 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rejection of Smooth GPS Time Synchronization Attacks via Sparse Techniques
Feb 28, 2021
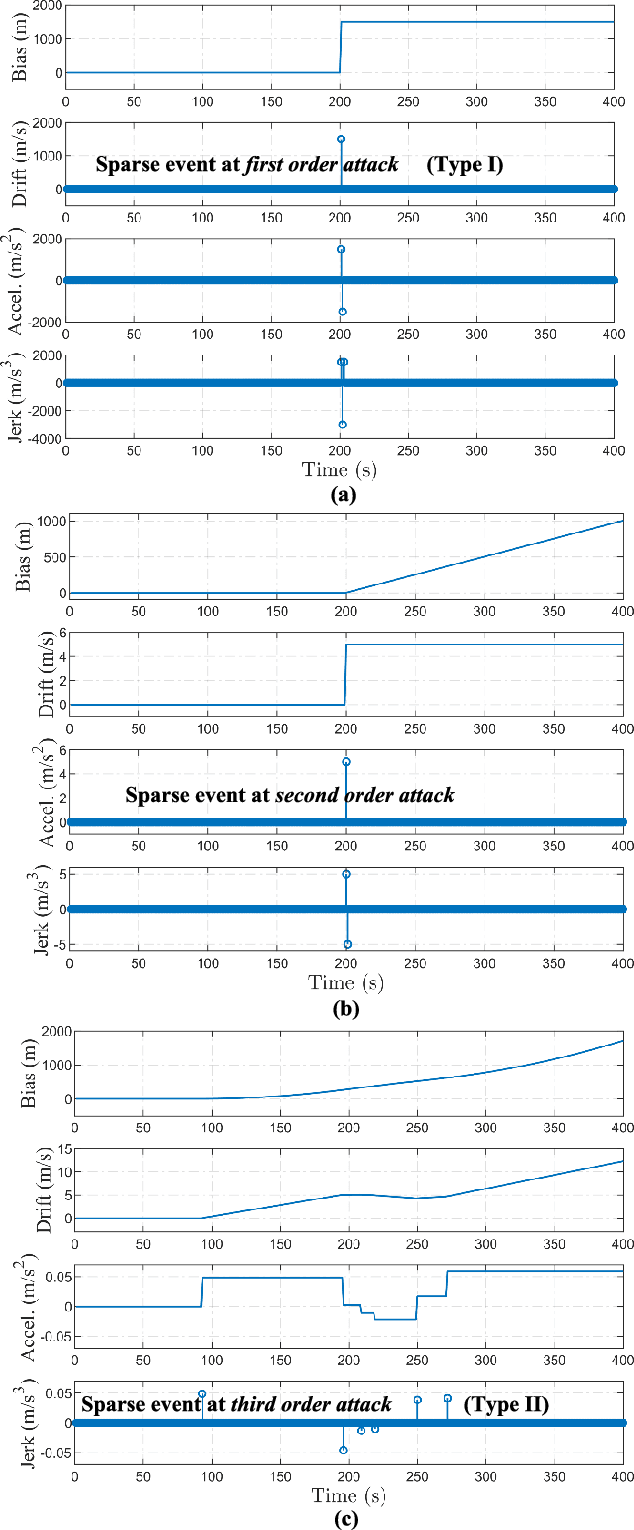
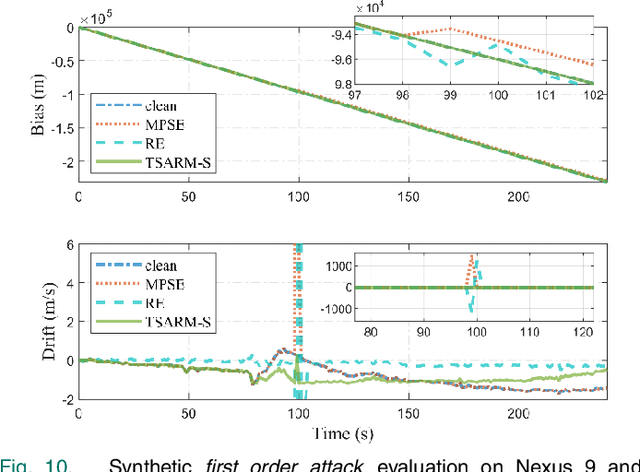
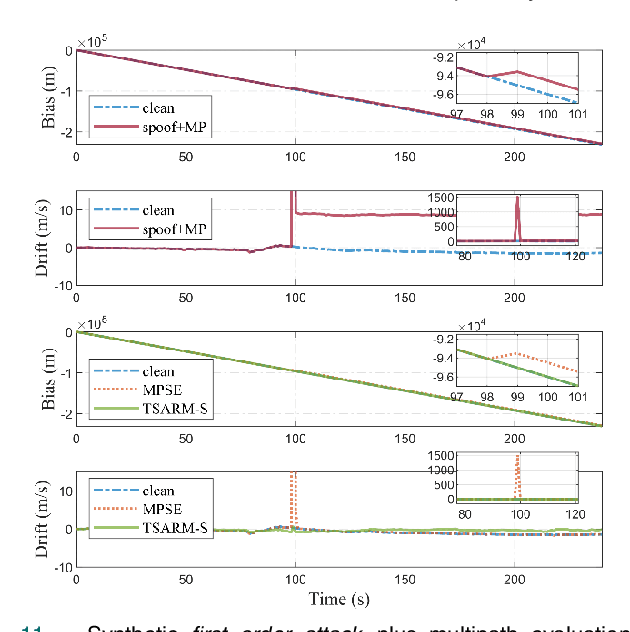
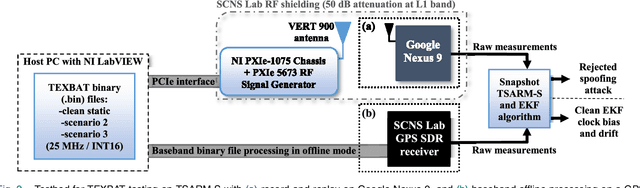
This paper presents a novel time synchronization attack (TSA) model for the Global Positioning System (GPS) based on clock data behavior changes in a higher-order derivative domain. Further, the time synchronization attack rejection and mitigation based on sparse domain (TSARM-S) is presented. TSAs affect stationary GPS receivers in applications where precise timing is required, such as cellular communications, financial transactions, and monitoring of the electric power grid. In the present work, the clock bias and clock drift are monitored at higher-order clock data derivatives where the TSA is seen as a sparse spike-like event. The smoothness of the attack relates to the derivative order where the sparsity is observed. The proposed method jointly estimates a dynamic solution for GPS timing and rejects behavior changes based on such sparse events. An evaluation procedure is presented for two testbeds, namely a commercial receiver and a software-defined radio. Further, the proposed method is evaluated against distinct real-dataset Texas Spoofing Test Battery (TEXBAT) scenarios. Combined synthetic and real-data results show an average RMS clock bias error of 12.08 m for the SDR platform, and 45.74 m for the commercial device. Further, the technique is evaluated against state-of-the-art mitigation techniques and in a spoofing-plus-multipath scenario for robustness. Finally, TSARM-S can be potentially optimized and implemented in commercial devices via a firmware upgrade.
* IEEE Sensors Journal ( Volume: 21, Issue: 1, Jan.1, 1 2021)
Dimensionality Reduction in Deep Learning via Kronecker Multi-layer Architectures
Apr 08, 2022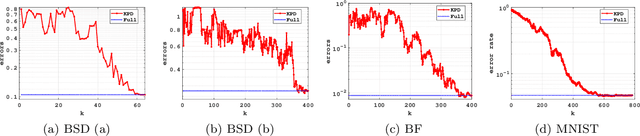

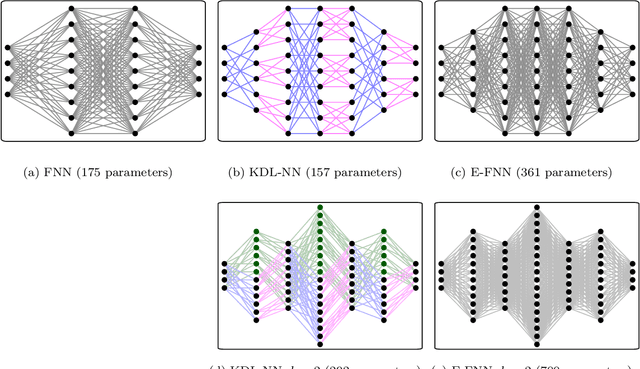
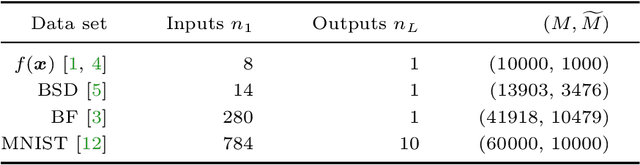
Deep learning using neural networks is an effective technique for generating models of complex data. However, training such models can be expensive when networks have large model capacity resulting from a large number of layers and nodes. For training in such a computationally prohibitive regime, dimensionality reduction techniques ease the computational burden, and allow implementations of more robust networks. We propose a novel type of such dimensionality reduction via a new deep learning architecture based on fast matrix multiplication of a Kronecker product decomposition; in particular our network construction can be viewed as a Kronecker product-induced sparsification of an "extended" fully connected network. Analysis and practical examples show that this architecture allows a neural network to be trained and implemented with a significant reduction in computational time and resources, while achieving a similar error level compared to a traditional feedforward neural network.
Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain
Mar 31, 2022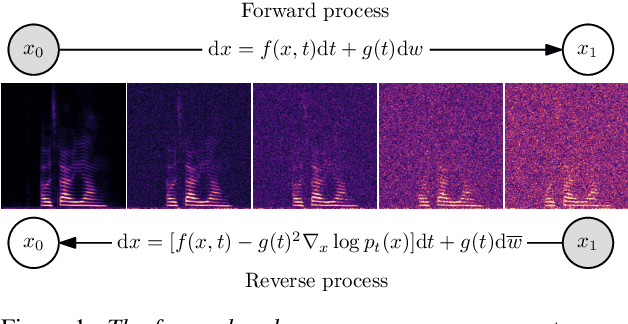
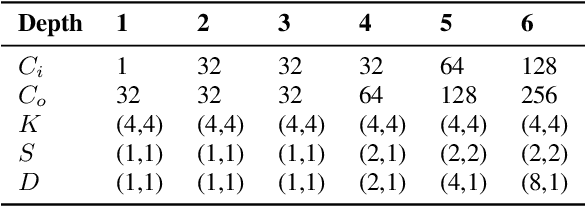
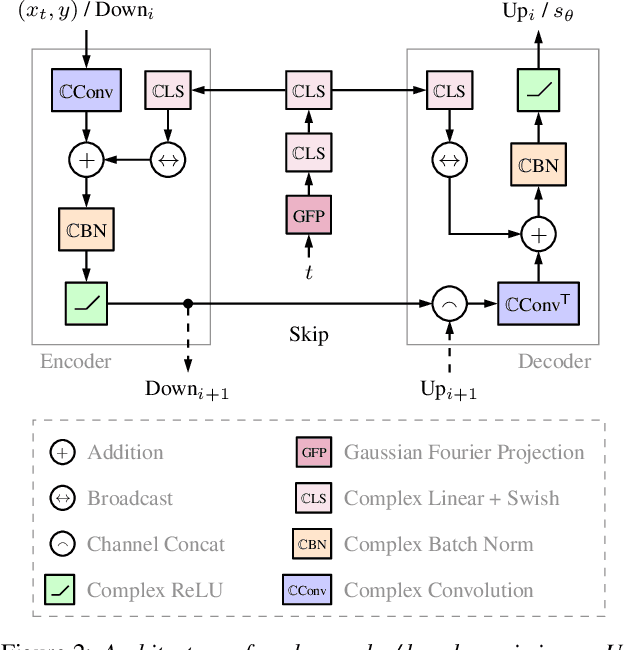
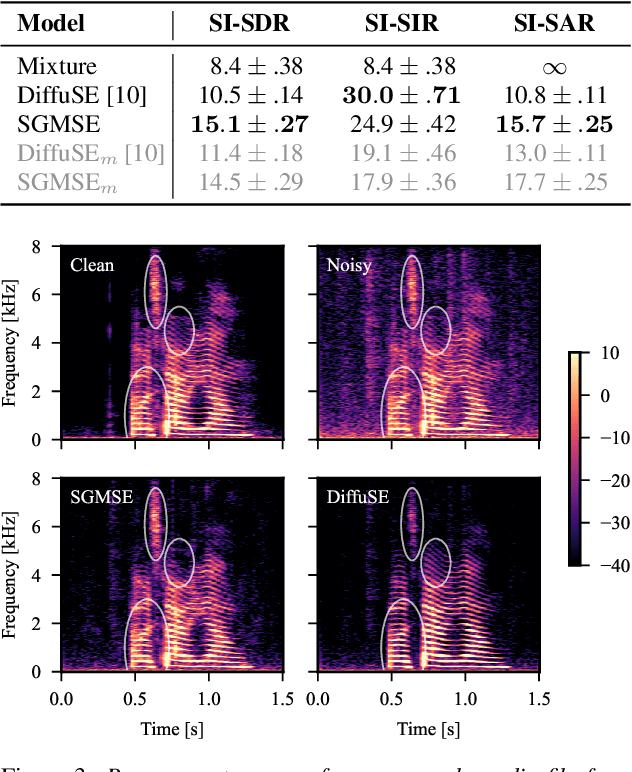
Score-based generative models (SGMs) have recently shown impressive results for difficult generative tasks such as the unconditional and conditional generation of natural images and audio signals. In this work, we extend these models to the complex short-time Fourier transform (STFT) domain, proposing a novel training task for speech enhancement using a complex-valued deep neural network. We derive this training task within the formalism of stochastic differential equations, thereby enabling the use of predictor-corrector samplers. We provide alternative formulations inspired by previous publications on using SGMs for speech enhancement, avoiding the need for any prior assumptions on the noise distribution and making the training task purely generative which, as we show, results in improved enhancement performance.
Neural Jacobian Fields: Learning Intrinsic Mappings of Arbitrary Meshes
May 05, 2022
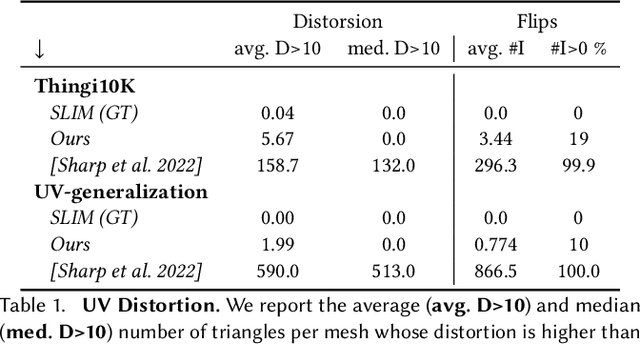

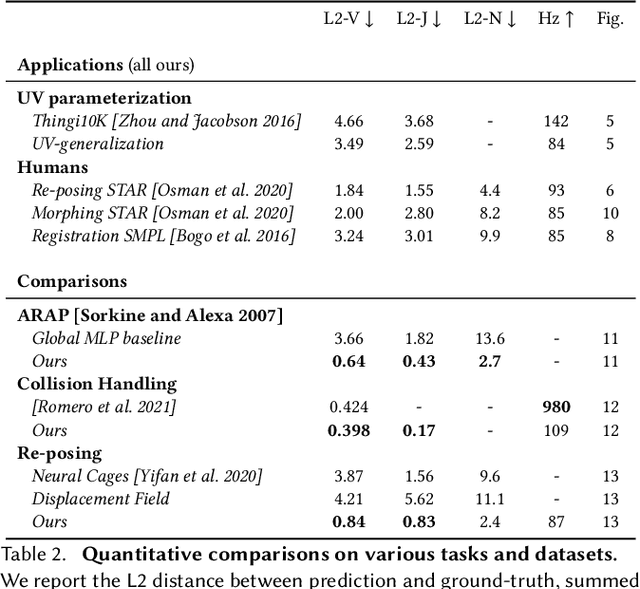
This paper introduces a framework designed to accurately predict piecewise linear mappings of arbitrary meshes via a neural network, enabling training and evaluating over heterogeneous collections of meshes that do not share a triangulation, as well as producing highly detail-preserving maps whose accuracy exceeds current state of the art. The framework is based on reducing the neural aspect to a prediction of a matrix for a single given point, conditioned on a global shape descriptor. The field of matrices is then projected onto the tangent bundle of the given mesh, and used as candidate jacobians for the predicted map. The map is computed by a standard Poisson solve, implemented as a differentiable layer with cached pre-factorization for efficient training. This construction is agnostic to the triangulation of the input, thereby enabling applications on datasets with varying triangulations. At the same time, by operating in the intrinsic gradient domain of each individual mesh, it allows the framework to predict highly-accurate mappings. We validate these properties by conducting experiments over a broad range of scenarios, from semantic ones such as morphing, registration, and deformation transfer, to optimization-based ones, such as emulating elastic deformations and contact correction, as well as being the first work, to our knowledge, to tackle the task of learning to compute UV parameterizations of arbitrary meshes. The results exhibit the high accuracy of the method as well as its versatility, as it is readily applied to the above scenarios without any changes to the framework.
To Fold or Not to Fold: a Necessary and Sufficient Condition on Batch-Normalization Layers Folding
Mar 28, 2022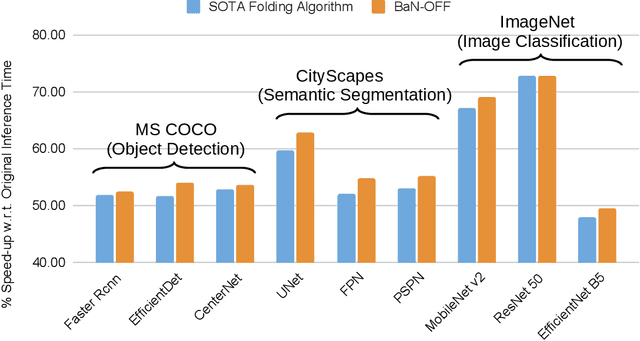
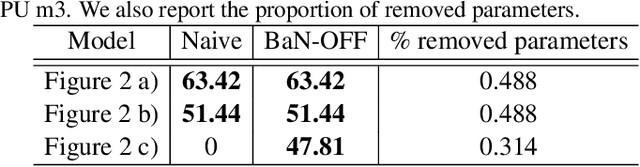
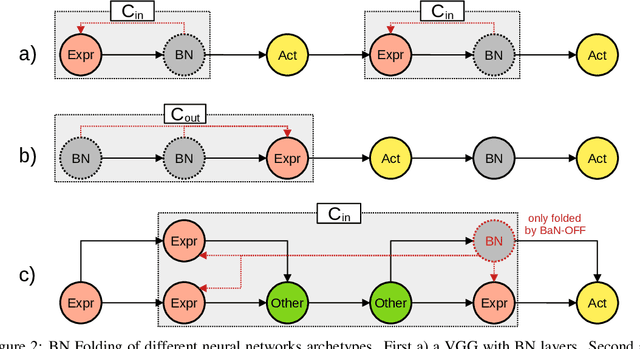
Batch-Normalization (BN) layers have become fundamental components in the evermore complex deep neural network architectures. Such models require acceleration processes for deployment on edge devices. However, BN layers add computation bottlenecks due to the sequential operation processing: thus, a key, yet often overlooked component of the acceleration process is BN layers folding. In this paper, we demonstrate that the current BN folding approaches are suboptimal in terms of how many layers can be removed. We therefore provide a necessary and sufficient condition for BN folding and a corresponding optimal algorithm. The proposed approach systematically outperforms existing baselines and allows to dramatically reduce the inference time of deep neural networks.
Temporal Modulation Network for Controllable Space-Time Video Super-Resolution
Apr 21, 2021
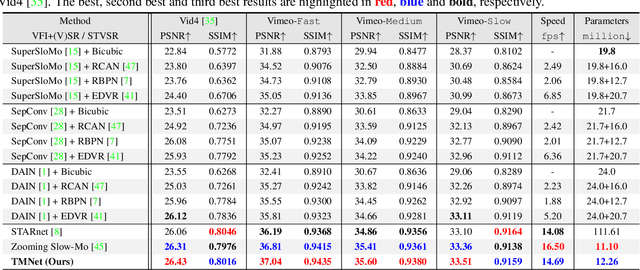
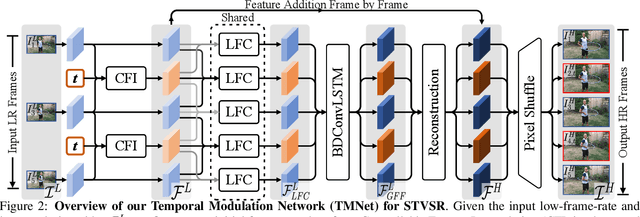
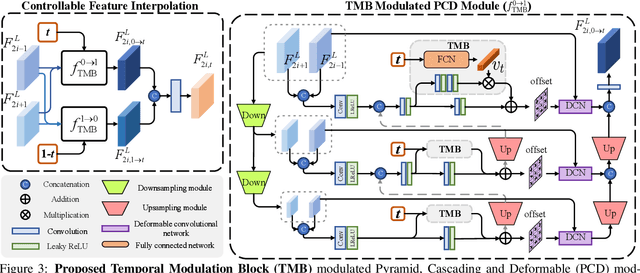
Space-time video super-resolution (STVSR) aims to increase the spatial and temporal resolutions of low-resolution and low-frame-rate videos. Recently, deformable convolution based methods have achieved promising STVSR performance, but they could only infer the intermediate frame pre-defined in the training stage. Besides, these methods undervalued the short-term motion cues among adjacent frames. In this paper, we propose a Temporal Modulation Network (TMNet) to interpolate arbitrary intermediate frame(s) with accurate high-resolution reconstruction. Specifically, we propose a Temporal Modulation Block (TMB) to modulate deformable convolution kernels for controllable feature interpolation. To well exploit the temporal information, we propose a Locally-temporal Feature Comparison (LFC) module, along with the Bi-directional Deformable ConvLSTM, to extract short-term and long-term motion cues in videos. Experiments on three benchmark datasets demonstrate that our TMNet outperforms previous STVSR methods. The code is available at https://github.com/CS-GangXu/TMNet.
Flowformer: Linearizing Transformers with Conservation Flows
Feb 13, 2022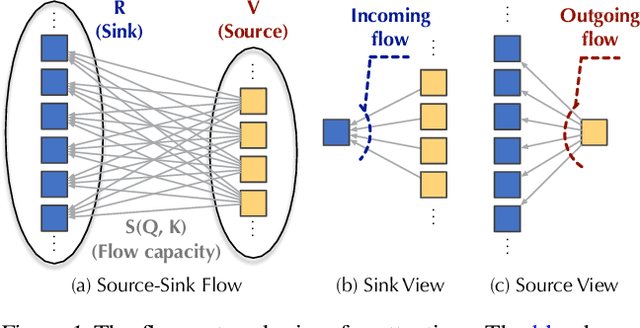
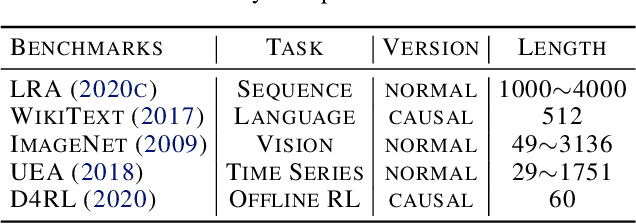
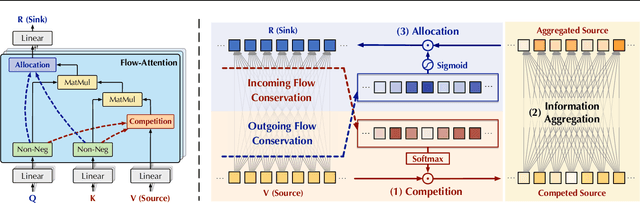
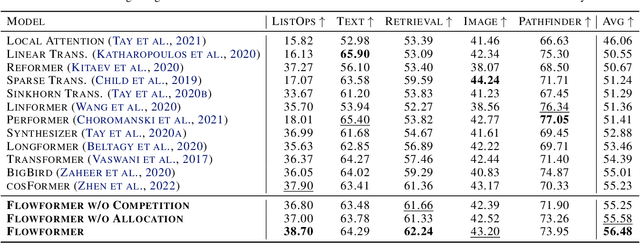
Transformers based on the attention mechanism have achieved impressive success in various areas. However, the attention mechanism has a quadratic complexity, significantly impeding Transformers from dealing with numerous tokens and scaling up to bigger models. Previous methods mainly utilize the similarity decomposition and the associativity of matrix multiplication to devise linear-time attention mechanisms. They avoid degeneration of attention to a trivial distribution by reintroducing inductive biases such as the locality, thereby at the expense of model generality and expressiveness. In this paper, we linearize Transformers free from specific inductive biases based on the flow network theory. We cast attention as the information flow aggregated from the sources (values) to the sinks (results) through the learned flow capacities (attentions). Within this framework, we apply the property of flow conservation with attention and propose the Flow-Attention mechanism of linear complexity. By respectively conserving the incoming flow of sinks for source competition and the outgoing flow of sources for sink allocation, Flow-Attention inherently generates informative attentions without using specific inductive biases. Empowered by the Flow-Attention, Flowformer yields strong performance in linear time for wide areas, including long sequence, time series, vision, natural language, and reinforcement learning.
Neural Architecture Search for Speech Emotion Recognition
Mar 31, 2022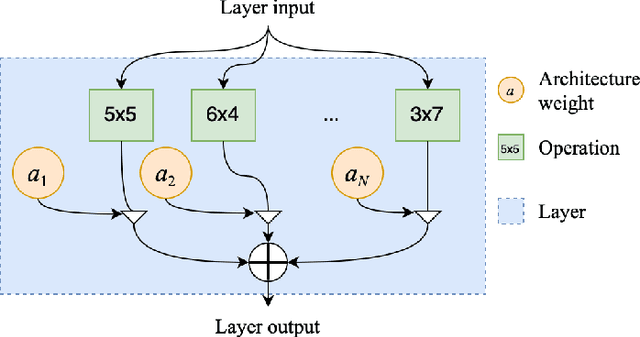
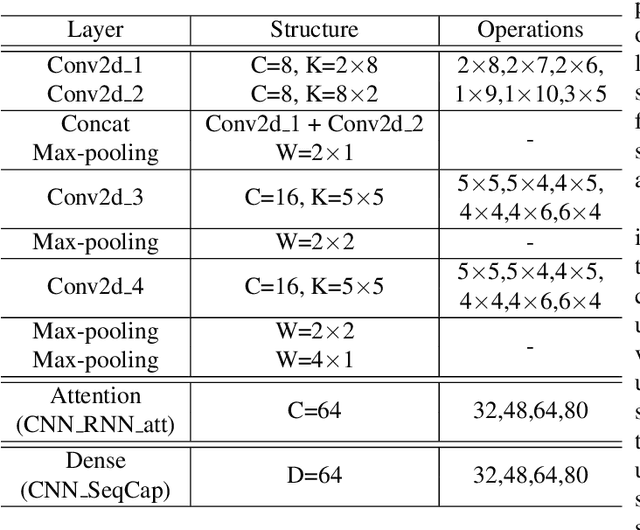
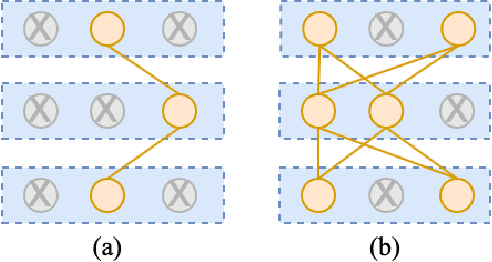
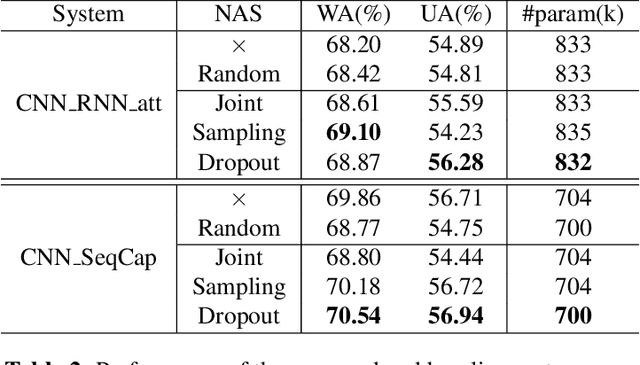
Deep neural networks have brought significant advancements to speech emotion recognition (SER). However, the architecture design in SER is mainly based on expert knowledge and empirical (trial-and-error) evaluations, which is time-consuming and resource intensive. In this paper, we propose to apply neural architecture search (NAS) techniques to automatically configure the SER models. To accelerate the candidate architecture optimization, we propose a uniform path dropout strategy to encourage all candidate architecture operations to be equally optimized. Experimental results of two different neural structures on IEMOCAP show that NAS can improve SER performance (54.89\% to 56.28\%) while maintaining model parameter sizes. The proposed dropout strategy also shows superiority over the previous approaches.
Conformal prediction interval for dynamic time-series
Oct 18, 2020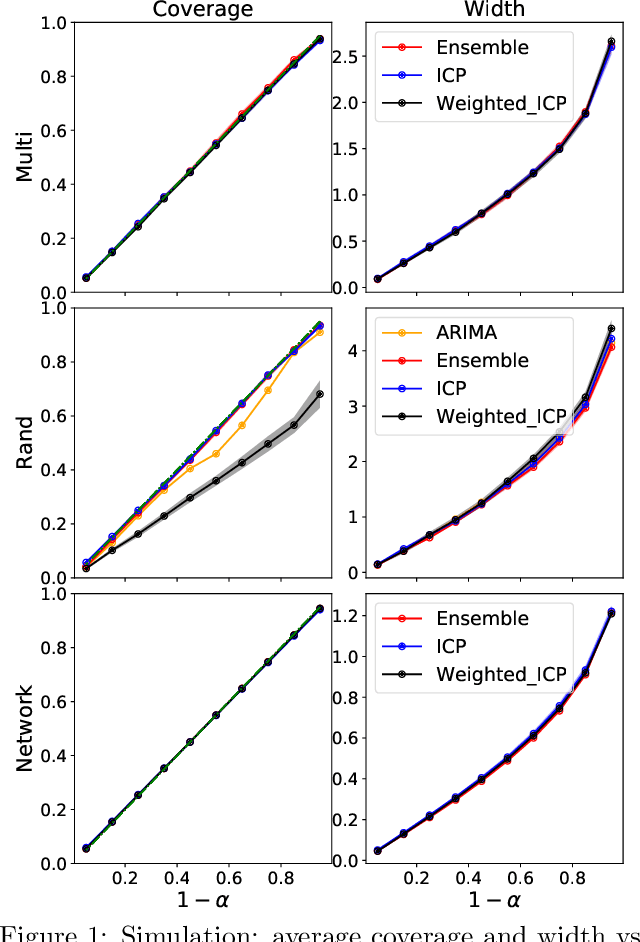
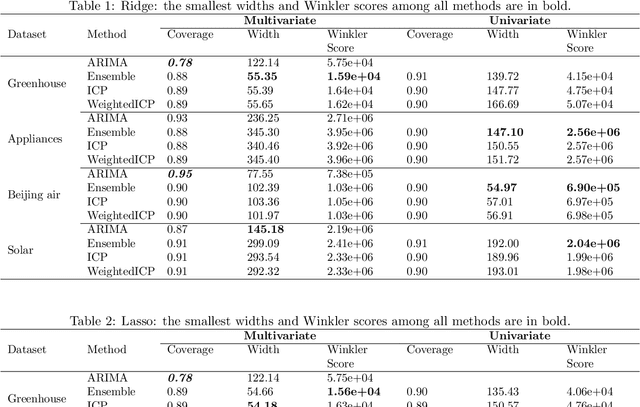
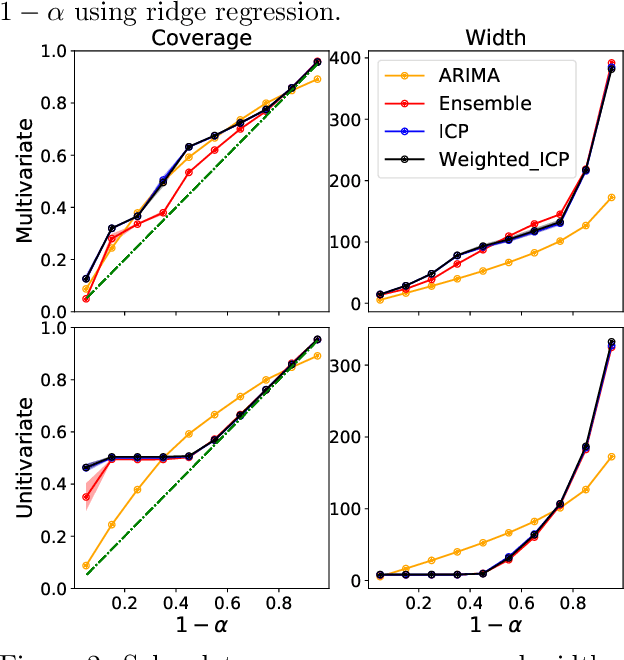
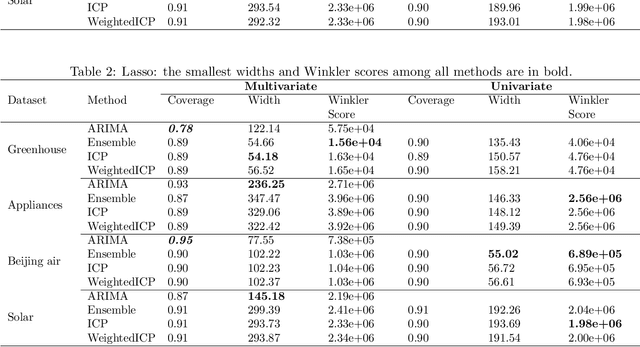
We develop a method to build distribution-free prediction intervals for time-series based on conformal inference, called \Verb|EnPI| that wraps around any ensemble estimator to construct sequential prediction intervals. \Verb|EnPI| is closely related to the conformal prediction (CP) framework but does not require data exchangeability. Theoretically, these intervals attain finite-sample, approximately valid average coverage for broad classes of regression functions and time-series with strongly mixing stochastic errors. Computationally, \Verb|EnPI| requires no training of multiple ensemble estimators; it efficiently operates around an already trained ensemble estimator. In general, \Verb|EnPI| is easy to implement, scalable to producing arbitrarily many prediction intervals sequentially, and well-suited to a wide range of regression functions. We perform extensive simulations and real-data analyses to demonstrate its effectiveness.
Color2Style: Real-Time Exemplar-Based Image Colorization with Self-Reference Learning and Deep Feature Modulation
Jun 16, 2021

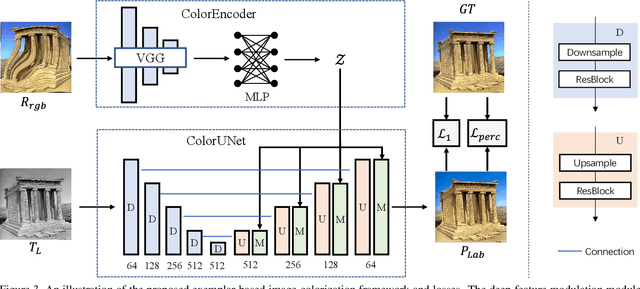
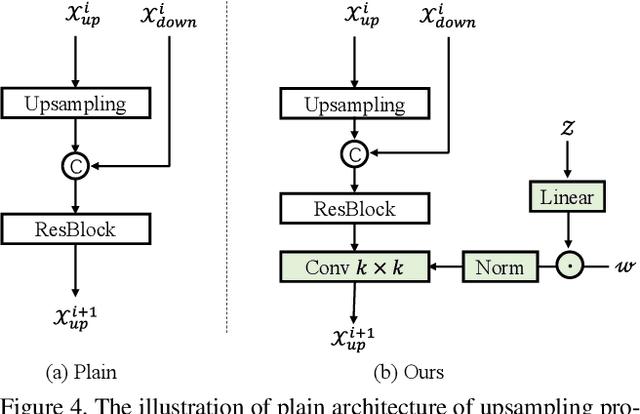
Legacy black-and-white photos are riddled with people's nostalgia and glorious memories of the past. To better relive the elapsed frozen moments, in this paper, we present a deep exemplar-based image colorization approach named Color2Style to resurrect these grayscale image media by filling them with vibrant colors. Generally, for exemplar-based colorization, unsupervised and unpaired training are usually adopted, due to the difficulty of obtaining input and ground truth image pairs. To train an exemplar-based colorization model, current algorithms usually strive to achieve two procedures: i) retrieving a large number of reference images with high similarity in advance, which is inevitably time-consuming and tedious; ii) designing complicated modules to transfer the colors of the reference image to the grayscale image, by calculating and leveraging the deep semantic correspondence between them (e.g., non-local operation). Contrary to the previous methods, we solve and simplify the above two steps in one end-to-end learning procedure. First, we adopt a self-augmented self-reference training scheme, where the reference image is generated by graphical transformations from the original colorful one whereby the training can be formulated in a paired manner. Second, instead of computing complex and inexplicable correspondence maps, our method exploits a simple yet effective deep feature modulation (DFM) module, which injects the color embeddings extracted from the reference image into the deep representations of the input grayscale image. Such design is much more lightweight and intelligible, achieving appealing performance with real-time processing speed. Moreover, our model does not require multifarious loss functions and regularization terms like existing methods, but only two widely used loss functions. Codes and models will be available at https://github.com/zhaohengyuan1/Color2Style.