 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Invariant Test-Time Adaptation for Vision-Language Model Generalization
Mar 01, 2024


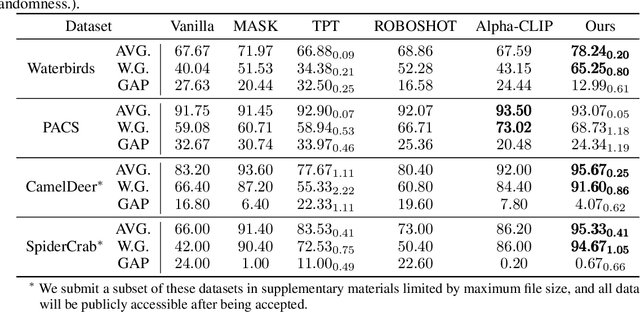
Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Mar 01, 2024We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.
Joint Power Allocation and Beamforming for In-band Full-duplex Multi-cell Multi-user Networks
Mar 16, 2024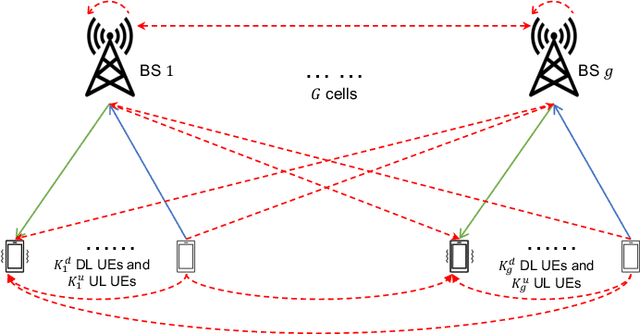
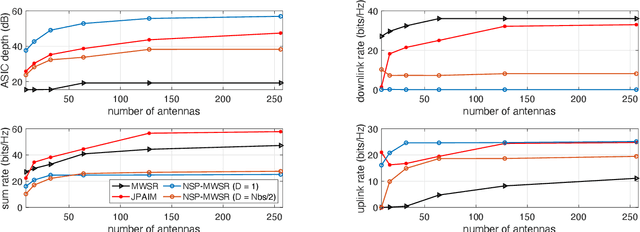
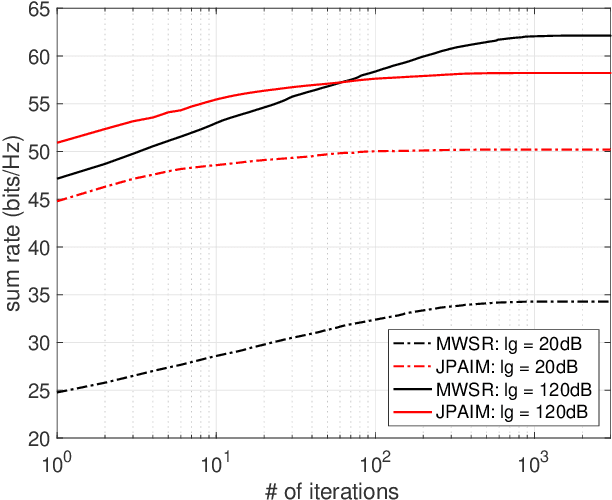
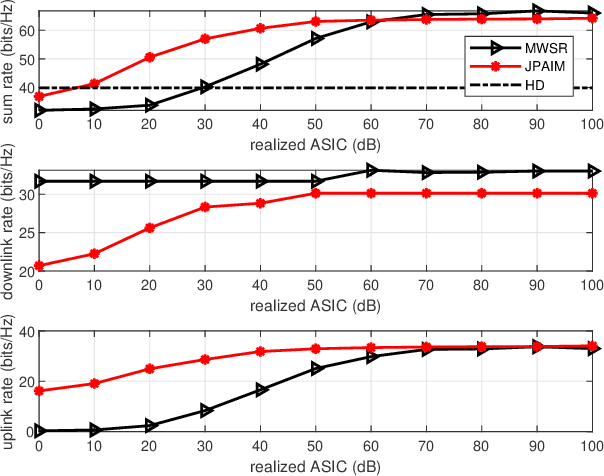
This paper investigates a robust joint power allocation and beamforming scheme for in-band full-duplex multi-cell multi-user (IBFD-MCMU) networks. A mean-squared error (MSE) minimization problem is formulated with constraints on the power budgets and residual self-interference (RSI) power. The problem is not convex, so we decompose it into two sub-problems: interference management beamforming and power allocation, and give closed-form solutions to the sub-problems. Then we propose an iterative algorithm to yield an overall solution. The computational complexity and convergence behavior of the algorithm are analyzed. Our method can enhance the analog self-interference cancellation (ASIC) depth provided by the precoder with less effect on the downlink communication than the existing null-space projection method, inspiring a low-cost but efficient IBFD transceiver design. It can achieve 42.9% of IBFD gain in terms of spectral efficiency with only antenna isolation, while this value increases to 60.9% with further digital self-interference cancellation (DSIC). Numerical results illustrate that our algorithm is robust to hardware impairments and channel uncertainty. With sufficient ASIC depth, our method reduces the computation time by at least 20% than the existing scheme due to its faster convergence speed at the cost of < 12.5% sum rate loss. The benefit is much more significant with single-antenna users that our algorithm saves at least 40% of the computation time at the cost of < 10% sum rate reduction.
Control of Medical Digital Twins with Artificial Neural Networks
Mar 18, 2024
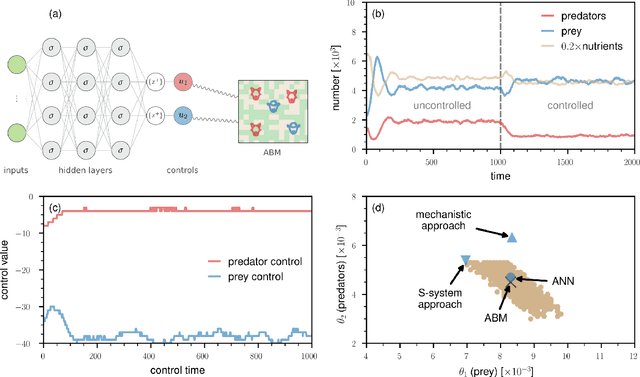
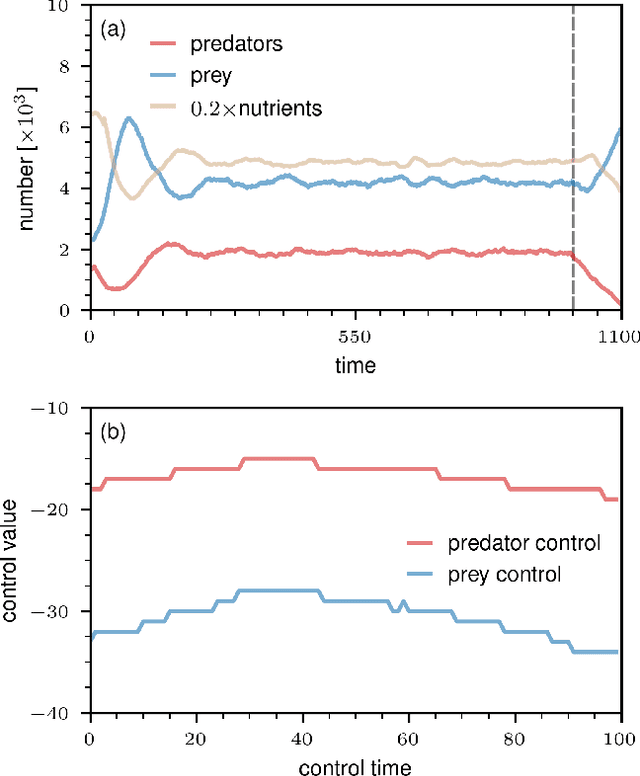
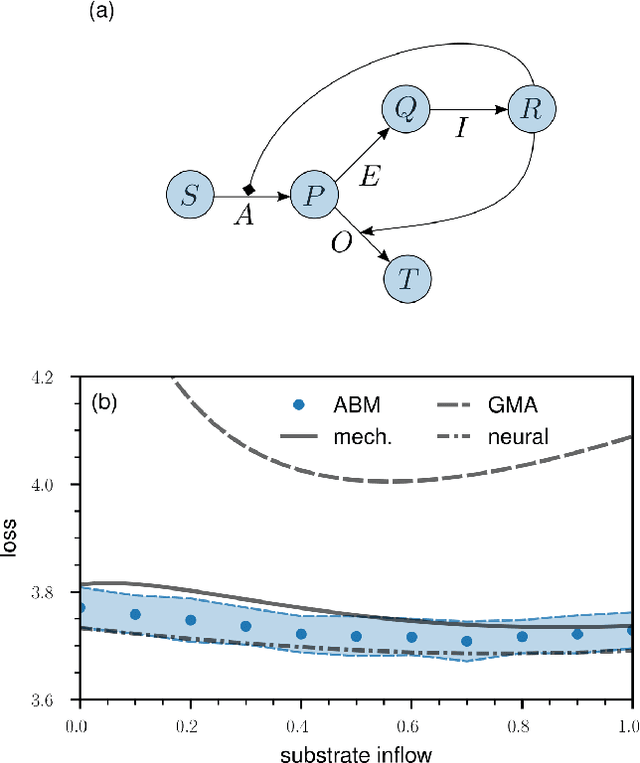
The objective of personalized medicine is to tailor interventions to an individual patient's unique characteristics. A key technology for this purpose involves medical digital twins, computational models of human biology that can be personalized and dynamically updated to incorporate patient-specific data collected over time. Certain aspects of human biology, such as the immune system, are not easily captured with physics-based models, such as differential equations. Instead, they are often multi-scale, stochastic, and hybrid. This poses a challenge to existing model-based control and optimization approaches that cannot be readily applied to such models. Recent advances in automatic differentiation and neural-network control methods hold promise in addressing complex control problems. However, the application of these approaches to biomedical systems is still in its early stages. This work introduces dynamics-informed neural-network controllers as an alternative approach to control of medical digital twins. As a first use case for this method, the focus is on agent-based models, a versatile and increasingly common modeling platform in biomedicine. The effectiveness of the proposed neural-network control method is illustrated and benchmarked against other methods with two widely-used agent-based model types. The relevance of the method introduced here extends beyond medical digital twins to other complex dynamical systems.
Lifelong Person Re-Identification with Backward-Compatibility
Mar 18, 2024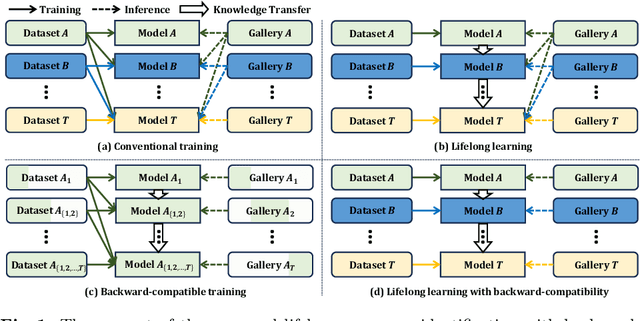
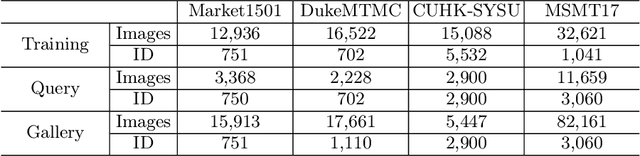
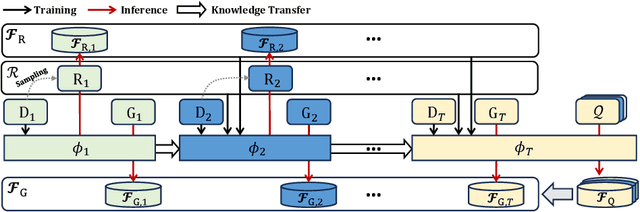
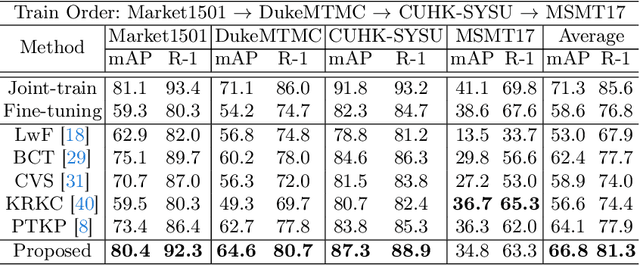
Lifelong person re-identification (LReID) assumes a practical scenario where the model is sequentially trained on continuously incoming datasets while alleviating the catastrophic forgetting in the old datasets. However, not only the training datasets but also the gallery images are incrementally accumulated, that requires a huge amount of computational complexity and storage space to extract the features at the inference phase. In this paper, we address the above mentioned problem by incorporating the backward-compatibility to LReID for the first time. We train the model using the continuously incoming datasets while maintaining the model's compatibility toward the previously trained old models without re-computing the features of the old gallery images. To this end, we devise the cross-model compatibility loss based on the contrastive learning with respect to the replay features across all the old datasets. Moreover, we also develop the knowledge consolidation method based on the part classification to learn the shared representation across different datasets for the backward-compatibility. We suggest a more practical methodology for performance evaluation as well where all the gallery and query images are considered together. Experimental results demonstrate that the proposed method achieves a significantly higher performance of the backward-compatibility compared with the existing methods. It is a promising tool for more practical scenarios of LReID.
Continual Forgetting for Pre-trained Vision Models
Mar 18, 2024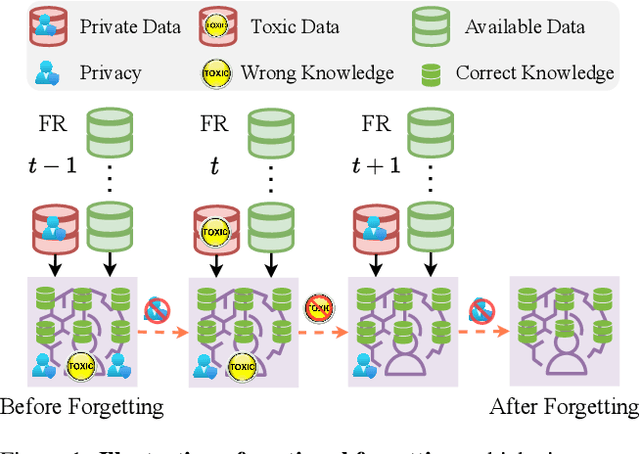
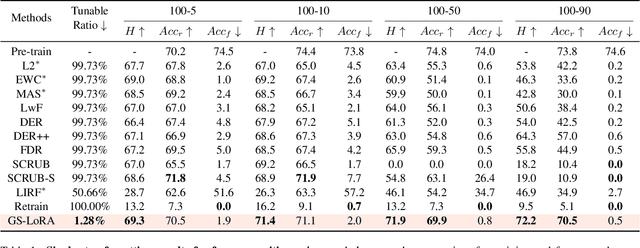
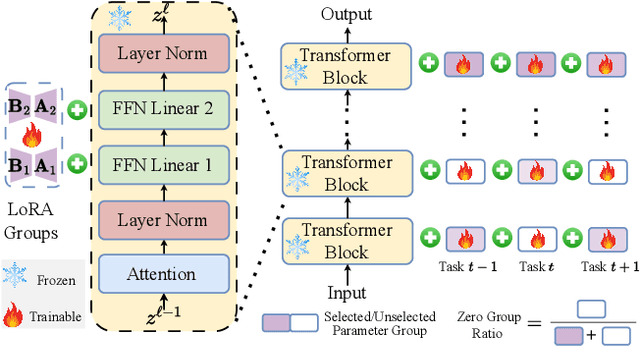
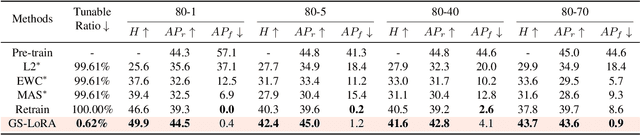
For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners. These requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify two key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. To address them, we propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we use LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. GS-LoRA is effective, parameter-efficient, data-efficient, and easy to implement. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that GS-LoRA manages to forget specific classes with minimal impact on other classes. Codes will be released on \url{https://github.com/bjzhb666/GS-LoRA}.
Siamese Learning with Joint Alignment and Regression for Weakly-Supervised Video Paragraph Grounding
Mar 18, 2024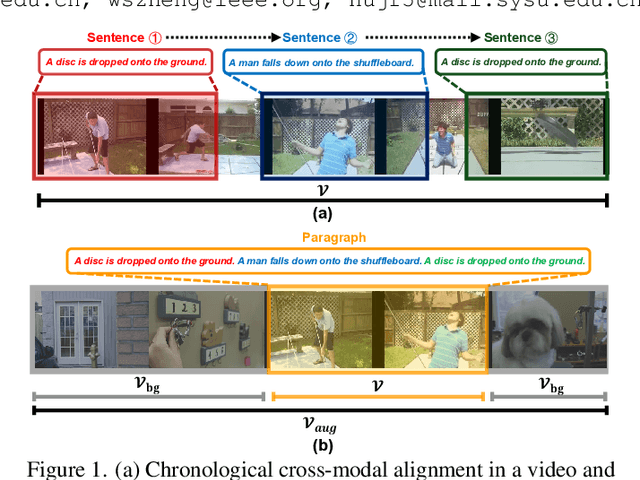
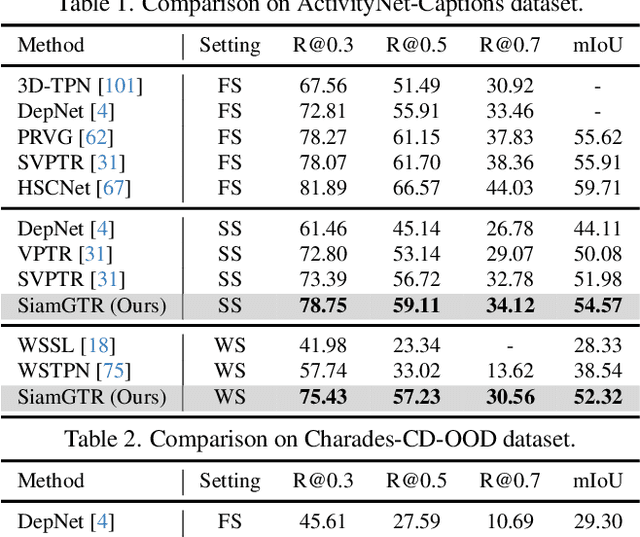
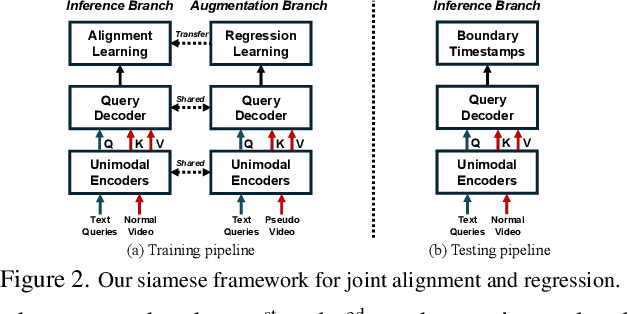
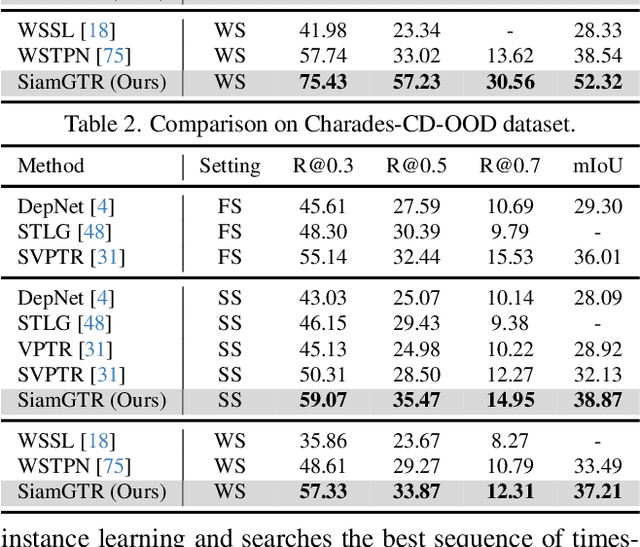
Video Paragraph Grounding (VPG) is an emerging task in video-language understanding, which aims at localizing multiple sentences with semantic relations and temporal order from an untrimmed video. However, existing VPG approaches are heavily reliant on a considerable number of temporal labels that are laborious and time-consuming to acquire. In this work, we introduce and explore Weakly-Supervised Video Paragraph Grounding (WSVPG) to eliminate the need of temporal annotations. Different from previous weakly-supervised grounding frameworks based on multiple instance learning or reconstruction learning for two-stage candidate ranking, we propose a novel siamese learning framework that jointly learns the cross-modal feature alignment and temporal coordinate regression without timestamp labels to achieve concise one-stage localization for WSVPG. Specifically, we devise a Siamese Grounding TRansformer (SiamGTR) consisting of two weight-sharing branches for learning complementary supervision. An Augmentation Branch is utilized for directly regressing the temporal boundaries of a complete paragraph within a pseudo video, and an Inference Branch is designed to capture the order-guided feature correspondence for localizing multiple sentences in a normal video. We demonstrate by extensive experiments that our paradigm has superior practicability and flexibility to achieve efficient weakly-supervised or semi-supervised learning, outperforming state-of-the-art methods trained with the same or stronger supervision.
Coarsening of chiral domains in itinerant electron magnets: A machine learning force field approach
Mar 18, 2024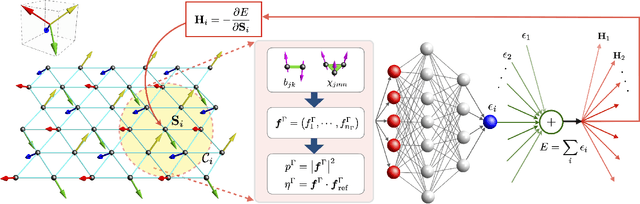
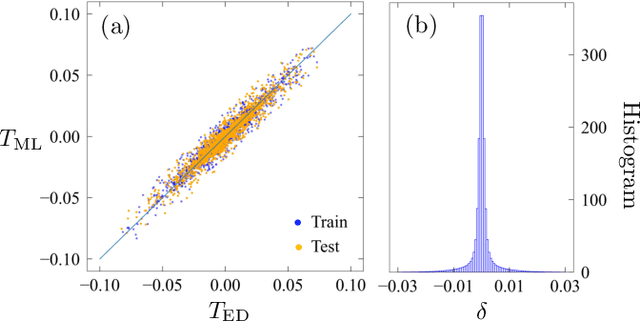
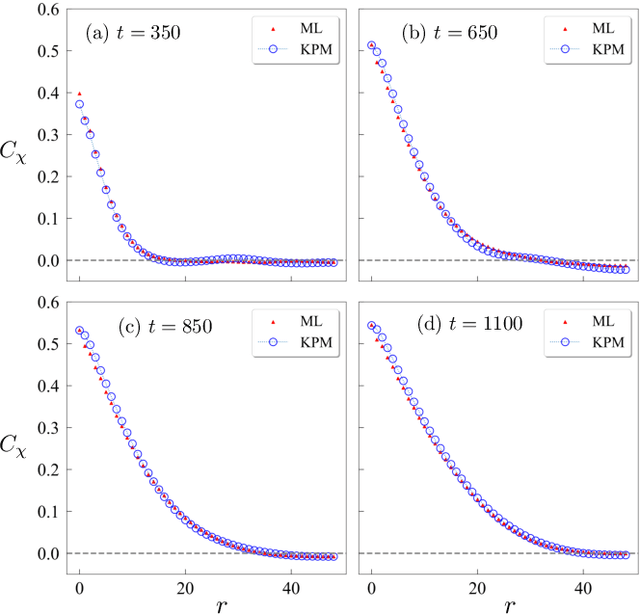
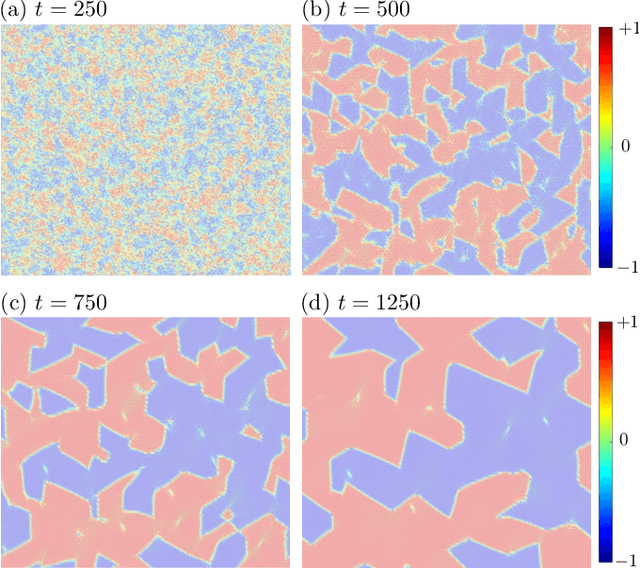
Frustrated itinerant magnets often exhibit complex noncollinear or noncoplanar magnetic orders which support topological electronic structures. A canonical example is the anomalous quantum Hall state with a chiral spin order stabilized by electron-spin interactions on a triangular lattice. While a long-range magnetic order cannot survive thermal fluctuations in two dimensions, the chiral order which results from the breaking of a discrete Ising symmetry persists even at finite temperatures. We present a scalable machine learning (ML) framework to model the complex electron-mediated spin-spin interactions that stabilize the chiral magnetic domains in a triangular lattice. Large-scale dynamical simulations, enabled by the ML force-field models, are performed to investigate the coarsening of chiral domains after a thermal quench. While the chiral phase is described by a broken $Z_2$ Ising-type symmetry, we find that the characteristic size of chiral domains increases linearly with time, in stark contrast to the expected Allen-Cahn domain growth law for a non-conserved Ising order parameter field. The linear growth of the chiral domains is attributed to the orientational anisotropy of domain boundaries. Our work also demonstrates the promising potential of ML models for large-scale spin dynamics of itinerant magnets.
NuGraph2: A Graph Neural Network for Neutrino Physics Event Reconstruction
Mar 18, 2024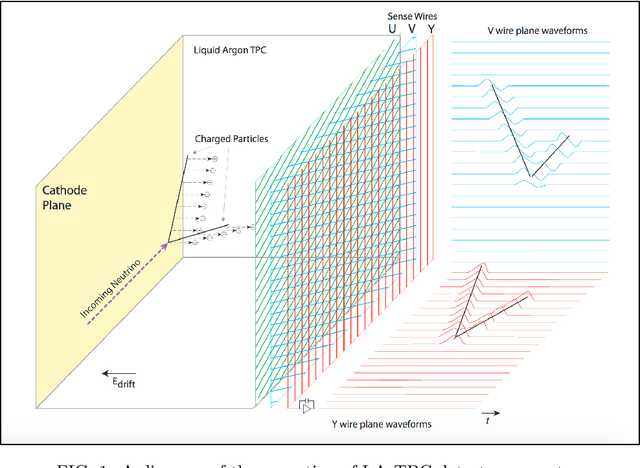
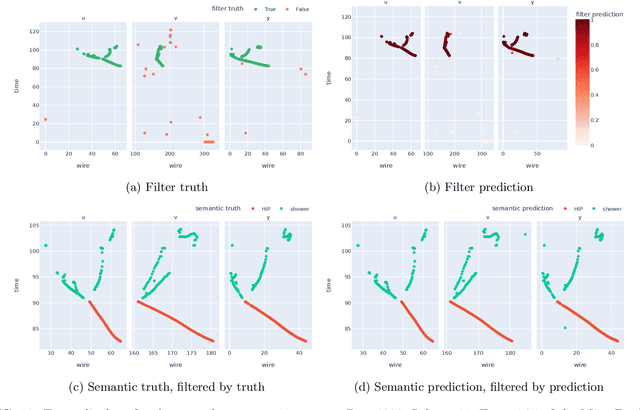
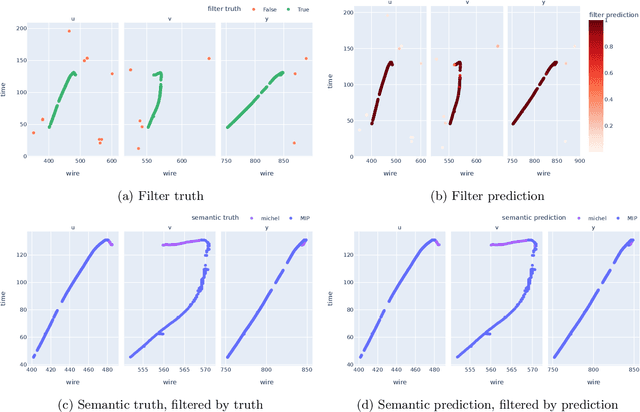
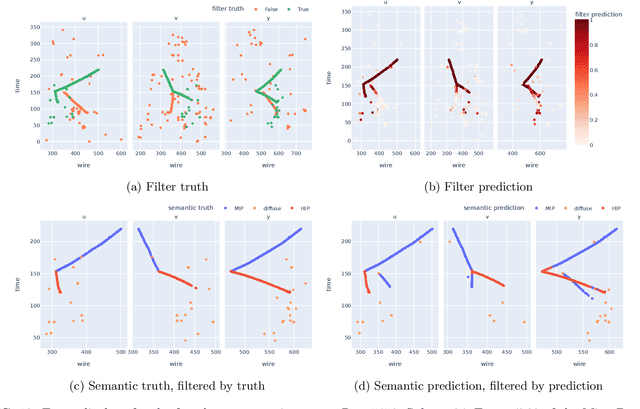
Liquid Argon Time Projection Chamber (LArTPC) detector technology offers a wealth of high-resolution information on particle interactions, and leveraging that information to its full potential requires sophisticated automated reconstruction techniques. This article describes NuGraph2, a Graph Neural Network (GNN) for low-level reconstruction of simulated neutrino interactions in a LArTPC detector. Simulated neutrino interactions in the MicroBooNE detector geometry are described as heterogeneous graphs, with energy depositions on each detector plane forming nodes on planar subgraphs. The network utilizes a multi-head attention message-passing mechanism to perform background filtering and semantic labelling on these graph nodes, identifying those associated with the primary physics interaction with 98.0\% efficiency and labelling them according to particle type with 94.9\% efficiency. The network operates directly on detector observables across multiple 2D representations, but utilizes a 3D-context-aware mechanism to encourage consistency between these representations. Model inference takes 0.12 s/event on a CPU, and 0.005 s/event batched on a GPU. This architecture is designed to be a general-purpose solution for particle reconstruction in neutrino physics, with the potential for deployment across a broad range of detector technologies, and offers a core convolution engine that can be leveraged for a variety of tasks beyond the two described in this article.
Continual Domain Randomization
Mar 18, 2024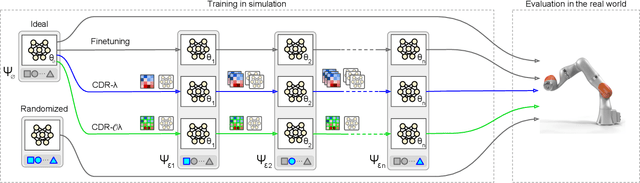

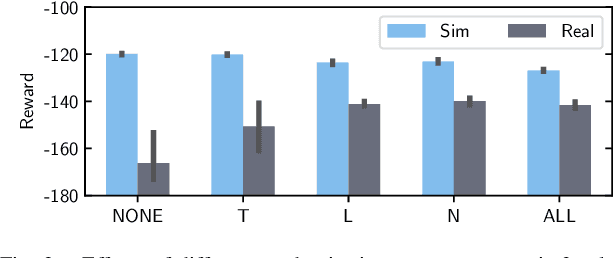
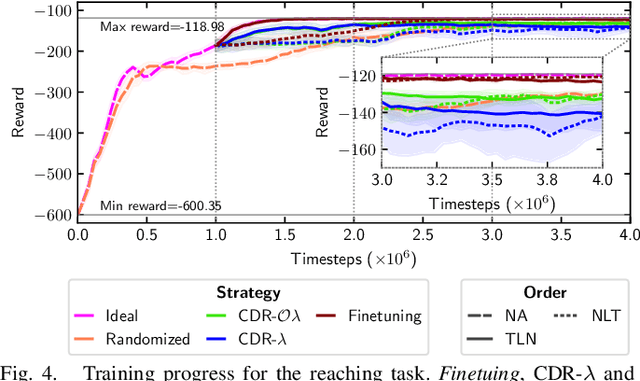
Domain Randomization (DR) is commonly used for sim2real transfer of reinforcement learning (RL) policies in robotics. Most DR approaches require a simulator with a fixed set of tunable parameters from the start of the training, from which the parameters are randomized simultaneously to train a robust model for use in the real world. However, the combined randomization of many parameters increases the task difficulty and might result in sub-optimal policies. To address this problem and to provide a more flexible training process, we propose Continual Domain Randomization (CDR) for RL that combines domain randomization with continual learning to enable sequential training in simulation on a subset of randomization parameters at a time. Starting from a model trained in a non-randomized simulation where the task is easier to solve, the model is trained on a sequence of randomizations, and continual learning is employed to remember the effects of previous randomizations. Our robotic reaching and grasping tasks experiments show that the model trained in this fashion learns effectively in simulation and performs robustly on the real robot while matching or outperforming baselines that employ combined randomization or sequential randomization without continual learning. Our code and videos are available at https://continual-dr.github.io/.