 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook-Ahead Reasoning on Learning Platforms
Nov 18, 2025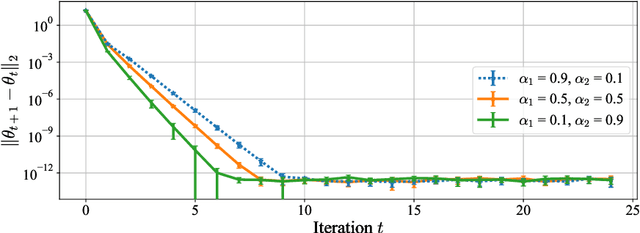
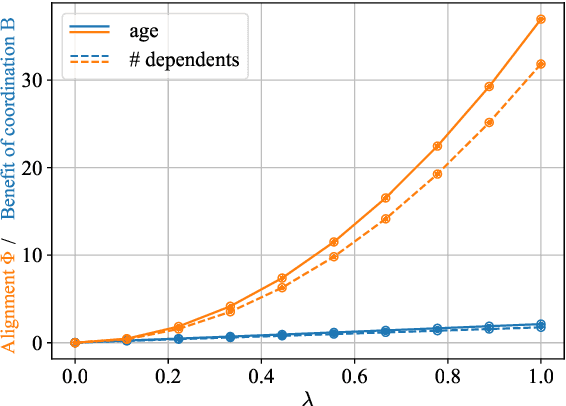
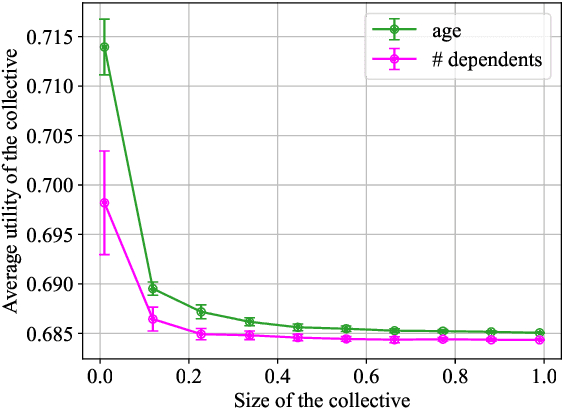
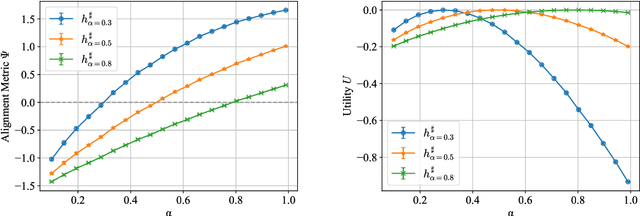
On many learning platforms, the optimization criteria guiding model training reflect the priorities of the designer rather than those of the individuals they affect. Consequently, users may act strategically to obtain more favorable outcomes, effectively contesting the platform's predictions. While past work has studied strategic user behavior on learning platforms, the focus has largely been on strategic responses to a deployed model, without considering the behavior of other users. In contrast, look-ahead reasoning takes into account that user actions are coupled, and -- at scale -- impact future predictions. Within this framework, we first formalize level-$k$ thinking, a concept from behavioral economics, where users aim to outsmart their peers by looking one step ahead. We show that, while convergence to an equilibrium is accelerated, the equilibrium remains the same, providing no benefit of higher-level reasoning for individuals in the long run. Then, we focus on collective reasoning, where users take coordinated actions by optimizing through their joint impact on the model. By contrasting collective with selfish behavior, we characterize the benefits and limits of coordination; a new notion of alignment between the learner's and the users' utilities emerges as a key concept. We discuss connections to several related mathematical frameworks, including strategic classification, performative prediction, and algorithmic collective action.
Performative Validity of Recourse Explanations
Jun 18, 2025When applicants get rejected by an algorithmic decision system, recourse explanations provide actionable suggestions for how to change their input features to get a positive evaluation. A crucial yet overlooked phenomenon is that recourse explanations are performative: When many applicants act according to their recommendations, their collective behavior may change statistical regularities in the data and, once the model is refitted, also the decision boundary. Consequently, the recourse algorithm may render its own recommendations invalid, such that applicants who make the effort of implementing their recommendations may be rejected again when they reapply. In this work, we formally characterize the conditions under which recourse explanations remain valid under performativity. A key finding is that recourse actions may become invalid if they are influenced by or if they intervene on non-causal variables. Based on our analysis, we caution against the use of standard counterfactual explanations and causal recourse methods, and instead advocate for recourse methods that recommend actions exclusively on causal variables.
Adjusting Pretrained Backbones for Performativity
Oct 06, 2024



With the widespread deployment of deep learning models, they influence their environment in various ways. The induced distribution shifts can lead to unexpected performance degradation in deployed models. Existing methods to anticipate performativity typically incorporate information about the deployed model into the feature vector when predicting future outcomes. While enjoying appealing theoretical properties, modifying the input dimension of the prediction task is often not practical. To address this, we propose a novel technique to adjust pretrained backbones for performativity in a modular way, achieving better sample efficiency and enabling the reuse of existing deep learning assets. Focusing on performative label shift, the key idea is to train a shallow adapter module to perform a Bayes-optimal label shift correction to the backbone's logits given a sufficient statistic of the model to be deployed. As such, our framework decouples the construction of input-specific feature embeddings from the mechanism governing performativity. Motivated by dynamic benchmarking as a use-case, we evaluate our approach under adversarial sampling, for vision and language tasks. We show how it leads to smaller loss along the retraining trajectory and enables us to effectively select among candidate models to anticipate performance degradations. More broadly, our work provides a first baseline for addressing performativity in deep learning.
Evaluating language models as risk scores
Jul 19, 2024



Current question-answering benchmarks predominantly focus on accuracy in realizable prediction tasks. Conditioned on a question and answer-key, does the most likely token match the ground truth? Such benchmarks necessarily fail to evaluate language models' ability to quantify outcome uncertainty. In this work, we focus on the use of language models as risk scores for unrealizable prediction tasks. We introduce folktexts, a software package to systematically generate risk scores using large language models, and evaluate them against benchmark prediction tasks. Specifically, the package derives natural language tasks from US Census data products, inspired by popular tabular data benchmarks. A flexible API allows for any task to be constructed out of 28 census features whose values are mapped to prompt-completion pairs. We demonstrate the utility of folktexts through a sweep of empirical insights on 16 recent large language models, inspecting risk scores, calibration curves, and diverse evaluation metrics. We find that zero-shot risk sores have high predictive signal while being widely miscalibrated: base models overestimate outcome uncertainty, while instruction-tuned models underestimate uncertainty and generate over-confident risk scores.
An engine not a camera: Measuring performative power of online search
May 29, 2024



The power of digital platforms is at the center of major ongoing policy and regulatory efforts. To advance existing debates, we designed and executed an experiment to measure the power of online search providers, building on the recent definition of performative power. Instantiated in our setting, performative power quantifies the ability of a search engine to steer web traffic by rearranging results. To operationalize this definition we developed a browser extension that performs unassuming randomized experiments in the background. These randomized experiments emulate updates to the search algorithm and identify the causal effect of different content arrangements on clicks. We formally relate these causal effects to performative power. Analyzing tens of thousands of clicks, we discuss what our robust quantitative findings say about the power of online search engines. More broadly, we envision our work to serve as a blueprint for how performative power and online experiments can be integrated with future investigations into the economic power of digital platforms.
Performative Prediction: Past and Future
Oct 25, 2023Predictions in the social world generally influence the target of prediction, a phenomenon known as performativity. Self-fulfilling and self-negating predictions are examples of performativity. Of fundamental importance to economics, finance, and the social sciences, the notion has been absent from the development of machine learning. In machine learning applications, performativity often surfaces as distribution shift. A predictive model deployed on a digital platform, for example, influences consumption and thereby changes the data-generating distribution. We survey the recently founded area of performative prediction that provides a definition and conceptual framework to study performativity in machine learning. A consequence of performative prediction is a natural equilibrium notion that gives rise to new optimization challenges. Another consequence is a distinction between learning and steering, two mechanisms at play in performative prediction. The notion of steering is in turn intimately related to questions of power in digital markets. We review the notion of performative power that gives an answer to the question how much a platform can steer participants through its predictions. We end on a discussion of future directions, such as the role that performativity plays in contesting algorithmic systems.
Questioning the Survey Responses of Large Language Models
Jun 13, 2023



As large language models increase in capability, researchers have started to conduct surveys of all kinds on these models with varying scientific motivations. In this work, we examine what we can learn from a model's survey responses on the basis of the well-established American Community Survey (ACS) by the U.S. Census Bureau. Evaluating more than a dozen different models, varying in size from a few hundred million to ten billion parameters, hundreds of thousands of times each on questions from the ACS, we systematically establish two dominant patterns. First, smaller models have a significant position and labeling bias, for example, towards survey responses labeled with the letter "A". This A-bias diminishes, albeit slowly, as model size increases. Second, when adjusting for this labeling bias through randomized answer ordering, models still do not trend toward US population statistics or those of any cognizable population. Rather, models across the board trend toward uniformly random aggregate statistics over survey responses. This pattern is robust to various different ways of prompting the model, including what is the de-facto standard. Our findings demonstrate that aggregate statistics of a language model's survey responses lack the signals found in human populations. This absence of statistical signal cautions about the use of survey responses from large language models at present time.
Collaborative Learning via Prediction Consensus
May 29, 2023We consider a collaborative learning setting where each agent's goal is to improve their own model by leveraging the expertise of collaborators, in addition to their own training data. To facilitate the exchange of expertise among agents, we propose a distillation-based method leveraging unlabeled auxiliary data, which is pseudo-labeled by the collective. Central to our method is a trust weighting scheme which serves to adaptively weigh the influence of each collaborator on the pseudo-labels until a consensus on how to label the auxiliary data is reached. We demonstrate that our collaboration scheme is able to significantly boost individual model's performance with respect to the global distribution, compared to local training. At the same time, the adaptive trust weights can effectively identify and mitigate the negative impact of bad models on the collective. We find that our method is particularly effective in the presence of heterogeneity among individual agents, both in terms of training data as well as model architectures.
Causal Inference out of Control: Estimating the Steerability of Consumption
Feb 10, 2023



Regulators and academics are increasingly interested in the causal effect that algorithmic actions of a digital platform have on consumption. We introduce a general causal inference problem we call the steerability of consumption that abstracts many settings of interest. Focusing on observational designs and exploiting the structure of the problem, we exhibit a set of assumptions for causal identifiability that significantly weaken the often unrealistic overlap assumptions of standard designs. The key novelty of our approach is to explicitly model the dynamics of consumption over time, viewing the platform as a controller acting on a dynamical system. From this dynamical systems perspective, we are able to show that exogenous variation in consumption and appropriately responsive algorithmic control actions are sufficient for identifying steerability of consumption. Our results illustrate the fruitful interplay of control theory and causal inference, which we illustrate with examples from econometrics, macroeconomics, and machine learning.
Algorithmic Collective Action in Machine Learning
Feb 08, 2023



We initiate a principled study of algorithmic collective action on digital platforms that deploy machine learning algorithms. We propose a simple theoretical model of a collective interacting with a firm's learning algorithm. The collective pools the data of participating individuals and executes an algorithmic strategy by instructing participants how to modify their own data to achieve a collective goal. We investigate the consequences of this model in three fundamental learning-theoretic settings: the case of a nonparametric optimal learning algorithm, a parametric risk minimizer, and gradient-based optimization. In each setting, we come up with coordinated algorithmic strategies and characterize natural success criteria as a function of the collective's size. Complementing our theory, we conduct systematic experiments on a skill classification task involving tens of thousands of resumes from a gig platform for freelancers. Through more than two thousand model training runs of a BERT-like language model, we see a striking correspondence emerge between our empirical observations and the predictions made by our theory. Taken together, our theory and experiments broadly support the conclusion that algorithmic collectives of exceedingly small fractional size can exert significant control over a platform's learning algorithm.