 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERFIFY: A Multi-Agent Framework for Turning NeRF Papers into Code
Feb 28, 2026The proliferation of neural radiance field (NeRF) research requires significant efforts to reimplement papers before building upon them. We introduce NERFIFY, a multi-agent framework that reliably converts NeRF research papers into trainable Nerfstudio plugins, in contrast to generic paper-to-code methods and frontier models like GPT-5 that usually fail to produce runnable code. NERFIFY achieves domain-specific executability through six key innovations: (1) Context-free grammar (CFG): LLM synthesis is constrained by Nerfstudio formalized as a CFG, ensuring generated code satisfies architectural invariants. (2) Graph-of-Thought code synthesis: Specialized multi-file-agents generate repositories in topological dependency order, validating contracts and errors at each node. (3) Compositional citation recovery: Agents automatically retrieve and integrate components (samplers, encoders, proposal networks) from citation graphs of references. (4) Visual feedback: Artifacts are diagnosed through PSNR-minima ROI analysis, cross-view geometric validation, and VLM-guided patching to iteratively improve quality. (5) Knowledge enhancement: Beyond reproduction, methods can be improved with novel optimizations. (6) Benchmarking: An evaluation framework is designed for NeRF paper-to-code synthesis across 30 diverse papers. On papers without public implementations, NERFIFY achieves visual quality matching expert human code (+/-0.5 dB PSNR, +/-0.2 SSIM) while reducing implementation time from weeks to minutes. NERFIFY demonstrates that a domain-aware design enables code translation for complex vision papers, potentiating accelerated and democratized reproducible research. Code, data and implementations will be publicly released.
Large Language Models for Automatic Detection of Sensitive Topics
Sep 02, 2024



Sensitive information detection is crucial in content moderation to maintain safe online communities. Assisting in this traditionally manual process could relieve human moderators from overwhelming and tedious tasks, allowing them to focus solely on flagged content that may pose potential risks. Rapidly advancing large language models (LLMs) are known for their capability to understand and process natural language and so present a potential solution to support this process. This study explores the capabilities of five LLMs for detecting sensitive messages in the mental well-being domain within two online datasets and assesses their performance in terms of accuracy, precision, recall, F1 scores, and consistency. Our findings indicate that LLMs have the potential to be integrated into the moderation workflow as a convenient and precise detection tool. The best-performing model, GPT-4o, achieved an average accuracy of 99.5\% and an F1-score of 0.99. We discuss the advantages and potential challenges of using LLMs in the moderation workflow and suggest that future research should address the ethical considerations of utilising this technology.
Integrating Physiological Data with Large Language Models for Empathic Human-AI Interaction
Apr 14, 2024
This paper explores enhancing empathy in Large Language Models (LLMs) by integrating them with physiological data. We propose a physiological computing approach that includes developing deep learning models that use physiological data for recognizing psychological states and integrating the predicted states with LLMs for empathic interaction. We showcase the application of this approach in an Empathic LLM (EmLLM) chatbot for stress monitoring and control. We also discuss the results of a pilot study that evaluates this EmLLM chatbot based on its ability to accurately predict user stress, provide human-like responses, and assess the therapeutic alliance with the user.
From Unstable Contacts to Stable Control: A Deep Learning Paradigm for HD-sEMG in Neurorobotics
Sep 20, 2023



In the past decade, there has been significant advancement in designing wearable neural interfaces for controlling neurorobotic systems, particularly bionic limbs. These interfaces function by decoding signals captured non-invasively from the skin's surface. Portable high-density surface electromyography (HD-sEMG) modules combined with deep learning decoding have attracted interest by achieving excellent gesture prediction and myoelectric control of prosthetic systems and neurorobots. However, factors like pixel-shape electrode size and unstable skin contact make HD-sEMG susceptible to pixel electrode drops. The sparse electrode-skin disconnections rooted in issues such as low adhesion, sweating, hair blockage, and skin stretch challenge the reliability and scalability of these modules as the perception unit for neurorobotic systems. This paper proposes a novel deep-learning model providing resiliency for HD-sEMG modules, which can be used in the wearable interfaces of neurorobots. The proposed 3D Dilated Efficient CapsNet model trains on an augmented input space to computationally `force' the network to learn channel dropout variations and thus learn robustness to channel dropout. The proposed framework maintained high performance under a sensor dropout reliability study conducted. Results show conventional models' performance significantly degrades with dropout and is recovered using the proposed architecture and the training paradigm.
Neural Jacobian Fields: Learning Intrinsic Mappings of Arbitrary Meshes
May 05, 2022
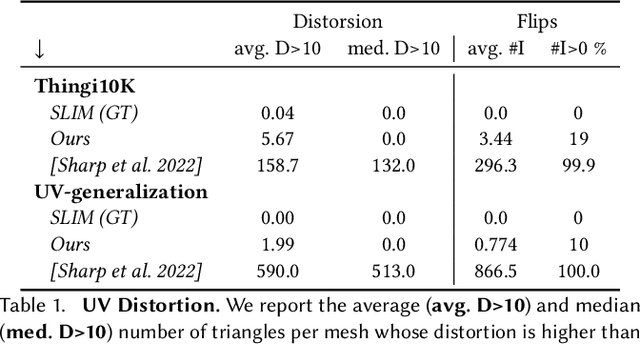

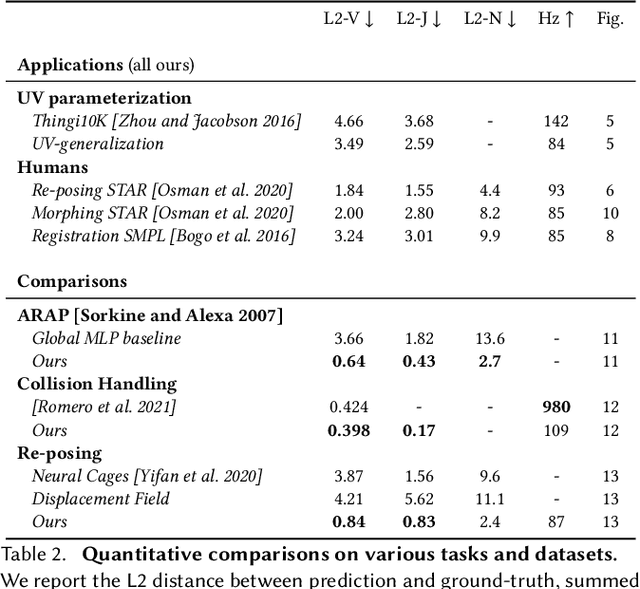
This paper introduces a framework designed to accurately predict piecewise linear mappings of arbitrary meshes via a neural network, enabling training and evaluating over heterogeneous collections of meshes that do not share a triangulation, as well as producing highly detail-preserving maps whose accuracy exceeds current state of the art. The framework is based on reducing the neural aspect to a prediction of a matrix for a single given point, conditioned on a global shape descriptor. The field of matrices is then projected onto the tangent bundle of the given mesh, and used as candidate jacobians for the predicted map. The map is computed by a standard Poisson solve, implemented as a differentiable layer with cached pre-factorization for efficient training. This construction is agnostic to the triangulation of the input, thereby enabling applications on datasets with varying triangulations. At the same time, by operating in the intrinsic gradient domain of each individual mesh, it allows the framework to predict highly-accurate mappings. We validate these properties by conducting experiments over a broad range of scenarios, from semantic ones such as morphing, registration, and deformation transfer, to optimization-based ones, such as emulating elastic deformations and contact correction, as well as being the first work, to our knowledge, to tackle the task of learning to compute UV parameterizations of arbitrary meshes. The results exhibit the high accuracy of the method as well as its versatility, as it is readily applied to the above scenarios without any changes to the framework.
Neural Computed Tomography
Jan 17, 2022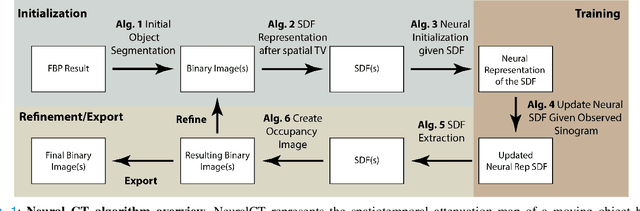
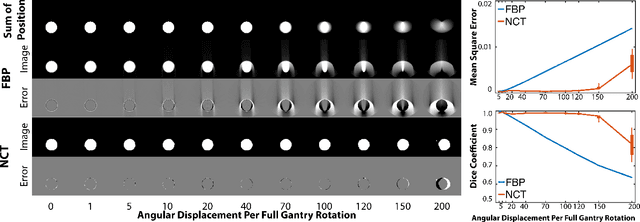
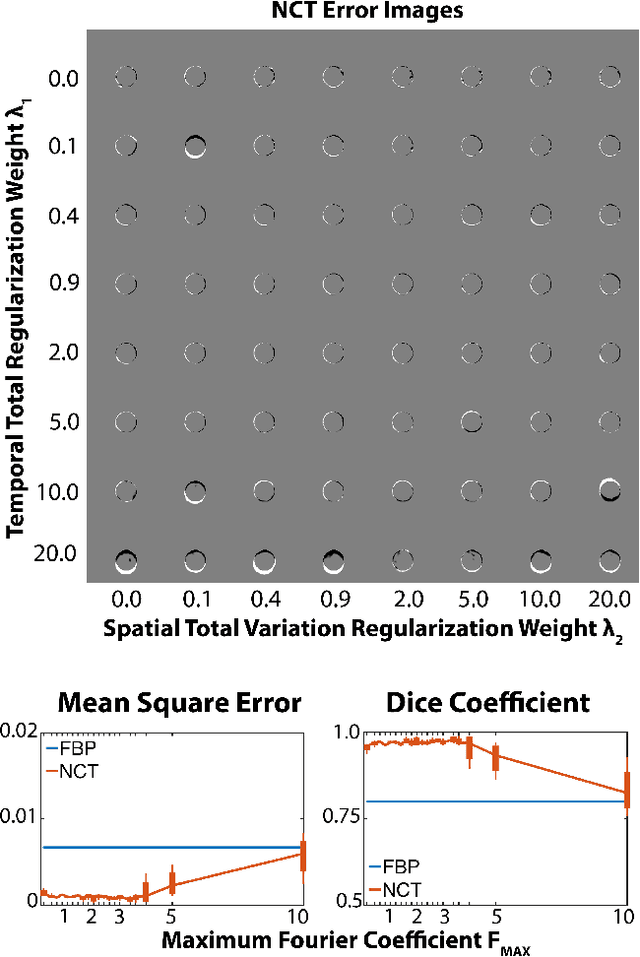
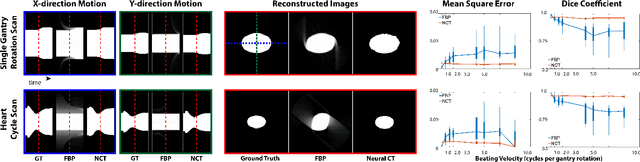
Motion during acquisition of a set of projections can lead to significant motion artifacts in computed tomography reconstructions despite fast acquisition of individual views. In cases such as cardiac imaging, motion may be unavoidable and evaluating motion may be of clinical interest. Reconstructing images with reduced motion artifacts has typically been achieved by developing systems with faster gantry rotation or using algorithms which measure and/or estimate the displacements. However, these approaches have had limited success due to both physical constraints as well as the challenge of estimating/measuring non-rigid, temporally varying, and patient-specific motions. We propose a novel reconstruction framework, NeuralCT, to generate time-resolved images free from motion artifacts. Our approaches utilizes a neural implicit approach and does not require estimation or modeling of the underlying motion. Instead, boundaries are represented using a signed distance metric and neural implicit framework. We utilize `analysis-by-synthesis' to identify a solution consistent with the acquired sinogram as well as spatial and temporal consistency constraints. We illustrate the utility of NeuralCT in three progressively more complex scenarios: translation of a small circle, heartbeat-like change in an ellipse's diameter, and complex topological deformation. Without hyperparameter tuning or change to the architecture, NeuralCT provides high quality image reconstruction for all three motions, as compared to filtered backprojection, using mean-square-error and Dice metrics.
Neural Mesh Flow: 3D Manifold Mesh Generationvia Diffeomorphic Flows
Jul 21, 2020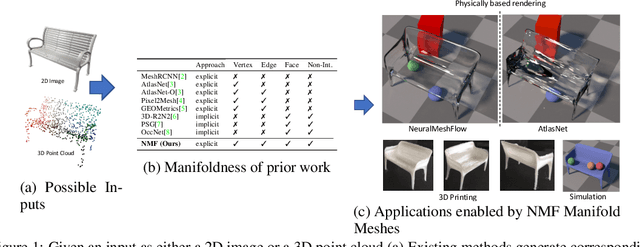
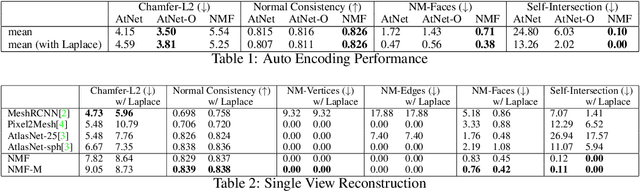
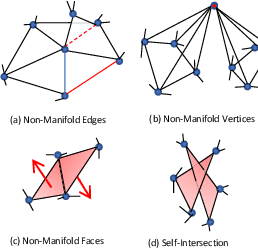

Meshes are important representations of physical 3D entities in the virtual world. Applications like rendering, simulations and 3D printing require meshes to be manifold so that they can interact with the world like the real objects they represent. Prior methods generate meshes with great geometric accuracy but poor manifoldness. In this work, we propose Neural Mesh Flow (NMF) to generate two-manifold meshes for genus-0 shapes. Specifically, NMF is a shape auto-encoder consisting of several Neural Ordinary Differential Equation (NODE)[1]blocks that learn accurate mesh geometry by progressively deforming a spherical mesh. Training NMF is simpler compared to state-of-the-art methods since it does not require any explicit mesh-based regularization. Our experiments demonstrate that NMF facilitates several applications such as single-view mesh reconstruction, global shape parameterization, texture mapping, shape deformation and correspondence. Importantly, we demonstrate that manifold meshes generated using NMF are better-suited for physically-based rendering and simulation. Code and data will be released.