 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
CoMotion: Concurrent Multi-person 3D Motion
Apr 16, 2025We introduce an approach for detecting and tracking detailed 3D poses of multiple people from a single monocular camera stream. Our system maintains temporally coherent predictions in crowded scenes filled with difficult poses and occlusions. Our model performs both strong per-frame detection and a learned pose update to track people from frame to frame. Rather than match detections across time, poses are updated directly from a new input image, which enables online tracking through occlusion. We train on numerous image and video datasets leveraging pseudo-labeled annotations to produce a model that matches state-of-the-art systems in 3D pose estimation accuracy while being faster and more accurate in tracking multiple people through time. Code and weights are provided at https://github.com/apple/ml-comotion
Lidar Panoptic Segmentation in an Open World
Sep 22, 2024Addressing Lidar Panoptic Segmentation (LPS ) is crucial for safe deployment of autonomous vehicles. LPS aims to recognize and segment lidar points w.r.t. a pre-defined vocabulary of semantic classes, including thing classes of countable objects (e.g., pedestrians and vehicles) and stuff classes of amorphous regions (e.g., vegetation and road). Importantly, LPS requires segmenting individual thing instances (e.g., every single vehicle). Current LPS methods make an unrealistic assumption that the semantic class vocabulary is fixed in the real open world, but in fact, class ontologies usually evolve over time as robots encounter instances of novel classes that are considered to be unknowns w.r.t. the pre-defined class vocabulary. To address this unrealistic assumption, we study LPS in the Open World (LiPSOW): we train models on a dataset with a pre-defined semantic class vocabulary and study their generalization to a larger dataset where novel instances of thing and stuff classes can appear. This experimental setting leads to interesting conclusions. While prior art train class-specific instance segmentation methods and obtain state-of-the-art results on known classes, methods based on class-agnostic bottom-up grouping perform favorably on classes outside of the initial class vocabulary (i.e., unknown classes). Unfortunately, these methods do not perform on-par with fully data-driven methods on known classes. Our work suggests a middle ground: we perform class-agnostic point clustering and over-segment the input cloud in a hierarchical fashion, followed by binary point segment classification, akin to Region Proposal Network [1]. We obtain the final point cloud segmentation by computing a cut in the weighted hierarchical tree of point segments, independently of semantic classification. Remarkably, this unified approach leads to strong performance on both known and unknown classes.
Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting
Mar 01, 2023Predicting how the world can evolve in the future is crucial for motion planning in autonomous systems. Classical methods are limited because they rely on costly human annotations in the form of semantic class labels, bounding boxes, and tracks or HD maps of cities to plan their motion and thus are difficult to scale to large unlabeled datasets. One promising self-supervised task is 3D point cloud forecasting from unannotated LiDAR sequences. We show that this task requires algorithms to implicitly capture (1) sensor extrinsics (i.e., the egomotion of the autonomous vehicle), (2) sensor intrinsics (i.e., the sampling pattern specific to the particular LiDAR sensor), and (3) the shape and motion of other objects in the scene. But autonomous systems should make predictions about the world and not their sensors. To this end, we factor out (1) and (2) by recasting the task as one of spacetime (4D) occupancy forecasting. But because it is expensive to obtain ground-truth 4D occupancy, we render point cloud data from 4D occupancy predictions given sensor extrinsics and intrinsics, allowing one to train and test occupancy algorithms with unannotated LiDAR sequences. This also allows one to evaluate and compare point cloud forecasting algorithms across diverse datasets, sensors, and vehicles.
Dfferentiable Raycasting for Self-supervised Occupancy Forecasting
Oct 04, 2022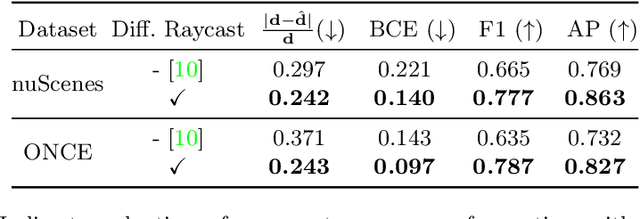


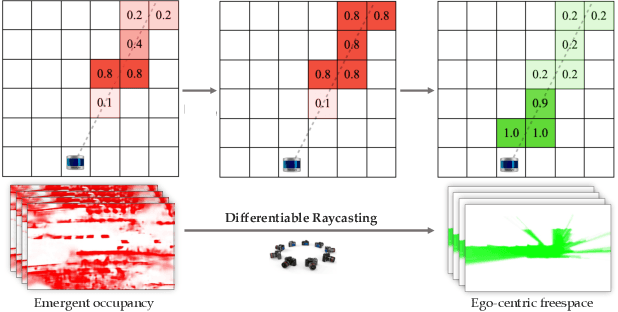
Motion planning for safe autonomous driving requires learning how the environment around an ego-vehicle evolves with time. Ego-centric perception of driveable regions in a scene not only changes with the motion of actors in the environment, but also with the movement of the ego-vehicle itself. Self-supervised representations proposed for large-scale planning, such as ego-centric freespace, confound these two motions, making the representation difficult to use for downstream motion planners. In this paper, we use geometric occupancy as a natural alternative to view-dependent representations such as freespace. Occupancy maps naturally disentangle the motion of the environment from the motion of the ego-vehicle. However, one cannot directly observe the full 3D occupancy of a scene (due to occlusion), making it difficult to use as a signal for learning. Our key insight is to use differentiable raycasting to "render" future occupancy predictions into future LiDAR sweep predictions, which can be compared with ground-truth sweeps for self-supervised learning. The use of differentiable raycasting allows occupancy to emerge as an internal representation within the forecasting network. In the absence of groundtruth occupancy, we quantitatively evaluate the forecasting of raycasted LiDAR sweeps and show improvements of upto 15 F1 points. For downstream motion planners, where emergent occupancy can be directly used to guide non-driveable regions, this representation relatively reduces the number of collisions with objects by up to 17% as compared to freespace-centric motion planners.
Active Perception using Light Curtains for Autonomous Driving
Aug 05, 2020
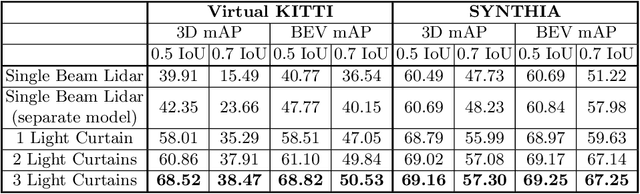
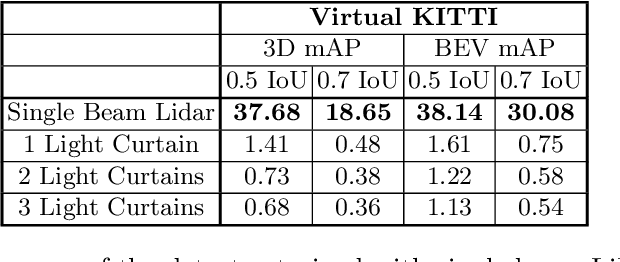
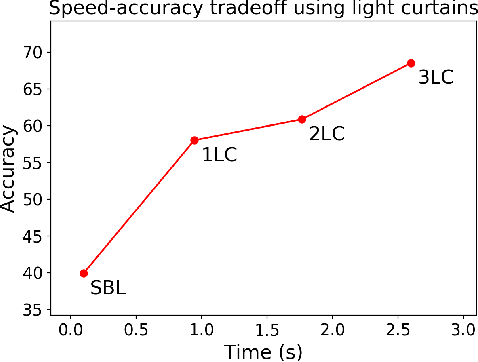
Most real-world 3D sensors such as LiDARs perform fixed scans of the entire environment, while being decoupled from the recognition system that processes the sensor data. In this work, we propose a method for 3D object recognition using light curtains, a resource-efficient controllable sensor that measures depth at user-specified locations in the environment. Crucially, we propose using prediction uncertainty of a deep learning based 3D point cloud detector to guide active perception. Given a neural network's uncertainty, we derive an optimization objective to place light curtains using the principle of maximizing information gain. Then, we develop a novel and efficient optimization algorithm to maximize this objective by encoding the physical constraints of the device into a constraint graph and optimizing with dynamic programming. We show how a 3D detector can be trained to detect objects in a scene by sequentially placing uncertainty-guided light curtains to successively improve detection accuracy. Code and details can be found on the project webpage: http://siddancha.github.io/projects/active-perception-light-curtains.
Inferring Distributions Over Depth from a Single Image
Dec 12, 2019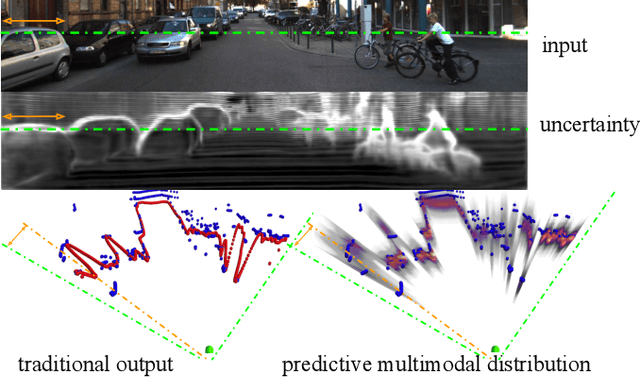

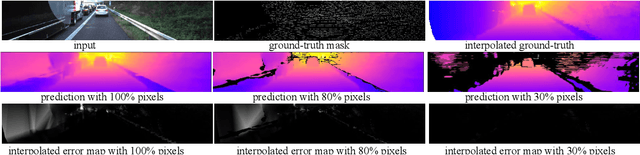
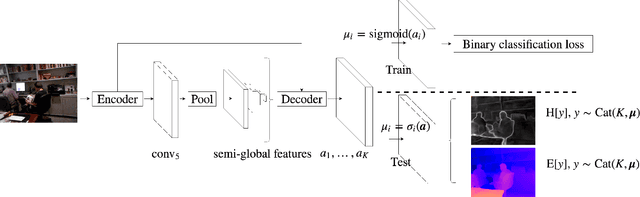
When building a geometric scene understanding system for autonomous vehicles, it is crucial to know when the system might fail. Most contemporary approaches cast the problem as depth regression, whose output is a depth value for each pixel. Such approaches cannot diagnose when failures might occur. One attractive alternative is a deep Bayesian network, which captures uncertainty in both model parameters and ambiguous sensor measurements. However, estimating uncertainties is often slow and the distributions are often limited to be uni-modal. In this paper, we recast the continuous problem of depth regression as discrete binary classification, whose output is an un-normalized distribution over possible depths for each pixel. Such output allows one to reliably and efficiently capture multi-modal depth distributions in ambiguous cases, such as depth discontinuities and reflective surfaces. Results on standard benchmarks show that our method produces accurate depth predictions and significantly better uncertainty estimations than prior art while running near real-time. Finally, by making use of uncertainties of the predicted distribution, we significantly reduce streak-like artifacts and improves accuracy as well as memory efficiency in 3D map reconstruction.
What You See is What You Get: Exploiting Visibility for 3D Object Detection
Dec 10, 2019

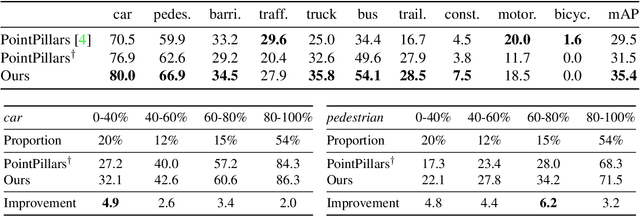
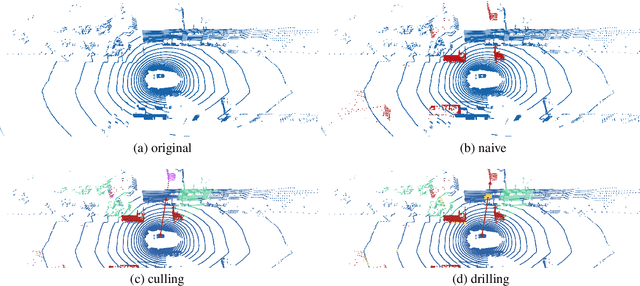
Recent advances in 3D sensing have created unique challenges for computer vision. One fundamental challenge is finding a good representation for 3D sensor data. Most popular representations (such as PointNet) are proposed in the context of processing truly 3D data (e.g. points sampled from mesh models), ignoring the fact that 3D sensored data such as a LiDAR sweep is in fact 2.5D. We argue that representing 2.5D data as collections of (x, y, z) points fundamentally destroys hidden information about freespace. In this paper, we demonstrate such knowledge can be efficiently recovered through 3D raycasting and readily incorporated into batch-based gradient learning. We describe a simple approach to augmenting voxel-based networks with visibility: we add a voxelized visibility map as an additional input stream. In addition, we show that visibility can be combined with two crucial modifications common to state-of-the-art 3D detectors: synthetic data augmentation of virtual objects and temporal aggregation of LiDAR sweeps over multiple time frames. On the NuScenes 3D detection benchmark, we show that, by adding an additional stream for visibility input, we can significantly improve the overall detection accuracy of a state-of-the-art 3D detector.
Learning to Optimally Segment Point Clouds
Dec 10, 2019
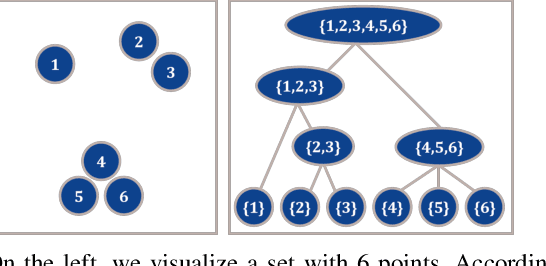


We focus on the problem of class-agnostic instance segmentation of LiDAR point clouds. We propose an approach that combines graph-theoretic search with data-driven learning: it searches over a set of candidate segmentations and returns one where individual segments score well according to a data-driven point-based model of "objectness". We prove that if we score a segmentation by the worst objectness among its individual segments, there is an efficient algorithm that finds the optimal worst-case segmentation among an exponentially large number of candidate segmentations. We also present an efficient algorithm for the average-case. For evaluation, we repurpose KITTI 3D detection as a segmentation benchmark and empirically demonstrate that our algorithms significantly outperform past bottom-up segmentation approaches and top-down object-based algorithms on segmenting point clouds.
Active Learning with Partial Feedback
Sep 28, 2018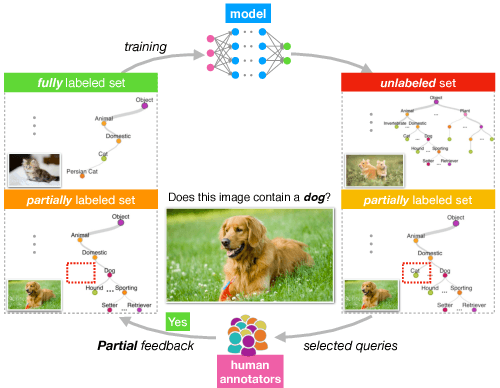
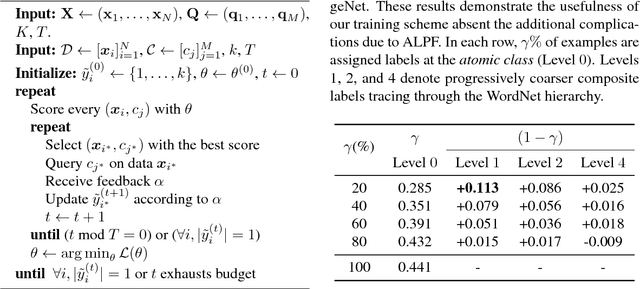
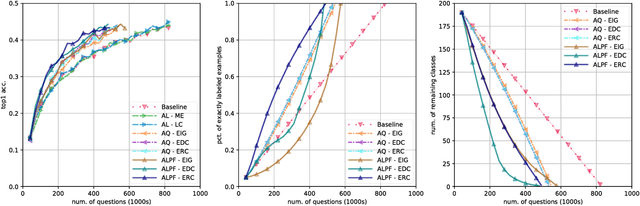
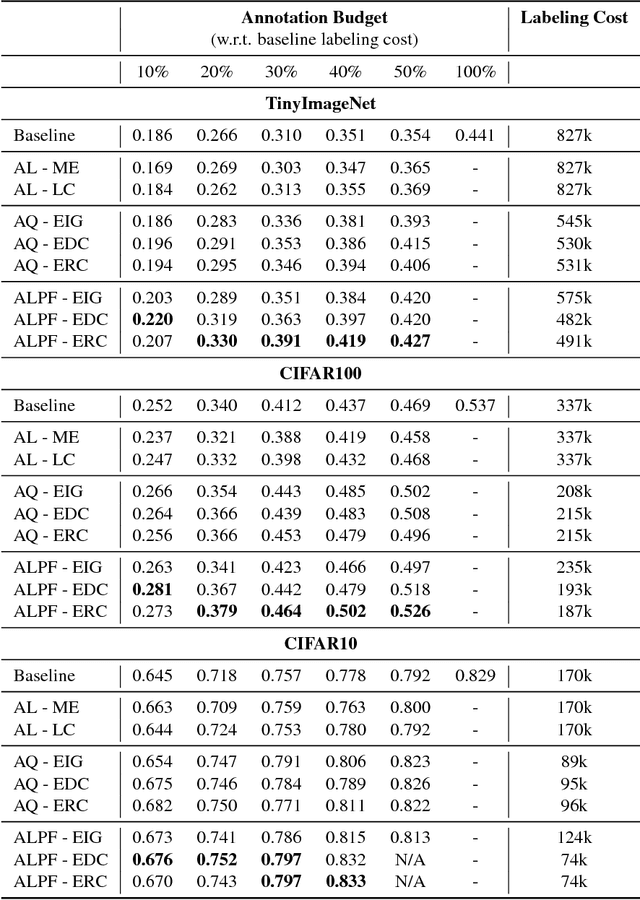
In the large-scale multiclass setting, assigning labels often consists of answering multiple questions to drill down through a hierarchy of classes. Here, the labor required per annotation scales with the number of questions asked. We propose active learning with partial feedback. In this setup, the learner asks the annotator if a chosen example belongs to a (possibly composite) chosen class. The answer eliminates some classes, leaving the agent with a partial label. Success requires (i) a sampling strategy to choose (example, class) pairs, and (ii) learning from partial labels. Experiments on the TinyImageNet dataset demonstrate that our most effective method achieves a 26% relative improvement (8.1% absolute) in top1 classification accuracy for a 250k (or 30%) binary question budget, compared to a naive baseline. Our work may also impact traditional data annotation. For example, our best method fully annotates TinyImageNet with only 482k (with EDC though, ERC is 491) binary questions (vs 827k for naive method).