 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph-Time Convolutional Neural Networks
Mar 02, 2021
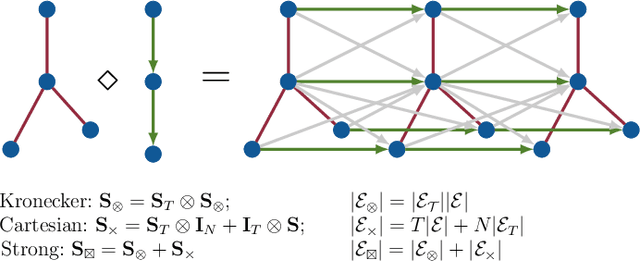
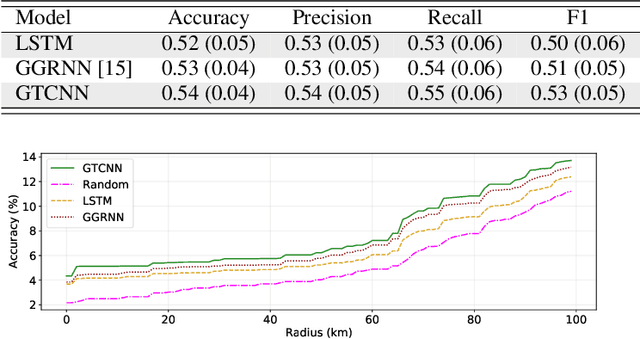
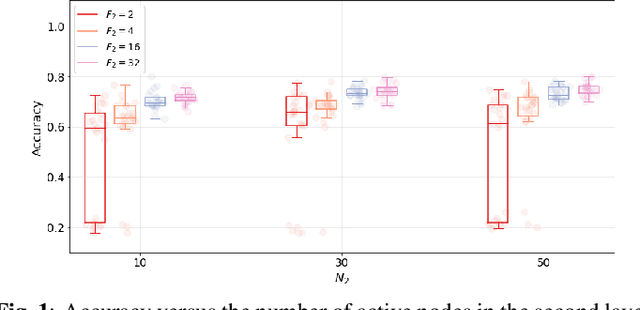
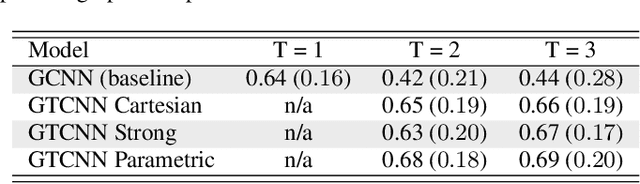
Spatiotemporal data can be represented as a process over a graph, which captures their spatial relationships either explicitly or implicitly. How to leverage such a structure for learning representations is one of the key challenges when working with graphs. In this paper, we represent the spatiotemporal relationships through product graphs and develop a first principle graph-time convolutional neural network (GTCNN). The GTCNN is a compositional architecture with each layer comprising a graph-time convolutional module, a graph-time pooling module, and a nonlinearity. We develop a graph-time convolutional filter by following the shift-and-sum principles of the convolutional operator to learn higher-level features over the product graph. The product graph itself is parametric so that we can learn also the spatiotemporal coupling from data. We develop a zero-pad pooling that preserves the spatial graph (the prior about the data) while reducing the number of active nodes and the parameters. Experimental results with synthetic and real data corroborate the different components and compare with baseline and state-of-the-art solutions.
SOMTimeS: Self Organizing Maps for Time Series Clustering and its Application to Serious Illness Conversations
Aug 26, 2021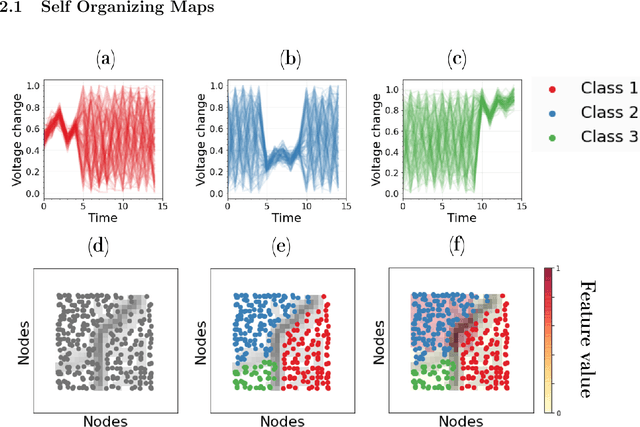
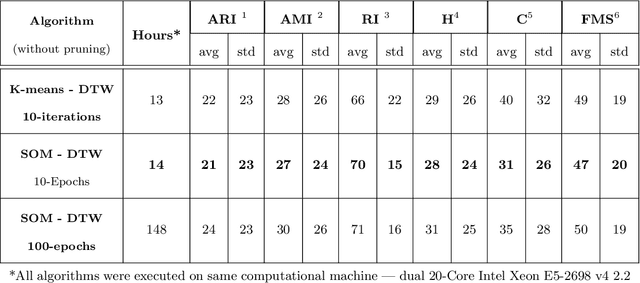
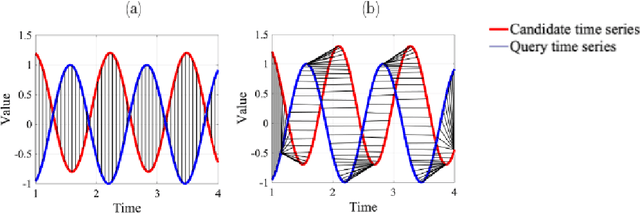
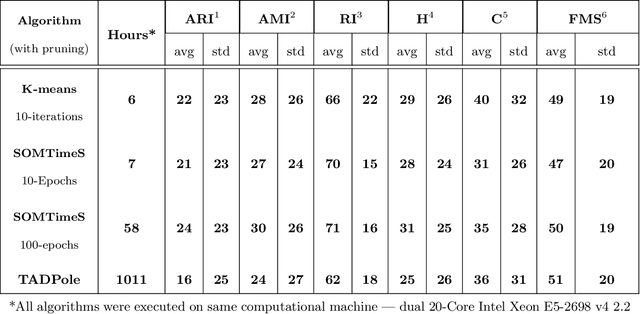
There is an increasing demand for scalable algorithms capable of clustering and analyzing large time series datasets. The Kohonen self-organizing map (SOM) is a type of unsupervised artificial neural network for visualizing and clustering complex data, reducing the dimensionality of data, and selecting influential features. Like all clustering methods, the SOM requires a measure of similarity between input data (in this work time series). Dynamic time warping (DTW) is one such measure, and a top performer given that it accommodates the distortions when aligning time series. Despite its use in clustering, DTW is limited in practice because it is quadratic in runtime complexity with the length of the time series data. To address this, we present a new DTW-based clustering method, called SOMTimeS (a Self-Organizing Map for TIME Series), that scales better and runs faster than other DTW-based clustering algorithms, and has similar performance accuracy. The computational performance of SOMTimeS stems from its ability to prune unnecessary DTW computations during the SOM's training phase. We also implemented a similar pruning strategy for K-means for comparison with one of the top performing clustering algorithms. We evaluated the pruning effectiveness, accuracy, execution time and scalability on 112 benchmark time series datasets from the University of California, Riverside classification archive. We showed that for similar accuracy, the speed-up achieved for SOMTimeS and K-means was 1.8x on average; however, rates varied between 1x and 18x depending on the dataset. SOMTimeS and K-means pruned 43% and 50% of the total DTW computations, respectively. We applied SOMtimeS to natural language conversation data collected as part of a large healthcare cohort study of patient-clinician serious illness conversations to demonstrate the algorithm's utility with complex, temporally sequenced phenomena.
FastATDC: Fast Anomalous Trajectory Detection and Classification
Jul 23, 2022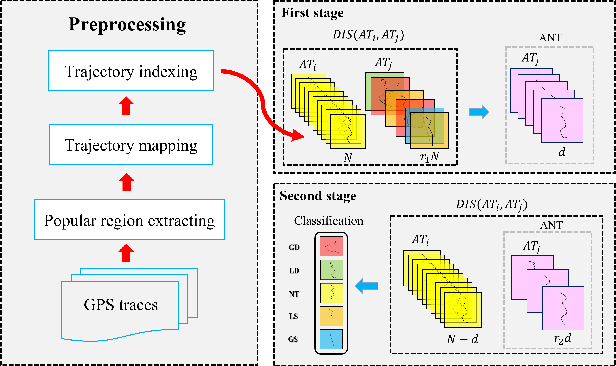
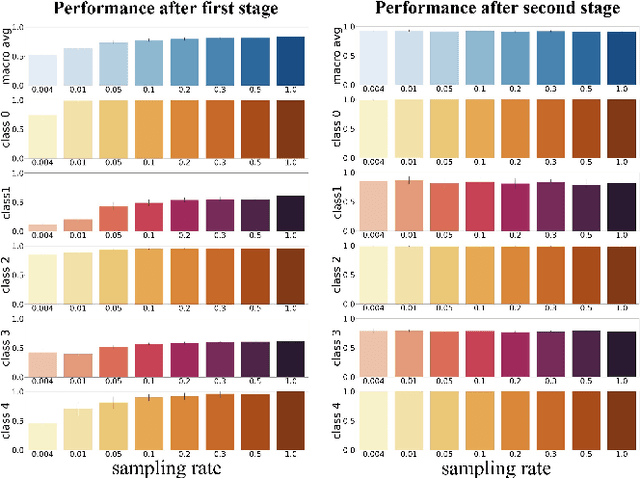
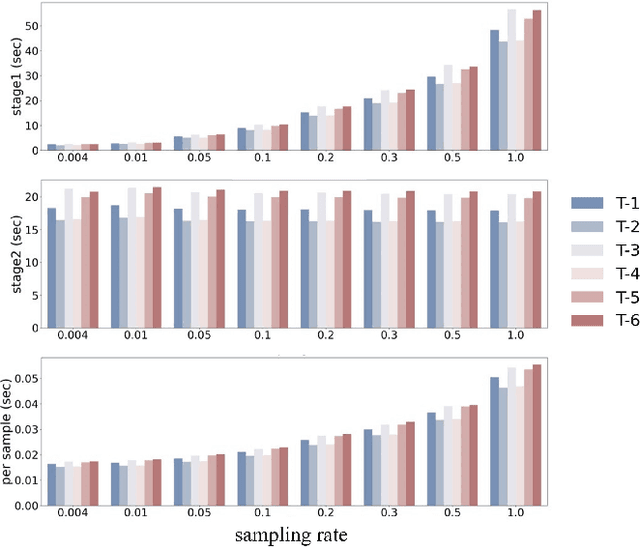
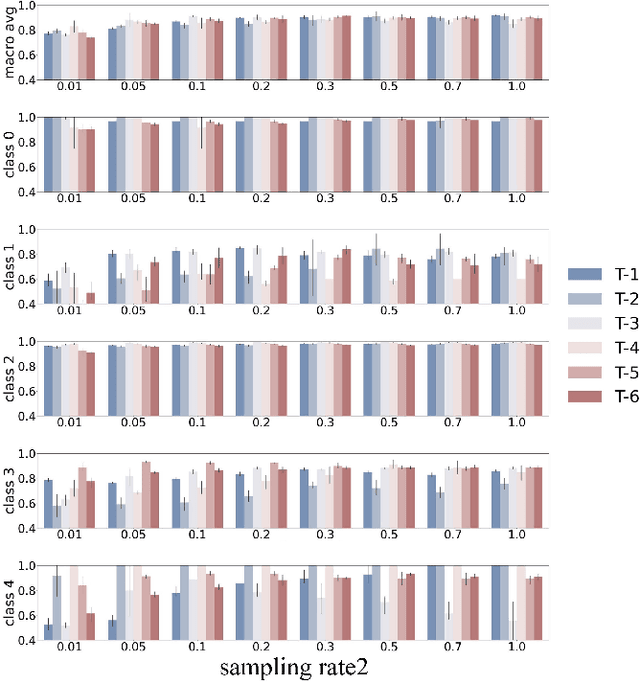
Automated detection of anomalous trajectories is an important problem with considerable applications in intelligent transportation systems. Many existing studies have focused on distinguishing anomalous trajectories from normal trajectories, ignoring the large differences between anomalous trajectories. A recent study has made great progress in identifying abnormal trajectory patterns and proposed a two-stage algorithm for anomalous trajectory detection and classification (ATDC). This algorithm has excellent performance but suffers from a few limitations, such as high time complexity and poor interpretation. Here, we present a careful theoretical and empirical analysis of the ATDC algorithm, showing that the calculation of anomaly scores in both stages can be simplified, and that the second stage of the algorithm is much more important than the first stage. Hence, we develop a FastATDC algorithm that introduces a random sampling strategy in both stages. Experimental results show that FastATDC is 10 to 20 times faster than ATDC on real datasets. Moreover, FastATDC outperforms the baseline algorithms and is comparable to the ATDC algorithm.
First Glance Diagnosis: Brain Disease Classification with Single fMRI Volume
Aug 10, 2022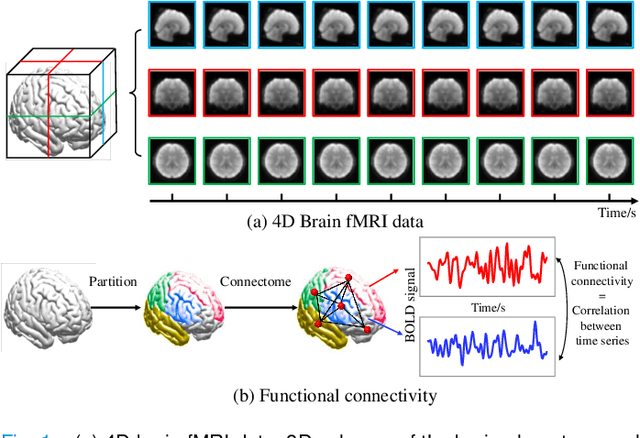
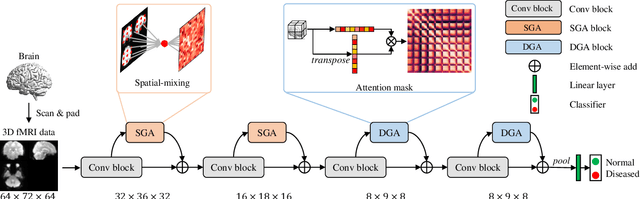
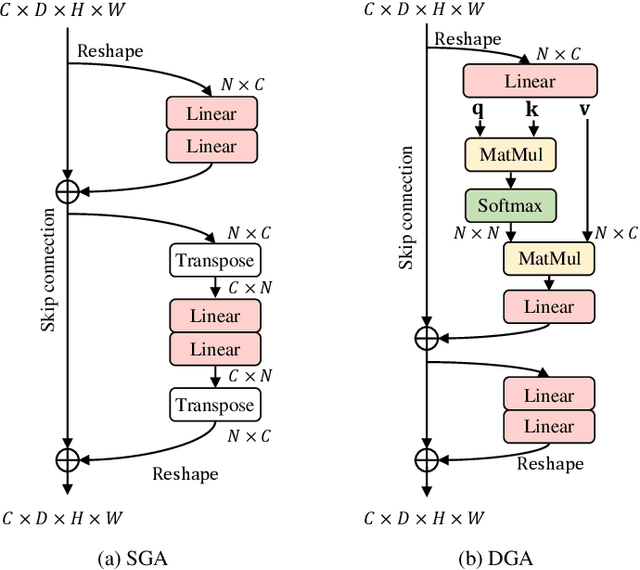

In neuroimaging analysis, functional magnetic resonance imaging (fMRI) can well assess brain function changes for brain diseases with no obvious structural lesions. So far, most deep-learning-based fMRI studies take functional connectivity as the basic feature in disease classification. However, functional connectivity is often calculated based on time series of predefined regions of interest and neglects detailed information contained in each voxel, which may accordingly deteriorate the performance of diagnostic models. Another methodological drawback is the limited sample size for the training of deep models. In this study, we propose BrainFormer, a general hybrid Transformer architecture for brain disease classification with single fMRI volume to fully exploit the voxel-wise details with sufficient data dimensions and sizes. BrainFormer is constructed by modeling the local cues within each voxel with 3D convolutions and capturing the global relations among distant regions with two global attention blocks. The local and global cues are aggregated in BrainFormer by a single-stream model. To handle multisite data, we propose a normalization layer to normalize the data into identical distribution. Finally, a Gradient-based Localization-map Visualization method is utilized for locating the possible disease-related biomarker. We evaluate BrainFormer on five independently acquired datasets including ABIDE, ADNI, MPILMBB, ADHD-200 and ECHO, with diseases of autism, Alzheimer's disease, depression, attention deficit hyperactivity disorder, and headache disorders. The results demonstrate the effectiveness and generalizability of BrainFormer for multiple brain diseases diagnosis. BrainFormer may promote neuroimaging-based precision diagnosis in clinical practice and motivate future study in fMRI analysis. Code is available at: https://github.com/ZiyaoZhangforPCL/BrainFormer.
Interplay between Distributed AI Workflow and URLLC
Aug 02, 2022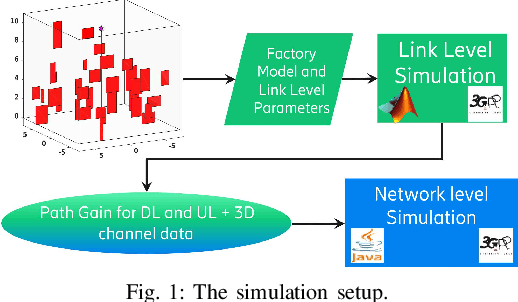
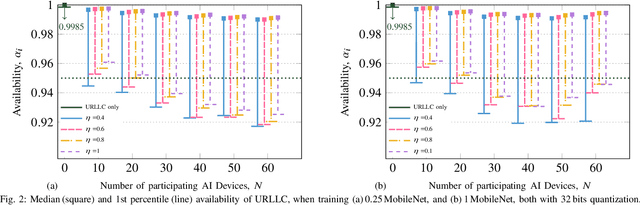
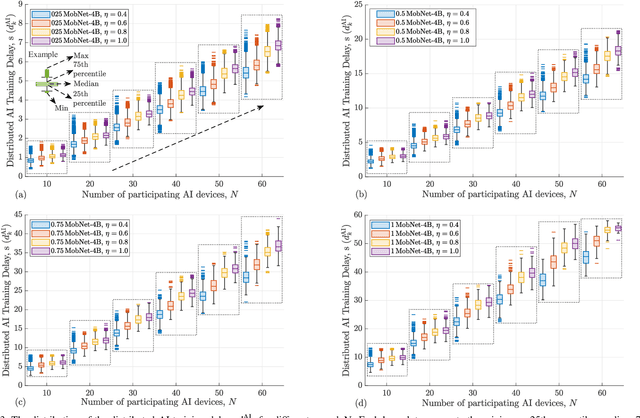

Distributed artificial intelligence (AI) has recently accomplished tremendous breakthroughs in various communication services, ranging from fault-tolerant factory automation to smart cities. When distributed learning is run over a set of wireless connected devices, random channel fluctuations, and the incumbent services simultaneously running on the same network affect the performance of distributed learning. In this paper, we investigate the interplay between distributed AI workflow and ultra-reliable low latency communication (URLLC) services running concurrently over a network. Using 3GPP compliant simulations in a factory automation use case, we show the impact of various distributed AI settings (e.g., model size and the number of participating devices) on the convergence time of distributed AI and the application layer performance of URLLC. Unless we leverage the existing 5G-NR quality of service handling mechanisms to separate the traffic from the two services, our simulation results show that the impact of distributed AI on the availability of the URLLC devices is significant. Moreover, with proper setting of distributed AI (e.g., proper user selection), we can substantially reduce network resource utilization, leading to lower latency for distributed AI and higher availability for the URLLC users. Our results provide important insights for future 6G and AI standardization.
Surrey System for DCASE 2022 Task 5: Few-shot Bioacoustic Event Detection with Segment-level Metric Learning
Jul 21, 2022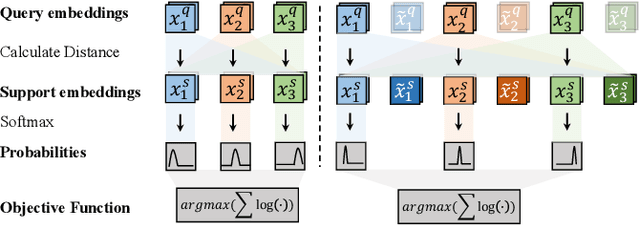

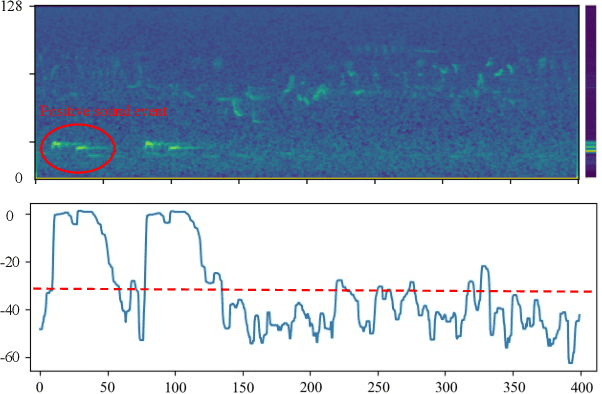

Few-shot audio event detection is a task that detects the occurrence time of a novel sound class given a few examples. In this work, we propose a system based on segment-level metric learning for the DCASE 2022 challenge of few-shot bioacoustic event detection (task 5). We make better utilization of the negative data within each sound class to build the loss function, and use transductive inference to gain better adaptation on the evaluation set. For the input feature, we find the per-channel energy normalization concatenated with delta mel-frequency cepstral coefficients to be the most effective combination. We also introduce new data augmentation and post-processing procedures for this task. Our final system achieves an f-measure of 68.74 on the DCASE task 5 validation set, outperforming the baseline performance of 29.5 by a large margin. Our system is fully open-sourced at https://github.com/haoheliu/DCASE_2022_Task_5.
Overlooked Poses Actually Make Sense: Distilling Privileged Knowledge for Human Motion Prediction
Aug 02, 2022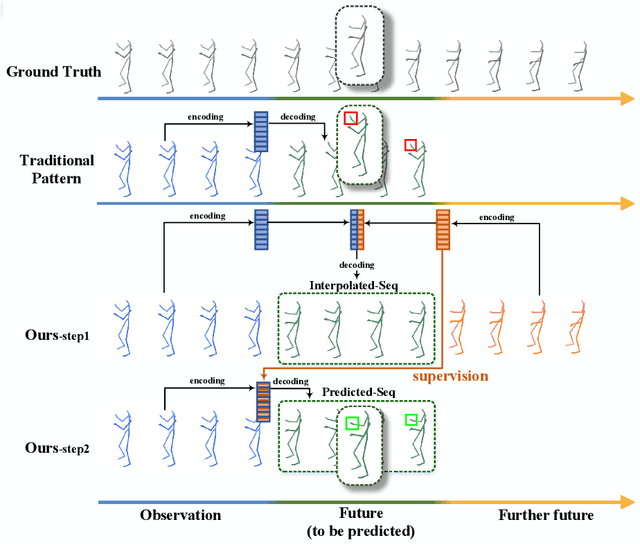
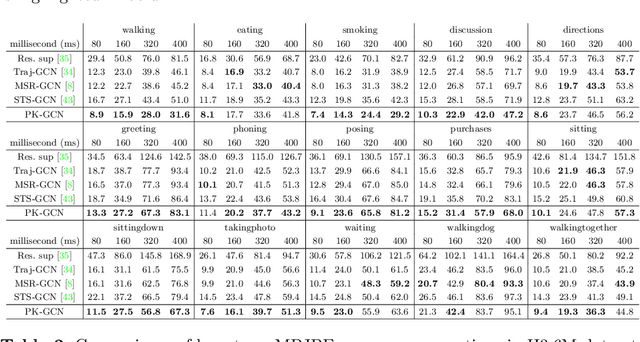
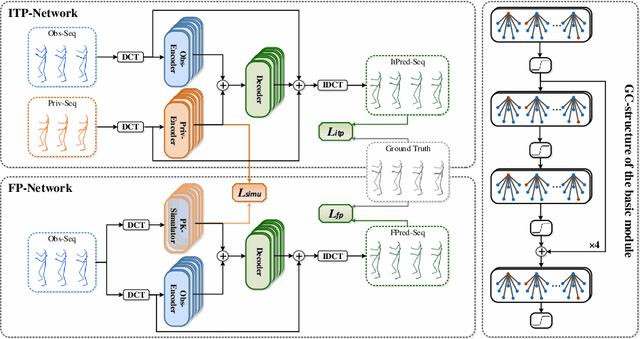
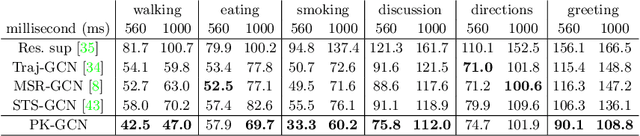
Previous works on human motion prediction follow the pattern of building a mapping relation between the sequence observed and the one to be predicted. However, due to the inherent complexity of multivariate time series data, it still remains a challenge to find the extrapolation relation between motion sequences. In this paper, we present a new prediction pattern, which introduces previously overlooked human poses, to implement the prediction task from the view of interpolation. These poses exist after the predicted sequence, and form the privileged sequence. To be specific, we first propose an InTerPolation learning Network (ITP-Network) that encodes both the observed sequence and the privileged sequence to interpolate the in-between predicted sequence, wherein the embedded Privileged-sequence-Encoder (Priv-Encoder) learns the privileged knowledge (PK) simultaneously. Then, we propose a Final Prediction Network (FP-Network) for which the privileged sequence is not observable, but is equipped with a novel PK-Simulator that distills PK learned from the previous network. This simulator takes as input the observed sequence, but approximates the behavior of Priv-Encoder, enabling FP-Network to imitate the interpolation process. Extensive experimental results demonstrate that our prediction pattern achieves state-of-the-art performance on benchmarked H3.6M, CMU-Mocap and 3DPW datasets in both short-term and long-term predictions.
A novel approach to rating transition modelling via Machine Learning and SDEs on Lie groups
May 31, 2022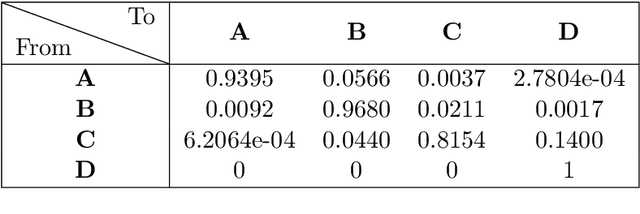
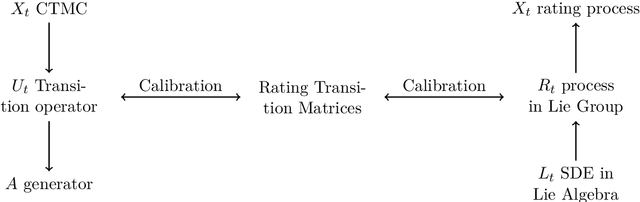

In this paper, we introduce a novel methodology to model rating transitions with a stochastic process. To introduce stochastic processes, whose values are valid rating matrices, we noticed the geometric properties of stochastic matrices and its link to matrix Lie groups. We give a gentle introduction to this topic and demonstrate how It\^o-SDEs in R will generate the desired model for rating transitions. To calibrate the rating model to historical data, we use a Deep-Neural-Network (DNN) called TimeGAN to learn the features of a time series of historical rating matrices. Then, we use this DNN to generate synthetic rating transition matrices. Afterwards, we fit the moments of the generated rating matrices and the rating process at specific time points, which results in a good fit. After calibration, we discuss the quality of the calibrated rating transition process by examining some properties that a time series of rating matrices should satisfy, and we will see that this geometric approach works very well.
Adapting Triplet Importance of Implicit Feedback for Personalized Recommendation
Aug 05, 2022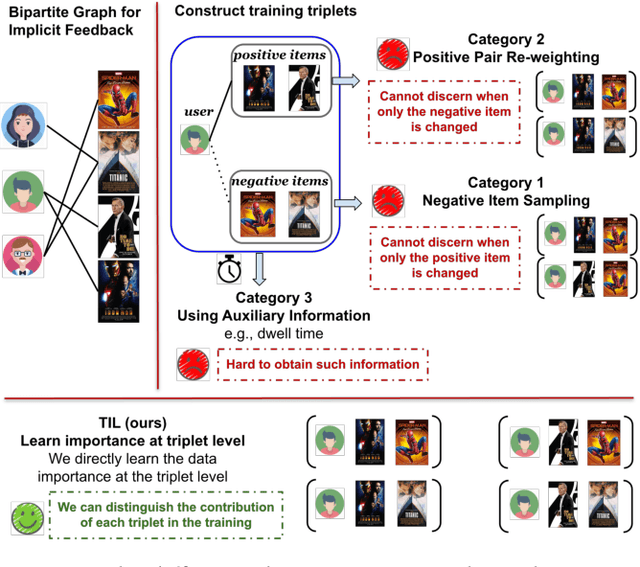
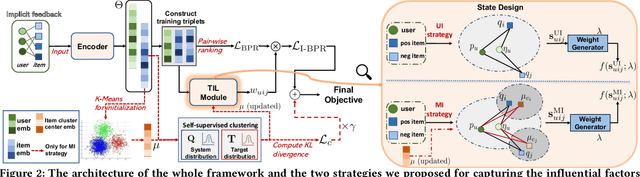
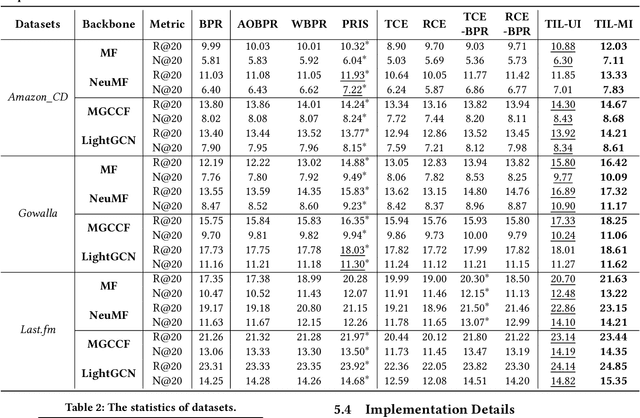
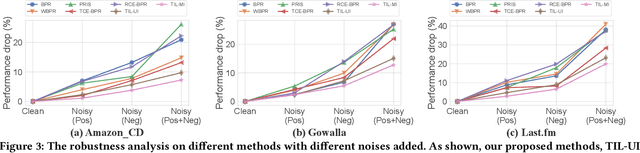
Implicit feedback is frequently used for developing personalized recommendation services due to its ubiquity and accessibility in real-world systems. In order to effectively utilize such information, most research adopts the pairwise ranking method on constructed training triplets (user, positive item, negative item) and aims to distinguish between positive items and negative items for each user. However, most of these methods treat all the training triplets equally, which ignores the subtle difference between different positive or negative items. On the other hand, even though some other works make use of the auxiliary information (e.g., dwell time) of user behaviors to capture this subtle difference, such auxiliary information is hard to obtain. To mitigate the aforementioned problems, we propose a novel training framework named Triplet Importance Learning (TIL), which adaptively learns the importance score of training triplets. We devise two strategies for the importance score generation and formulate the whole procedure as a bilevel optimization, which does not require any rule-based design. We integrate the proposed training procedure with several Matrix Factorization (MF)- and Graph Neural Network (GNN)-based recommendation models, demonstrating the compatibility of our framework. Via a comparison using three real-world datasets with many state-of-the-art methods, we show that our proposed method outperforms the best existing models by 3-21\% in terms of Recall@k for the top-k recommendation.
Classification of Time-Series Data Using Boosted Decision Trees
Oct 01, 2021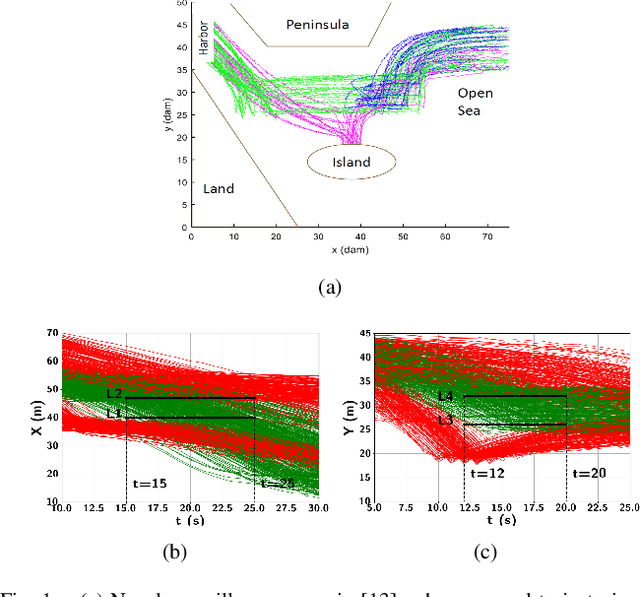
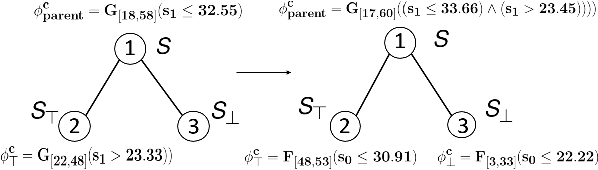
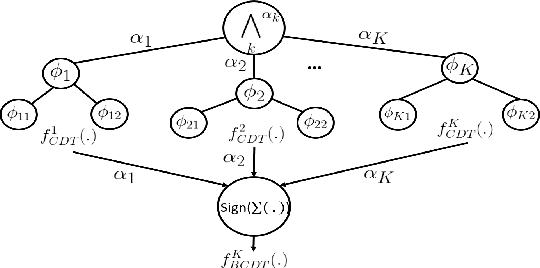
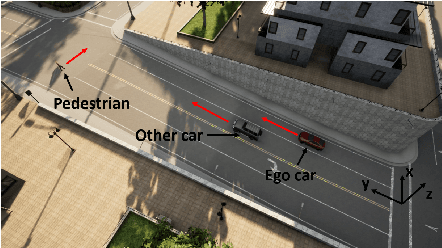
Time-series data classification is central to the analysis and control of autonomous systems, such as robots and self-driving cars. Temporal logic-based learning algorithms have been proposed recently as classifiers of such data. However, current frameworks are either inaccurate for real-world applications, such as autonomous driving, or they generate long and complicated formulae that lack interpretability. To address these limitations, we introduce a novel learning method, called Boosted Concise Decision Trees (BCDTs), to generate binary classifiers that are represented as Signal Temporal Logic (STL) formulae. Our algorithm leverages an ensemble of Concise Decision Trees (CDTs) to improve the classification performance, where each CDT is a decision tree that is empowered by a set of techniques to generate simpler formulae and improve interpretability. The effectiveness and classification performance of our algorithm are evaluated on naval surveillance and urban-driving case studies.