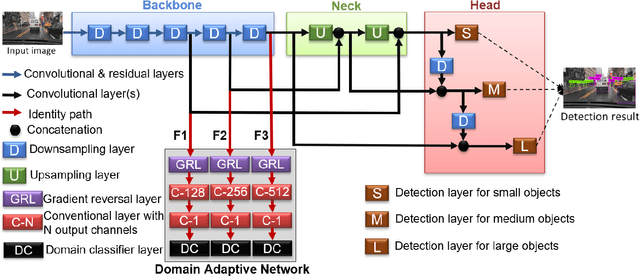
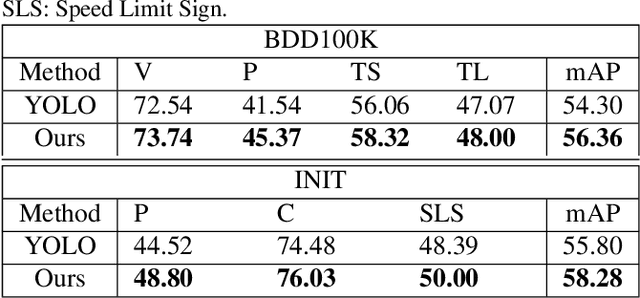
The area of domain adaptation has been instrumental in addressing the domain shift problem encountered by many applications. This problem arises due to the difference between the distributions of source data used for training in comparison with target data used during realistic testing scenarios. In this paper, we introduce a novel MultiScale Domain Adaptive YOLO (MS-DAYOLO) framework that employs multiple domain adaptation paths and corresponding domain classifiers at different scales of the recently introduced YOLOv4 object detector to generate domain-invariant features. We train and test our proposed method using popular datasets. Our experiments show significant improvements in object detection performance when training YOLOv4 using the proposed MS-DAYOLO and when tested on target data representing challenging weather conditions for autonomous driving applications.