 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SceneX:Procedural Controllable Large-scale Scene Generation via Large-language Models
Mar 23, 2024
Due to its great application potential, large-scale scene generation has drawn extensive attention in academia and industry. Recent research employs powerful generative models to create desired scenes and achieves promising results. However, most of these methods represent the scene using 3D primitives (e.g. point cloud or radiance field) incompatible with the industrial pipeline, which leads to a substantial gap between academic research and industrial deployment. Procedural Controllable Generation (PCG) is an efficient technique for creating scalable and high-quality assets, but it is unfriendly for ordinary users as it demands profound domain expertise. To address these issues, we resort to using the large language model (LLM) to drive the procedural modeling. In this paper, we introduce a large-scale scene generation framework, SceneX, which can automatically produce high-quality procedural models according to designers' textual descriptions.Specifically, the proposed method comprises two components, PCGBench and PCGPlanner. The former encompasses an extensive collection of accessible procedural assets and thousands of hand-craft API documents. The latter aims to generate executable actions for Blender to produce controllable and precise 3D assets guided by the user's instructions. Our SceneX can generate a city spanning 2.5 km times 2.5 km with delicate layout and geometric structures, drastically reducing the time cost from several weeks for professional PCG engineers to just a few hours for an ordinary user. Extensive experiments demonstrated the capability of our method in controllable large-scale scene generation and editing, including asset placement and season translation.
Latent Attention for Linear Time Transformers
Feb 27, 2024The time complexity of the standard attention mechanism in a transformer scales quadratically with the length of the sequence. We introduce a method to reduce this to linear scaling with time, based on defining attention via latent vectors. The method is readily usable as a drop-in replacement for the standard attention mechanism. Our "Latte Transformer" model can be implemented for both bidirectional and unidirectional tasks, with the causal version allowing a recurrent implementation which is memory and time-efficient during inference of language generation tasks. Whilst next token prediction scales linearly with the sequence length for a standard transformer, a Latte Transformer requires constant time to compute the next token. The empirical performance of our method is comparable to standard attention, yet allows scaling to context windows much larger than practical in standard attention.
FFT-based Selection and Optimization of Statistics for Robust Recognition of Severely Corrupted Images
Mar 21, 2024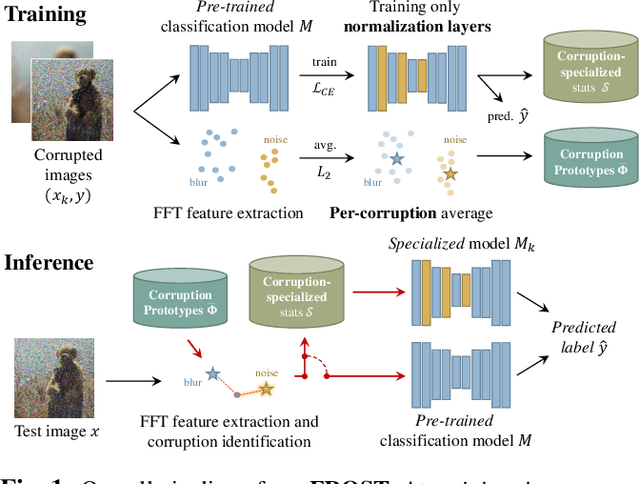
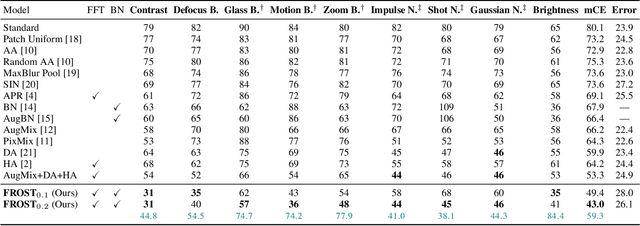
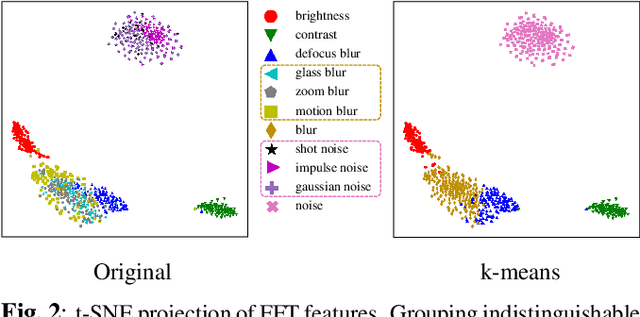

Improving model robustness in case of corrupted images is among the key challenges to enable robust vision systems on smart devices, such as robotic agents. Particularly, robust test-time performance is imperative for most of the applications. This paper presents a novel approach to improve robustness of any classification model, especially on severely corrupted images. Our method (FROST) employs high-frequency features to detect input image corruption type, and select layer-wise feature normalization statistics. FROST provides the state-of-the-art results for different models and datasets, outperforming competitors on ImageNet-C by up to 37.1% relative gain, improving baseline of 40.9% mCE on severe corruptions.
Robotics meets Fluid Dynamics: A Characterization of the Induced Airflow around a Quadrotor
Mar 20, 2024
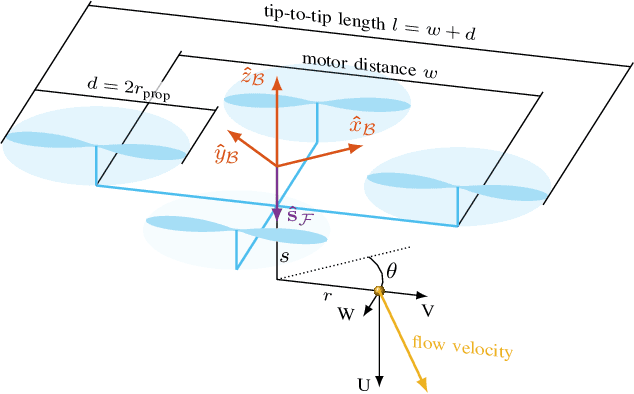

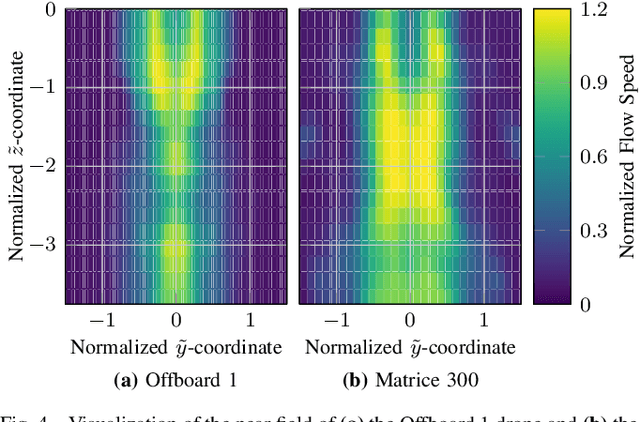
The widespread adoption of quadrotors for diverse applications, from agriculture to public safety, necessitates an understanding of the aerodynamic disturbances they create. This paper introduces a computationally lightweight model for estimating the time-averaged magnitude of the induced flow below quadrotors in hover. Unlike related approaches that rely on expensive computational fluid dynamics (CFD) simulations or time-consuming empirical measurements, our method leverages classical theory from turbulent flows. By analyzing over 9 hours of flight data from drones of varying sizes within a large motion capture system, we show that the combined flow from all propellers of the drone is well-approximated by a turbulent jet. Through the use of a novel normalization and scaling, we have developed and experimentally validated a unified model that describes the mean velocity field of the induced flow for different drone sizes. The model accurately describes the far-field airflow in a very large volume below the drone which is difficult to simulate in CFD. Our model, which requires only the drone's mass, propeller size, and drone size for calculations, offers a practical tool for dynamic planning in multi-agent scenarios, ensuring safer operations near humans and optimizing sensor placements.
Overview of Publicly Available Degradation Data Sets for Tasks within Prognostics and Health Management
Mar 20, 2024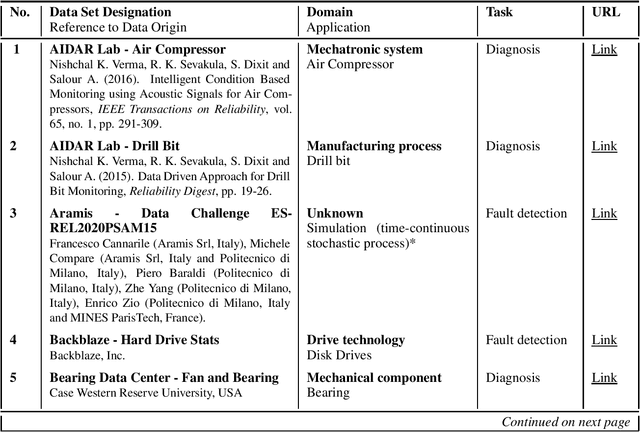
Central to the efficacy of prognostics and health management methods is the acquisition and analysis of degradation data, which encapsulates the evolving health condition of engineering systems over time. Degradation data serves as a rich source of information, offering invaluable insights into the underlying degradation processes, failure modes, and performance trends of engineering systems. This paper provides an overview of publicly available degradation data sets.
A Sub-Quadratic Time Algorithm for Robust Sparse Mean Estimation
Mar 07, 2024We study the algorithmic problem of sparse mean estimation in the presence of adversarial outliers. Specifically, the algorithm observes a \emph{corrupted} set of samples from $\mathcal{N}(\mu,\mathbf{I}_d)$, where the unknown mean $\mu \in \mathbb{R}^d$ is constrained to be $k$-sparse. A series of prior works has developed efficient algorithms for robust sparse mean estimation with sample complexity $\mathrm{poly}(k,\log d, 1/\epsilon)$ and runtime $d^2 \mathrm{poly}(k,\log d,1/\epsilon)$, where $\epsilon$ is the fraction of contamination. In particular, the fastest runtime of existing algorithms is quadratic ($\Omega(d^2)$), which can be prohibitive in high dimensions. This quadratic barrier in the runtime stems from the reliance of these algorithms on the sample covariance matrix, which is of size $d^2$. Our main contribution is an algorithm for robust sparse mean estimation which runs in \emph{subquadratic} time using $\mathrm{poly}(k,\log d,1/\epsilon)$ samples. We also provide analogous results for robust sparse PCA. Our results build on algorithmic advances in detecting weak correlations, a generalized version of the light-bulb problem by Valiant.
Reachability-based Trajectory Design via Exact Formulation of Implicit Neural Signed Distance Functions
Mar 18, 2024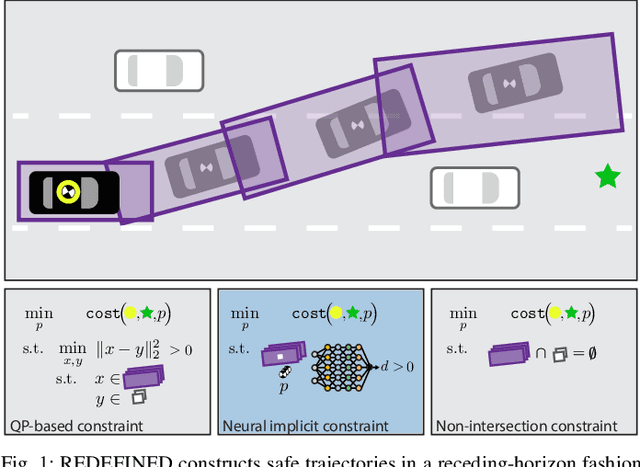
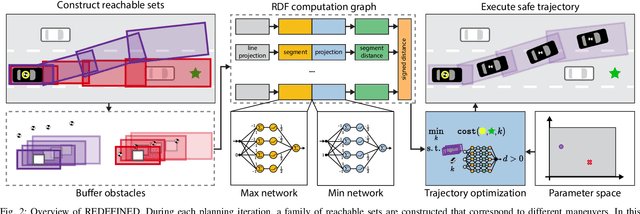
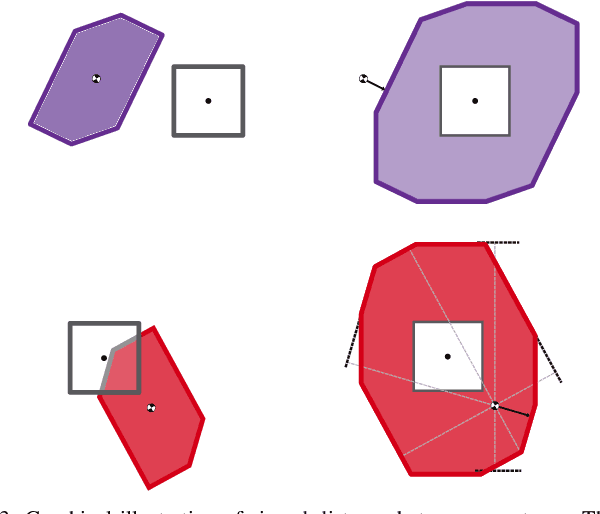
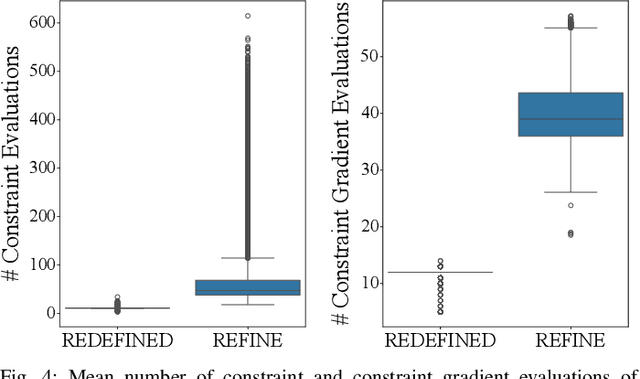
Generating receding-horizon motion trajectories for autonomous vehicles in real-time while also providing safety guarantees is challenging. This is because a future trajectory needs to be planned before the previously computed trajectory is completely executed. This becomes even more difficult if the trajectory is required to satisfy continuous-time collision-avoidance constraints while accounting for a large number of obstacles. To address these challenges, this paper proposes a novel real-time, receding-horizon motion planning algorithm named REachability-based trajectory Design via Exact Formulation of Implicit NEural signed Distance functions (REDEFINED). REDEFINED first applies offline reachability analysis to compute zonotope-based reachable sets that overapproximate the motion of the ego vehicle. During online planning, REDEFINED leverages zonotope arithmetic to construct a neural implicit representation that computes the exact signed distance between a parameterized swept volume of the ego vehicle and obstacle vehicles. REDEFINED then implements a novel, real-time optimization framework that utilizes the neural network to construct a collision avoidance constraint. REDEFINED is compared to a variety of state-of-the-art techniques and is demonstrated to successfully enable the vehicle to safely navigate through complex environments. Code, data, and video demonstrations can be found at https://roahmlab.github.io/redefined/.
Random Projection Layers for Multidimensional Time Series Forecasting
Feb 29, 2024All-Multi-Layer Perceptron (all-MLP) mixer models have been shown to be effective for time series forecasting problems. However, when such a model is applied to high-dimensional time series (e.g., the time series in a spatial-temporal dataset), its performance is likely to degrade due to overfitting issues. In this paper, we propose an all-MLP time series forecasting architecture, referred to as RPMixer. Our method leverages the ensemble-like behavior of deep neural networks, where each individual block within the network acts like a base learner in an ensemble model, especially when identity mapping residual connections are incorporated. By integrating random projection layers into our model, we increase the diversity among the blocks' outputs, thereby enhancing the overall performance of RPMixer. Extensive experiments conducted on large-scale spatial-temporal forecasting benchmark datasets demonstrate that our proposed method outperforms alternative methods, including both spatial-temporal graph models and general forecasting models.
Defying Imbalanced Forgetting in Class Incremental Learning
Mar 22, 2024We observe a high level of imbalance in the accuracy of different classes in the same old task for the first time. This intriguing phenomenon, discovered in replay-based Class Incremental Learning (CIL), highlights the imbalanced forgetting of learned classes, as their accuracy is similar before the occurrence of catastrophic forgetting. This discovery remains previously unidentified due to the reliance on average incremental accuracy as the measurement for CIL, which assumes that the accuracy of classes within the same task is similar. However, this assumption is invalid in the face of catastrophic forgetting. Further empirical studies indicate that this imbalanced forgetting is caused by conflicts in representation between semantically similar old and new classes. These conflicts are rooted in the data imbalance present in replay-based CIL methods. Building on these insights, we propose CLass-Aware Disentanglement (CLAD) to predict the old classes that are more likely to be forgotten and enhance their accuracy. Importantly, CLAD can be seamlessly integrated into existing CIL methods. Extensive experiments demonstrate that CLAD consistently improves current replay-based methods, resulting in performance gains of up to 2.56%.
Explore until Confident: Efficient Exploration for Embodied Question Answering
Mar 23, 2024We consider the problem of Embodied Question Answering (EQA), which refers to settings where an embodied agent such as a robot needs to actively explore an environment to gather information until it is confident about the answer to a question. In this work, we leverage the strong semantic reasoning capabilities of large vision-language models (VLMs) to efficiently explore and answer such questions. However, there are two main challenges when using VLMs in EQA: they do not have an internal memory for mapping the scene to be able to plan how to explore over time, and their confidence can be miscalibrated and can cause the robot to prematurely stop exploration or over-explore. We propose a method that first builds a semantic map of the scene based on depth information and via visual prompting of a VLM - leveraging its vast knowledge of relevant regions of the scene for exploration. Next, we use conformal prediction to calibrate the VLM's question answering confidence, allowing the robot to know when to stop exploration - leading to a more calibrated and efficient exploration strategy. To test our framework in simulation, we also contribute a new EQA dataset with diverse, realistic human-robot scenarios and scenes built upon the Habitat-Matterport 3D Research Dataset (HM3D). Both simulated and real robot experiments show our proposed approach improves the performance and efficiency over baselines that do no leverage VLM for exploration or do not calibrate its confidence. Webpage with experiment videos and code: https://explore-eqa.github.io/