 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-stage warm started optimal motion planning for over-actuated mobile platforms
Jul 29, 2022
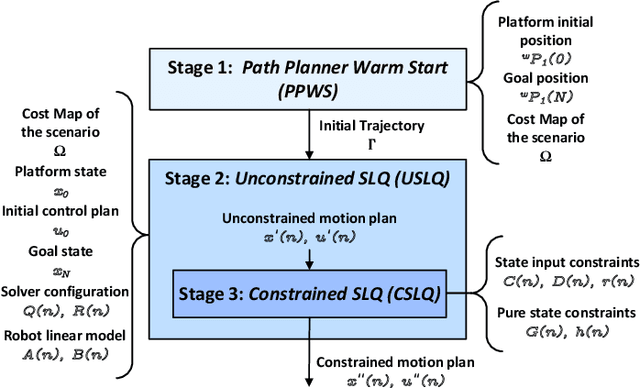
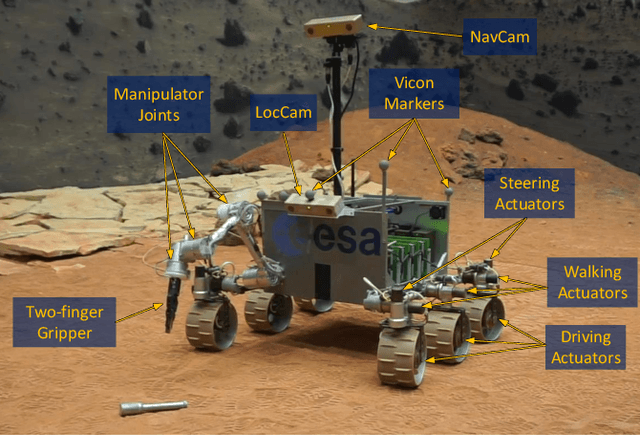
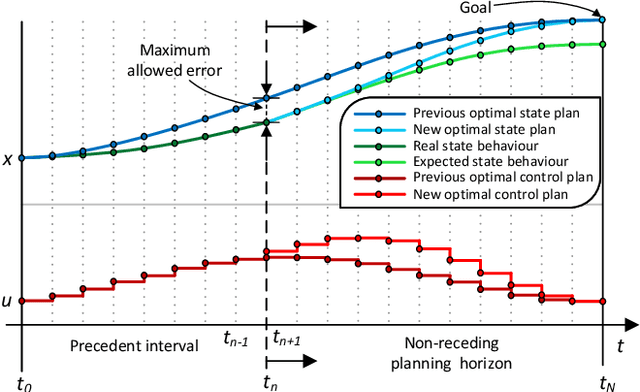
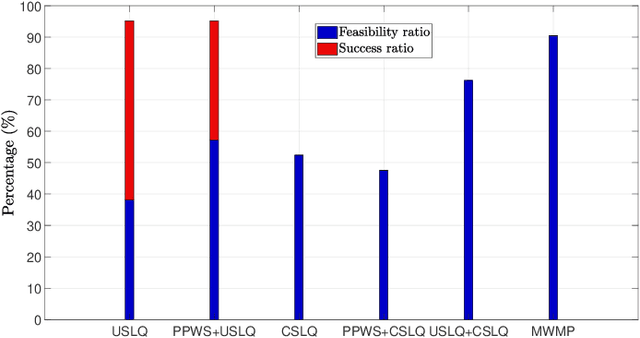
This work presents a computationally lightweight motion planner for over-actuated platforms. For this purpose, a general state-space model for mobile platforms with several kinematic chains is defined, which considers non-linearities and constraints. The proposed motion planner is based on a sequential multi-stage approach that takes advantage of the warm start on each step. Firstly, a globally optimal and smooth 2D/3D trajectory is generated using the Fast Marching Method. This trajectory is fed as a warm start to a sequential linear quadratic regulator that is able to generate an optimal motion plan without constraints for all the platform actuators. Finally, a feasible motion plan is generated considering the constraints defined in the model. In this respect, the sequential linear quadratic regulator is employed again, taking the previously generated unconstrained motion plan as a warm start. This novel approach has been deployed into the Exomars Testing Rover of the European Space Agency. This rover is an Ackermann-capable planetary exploration testbed that is equipped with a robotic arm. Several experiments were carried out demonstrating that the proposed approach speeds up the computation time, increasing the success ratio for a martian sample retrieval mission, which can be considered as a representative use case of an over-actuated mobile platform.
Vision-Based Activity Recognition in Children with Autism-Related Behaviors
Aug 08, 2022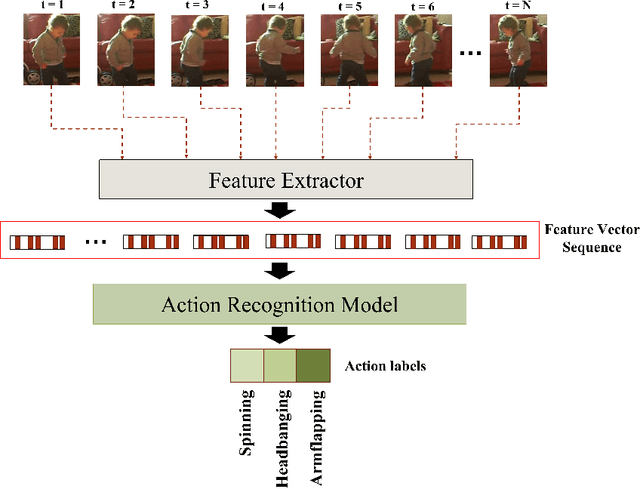
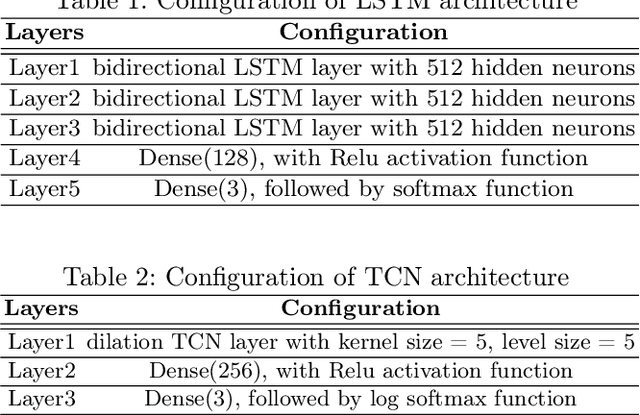
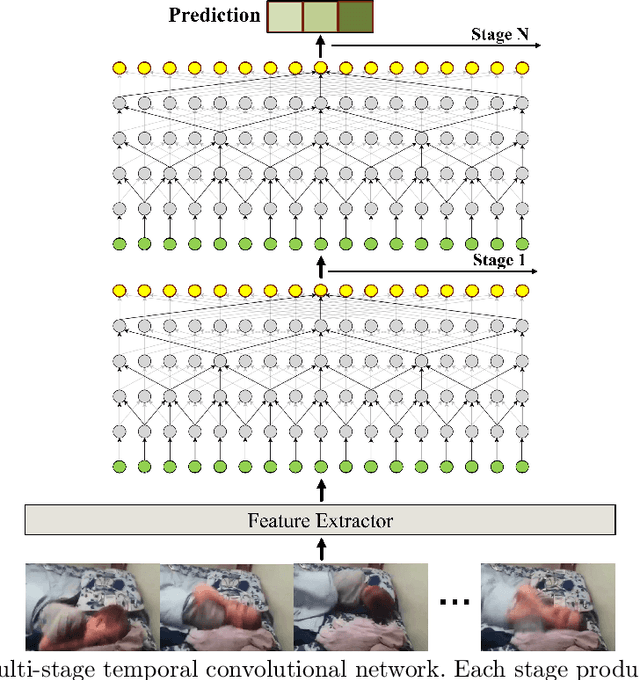
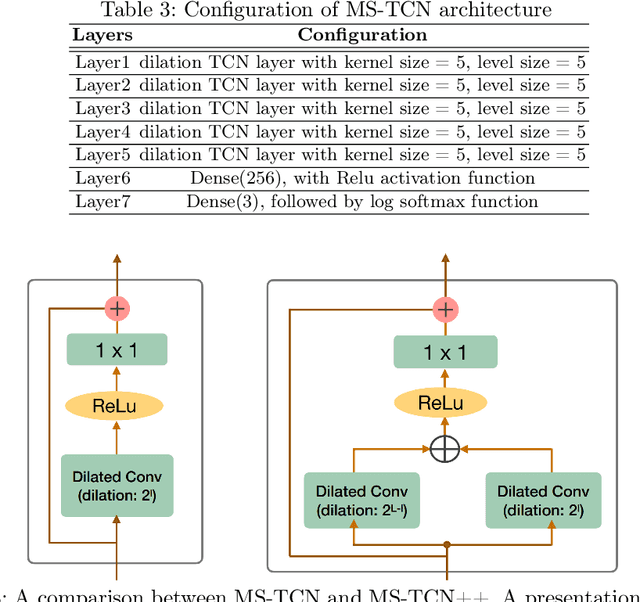
Advances in machine learning and contactless sensors have enabled the understanding complex human behaviors in a healthcare setting. In particular, several deep learning systems have been introduced to enable comprehensive analysis of neuro-developmental conditions such as Autism Spectrum Disorder (ASD). This condition affects children from their early developmental stages onwards, and diagnosis relies entirely on observing the child's behavior and detecting behavioral cues. However, the diagnosis process is time-consuming as it requires long-term behavior observation, and the scarce availability of specialists. We demonstrate the effect of a region-based computer vision system to help clinicians and parents analyze a child's behavior. For this purpose, we adopt and enhance a dataset for analyzing autism-related actions using videos of children captured in uncontrolled environments (e.g. videos collected with consumer-grade cameras, in varied environments). The data is pre-processed by detecting the target child in the video to reduce the impact of background noise. Motivated by the effectiveness of temporal convolutional models, we propose both light-weight and conventional models capable of extracting action features from video frames and classifying autism-related behaviors by analyzing the relationships between frames in a video. Through extensive evaluations on the feature extraction and learning strategies, we demonstrate that the best performance is achieved with an Inflated 3D Convnet and Multi-Stage Temporal Convolutional Networks, achieving a 0.83 Weighted F1-score for classification of the three autism-related actions, outperforming existing methods. We also propose a light-weight solution by employing the ESNet backbone within the same system, achieving competitive results of 0.71 Weighted F1-score, and enabling potential deployment on embedded systems.
Model-based graph reinforcement learning for inductive traffic signal control
Aug 01, 2022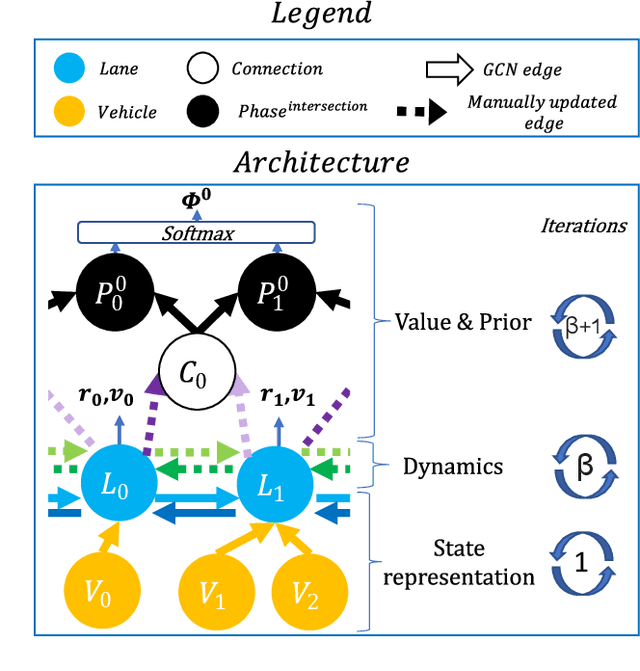
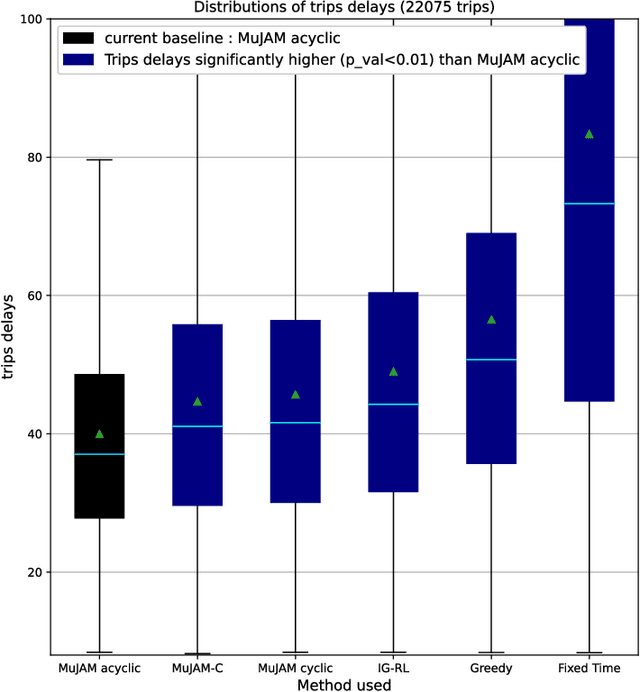
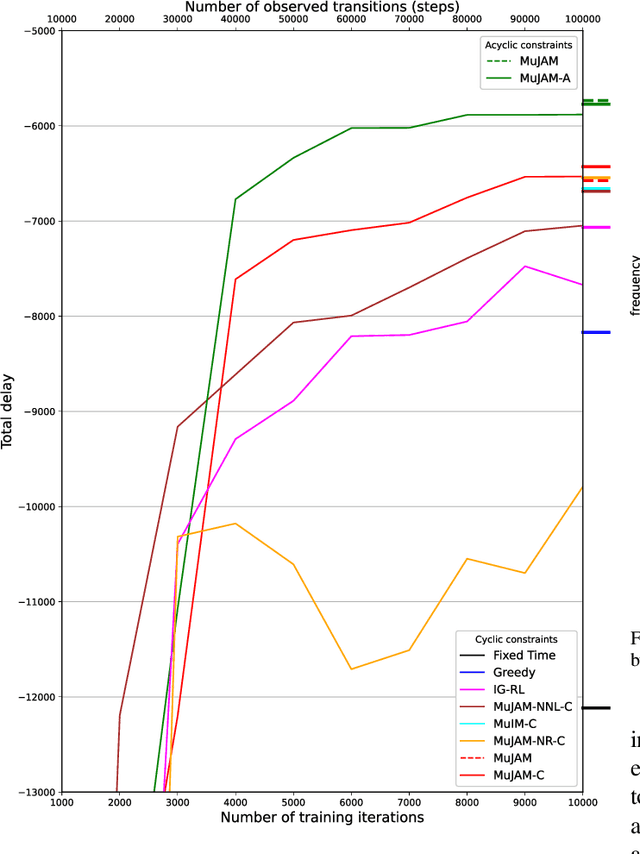
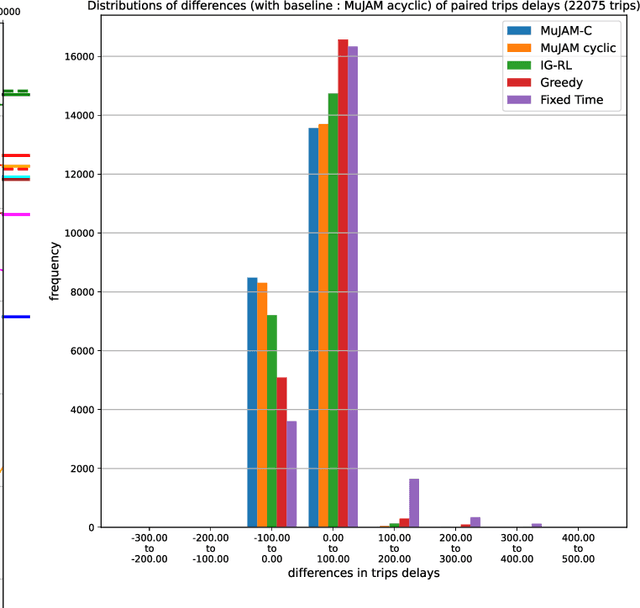
Most reinforcement learning methods for adaptive-traffic-signal-control require training from scratch to be applied on any new intersection or after any modification to the road network, traffic distribution, or behavioral constraints experienced during training. Considering 1) the massive amount of experience required to train such methods, and 2) that experience must be gathered by interacting in an exploratory fashion with real road-network-users, such a lack of transferability limits experimentation and applicability. Recent approaches enable learning policies that generalize for unseen road-network topologies and traffic distributions, partially tackling this challenge. However, the literature remains divided between the learning of cyclic (the evolution of connectivity at an intersection must respect a cycle) and acyclic (less constrained) policies, and these transferable methods 1) are only compatible with cyclic constraints and 2) do not enable coordination. We introduce a new model-based method, MuJAM, which, on top of enabling explicit coordination at scale for the first time, pushes generalization further by allowing a generalization to the controllers' constraints. In a zero-shot transfer setting involving both road networks and traffic settings never experienced during training, and in a larger transfer experiment involving the control of 3,971 traffic signal controllers in Manhattan, we show that MuJAM, using both cyclic and acyclic constraints, outperforms domain-specific baselines as well as another transferable approach.
Computer Vision Aided mmWave Beam Alignment in V2X Communications
Jul 23, 2022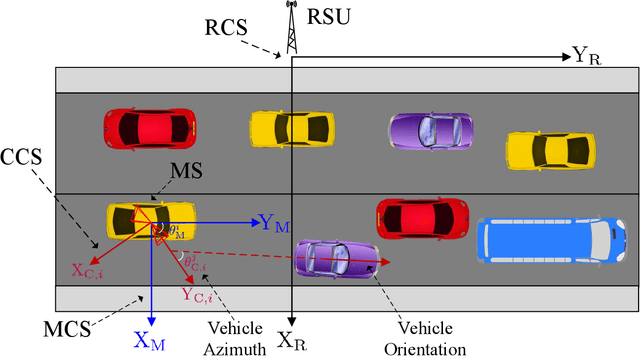

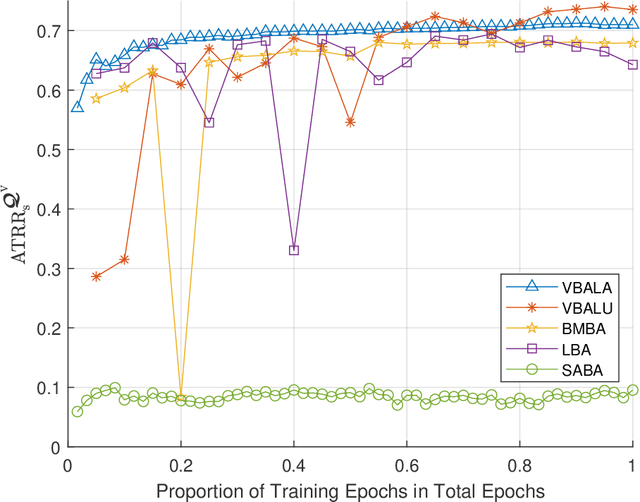
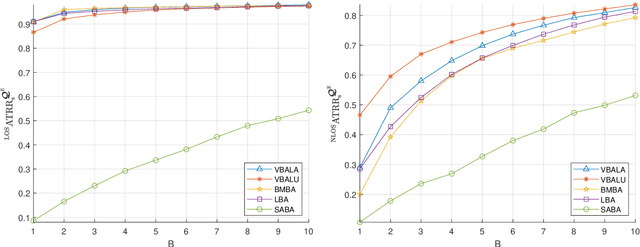
Visual information, captured for example by cameras, can effectively reflect the sizes and locations of the environmental scattering objects, and thereby can be used to infer communications parameters like propagation directions, receiver powers, as well as the blockage status. In this paper, we propose a novel beam alignment framework that leverages images taken by cameras installed at the mobile user. Specifically, we utilize 3D object detection techniques to extract the size and location information of the dynamic vehicles around the mobile user, and design a deep neural network (DNN) to infer the optimal beam pair for transceivers without any pilot signal overhead. Moreover, to avoid performing beam alignment too frequently or too slowly, a beam coherence time (BCT) prediction method is developed based on the vision information. This can effectively improve the transmission rate compared with the beam alignment approach with the fixed BCT. Simulation results show that the proposed vision based beam alignment methods outperform the existing LIDAR and vision based solutions, and demand for much lower hardware cost and communication overhead.
Hyperspectral image reconstruction for spectral camera based on ghost imaging via sparsity constraints using V-DUnet
Jun 28, 2022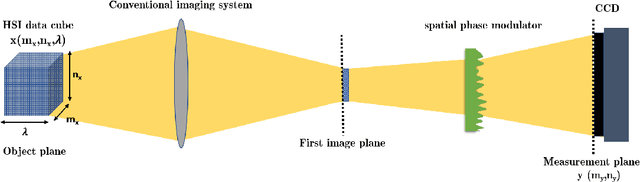
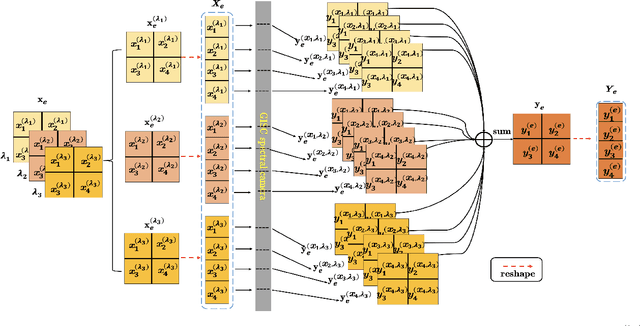
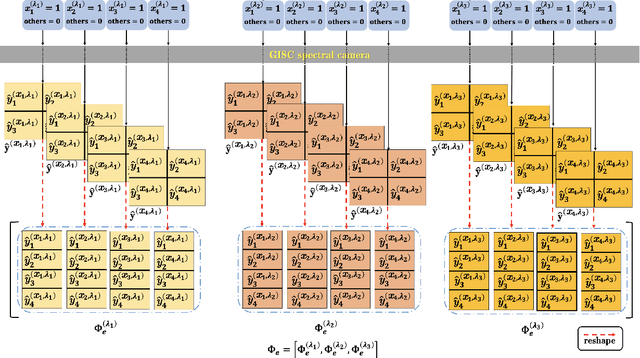
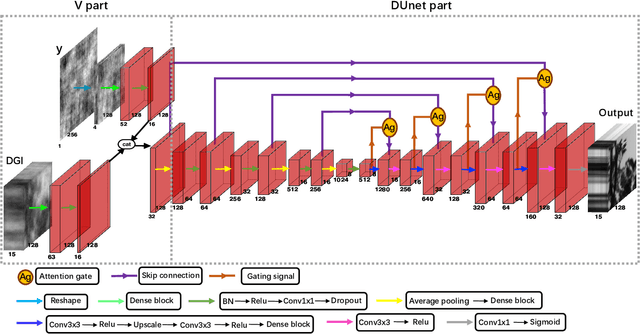
Spectral camera based on ghost imaging via sparsity constraints (GISC spectral camera) obtains three-dimensional (3D) hyperspectral information with two-dimensional (2D) compressive measurements in a single shot, which has attracted much attention in recent years. However, its imaging quality and real-time performance of reconstruction still need to be further improved. Recently, deep learning has shown great potential in improving the reconstruction quality and reconstruction speed for computational imaging. When applying deep learning into GISC spectral camera, there are several challenges need to be solved: 1) how to deal with the large amount of 3D hyperspectral data, 2) how to reduce the influence caused by the uncertainty of the random reference measurements, 3) how to improve the reconstructed image quality as far as possible. In this paper, we present an end-to-end V-DUnet for the reconstruction of 3D hyperspectral data in GISC spectral camera. To reduce the influence caused by the uncertainty of the measurement matrix and enhance the reconstructed image quality, both differential ghost imaging results and the detected measurements are sent into the network's inputs. Compared with compressive sensing algorithm, such as PICHCS and TwIST, it not only significantly improves the imaging quality with high noise immunity, but also speeds up the reconstruction time by more than two orders of magnitude.
CheXplaining in Style: Counterfactual Explanations for Chest X-rays using StyleGAN
Jul 15, 2022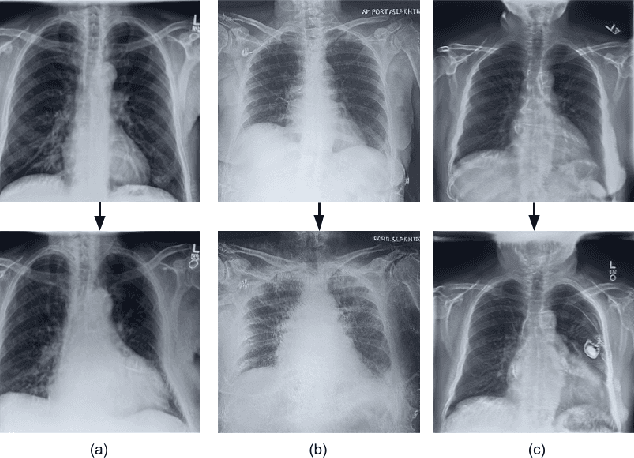
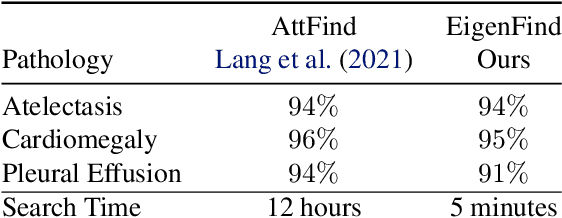
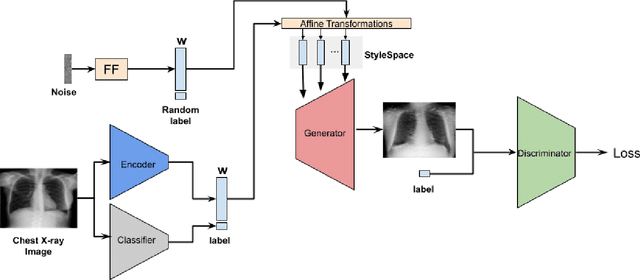
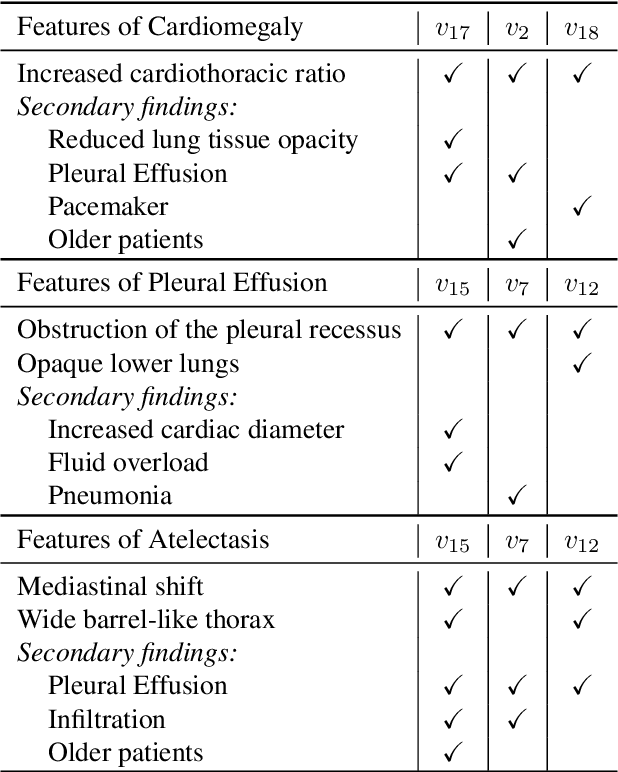
Deep learning models used in medical image analysis are prone to raising reliability concerns due to their black-box nature. To shed light on these black-box models, previous works predominantly focus on identifying the contribution of input features to the diagnosis, i.e., feature attribution. In this work, we explore counterfactual explanations to identify what patterns the models rely on for diagnosis. Specifically, we investigate the effect of changing features within chest X-rays on the classifier's output to understand its decision mechanism. We leverage a StyleGAN-based approach (StyleEx) to create counterfactual explanations for chest X-rays by manipulating specific latent directions in their latent space. In addition, we propose EigenFind to significantly reduce the computation time of generated explanations. We clinically evaluate the relevancy of our counterfactual explanations with the help of radiologists. Our code is publicly available.
Test-time Collective Prediction
Jun 22, 2021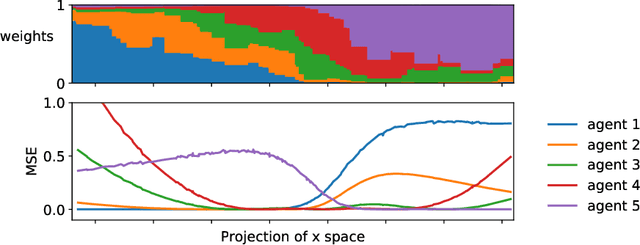
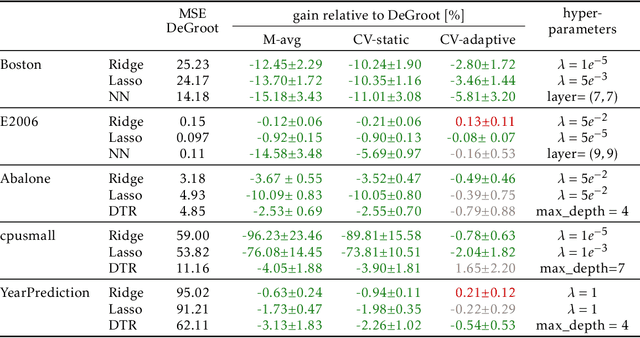
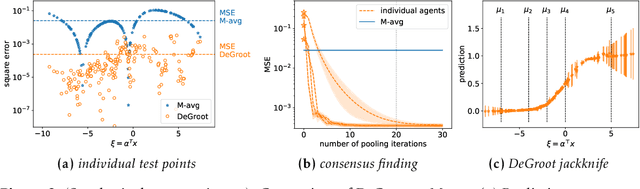
An increasingly common setting in machine learning involves multiple parties, each with their own data, who want to jointly make predictions on future test points. Agents wish to benefit from the collective expertise of the full set of agents to make better predictions than they would individually, but may not be willing to release their data or model parameters. In this work, we explore a decentralized mechanism to make collective predictions at test time, leveraging each agent's pre-trained model without relying on external validation, model retraining, or data pooling. Our approach takes inspiration from the literature in social science on human consensus-making. We analyze our mechanism theoretically, showing that it converges to inverse meansquared-error (MSE) weighting in the large-sample limit. To compute error bars on the collective predictions we propose a decentralized Jackknife procedure that evaluates the sensitivity of our mechanism to a single agent's prediction. Empirically, we demonstrate that our scheme effectively combines models with differing quality across the input space. The proposed consensus prediction achieves significant gains over classical model averaging, and even outperforms weighted averaging schemes that have access to additional validation data.
Determining HEDP Foams' Quality with Multi-View Deep Learning Classification
Aug 10, 2022

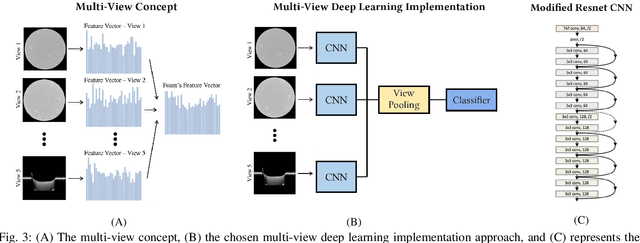
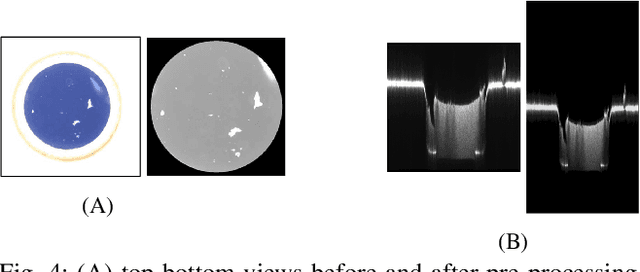
High energy density physics (HEDP) experiments commonly involve a dynamic wave-front propagating inside a low-density foam. This effect affects its density and hence, its transparency. A common problem in foam production is the creation of defective foams. Accurate information on their dimension and homogeneity is required to classify the foams' quality. Therefore, those parameters are being characterized using a 3D-measuring laser confocal microscope. For each foam, five images are taken: two 2D images representing the top and bottom surface foam planes and three images of side cross-sections from 3D scannings. An expert has to do the complicated, harsh, and exhausting work of manually classifying the foam's quality through the image set and only then determine whether the foam can be used in experiments or not. Currently, quality has two binary levels of normal vs. defective. At the same time, experts are commonly required to classify a sub-class of normal-defective, i.e., foams that are defective but might be sufficient for the needed experiment. This sub-class is problematic due to inconclusive judgment that is primarily intuitive. In this work, we present a novel state-of-the-art multi-view deep learning classification model that mimics the physicist's perspective by automatically determining the foams' quality classification and thus aids the expert. Our model achieved 86\% accuracy on upper and lower surface foam planes and 82\% on the entire set, suggesting interesting heuristics to the problem. A significant added value in this work is the ability to regress the foam quality instead of binary deduction and even explain the decision visually. The source code used in this work, as well as other relevant sources, are available at: https://github.com/Scientific-Computing-Lab-NRCN/Multi-View-Foams.git
Unbiased Estimation using the Underdamped Langevin Dynamics
Jun 14, 2022
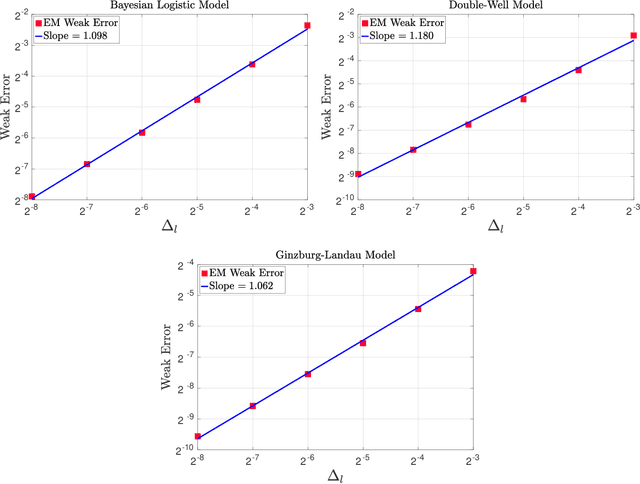
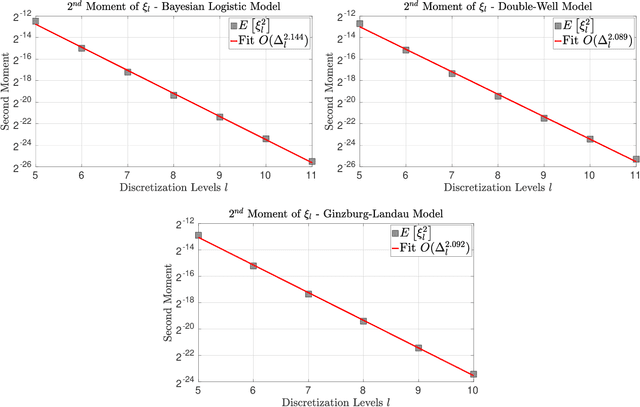
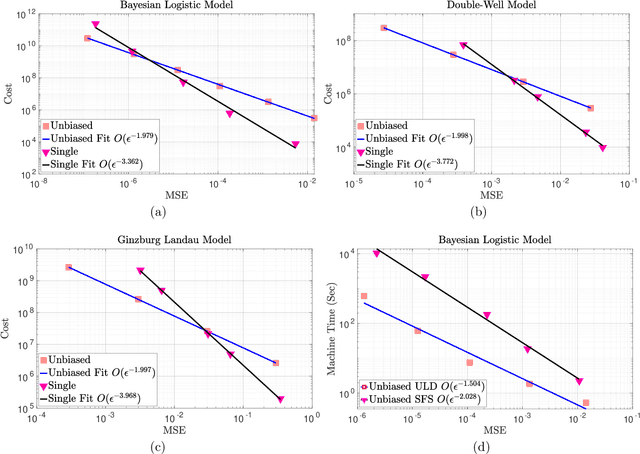
In this work we consider the unbiased estimation of expectations w.r.t.~probability measures that have non-negative Lebesgue density, and which are known point-wise up-to a normalizing constant. We focus upon developing an unbiased method via the underdamped Langevin dynamics, which has proven to be popular of late due to applications in statistics and machine learning. Specifically in continuous-time, the dynamics can be constructed to admit the probability of interest as a stationary measure. We develop a novel scheme based upon doubly randomized estimation, which requires access only to time-discretized versions of the dynamics and are the ones that are used in practical algorithms. We prove, under standard assumptions, that our estimator is of finite variance and either has finite expected cost, or has finite cost with a high probability. To illustrate our theoretical findings we provide numerical experiments that verify our theory, which include challenging examples from Bayesian statistics and statistical physics.
Continual Meta-Reinforcement Learning for UAV-Aided Vehicular Wireless Networks
Jul 13, 2022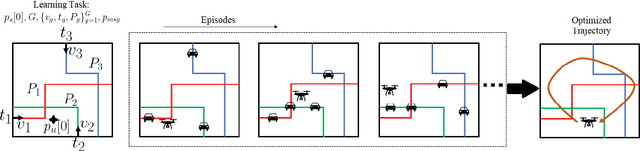
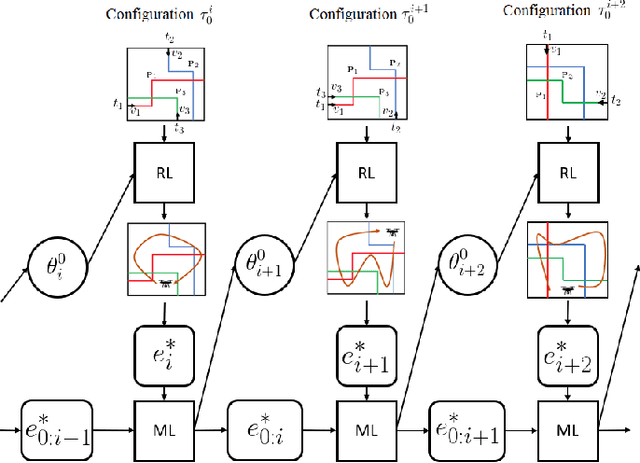
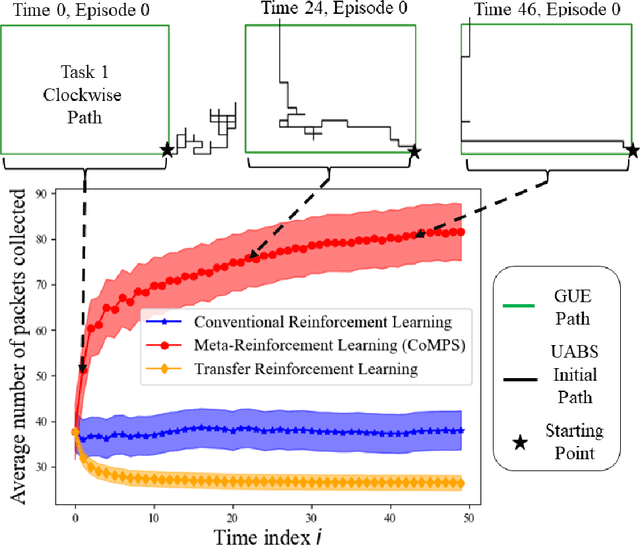
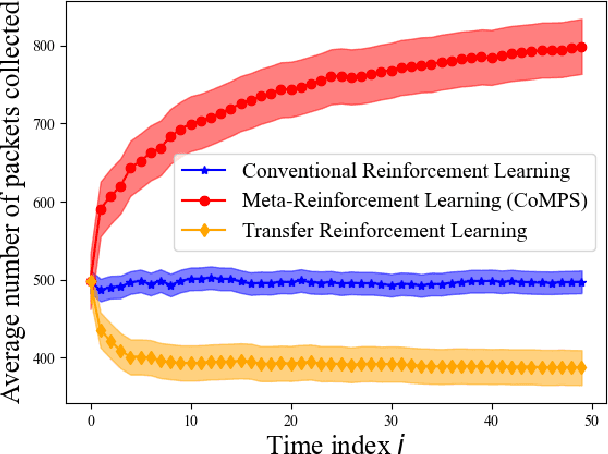
Unmanned aerial base stations (UABSs) can be deployed in vehicular wireless networks to support applications such as extended sensing via vehicle-to-everything (V2X) services. A key problem in such systems is designing algorithms that can efficiently optimize the trajectory of the UABS in order to maximize coverage. In existing solutions, such optimization is carried out from scratch for any new traffic configuration, often by means of conventional reinforcement learning (RL). In this paper, we propose the use of continual meta-RL as a means to transfer information from previously experienced traffic configurations to new conditions, with the goal of reducing the time needed to optimize the UABS's policy. Adopting the Continual Meta Policy Search (CoMPS) strategy, we demonstrate significant efficiency gains as compared to conventional RL, as well as to naive transfer learning methods.