 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Matching Normalizing Flows and Probability Paths on Manifolds
Jul 11, 2022

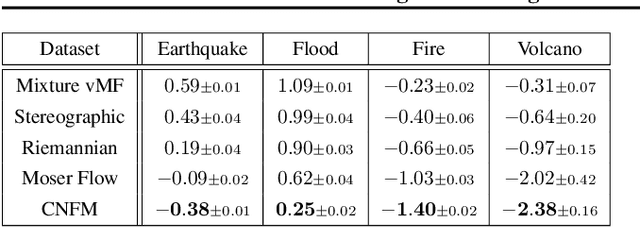
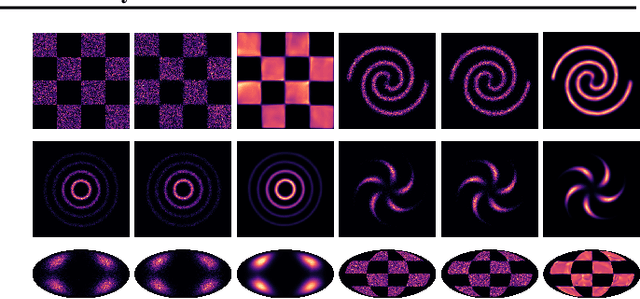
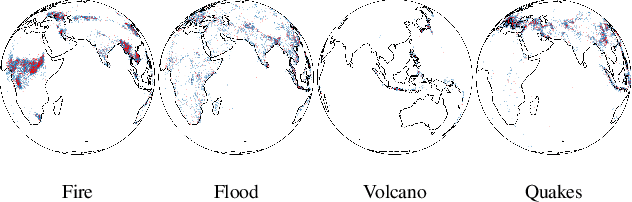
Continuous Normalizing Flows (CNFs) are a class of generative models that transform a prior distribution to a model distribution by solving an ordinary differential equation (ODE). We propose to train CNFs on manifolds by minimizing probability path divergence (PPD), a novel family of divergences between the probability density path generated by the CNF and a target probability density path. PPD is formulated using a logarithmic mass conservation formula which is a linear first order partial differential equation relating the log target probabilities and the CNF's defining vector field. PPD has several key benefits over existing methods: it sidesteps the need to solve an ODE per iteration, readily applies to manifold data, scales to high dimensions, and is compatible with a large family of target paths interpolating pure noise and data in finite time. Theoretically, PPD is shown to bound classical probability divergences. Empirically, we show that CNFs learned by minimizing PPD achieve state-of-the-art results in likelihoods and sample quality on existing low-dimensional manifold benchmarks, and is the first example of a generative model to scale to moderately high dimensional manifolds.
Rhythm and form in music: a complex systems approach
Jul 07, 2022
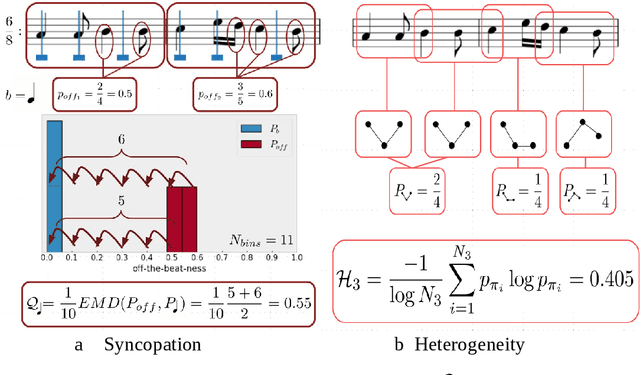
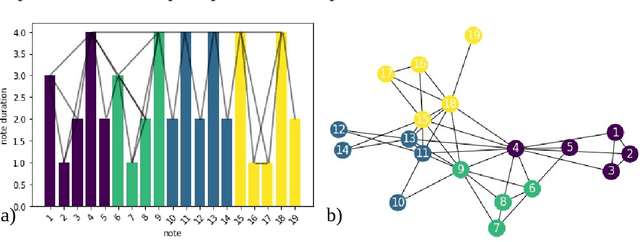

There has been an everlasting discussion around the concept of form in music. This work is motivated by such debate by using a complex systems framework in which we study the form as an emergent property of rhythm. Such a framework corresponds with the traditional notion of musical form and allows us to generalize this concept to more general shapes and structures in music. We develop the three following metrics of the rhythmic complexity of a musical piece and its parts: 1) the rhythmic heterogeneity, based on the permutation entropy, where high values indicate a wide variety of rhythmic patterns; 2) the syncopation, based on the distribution of on-beat onsets, where high values indicate a high proportion of off-the-beat notes; and 3) the component extractor, based on the communities of a visibility graph of the rhythmic figures over time, where we identify structural components that constitute the piece at a (to be explained) perceptual level. With the same parameters, our metrics are comparable within a piece or between pieces.
United States Politicians' Tone Became More Negative with 2016 Primary Campaigns
Jul 17, 2022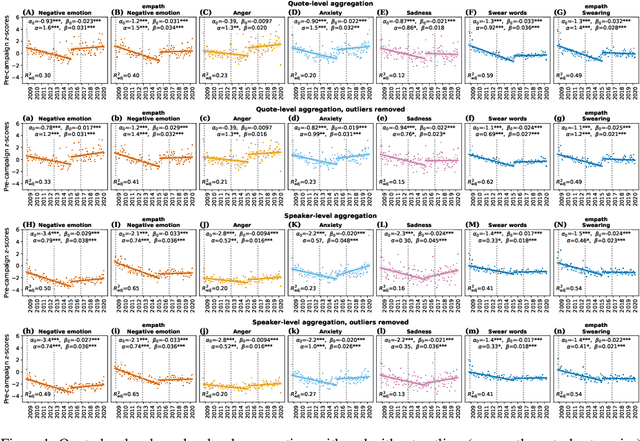
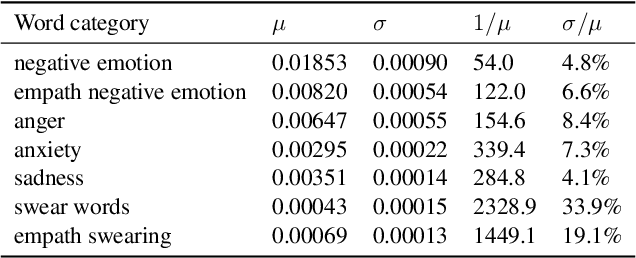
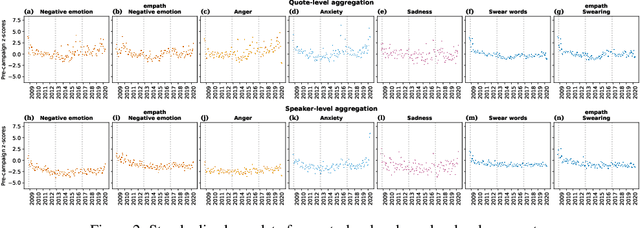
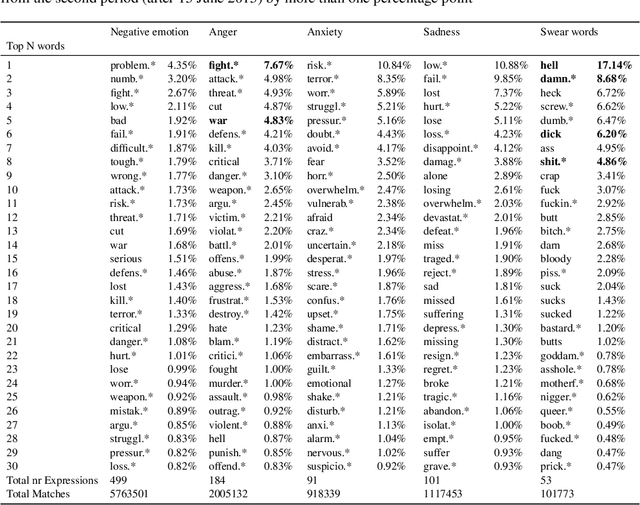
There is a widespread belief that the tone of US political language has become more negative recently, in particular when Donald Trump entered politics. At the same time, there is disagreement as to whether Trump changed or merely continued previous trends. To date, data-driven evidence regarding these questions is scarce, partly due to the difficulty of obtaining a comprehensive, longitudinal record of politicians' utterances. Here we apply psycholinguistic tools to a novel, comprehensive corpus of 24 million quotes from online news attributed to 18,627 US politicians in order to analyze how the tone of US politicians' language evolved between 2008 and 2020. We show that, whereas the frequency of negative emotion words had decreased continuously during Obama's tenure, it suddenly and lastingly increased with the 2016 primary campaigns, by 1.6 pre-campaign standard deviations, or 8% of the pre-campaign mean, in a pattern that emerges across parties. The effect size drops by 40% when omitting Trump's quotes, and by 50% when averaging over speakers rather than quotes, implying that prominent speakers, and Trump in particular, have disproportionately, though not exclusively, contributed to the rise in negative language. This work provides the first large-scale data-driven evidence of a drastic shift toward a more negative political tone following Trump's campaign start as a catalyst, with important implications for the debate about the state of US politics.
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 17, 2021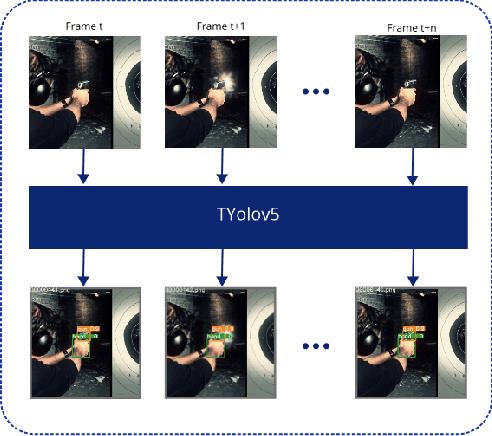
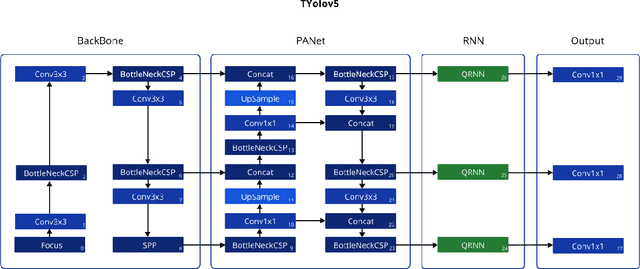
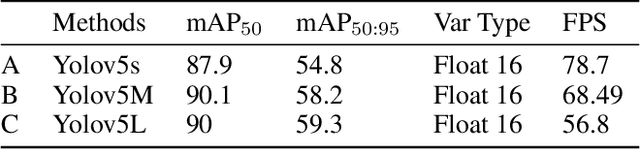
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depend of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based in Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of the handgun detection. Moreover, two publicity available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based in Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 56.1, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59.4, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
Landscape Learning for Neural Network Inversion
Jun 17, 2022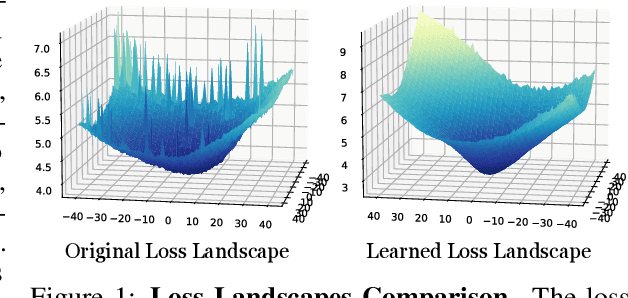
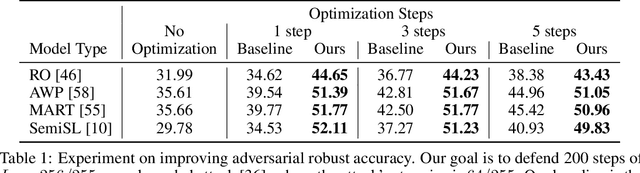
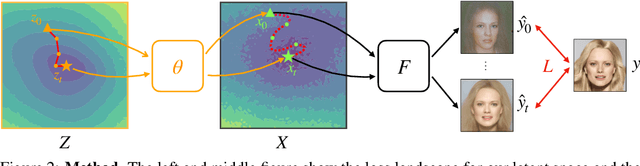

Many machine learning methods operate by inverting a neural network at inference time, which has become a popular technique for solving inverse problems in computer vision, robotics, and graphics. However, these methods often involve gradient descent through a highly non-convex loss landscape, causing the optimization process to be unstable and slow. We introduce a method that learns a loss landscape where gradient descent is efficient, bringing massive improvement and acceleration to the inversion process. We demonstrate this advantage on a number of methods for both generative and discriminative tasks, including GAN inversion, adversarial defense, and 3D human pose reconstruction.
Forecasting COVID-19 Caseloads Using Unsupervised Embedding Clusters of Social Media Posts
May 20, 2022
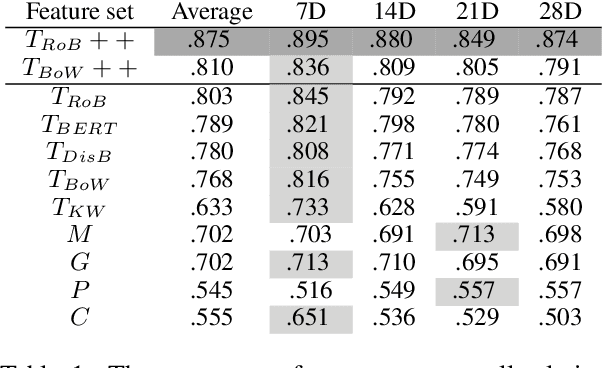
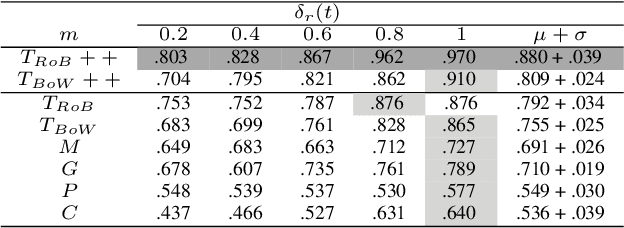
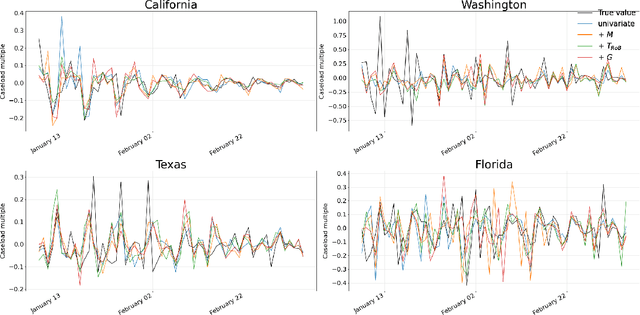
We present a novel approach incorporating transformer-based language models into infectious disease modelling. Text-derived features are quantified by tracking high-density clusters of sentence-level representations of Reddit posts within specific US states' COVID-19 subreddits. We benchmark these clustered embedding features against features extracted from other high-quality datasets. In a threshold-classification task, we show that they outperform all other feature types at predicting upward trend signals, a significant result for infectious disease modelling in areas where epidemiological data is unreliable. Subsequently, in a time-series forecasting task we fully utilise the predictive power of the caseload and compare the relative strengths of using different supplementary datasets as covariate feature sets in a transformer-based time-series model.
Real-Time Optimal Trajectory Planning for Autonomous Vehicles and Lap Time Simulation Using Machine Learning
Feb 05, 2021
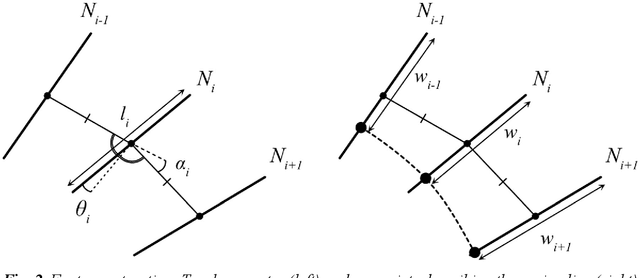
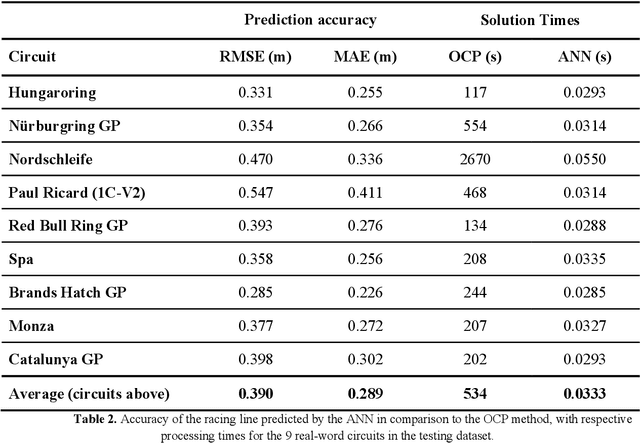

The widespread development of driverless vehicles has led to the formation of autonomous racing competitions, where the high speeds and fierce rivalry in motorsport provide a testbed to accelerate technology development. A particular challenge for an autonomous vehicle is that of identifying a target trajectory - or in the case of a racing car, the ideal racing line. Many existing approaches to identifying the racing line are either not the time-optimal solutions, or have solution times which are computationally expensive, thus rendering them unsuitable for real-time application using on-board processing hardware. This paper describes a machine learning approach to generating an accurate prediction of the racing line in real-time on desktop processing hardware. The proposed algorithm is a dense feed-forward neural network, trained using a dataset comprising racing lines for a large number of circuits calculated via a traditional optimal control lap time simulation. The network is capable of predicting the racing line with a mean absolute error of +/-0.27m, meaning that the accuracy outperforms a human driver, and is comparable to other parts of the autonomous vehicle control system. The system generates predictions within 33ms, making it over 9,000 times faster than traditional methods of finding the optimal racing line. Results suggest that a data-driven approach may therefore be favourable for real-time generation of near-optimal racing lines than traditional computational methods.
Hybrid iLQR Model Predictive Control for Contact Implicit Stabilization on Legged Robots
Jul 11, 2022

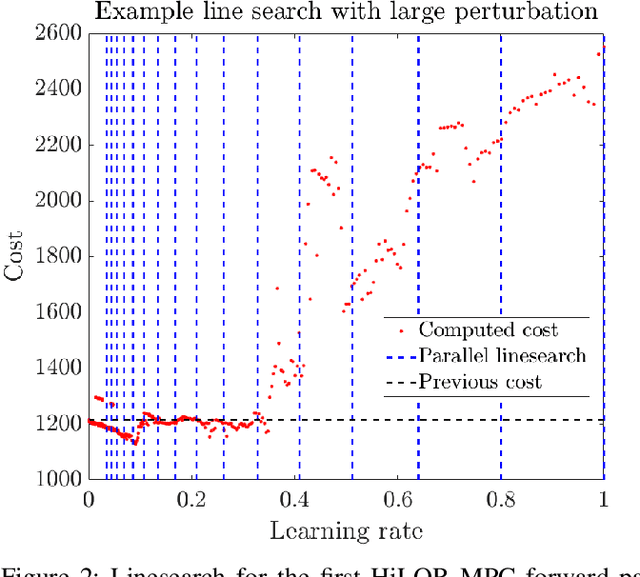
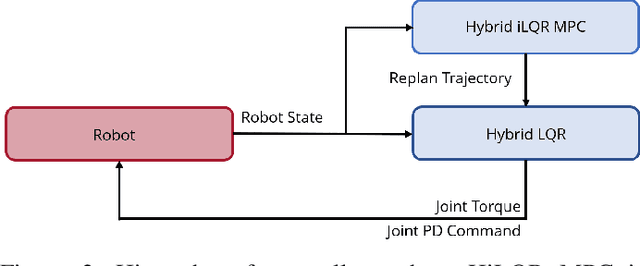
Model Predictive Control (MPC) is a popular strategy for controlling robots but is difficult for systems with contact due to the complex nature of hybrid dynamics. To implement MPC for systems with contact, dynamic models are often simplified or contact sequences fixed in time in order to plan trajectories efficiently. In this work, we extend Hybrid iterative Linear Quadratic Regulator to work in a MPC fashion (HiLQR MPC) by 1) modifying how the cost function is computed when contact modes do not align, 2) utilizing parallelizations when simulating rigid body dynamics, and 3) using efficient analytical derivative computations of the rigid body dynamics. The result is a system that can modify the contact sequence of the reference behavior and plan whole body motions cohesively -- which is crucial when dealing with large perturbations. HiLQR MPC is tested on two systems: first, the hybrid cost modification is validated on a simple actuated bouncing ball hybrid system. Then HiLQR MPC is compared against methods that utilize centroidal dynamic assumptions on a quadruped robot (Unitree A1). HiLQR MPC outperforms the centroidal methods in both simulation and hardware tests.
TIMo -- A Dataset for Indoor Building Monitoring with a Time-of-Flight Camera
Aug 27, 2021
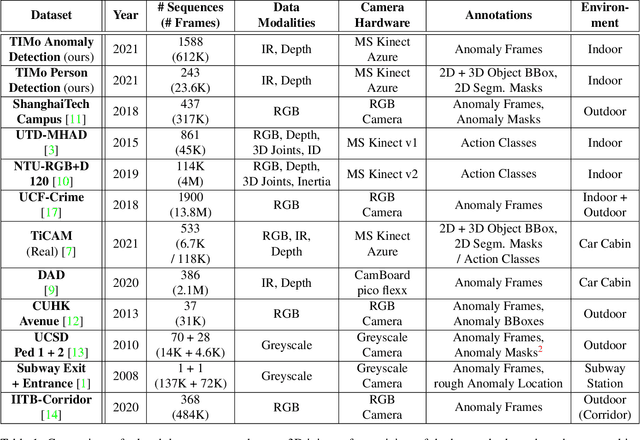

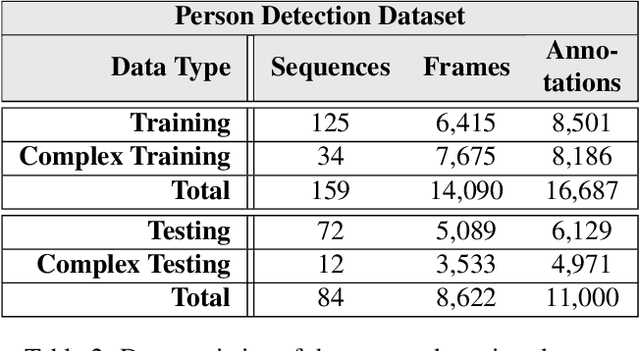
We present TIMo (Time-of-flight Indoor Monitoring), a dataset for video-based monitoring of indoor spaces captured using a time-of-flight (ToF) camera. The resulting depth videos feature people performing a set of different predefined actions, for which we provide detailed annotations. Person detection for people counting and anomaly detection are the two targeted applications. Most existing surveillance video datasets provide either grayscale or RGB videos. Depth information, on the other hand, is still a rarity in this class of datasets in spite of being popular and much more common in other research fields within computer vision. Our dataset addresses this gap in the landscape of surveillance video datasets. The recordings took place at two different locations with the ToF camera set up either in a top-down or a tilted perspective on the scene. The dataset is publicly available at https://vizta-tof.kl.dfki.de/timo-dataset-overview/.
Two-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022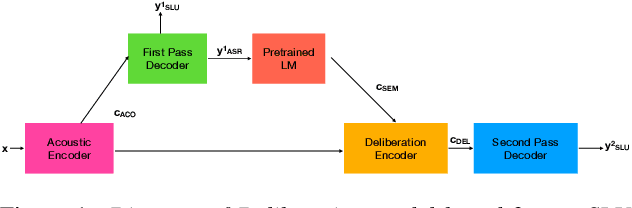
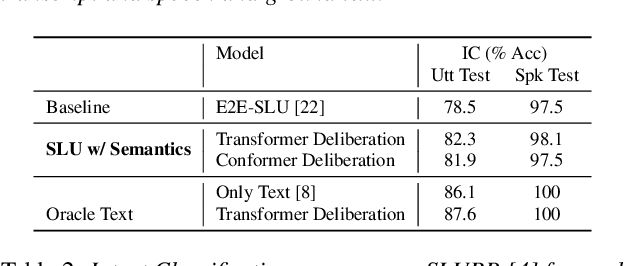

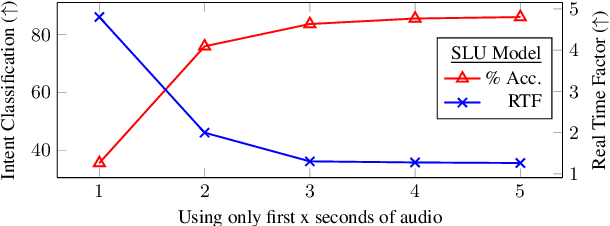
End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.