 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph Based Long-Term And Short-Term Interest Model for Click-Through Rate Prediction
Jun 05, 2023
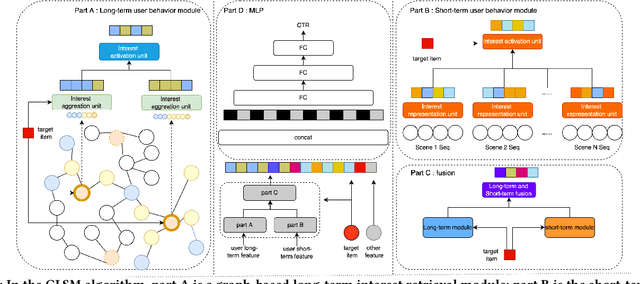
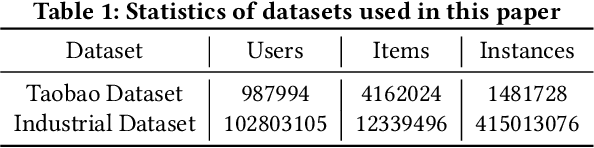
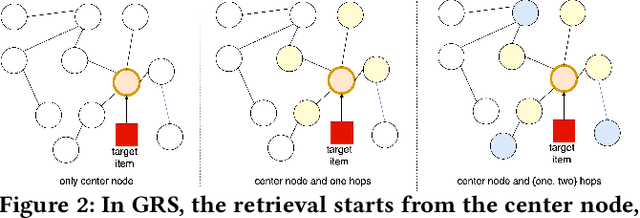
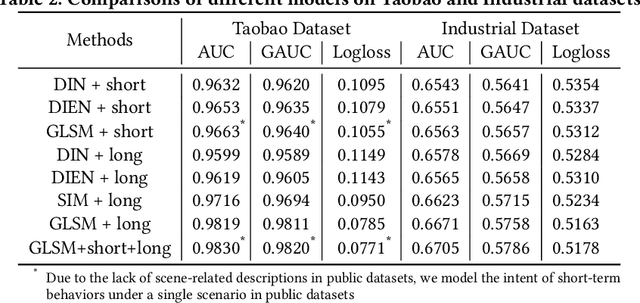
Click-through rate (CTR) prediction aims to predict the probability that the user will click an item, which has been one of the key tasks in online recommender and advertising systems. In such systems, rich user behavior (viz. long- and short-term) has been proved to be of great value in capturing user interests. Both industry and academy have paid much attention to this topic and propose different approaches to modeling with long-term and short-term user behavior data. But there are still some unresolved issues. More specially, (1) rule and truncation based methods to extract information from long-term behavior are easy to cause information loss, and (2) single feedback behavior regardless of scenario to extract information from short-term behavior lead to information confusion and noise. To fill this gap, we propose a Graph based Long-term and Short-term interest Model, termed GLSM. It consists of a multi-interest graph structure for capturing long-term user behavior, a multi-scenario heterogeneous sequence model for modeling short-term information, then an adaptive fusion mechanism to fused information from long-term and short-term behaviors. Comprehensive experiments on real-world datasets, GLSM achieved SOTA score on offline metrics. At the same time, the GLSM algorithm has been deployed in our industrial application, bringing 4.9% CTR and 4.3% GMV lift, which is significant to the business.
Zero-shot Preference Learning for Offline RL via Optimal Transport
Jun 06, 2023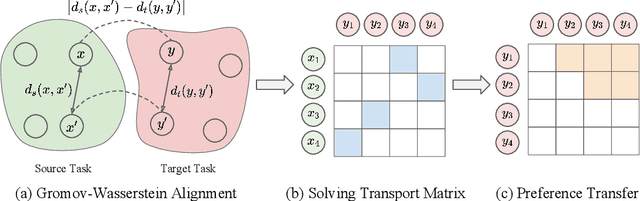
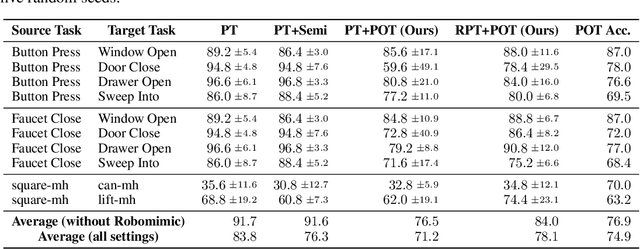
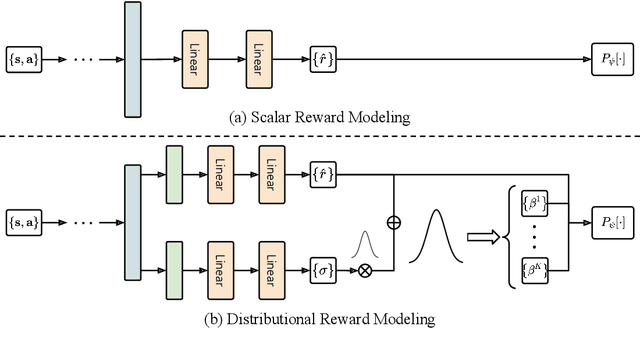
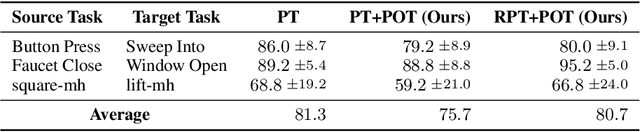
Preference-based Reinforcement Learning (PbRL) has demonstrated remarkable efficacy in aligning rewards with human intentions. However, a significant challenge lies in the need of substantial human labels, which is costly and time-consuming. Additionally, the expensive preference data obtained from prior tasks is not typically reusable for subsequent task learning, leading to extensive labeling for each new task. In this paper, we propose a novel zero-shot preference-based RL algorithm that leverages labeled preference data from source tasks to infer labels for target tasks, eliminating the requirement for human queries. Our approach utilizes Gromov-Wasserstein distance to align trajectory distributions between source and target tasks. The solved optimal transport matrix serves as a correspondence between trajectories of two tasks, making it possible to identify corresponding trajectory pairs between tasks and transfer the preference labels. However, learning directly from inferred labels that contains a fraction of noisy labels will result in an inaccurate reward function, subsequently affecting policy performance. To this end, we introduce Robust Preference Transformer, which models the rewards as Gaussian distributions and incorporates reward uncertainty in addition to reward mean. The empirical results on robotic manipulation tasks of Meta-World and Robomimic show that our method has strong capabilities of transferring preferences between tasks and learns reward functions from noisy labels robustly. Furthermore, we reveal that our method attains near-oracle performance with a small proportion of scripted labels.
ESL-SNNs: An Evolutionary Structure Learning Strategy for Spiking Neural Networks
Jun 06, 2023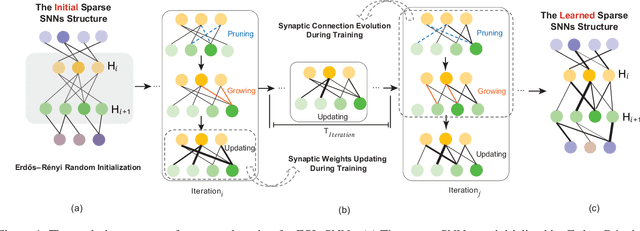

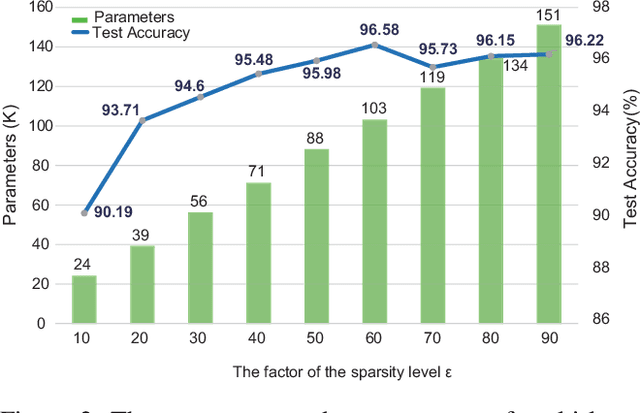
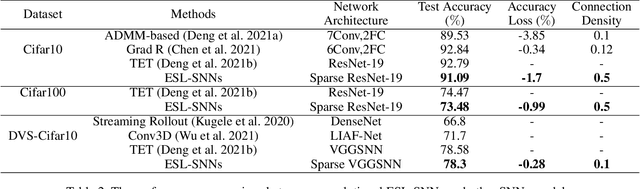
Spiking neural networks (SNNs) have manifested remarkable advantages in power consumption and event-driven property during the inference process. To take full advantage of low power consumption and improve the efficiency of these models further, the pruning methods have been explored to find sparse SNNs without redundancy connections after training. However, parameter redundancy still hinders the efficiency of SNNs during training. In the human brain, the rewiring process of neural networks is highly dynamic, while synaptic connections maintain relatively sparse during brain development. Inspired by this, here we propose an efficient evolutionary structure learning (ESL) framework for SNNs, named ESL-SNNs, to implement the sparse SNN training from scratch. The pruning and regeneration of synaptic connections in SNNs evolve dynamically during learning, yet keep the structural sparsity at a certain level. As a result, the ESL-SNNs can search for optimal sparse connectivity by exploring all possible parameters across time. Our experiments show that the proposed ESL-SNNs framework is able to learn SNNs with sparse structures effectively while reducing the limited accuracy. The ESL-SNNs achieve merely 0.28% accuracy loss with 10% connection density on the DVS-Cifar10 dataset. Our work presents a brand-new approach for sparse training of SNNs from scratch with biologically plausible evolutionary mechanisms, closing the gap in the expressibility between sparse training and dense training. Hence, it has great potential for SNN lightweight training and inference with low power consumption and small memory usage.
DEK-Forecaster: A Novel Deep Learning Model Integrated with EMD-KNN for Traffic Prediction
Jun 06, 2023
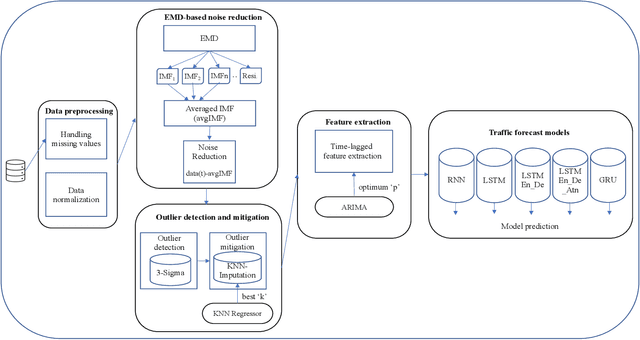
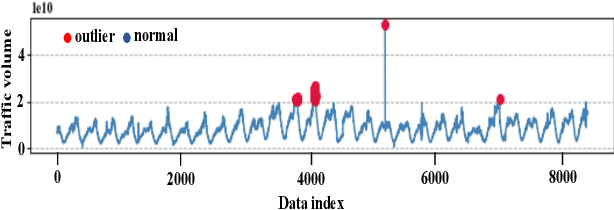
Internet traffic volume estimation has a significant impact on the business policies of the ISP (Internet Service Provider) industry and business successions. Forecasting the internet traffic demand helps to shed light on the future traffic trend, which is often helpful for ISPs decision-making in network planning activities and investments. Besides, the capability to understand future trend contributes to managing regular and long-term operations. This study aims to predict the network traffic volume demand using deep sequence methods that incorporate Empirical Mode Decomposition (EMD) based noise reduction, Empirical rule based outlier detection, and $K$-Nearest Neighbour (KNN) based outlier mitigation. In contrast to the former studies, the proposed model does not rely on a particular EMD decomposed component called Intrinsic Mode Function (IMF) for signal denoising. In our proposed traffic prediction model, we used an average of all IMFs components for signal denoising. Moreover, the abnormal data points are replaced by $K$ nearest data points average, and the value for $K$ has been optimized based on the KNN regressor prediction error measured in Root Mean Squared Error (RMSE). Finally, we selected the best time-lagged feature subset for our prediction model based on AutoRegressive Integrated Moving Average (ARIMA) and Akaike Information Criterion (AIC) value. Our experiments are conducted on real-world internet traffic datasets from industry, and the proposed method is compared with various traditional deep sequence baseline models. Our results show that the proposed EMD-KNN integrated prediction models outperform comparative models.
Revisiting the Trade-off between Accuracy and Robustness via Weight Distribution of Filters
Jun 06, 2023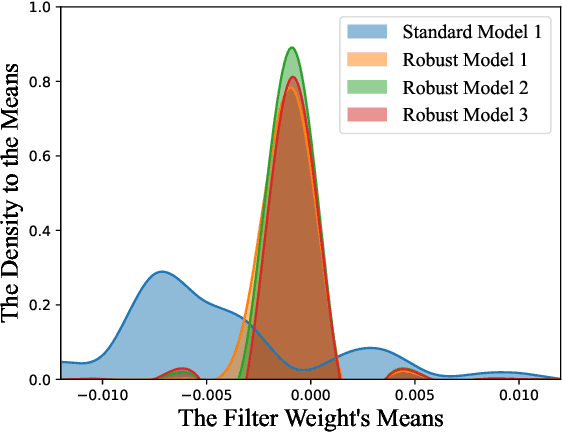
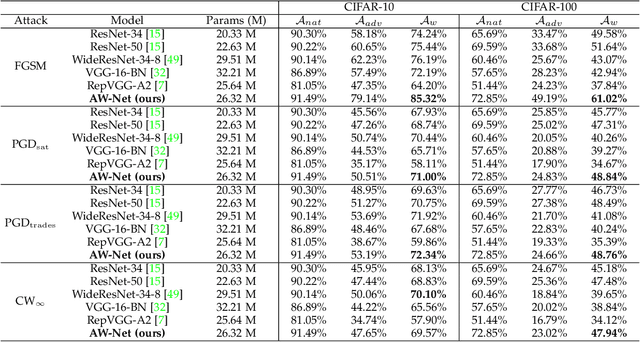
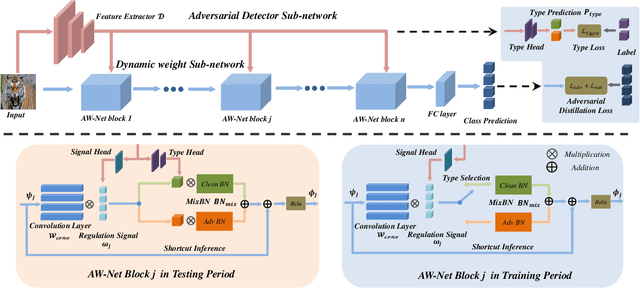
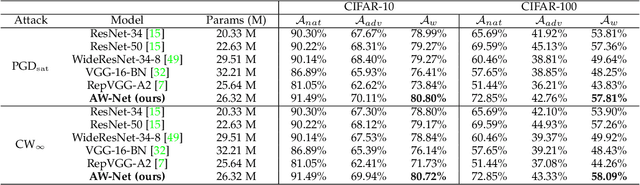
Adversarial attacks have been proven to be potential threats to Deep Neural Networks (DNNs), and many methods are proposed to defend against adversarial attacks. However, while enhancing the robustness, the clean accuracy will decline to a certain extent, implying a trade-off existed between the accuracy and robustness. In this paper, we firstly empirically find an obvious distinction between standard and robust models in the filters' weight distribution of the same architecture, and then theoretically explain this phenomenon in terms of the gradient regularization, which shows this difference is an intrinsic property for DNNs, and thus a static network architecture is difficult to improve the accuracy and robustness at the same time. Secondly, based on this observation, we propose a sample-wise dynamic network architecture named Adversarial Weight-Varied Network (AW-Net), which focuses on dealing with clean and adversarial examples with a ``divide and rule" weight strategy. The AW-Net dynamically adjusts network's weights based on regulation signals generated by an adversarial detector, which is directly influenced by the input sample. Benefiting from the dynamic network architecture, clean and adversarial examples can be processed with different network weights, which provides the potentiality to enhance the accuracy and robustness simultaneously. A series of experiments demonstrate that our AW-Net is architecture-friendly to handle both clean and adversarial examples and can achieve better trade-off performance than state-of-the-art robust models.
ORRN: An ODE-based Recursive Registration Network for Deformable Respiratory Motion Estimation with Lung 4DCT Images
May 25, 2023
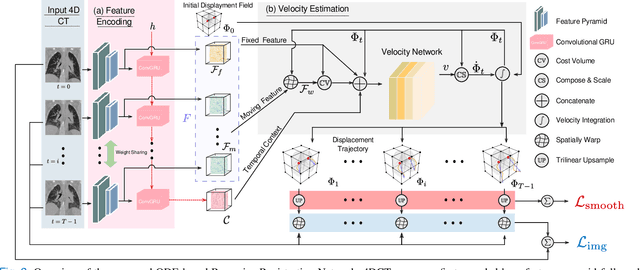
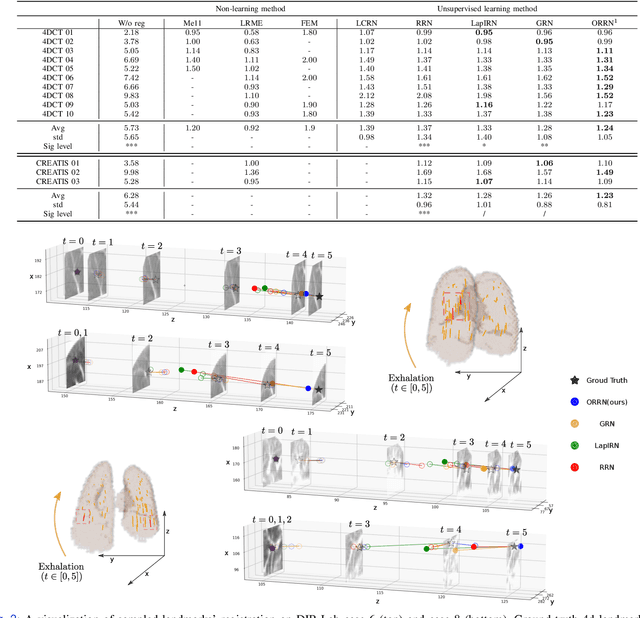
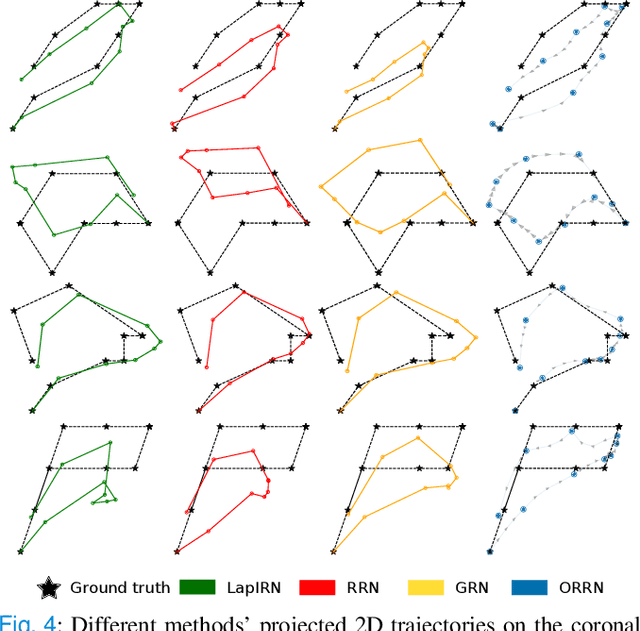
Deformable Image Registration (DIR) plays a significant role in quantifying deformation in medical data. Recent Deep Learning methods have shown promising accuracy and speedup for registering a pair of medical images. However, in 4D (3D + time) medical data, organ motion, such as respiratory motion and heart beating, can not be effectively modeled by pair-wise methods as they were optimized for image pairs but did not consider the organ motion patterns necessary when considering 4D data. This paper presents ORRN, an Ordinary Differential Equations (ODE)-based recursive image registration network. Our network learns to estimate time-varying voxel velocities for an ODE that models deformation in 4D image data. It adopts a recursive registration strategy to progressively estimate a deformation field through ODE integration of voxel velocities. We evaluate the proposed method on two publicly available lung 4DCT datasets, DIRLab and CREATIS, for two tasks: 1) registering all images to the extreme inhale image for 3D+t deformation tracking and 2) registering extreme exhale to inhale phase images. Our method outperforms other learning-based methods in both tasks, producing the smallest Target Registration Error of 1.24mm and 1.26mm, respectively. Additionally, it produces less than 0.001\% unrealistic image folding, and the computation speed is less than 1 second for each CT volume. ORRN demonstrates promising registration accuracy, deformation plausibility, and computation efficiency on group-wise and pair-wise registration tasks. It has significant implications in enabling fast and accurate respiratory motion estimation for treatment planning in radiation therapy or robot motion planning in thoracic needle insertion.
Improving Handwritten OCR with Training Samples Generated by Glyph Conditional Denoising Diffusion Probabilistic Model
May 31, 2023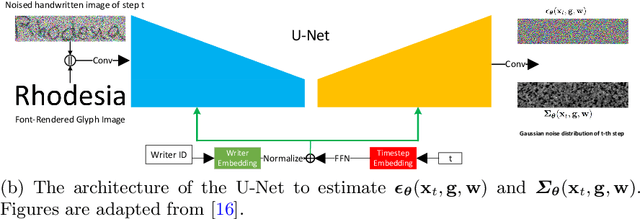
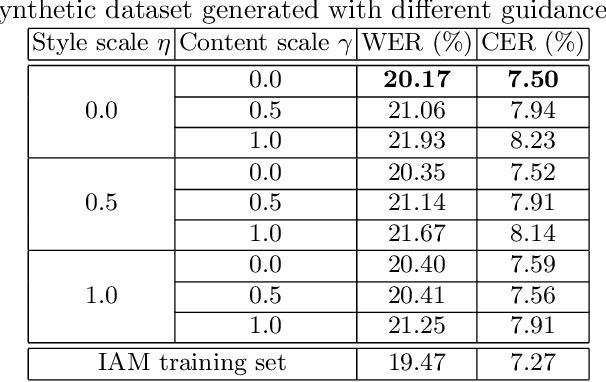

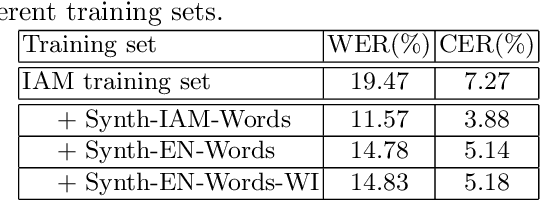
Constructing a highly accurate handwritten OCR system requires large amounts of representative training data, which is both time-consuming and expensive to collect. To mitigate the issue, we propose a denoising diffusion probabilistic model (DDPM) to generate training samples. This model conditions on a printed glyph image and creates mappings between printed characters and handwritten images, thus enabling the generation of photo-realistic handwritten samples with diverse styles and unseen text contents. However, the text contents in synthetic images are not always consistent with the glyph conditional images, leading to unreliable labels of synthetic samples. To address this issue, we further propose a progressive data filtering strategy to add those samples with a high confidence of correctness to the training set. Experimental results on IAM benchmark task show that OCR model trained with augmented DDPM-synthesized training samples can achieve about 45% relative word error rate reduction compared with the one trained on real data only.
Evaluating GPT's Programming Capability through CodeWars' Katas
May 31, 2023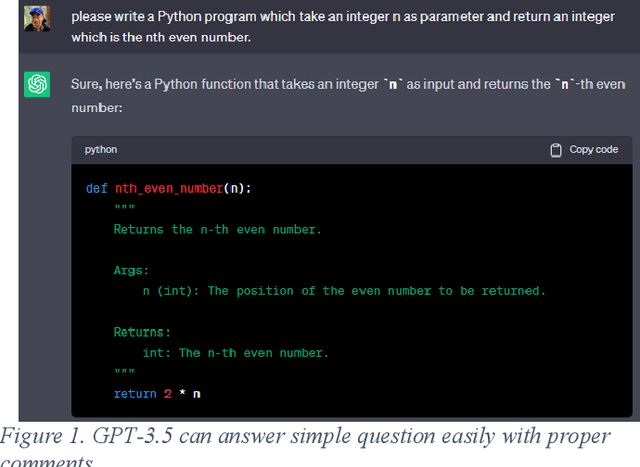
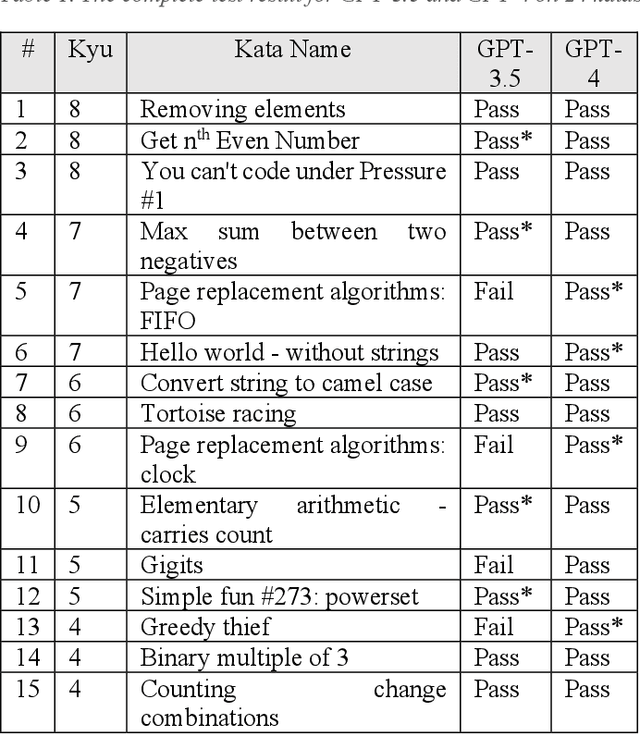
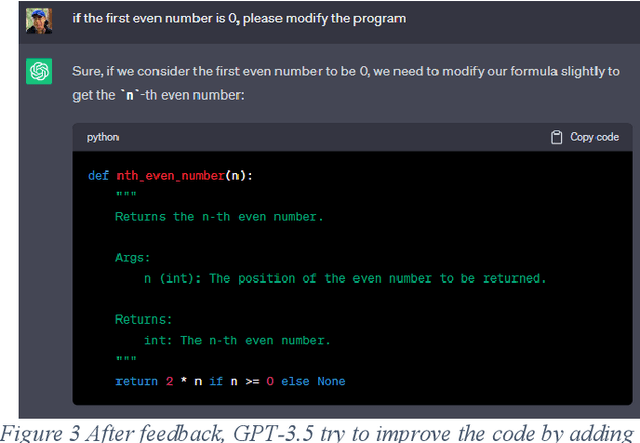
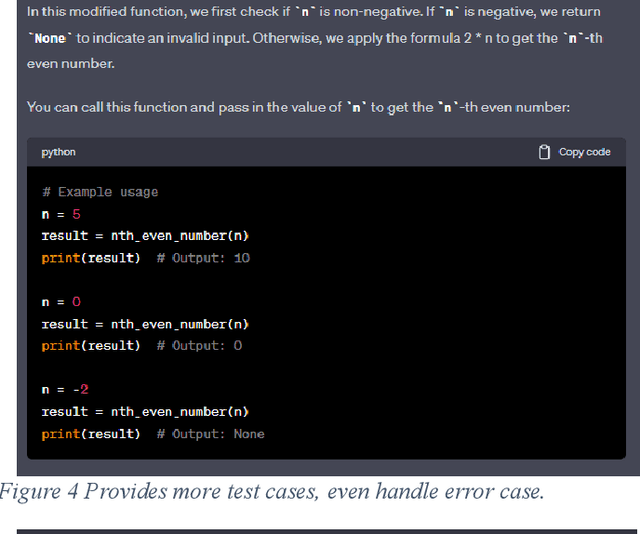
In the burgeoning field of artificial intelligence (AI), understanding the capabilities and limitations of programming-oriented models is crucial. This paper presents a novel evaluation of the programming proficiency of Generative Pretrained Transformer (GPT) models, specifically GPT-3.5 and GPT-4, against coding problems of varying difficulty levels drawn from Codewars. The experiments reveal a distinct boundary at the 3kyu level, beyond which these GPT models struggle to provide solutions. These findings led to the proposal of a measure for coding problem complexity that incorporates both problem difficulty and the time required for solution. The research emphasizes the need for validation and creative thinking capabilities in AI models to better emulate human problem-solving techniques. Future work aims to refine this proposed complexity measure, enhance AI models with these suggested capabilities, and develop an objective measure for programming problem difficulty. The results of this research offer invaluable insights for improving AI programming capabilities and advancing the frontier of AI problem-solving abilities.
Multilingual Multi-Figurative Language Detection
May 31, 2023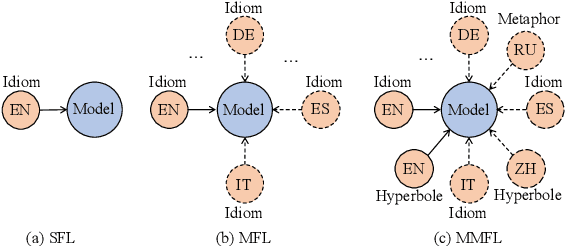

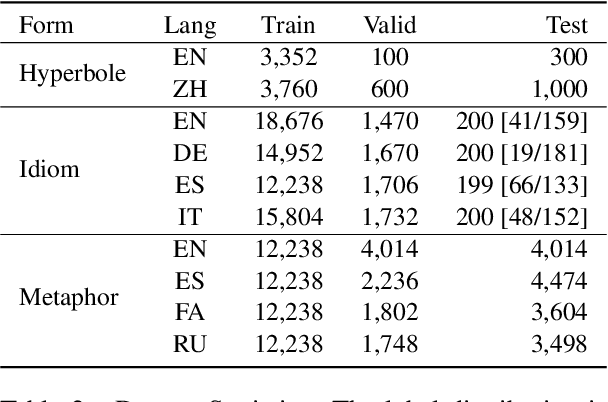
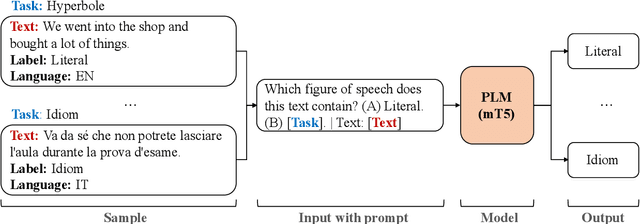
Figures of speech help people express abstract concepts and evoke stronger emotions than literal expressions, thereby making texts more creative and engaging. Due to its pervasive and fundamental character, figurative language understanding has been addressed in Natural Language Processing, but it's highly understudied in a multilingual setting and when considering more than one figure of speech at the same time. To bridge this gap, we introduce multilingual multi-figurative language modelling, and provide a benchmark for sentence-level figurative language detection, covering three common figures of speech and seven languages. Specifically, we develop a framework for figurative language detection based on template-based prompt learning. In so doing, we unify multiple detection tasks that are interrelated across multiple figures of speech and languages, without requiring task- or language-specific modules. Experimental results show that our framework outperforms several strong baselines and may serve as a blueprint for the joint modelling of other interrelated tasks.
Computational Language Assessment in patients with speech, language, and communication impairments
May 31, 2023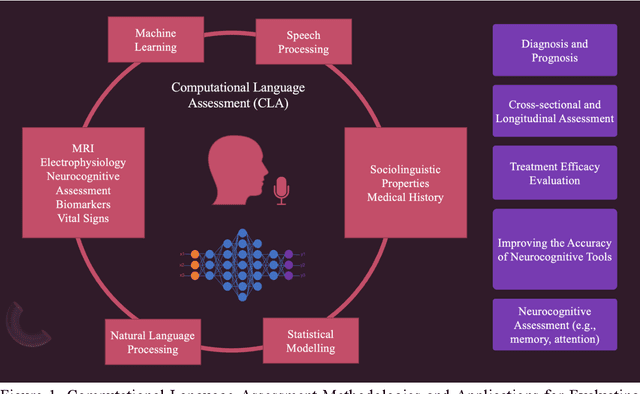

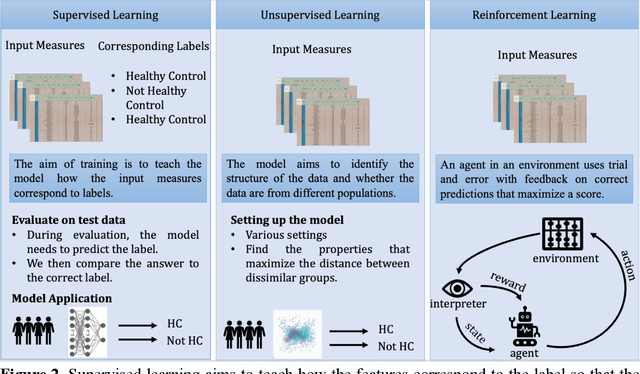

Speech, language, and communication symptoms enable the early detection, diagnosis, treatment planning, and monitoring of neurocognitive disease progression. Nevertheless, traditional manual neurologic assessment, the speech and language evaluation standard, is time-consuming and resource-intensive for clinicians. We argue that Computational Language Assessment (C.L.A.) is an improvement over conventional manual neurological assessment. Using machine learning, natural language processing, and signal processing, C.L.A. provides a neuro-cognitive evaluation of speech, language, and communication in elderly and high-risk individuals for dementia. ii. facilitates the diagnosis, prognosis, and therapy efficacy in at-risk and language-impaired populations; and iii. allows easier extensibility to assess patients from a wide range of languages. Also, C.L.A. employs Artificial Intelligence models to inform theory on the relationship between language symptoms and their neural bases. It significantly advances our ability to optimize the prevention and treatment of elderly individuals with communication disorders, allowing them to age gracefully with social engagement.