 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowformer: Linearizing Transformers with Conservation Flows
Feb 13, 2022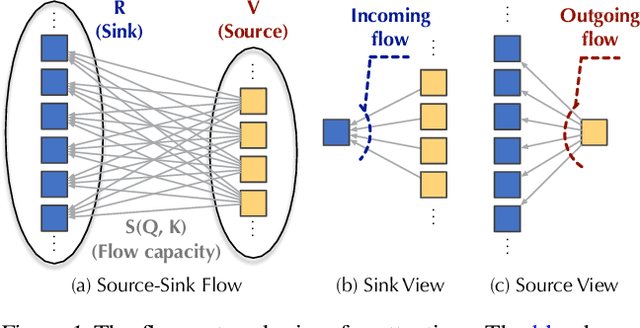
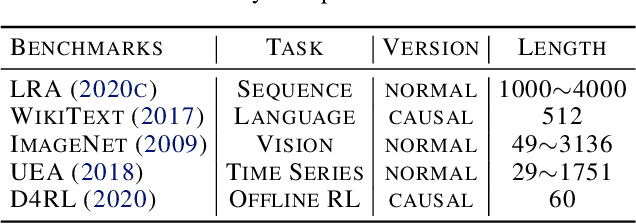
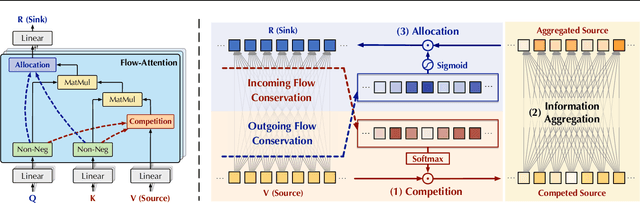
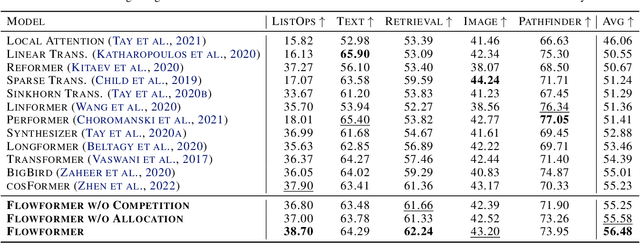
Transformers based on the attention mechanism have achieved impressive success in various areas. However, the attention mechanism has a quadratic complexity, significantly impeding Transformers from dealing with numerous tokens and scaling up to bigger models. Previous methods mainly utilize the similarity decomposition and the associativity of matrix multiplication to devise linear-time attention mechanisms. They avoid degeneration of attention to a trivial distribution by reintroducing inductive biases such as the locality, thereby at the expense of model generality and expressiveness. In this paper, we linearize Transformers free from specific inductive biases based on the flow network theory. We cast attention as the information flow aggregated from the sources (values) to the sinks (results) through the learned flow capacities (attentions). Within this framework, we apply the property of flow conservation with attention and propose the Flow-Attention mechanism of linear complexity. By respectively conserving the incoming flow of sinks for source competition and the outgoing flow of sources for sink allocation, Flow-Attention inherently generates informative attentions without using specific inductive biases. Empowered by the Flow-Attention, Flowformer yields strong performance in linear time for wide areas, including long sequence, time series, vision, natural language, and reinforcement learning.
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
Oct 11, 2021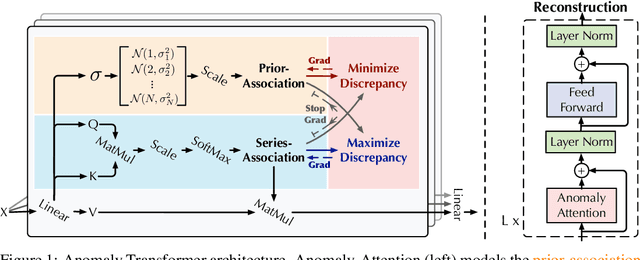
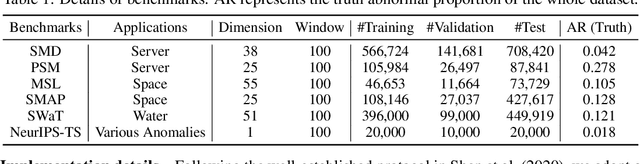
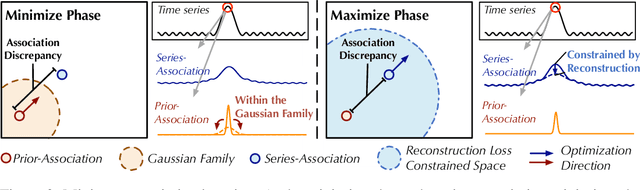
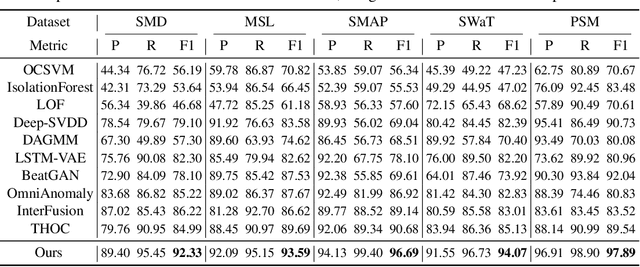
Unsupervisedly detecting anomaly points in time series is challenging, which requires the model to learn informative representations and derive a distinguishable criterion. Prior methods mainly detect anomalies based on the recurrent network representation of each time point. However, the point-wise representation is less informative for complex temporal patterns and can be dominated by normal patterns, making rare anomalies less distinguishable. We find that in each time series, each time point can also be described by its associations with all time points, presenting as a point-wise distribution that is more expressive for temporal modeling. We further observe that due to the rarity of anomalies, it is harder for anomalies to build strong associations with the whole series and their associations shall mainly concentrate on the adjacent time points. This observation implies an inherently distinguishable criterion between normal and abnormal points, which we highlight as the \emph{Association Discrepancy}. Technically we propose the \emph{Anomaly Transformer} with an \emph{Anomaly-Attention} mechanism to compute the association discrepancy. A minimax strategy is devised to amplify the normal-abnormal distinguishability of the association discrepancy. Anomaly Transformer achieves state-of-the-art performance on six unsupervised time series anomaly detection benchmarks for three applications: service monitoring, space \& earth exploration, and water treatment.
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Jul 11, 2021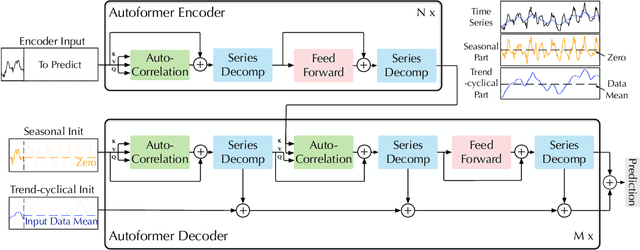
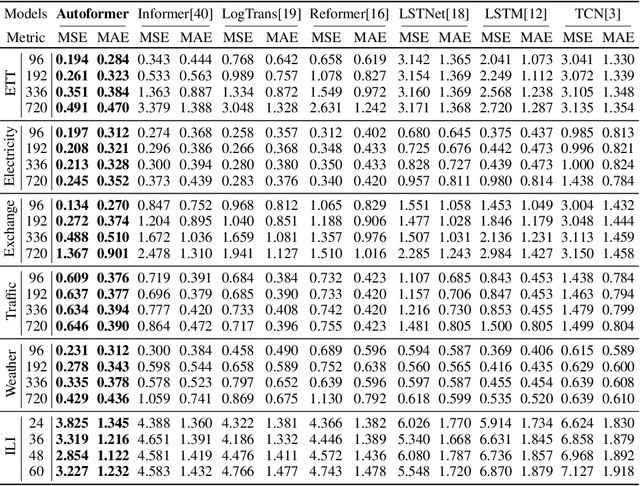
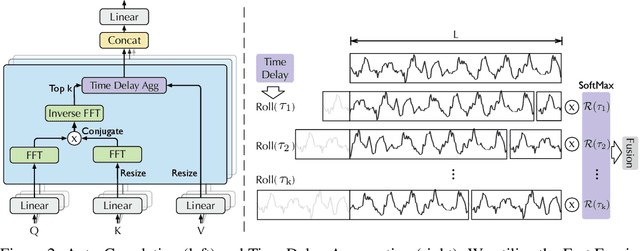
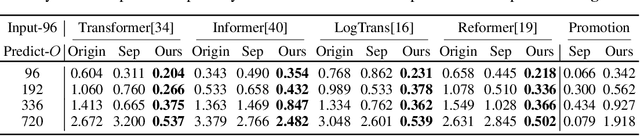
Extending the forecasting time is a critical demand for real applications, such as extreme weather early warning and long-term energy consumption planning. This paper studies the \textit{long-term forecasting} problem of time series. Prior Transformer-based models adopt various self-attention mechanisms to discover the long-range dependencies. However, intricate temporal patterns of the long-term future prohibit the model from finding reliable dependencies. Also, Transformers have to adopt the sparse versions of point-wise self-attentions for long series efficiency, resulting in the information utilization bottleneck. Towards these challenges, we propose Autoformer as a novel decomposition architecture with an Auto-Correlation mechanism. We go beyond the pre-processing convention of series decomposition and renovate it as a basic inner block of deep models. This design empowers Autoformer with progressive decomposition capacities for complex time series. Further, inspired by the stochastic process theory, we design the Auto-Correlation mechanism based on the series periodicity, which conducts the dependencies discovery and representation aggregation at the sub-series level. Auto-Correlation outperforms self-attention in both efficiency and accuracy. In long-term forecasting, Autoformer yields state-of-the-art accuracy, with a 38% relative improvement on six benchmarks, covering five practical applications: energy, traffic, economics, weather and disease.