 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The optimality of word lengths. Theoretical foundations and an empirical study
Aug 24, 2022
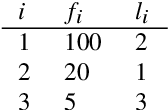
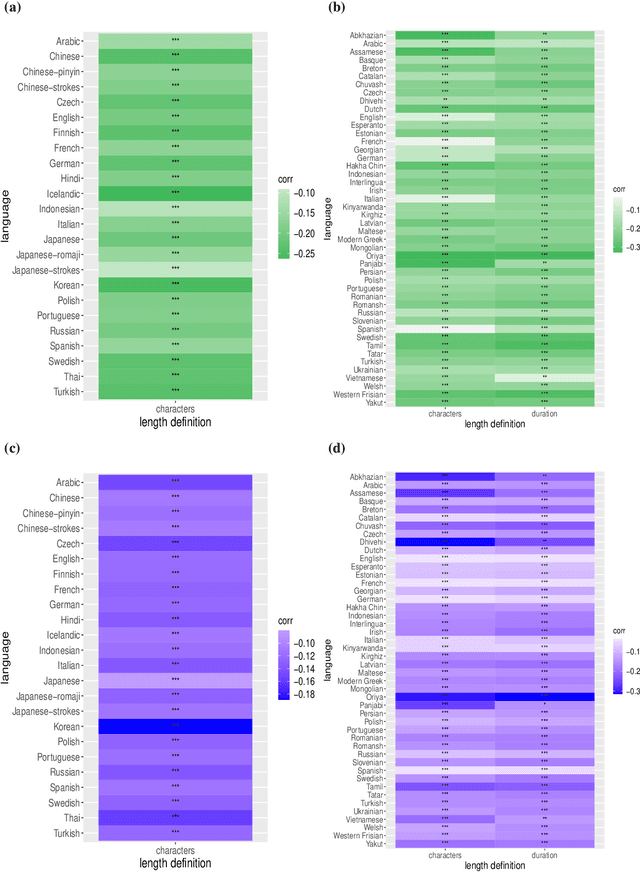
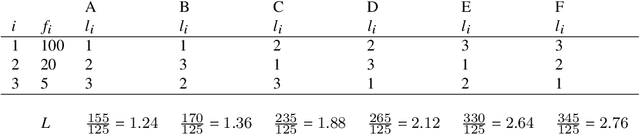
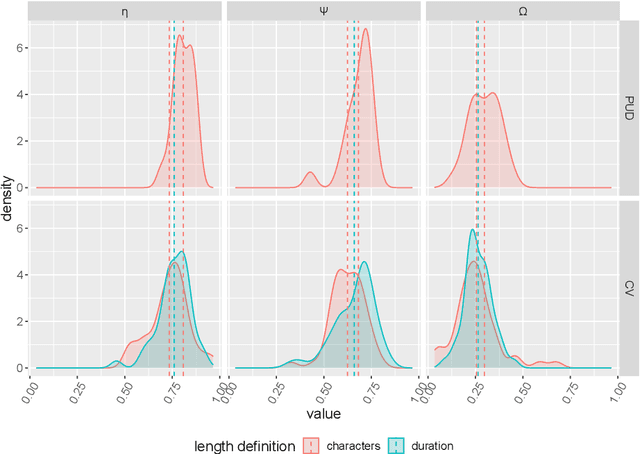
One of the most robust patterns found in human languages is Zipf's law of abbreviation, that is, the tendency of more frequent words to be shorter. Since Zipf's pioneering research, this law has been viewed as a manifestation of compression, i.e. the minimization of the length of forms - a universal principle of natural communication. Although the claim that languages are optimized has become trendy, attempts to measure the degree of optimization of languages have been rather scarce. Here we demonstrate that compression manifests itself in a wide sample of languages without exceptions, and independently of the unit of measurement. It is detectable for both word lengths in characters of written language as well as durations in time in spoken language. Moreover, to measure the degree of optimization, we derive a simple formula for a random baseline and present two scores that are dualy normalized, namely, they are normalized with respect to both the minimum and the random baseline. We analyze the theoretical and statistical advantages and disadvantages of these and other scores. Harnessing the best score, we quantify for the first time the degree of optimality of word lengths in languages. This indicates that languages are optimized to 62 or 67 percent on average (depending on the source) when word lengths are measured in characters, and to 65 percent on average when word lengths are measured in time. In general, spoken word durations are more optimized than written word lengths in characters. Beyond the analyses reported here, our work paves the way to measure the degree of optimality of the vocalizations or gestures of other species, and to compare them against written, spoken, or signed human languages.
V2XP-ASG: Generating Adversarial Scenes for Vehicle-to-Everything Perception
Sep 27, 2022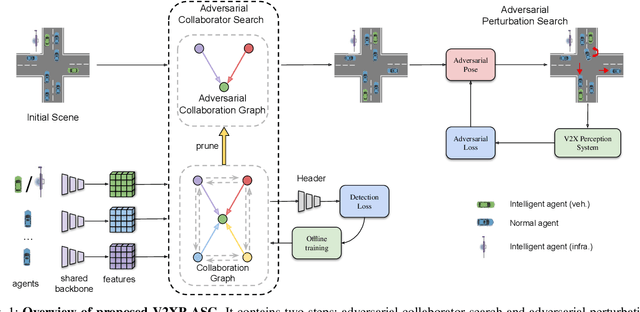
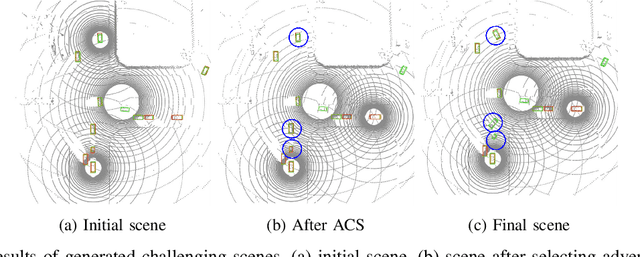
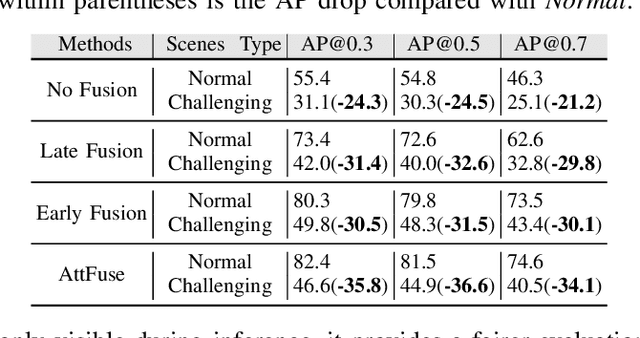

Recent advancements in Vehicle-to-Everything communication technology have enabled autonomous vehicles to share sensory information to obtain better perception performance. With the rapid growth of autonomous vehicles and intelligent infrastructure, the V2X perception systems will soon be deployed at scale, which raises a safety-critical question: how can we evaluate and improve its performance under challenging traffic scenarios before the real-world deployment? Collecting diverse large-scale real-world test scenes seems to be the most straightforward solution, but it is expensive and time-consuming, and the collections can only cover limited scenarios. To this end, we propose the first open adversarial scene generator V2XP-ASG that can produce realistic, challenging scenes for modern LiDAR-based multi-agent perception system. V2XP-ASG learns to construct an adversarial collaboration graph and simultaneously perturb multiple agents' poses in an adversarial and plausible manner. The experiments demonstrate that V2XP-ASG can effectively identify challenging scenes for a large range of V2X perception systems. Meanwhile, by training on the limited number of generated challenging scenes, the accuracy of V2X perception systems can be further improved by 12.3% on challenging and 4% on normal scenes.
Data-driven Attention and Data-independent DCT based Global Context Modeling for Text-independent Speaker Recognition
Aug 04, 2022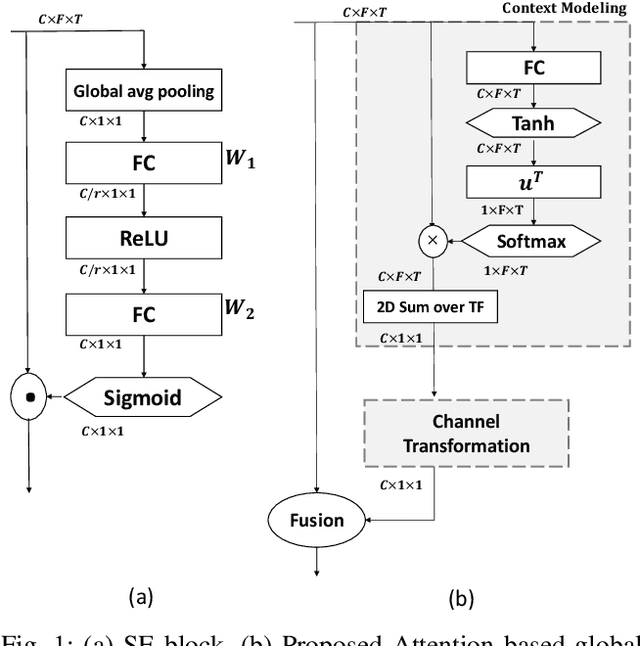
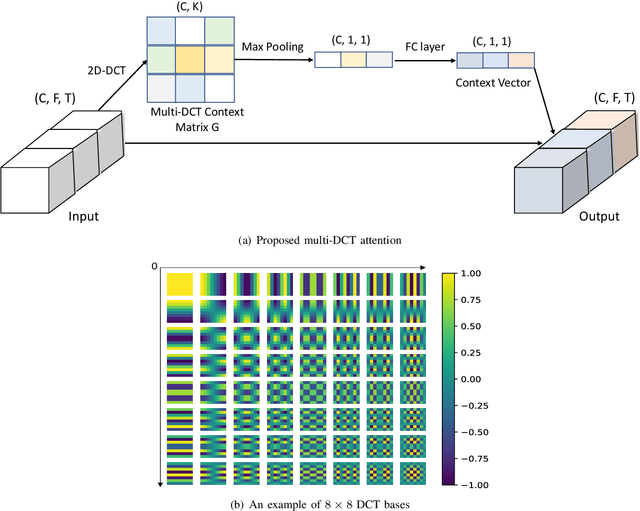
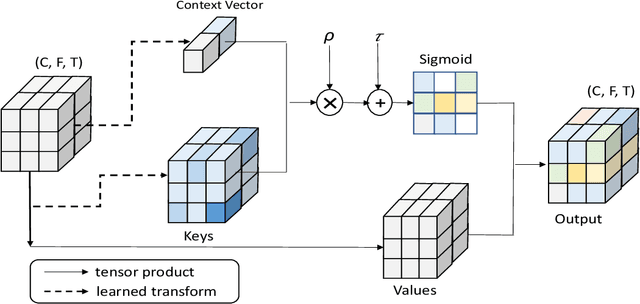
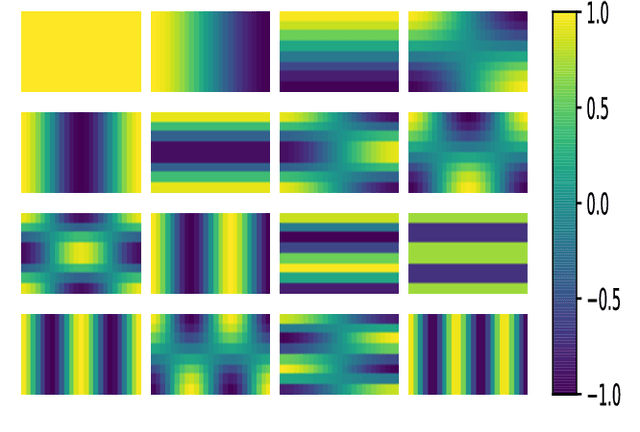
Learning an effective speaker representation is crucial for achieving reliable performance in speaker verification tasks. Speech signals are high-dimensional, long, and variable-length sequences that entail a complex hierarchical structure. Signals may contain diverse information at each time-frequency (TF) location. For example, it may be more beneficial to focus on high-energy parts for phoneme classes such as fricatives. The standard convolutional layer that operates on neighboring local regions cannot capture the complex TF global context information. In this study, a general global time-frequency context modeling framework is proposed to leverage the context information specifically for speaker representation modeling. First, a data-driven attention-based context model is introduced to capture the long-range and non-local relationship across different time-frequency locations. Second, a data-independent 2D-DCT based context model is proposed to improve model interpretability. A multi-DCT attention mechanism is presented to improve modeling power with alternate DCT base forms. Finally, the global context information is used to recalibrate salient time-frequency locations by computing the similarity between the global context and local features. The proposed lightweight blocks can be easily incorporated into a speaker model with little additional computational costs and effectively improves the speaker verification performance compared to the standard ResNet model and Squeeze\&Excitation block by a large margin. Detailed ablation studies are also performed to analyze various factors that may impact performance of the proposed individual modules. Results from experiments show that the proposed global context modeling framework can efficiently improve the learned speaker representations by achieving channel-wise and time-frequency feature recalibration.
PREF: Predictability Regularized Neural Motion Fields
Sep 21, 2022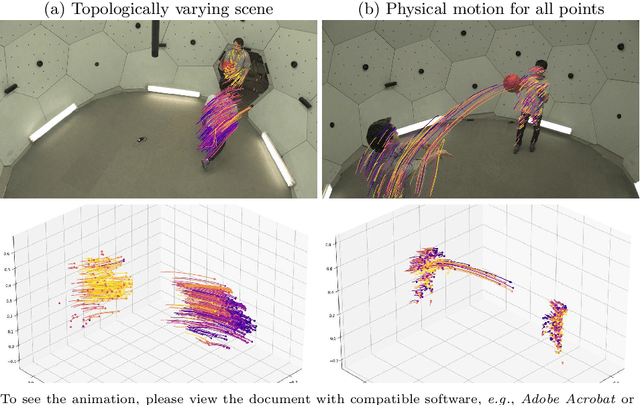
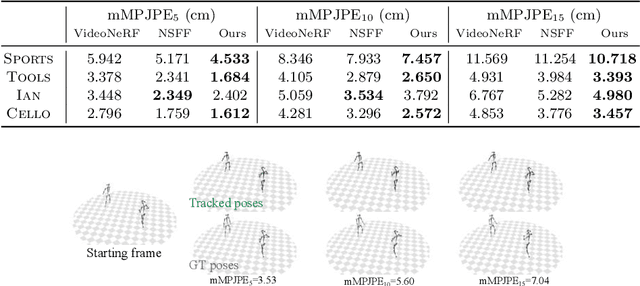
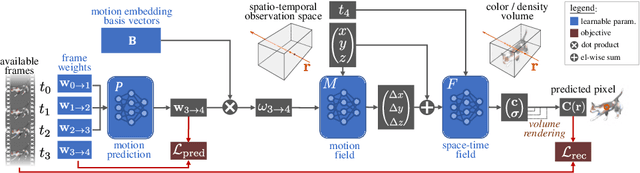
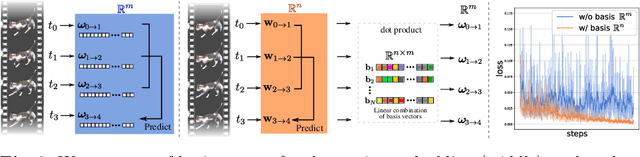
Knowing the 3D motions in a dynamic scene is essential to many vision applications. Recent progress is mainly focused on estimating the activity of some specific elements like humans. In this paper, we leverage a neural motion field for estimating the motion of all points in a multiview setting. Modeling the motion from a dynamic scene with multiview data is challenging due to the ambiguities in points of similar color and points with time-varying color. We propose to regularize the estimated motion to be predictable. If the motion from previous frames is known, then the motion in the near future should be predictable. Therefore, we introduce a predictability regularization by first conditioning the estimated motion on latent embeddings, then by adopting a predictor network to enforce predictability on the embeddings. The proposed framework PREF (Predictability REgularized Fields) achieves on par or better results than state-of-the-art neural motion field-based dynamic scene representation methods, while requiring no prior knowledge of the scene.
Quasi-Monolithic Graph Neural Network for Fluid-Structure Interaction
Oct 09, 2022

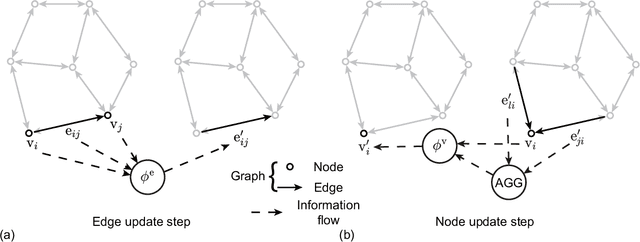
Using convolutional neural networks, deep learning-based reduced-order models have demonstrated great potential in accelerating the simulations of coupled fluid-structure systems for downstream optimization and control tasks. However, these networks have to operate on a uniform Cartesian grid due to the inherent restriction of convolutions, leading to difficulties in extracting fine physical details along a fluid-structure interface without excessive computational burden. In this work, we present a quasi-monolithic graph neural network framework for the reduced-order modelling of fluid-structure interaction systems. With the aid of an arbitrary Lagrangian-Eulerian formulation, the mesh and fluid states are evolved temporally with two sub-networks. The movement of the mesh is reduced to the evolution of several coefficients via proper orthogonal decomposition, and these coefficients are propagated through time via a multi-layer perceptron. A graph neural network is employed to predict the evolution of the fluid state based on the state of the whole system. The structural state is implicitly modelled by the movement of the mesh on the fluid-structure boundary; hence it makes the proposed data-driven methodology quasi-monolithic. The effectiveness of the proposed quasi-monolithic graph neural network architecture is assessed on a prototypical fluid-structure system of the flow around an elastically-mounted cylinder. We use the full-order flow snapshots and displacements as target physical data to learn and infer coupled fluid-structure dynamics. The proposed framework tracks the interface description and provides the state predictions during roll-out with acceptable accuracy. We also directly extract the lift and drag forces from the predicted fluid and mesh states, in contrast to existing convolution-based architectures.
Sauron U-Net: Simple automated redundancy elimination in medical image segmentation via filter pruning
Sep 27, 2022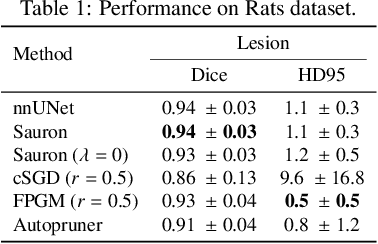
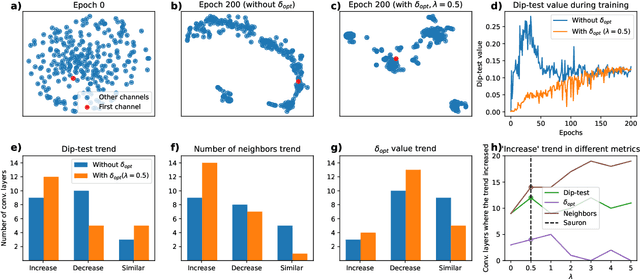
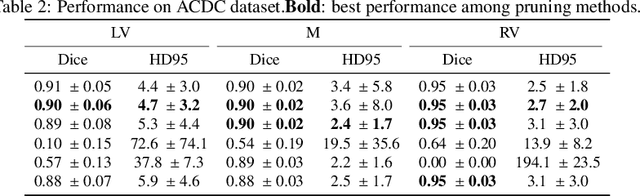
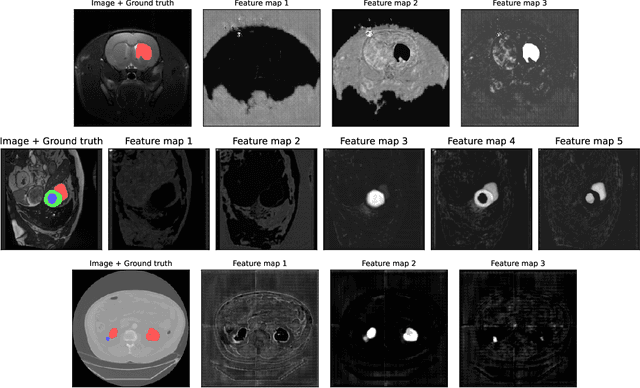
We present Sauron, a filter pruning method that eliminates redundant feature maps by discarding the corresponding filters with automatically-adjusted layer-specific thresholds. Furthermore, Sauron minimizes a regularization term that, as we show with various metrics, promotes the formation of feature maps clusters. In contrast to most filter pruning methods, Sauron is single-phase, similarly to typical neural network optimization, requiring fewer hyperparameters and design decisions. Additionally, unlike other cluster-based approaches, our method does not require pre-selecting the number of clusters, which is non-trivial to determine and varies across layers. We evaluated Sauron and three state-of-the-art filter pruning methods on three medical image segmentation tasks. This is an area where filter pruning has received little attention and where it can help building efficient models for medical grade computers that cannot use cloud services due to privacy considerations. Sauron achieved models with higher performance and pruning rate than the competing pruning methods. Additionally, since Sauron removes filters during training, its optimization accelerated over time. Finally, we show that the feature maps of a Sauron-pruned model were highly interpretable. The Sauron code is publicly available at https://github.com/jmlipman/SauronUNet.
Argus++: Robust Real-time Activity Detection for Unconstrained Video Streams with Overlapping Cube Proposals
Jan 14, 2022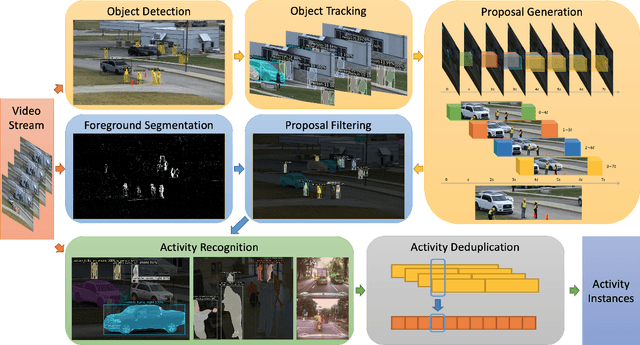
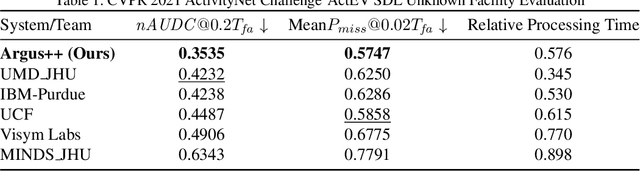

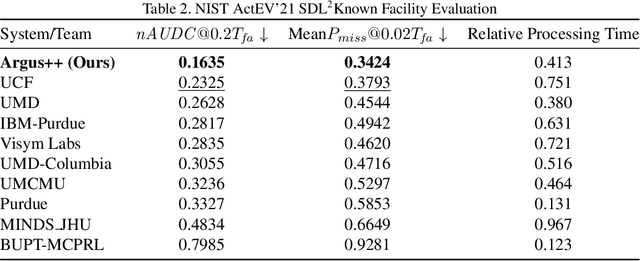
Activity detection is one of the attractive computer vision tasks to exploit the video streams captured by widely installed cameras. Although achieving impressive performance, conventional activity detection algorithms are usually designed under certain constraints, such as using trimmed and/or object-centered video clips as inputs. Therefore, they failed to deal with the multi-scale multi-instance cases in real-world unconstrained video streams, which are untrimmed and have large field-of-views. Real-time requirements for streaming analysis also mark brute force expansion of them unfeasible. To overcome these issues, we propose Argus++, a robust real-time activity detection system for analyzing unconstrained video streams. The design of Argus++ introduces overlapping spatio-temporal cubes as an intermediate concept of activity proposals to ensure coverage and completeness of activity detection through over-sampling. The overall system is optimized for real-time processing on standalone consumer-level hardware. Extensive experiments on different surveillance and driving scenarios demonstrated its superior performance in a series of activity detection benchmarks, including CVPR ActivityNet ActEV 2021, NIST ActEV SDL UF/KF, TRECVID ActEV 2020/2021, and ICCV ROAD 2021.
Graph Neural Networks for Multi-Robot Active Information Acquisition
Sep 24, 2022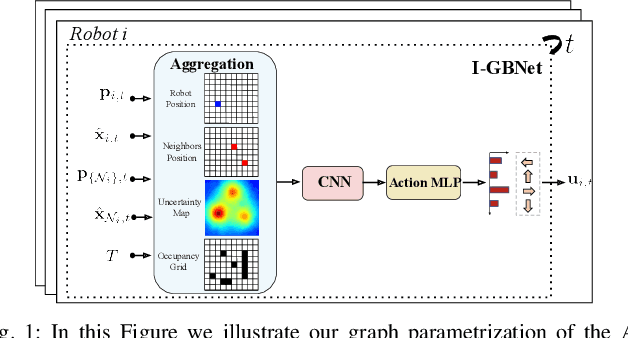
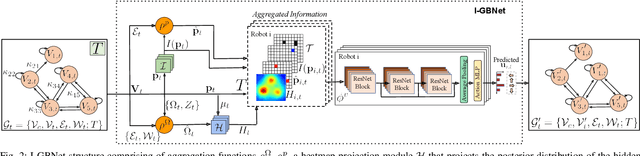
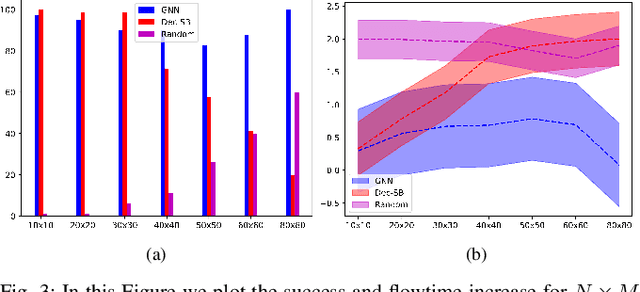
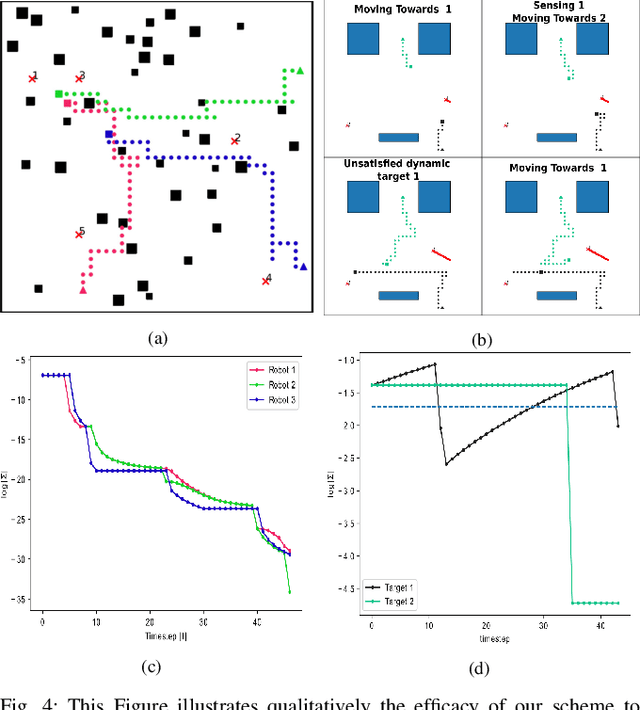
This paper addresses the Multi-Robot Active Information Acquisition (AIA) problem, where a team of mobile robots, communicating through an underlying graph, estimates a hidden state expressing a phenomenon of interest. Applications like target tracking, coverage and SLAM can be expressed in this framework. Existing approaches, though, are either not scalable, unable to handle dynamic phenomena or not robust to changes in the communication graph. To counter these shortcomings, we propose an Information-aware Graph Block Network (I-GBNet), an AIA adaptation of Graph Neural Networks, that aggregates information over the graph representation and provides sequential-decision making in a distributed manner. The I-GBNet, trained via imitation learning with a centralized sampling-based expert solver, exhibits permutation equivariance and time invariance, while harnessing the superior scalability, robustness and generalizability to previously unseen environments and robot configurations. Experiments on significantly larger graphs and dimensionality of the hidden state and more complex environments than those seen in training validate the properties of the proposed architecture and its efficacy in the application of localization and tracking of dynamic targets.
A Dataset for Answering Time-Sensitive Questions
Aug 13, 2021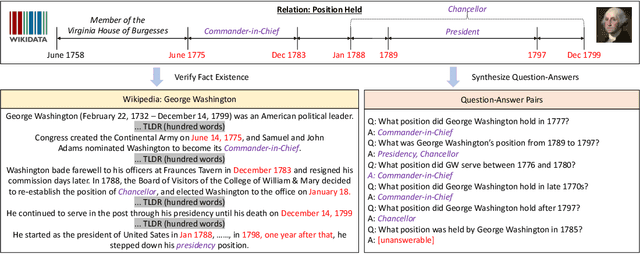
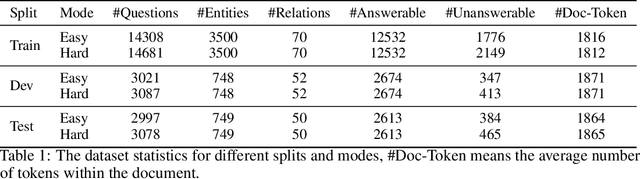
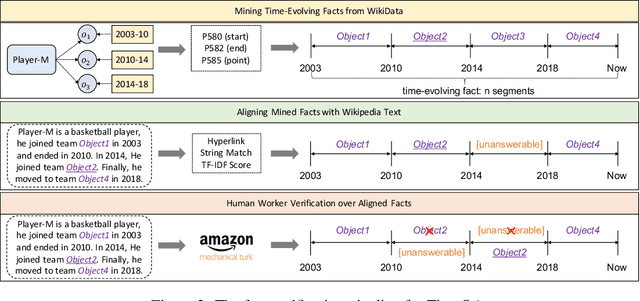
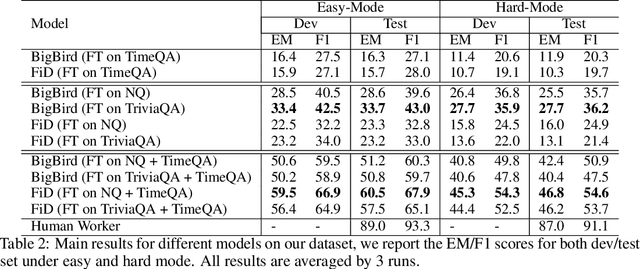
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses two novel challenges: 1) the model needs to understand both explicit and implicit mention of time information in the long document, 2) the model needs to perform temporal reasoning like comparison, addition, subtraction. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform robust temporal understanding and reasoning. Therefore, we believe that our dataset could serve as a benchmark to empower future studies in temporal reasoning. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
Dfferentiable Raycasting for Self-supervised Occupancy Forecasting
Oct 04, 2022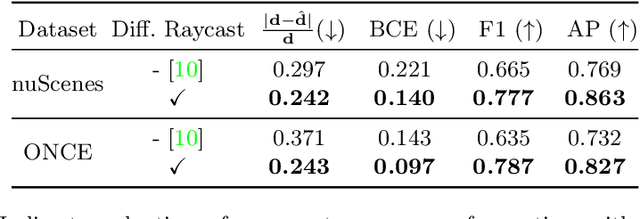


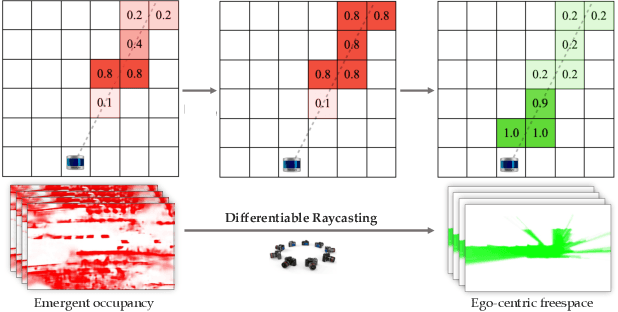
Motion planning for safe autonomous driving requires learning how the environment around an ego-vehicle evolves with time. Ego-centric perception of driveable regions in a scene not only changes with the motion of actors in the environment, but also with the movement of the ego-vehicle itself. Self-supervised representations proposed for large-scale planning, such as ego-centric freespace, confound these two motions, making the representation difficult to use for downstream motion planners. In this paper, we use geometric occupancy as a natural alternative to view-dependent representations such as freespace. Occupancy maps naturally disentangle the motion of the environment from the motion of the ego-vehicle. However, one cannot directly observe the full 3D occupancy of a scene (due to occlusion), making it difficult to use as a signal for learning. Our key insight is to use differentiable raycasting to "render" future occupancy predictions into future LiDAR sweep predictions, which can be compared with ground-truth sweeps for self-supervised learning. The use of differentiable raycasting allows occupancy to emerge as an internal representation within the forecasting network. In the absence of groundtruth occupancy, we quantitatively evaluate the forecasting of raycasted LiDAR sweeps and show improvements of upto 15 F1 points. For downstream motion planners, where emergent occupancy can be directly used to guide non-driveable regions, this representation relatively reduces the number of collisions with objects by up to 17% as compared to freespace-centric motion planners.