 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recovering the Graph Underlying Networked Dynamical Systems under Partial Observability: A Deep Learning Approach
Aug 08, 2022
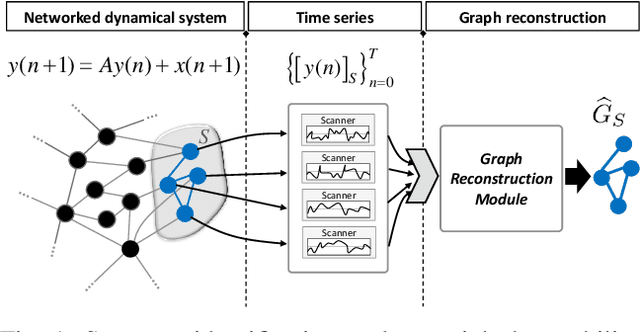
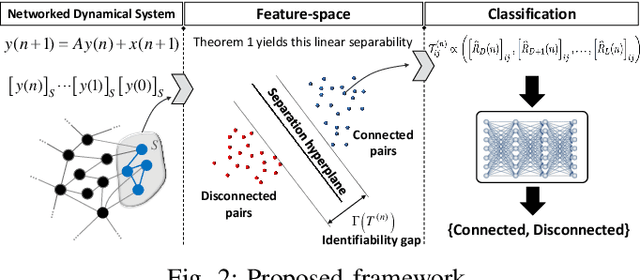
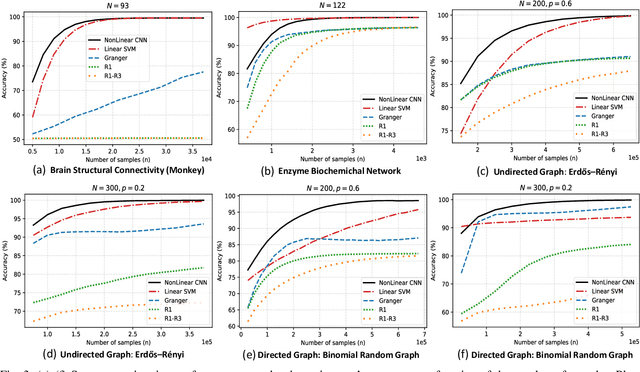
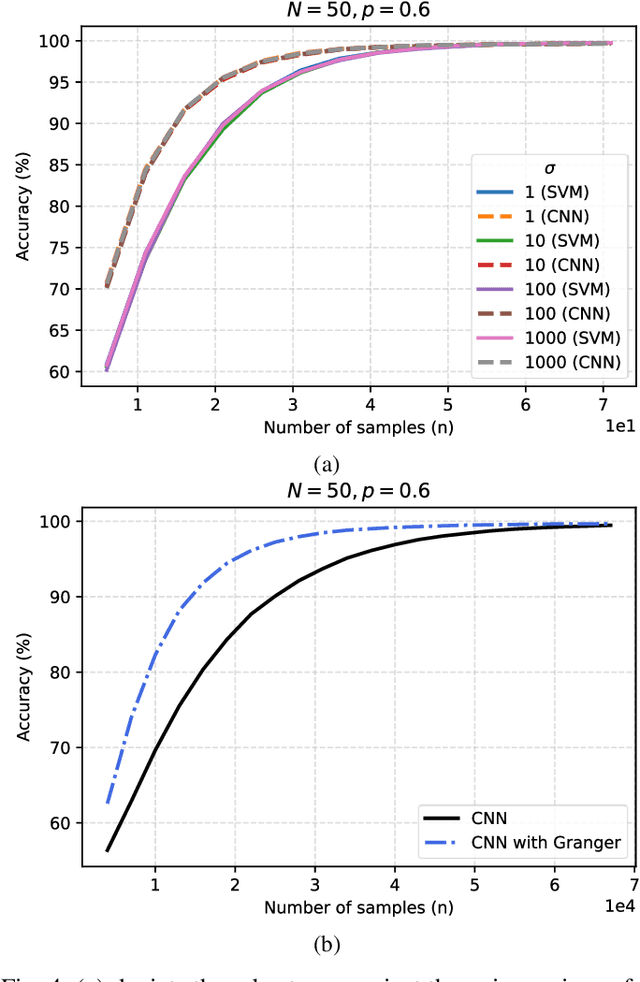
We study the problem of graph structure identification, i.e., of recovering the graph of dependencies among time series. We model these time series data as components of the state of linear stochastic networked dynamical systems. We assume partial observability, where the state evolution of only a subset of nodes comprising the network is observed. We devise a new feature vector computed from the observed time series and prove that these features are linearly separable, i.e., there exists a hyperplane that separates the cluster of features associated with connected pairs of nodes from those associated with disconnected pairs. This renders the features amenable to train a variety of classifiers to perform causal inference. In particular, we use these features to train Convolutional Neural Networks (CNNs). The resulting causal inference mechanism outperforms state-of-the-art counterparts w.r.t. sample-complexity. The trained CNNs generalize well over structurally distinct networks (dense or sparse) and noise-level profiles. Remarkably, they also generalize well to real-world networks while trained over a synthetic network (realization of a random graph). Finally, the proposed method consistently reconstructs the graph in a pairwise manner, that is, by deciding if an edge or arrow is present or absent in each pair of nodes, from the corresponding time series of each pair. This fits the framework of large-scale systems, where observation or processing of all nodes in the network is prohibitive.
A Dataset for Answering Time-Sensitive Questions
Aug 13, 2021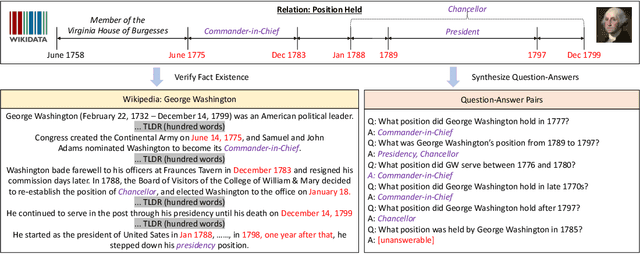
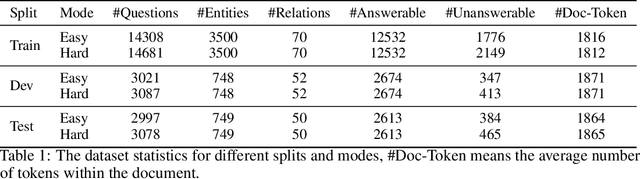
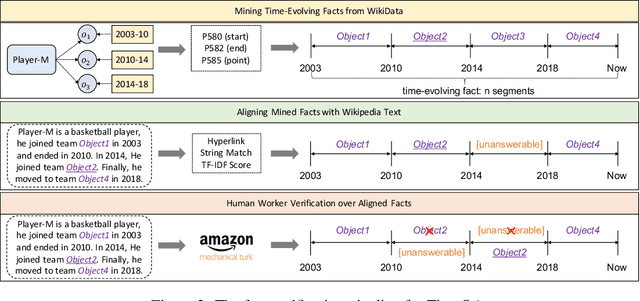
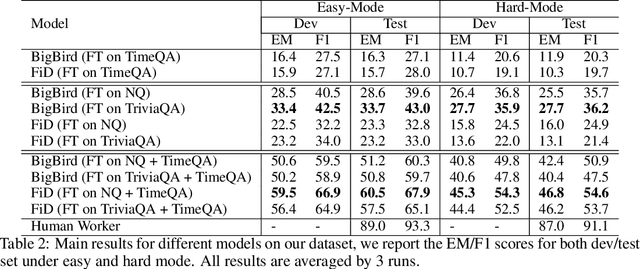
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses two novel challenges: 1) the model needs to understand both explicit and implicit mention of time information in the long document, 2) the model needs to perform temporal reasoning like comparison, addition, subtraction. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform robust temporal understanding and reasoning. Therefore, we believe that our dataset could serve as a benchmark to empower future studies in temporal reasoning. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
Liquid State Machine-Empowered Reflection Tracking in RIS-Aided THz Communications
Aug 08, 2022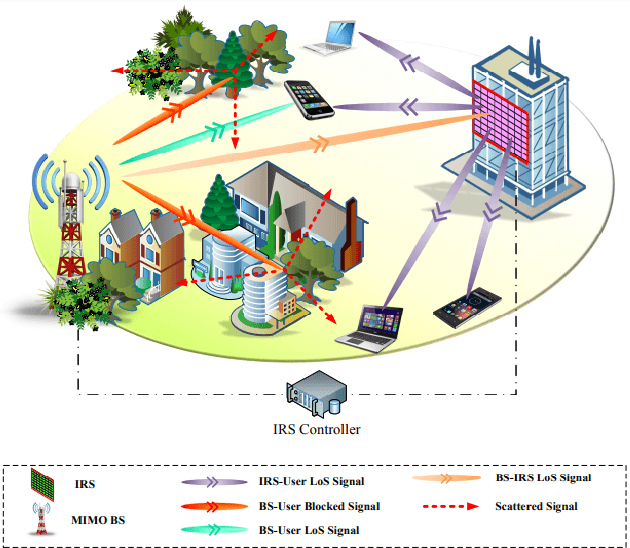
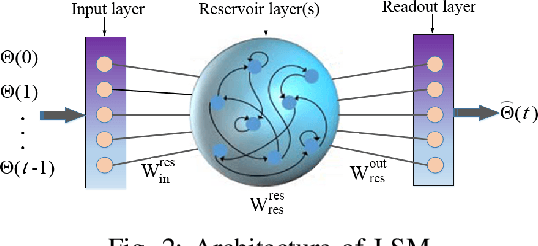
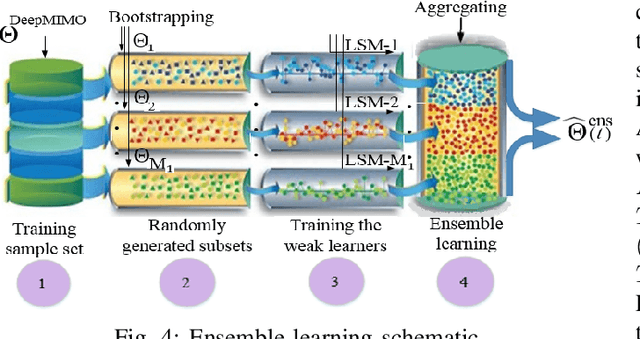
Passive beamforming in reconfigurable intelligent surfaces (RISs) enables a feasible and efficient way of communication when the RIS reflection coefficients are precisely adjusted. In this paper, we present a framework to track the RIS reflection coefficients with the aid of deep learning from a time-series prediction perspective in a terahertz (THz) communication system. The proposed framework achieves a two-step enhancement over the similar learning-driven counterparts. Specifically, in the first step, we train a liquid state machine (LSM) to track the historical RIS reflection coefficients at prior time steps (known as a time-series sequence) and predict their upcoming time steps. We also fine-tune the trained LSM through Xavier initialization technique to decrease the prediction variance, thus resulting in a higher prediction accuracy. In the second step, we use ensemble learning technique which leverages on the prediction power of multiple LSMs to minimize the prediction variance and improve the precision of the first step. It is numerically demonstrated that, in the first step, employing the Xavier initialization technique to fine-tune the LSM results in at most 26% lower LSM prediction variance and as much as 46% achievable spectral efficiency (SE) improvement over the existing counterparts, when an RIS of size 11x11 is deployed. In the second step, under the same computational complexity of training a single LSM, the ensemble learning with multiple LSMs degrades the prediction variance of a single LSM up to 66% and improves the system achievable SE at most 54%.
Time Series Analysis of Blockchain-Based Cryptocurrency Price Changes
Feb 19, 2022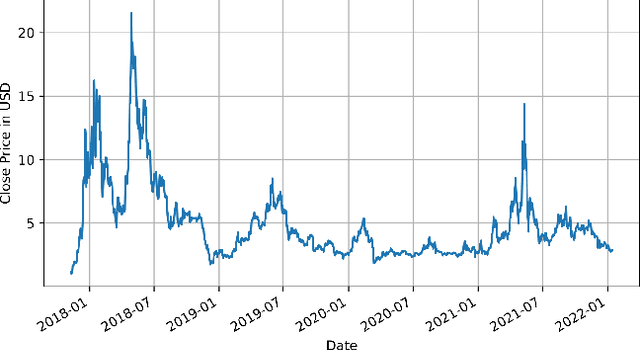
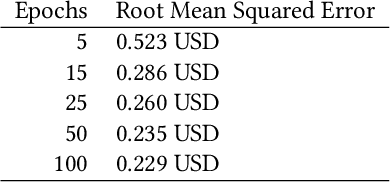
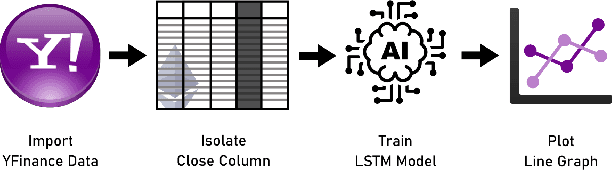

In this paper we apply neural networks and Artificial Intelligence (AI) to historical records of high-risk cryptocurrency coins to train a prediction model that guesses their price. This paper's code contains Jupyter notebooks, one of which outputs a timeseries graph of any cryptocurrency price once a CSV file of the historical data is inputted into the program. Another Jupyter notebook trains an LSTM, or a long short-term memory model, to predict a cryptocurrency's closing price. The LSTM is fed the close price, which is the price that the currency has at the end of the day, so it can learn from those values. The notebook creates two sets: a training set and a test set to assess the accuracy of the results. The data is then normalized using manual min-max scaling so that the model does not experience any bias; this also enhances the performance of the model. Then, the model is trained using three layers -- an LSTM, dropout, and dense layer-minimizing the loss through 50 epochs of training; from this training, a recurrent neural network (RNN) is produced and fitted to the training set. Additionally, a graph of the loss over each epoch is produced, with the loss minimizing over time. Finally, the notebook plots a line graph of the actual currency price in red and the predicted price in blue. The process is then repeated for several more cryptocurrencies to compare prediction models. The parameters for the LSTM, such as number of epochs and batch size, are tweaked to try and minimize the root mean square error.
SoLo T-DIRL: Socially-Aware Dynamic Local Planner based on Trajectory-Ranked Deep Inverse Reinforcement Learning
Sep 16, 2022
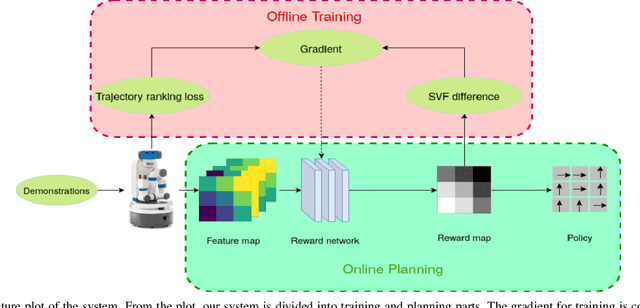

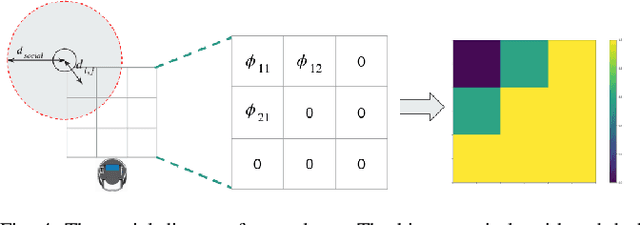
This work proposes a new framework for a socially-aware dynamic local planner in crowded environments by building on the recently proposed Trajectory-ranked Maximum Entropy Deep Inverse Reinforcement Learning (T-MEDIRL). To address the social navigation problem, our multi-modal learning planner explicitly considers social interaction factors, as well as social-awareness factors into T-MEDIRL pipeline to learn a reward function from human demonstrations. Moreover, we propose a novel trajectory ranking score using the sudden velocity change of pedestrians around the robot to address the sub-optimality in human demonstrations. Our evaluation shows that this method can successfully make a robot navigate in a crowded social environment and outperforms the state-of-art social navigation methods in terms of the success rate, navigation time, and invasion rate.
Accelerating hypersonic reentry simulations using deep learning-based hybridization (with guarantees)
Sep 27, 2022

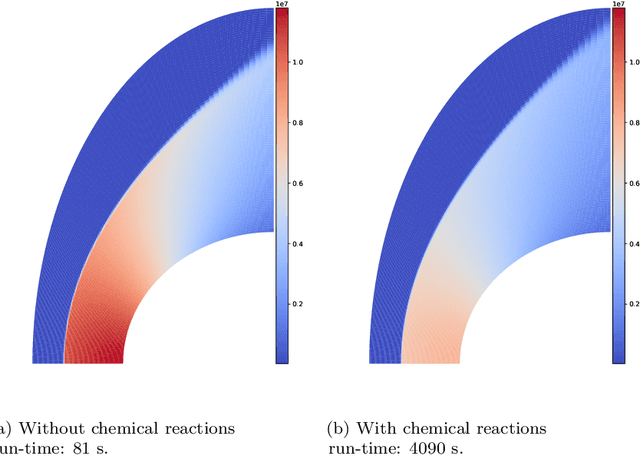
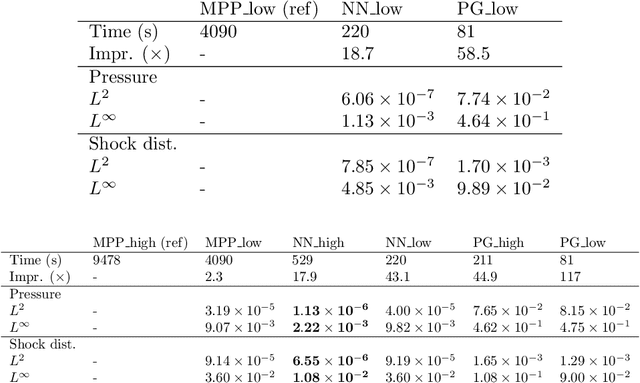
In this paper, we are interested in the acceleration of numerical simulations. We focus on a hypersonic planetary reentry problem whose simulation involves coupling fluid dynamics and chemical reactions. Simulating chemical reactions takes most of the computational time but, on the other hand, cannot be avoided to obtain accurate predictions. We face a trade-off between cost-efficiency and accuracy: the simulation code has to be sufficiently efficient to be used in an operational context but accurate enough to predict the phenomenon faithfully. To tackle this trade-off, we design a hybrid simulation code coupling a traditional fluid dynamic solver with a neural network approximating the chemical reactions. We rely on their power in terms of accuracy and dimension reduction when applied in a big data context and on their efficiency stemming from their matrix-vector structure to achieve important acceleration factors ($\times 10$ to $\times 18.6$). This paper aims to explain how we design such cost-effective hybrid simulation codes in practice. Above all, we describe methodologies to ensure accuracy guarantees, allowing us to go beyond traditional surrogate modeling and to use these codes as references.
StyleGAN Encoder-Based Attack for Block Scrambled Face Images
Sep 16, 2022
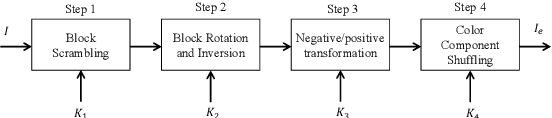

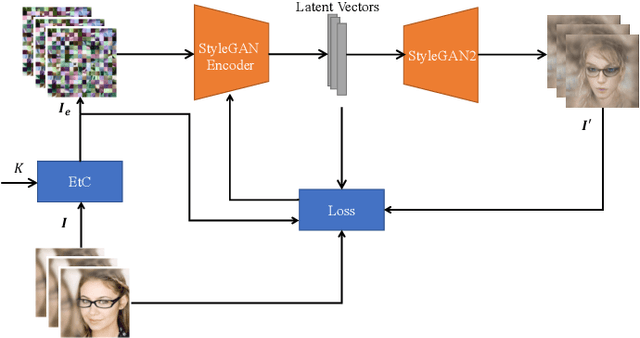
In this paper, we propose an attack method to block scrambled face images, particularly Encryption-then-Compression (EtC) applied images by utilizing the existing powerful StyleGAN encoder and decoder for the first time. Instead of reconstructing identical images as plain ones from encrypted images, we focus on recovering styles that can reveal identifiable information from the encrypted images. The proposed method trains an encoder by using plain and encrypted image pairs with a particular training strategy. While state-of-the-art attack methods cannot recover any perceptual information from EtC images, the proposed method discloses personally identifiable information such as hair color, skin color, eyeglasses, gender, etc. Experiments were carried out on the CelebA dataset, and results show that reconstructed images have some perceptual similarities compared to plain images.
Multi-Stage NMPC for a MAV based Collision Free Navigation under Varying Communication Delays
Aug 07, 2022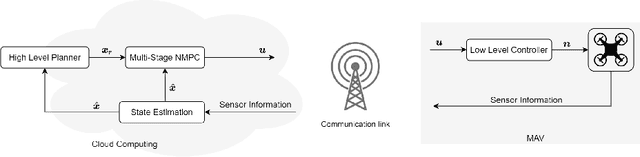

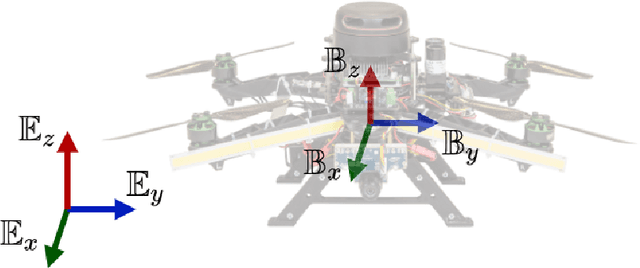

Time delays in communication networks are one of the main concerns in deploying robots with computation boards on the edge. This article proposes a multi-stage Nonlinear Model Predictive Control (NMPC) that is capable of handling varying network-induced time delays for establishing a control framework being able to guarantee collision-free Micro Aerial Vehicles (MAVs) navigation. This study introduces a novel approach that considers different sampling times by a tree of discretization scenarios contrary to the existing typical multi-stage NMPC where system uncertainties are modeled by a tree of scenarios. Additionally, the proposed method considers adaptive weights for the multi-stage NMPC scenarios based on the probability of time delays in the communication link. As a result of the multi-stage NMPC, the obtained optimal control action is valid for multiple sampling times. Finally, the overall effectiveness of the proposed novel control framework is demonstrated in various tests and different simulation environments.
DELTAR: Depth Estimation from a Light-weight ToF Sensor and RGB Image
Sep 27, 2022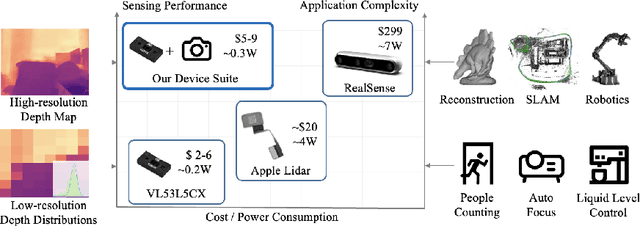
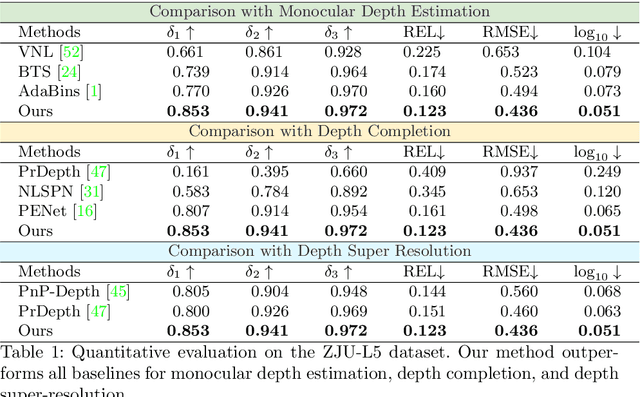
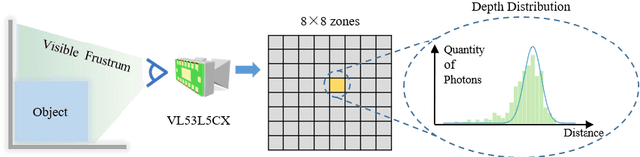
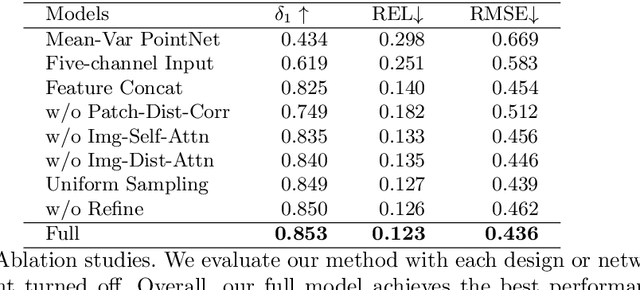
Light-weight time-of-flight (ToF) depth sensors are small, cheap, low-energy and have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. However, due to their specific measurements (depth distribution in a region instead of the depth value at a certain pixel) and extremely low resolution, they are insufficient for applications requiring high-fidelity depth such as 3D reconstruction. In this paper, we propose DELTAR, a novel method to empower light-weight ToF sensors with the capability of measuring high resolution and accurate depth by cooperating with a color image. As the core of DELTAR, a feature extractor customized for depth distribution and an attention-based neural architecture is proposed to fuse the information from the color and ToF domain efficiently. To evaluate our system in real-world scenarios, we design a data collection device and propose a new approach to calibrate the RGB camera and ToF sensor. Experiments show that our method produces more accurate depth than existing frameworks designed for depth completion and depth super-resolution and achieves on par performance with a commodity-level RGB-D sensor. Code and data are available at https://zju3dv.github.io/deltar/.
OysterSim: Underwater Simulation for Enhancing Oyster Reef Monitoring
Sep 20, 2022
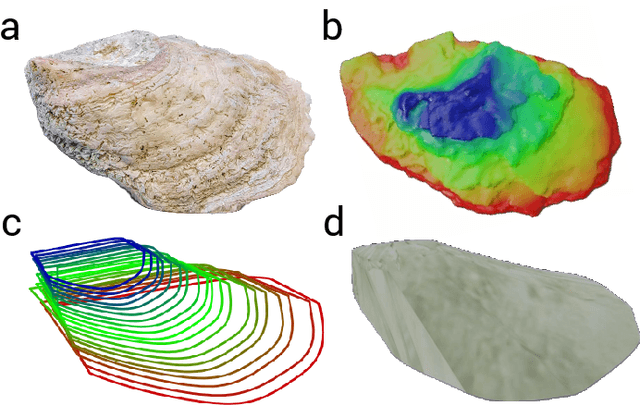
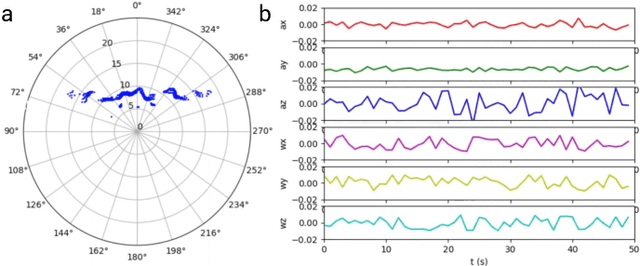

Oysters are the living vacuum cleaners of the oceans. There is an exponential decline in the oyster population due to over-harvesting. With the current development of the automation and AI, robots are becoming an integral part of the environmental monitoring process that can be also utilized for oyster reef preservation. Nevertheless, the underwater environment poses many difficulties, both from the practical - dangerous and time consuming operations, and the technical perspectives - distorted perception and unreliable navigation. To this end, we present a simulated environment that can be used to improve oyster reef monitoring. The simulated environment can be used to create photo-realistic image datasets with multiple sensor data and ground truth location of a remotely operated vehicle(ROV). Currently, there are no photo-realistic image datasets for oyster reef monitoring. Thus, we want to provide a new benchmark suite to the underwater community.