 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Foundation Time Series Model: To Synthesize Or Not To Synthesize?
Mar 04, 2024
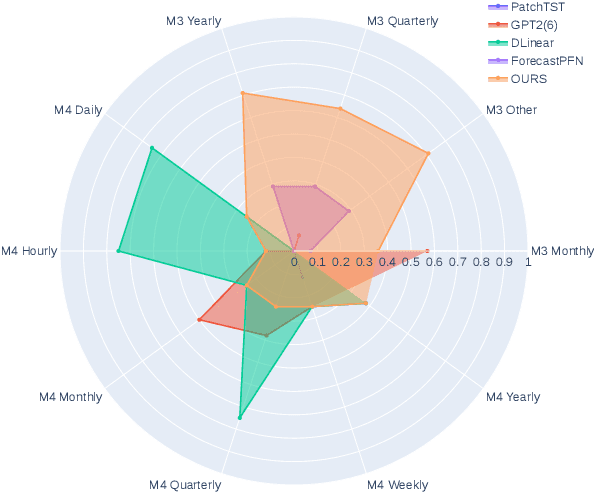

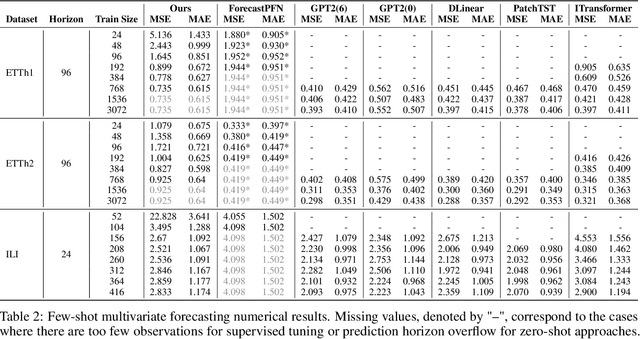
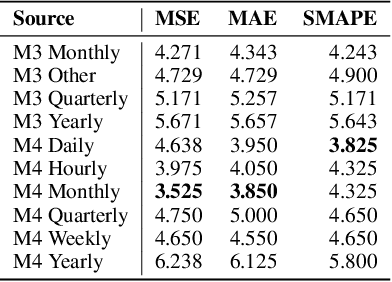
The industry is rich in cases when we are required to make forecasting for large amounts of time series at once. However, we might be in a situation where we can not afford to train a separate model for each of them. Such issue in time series modeling remains without due attention. The remedy for this setting is the establishment of a foundation model. Such a model is expected to work in zero-shot and few-shot regimes. However, what should we take as a training dataset for such kind of model? Witnessing the benefits from the enrichment of NLP datasets with artificially-generated data, we might want to adopt their experience for time series. In contrast to natural language, the process of generation of synthetic time series data is even more favorable because it provides full control of series patterns, time horizons, and number of samples. In this work, we consider the essential question if it is advantageous to train a foundation model on synthetic data or it is better to utilize only a limited number of real-life examples. Our experiments are conducted only for regular time series and speak in favor of leveraging solely the real time series. Moreover, the choice of the proper source dataset strongly influences the performance during inference. When provided access even to a limited quantity of short time series data, employing it within a supervised framework yields more favorable results than training on a larger volume of synthetic data. The code for our experiments is publicly available on Github \url{https://github.com/sb-ai-lab/synthesize_or_not}.
Brain Stroke Segmentation Using Deep Learning Models: A Comparative Study
Mar 25, 2024Stroke segmentation plays a crucial role in the diagnosis and treatment of stroke patients by providing spatial information about affected brain regions and the extent of damage. Segmenting stroke lesions accurately is a challenging task, given that conventional manual techniques are time consuming and prone to errors. Recently, advanced deep models have been introduced for general medical image segmentation, demonstrating promising results that surpass many state of the art networks when evaluated on specific datasets. With the advent of the vision Transformers, several models have been introduced based on them, while others have aimed to design better modules based on traditional convolutional layers to extract long-range dependencies like Transformers. The question of whether such high-level designs are necessary for all segmentation cases to achieve the best results remains unanswered. In this study, we selected four types of deep models that were recently proposed and evaluated their performance for stroke segmentation: a pure Transformer-based architecture (DAE-Former), two advanced CNN-based models (LKA and DLKA) with attention mechanisms in their design, an advanced hybrid model that incorporates CNNs with Transformers (FCT), and the well-known self-adaptive nnUNet framework with its configuration based on given data. We examined their performance on two publicly available datasets, and found that the nnUNet achieved the best results with the simplest design among all. Revealing the robustness issue of Transformers to such variabilities serves as a potential reason for their weaker performance. Furthermore, nnUNet's success underscores the significant impact of preprocessing and postprocessing techniques in enhancing segmentation results, surpassing the focus solely on architectural designs
Point-DETR3D: Leveraging Imagery Data with Spatial Point Prior for Weakly Semi-supervised 3D Object Detection
Mar 25, 2024Training high-accuracy 3D detectors necessitates massive labeled 3D annotations with 7 degree-of-freedom, which is laborious and time-consuming. Therefore, the form of point annotations is proposed to offer significant prospects for practical applications in 3D detection, which is not only more accessible and less expensive but also provides strong spatial information for object localization. In this paper, we empirically discover that it is non-trivial to merely adapt Point-DETR to its 3D form, encountering two main bottlenecks: 1) it fails to encode strong 3D prior into the model, and 2) it generates low-quality pseudo labels in distant regions due to the extreme sparsity of LiDAR points. To overcome these challenges, we introduce Point-DETR3D, a teacher-student framework for weakly semi-supervised 3D detection, designed to fully capitalize on point-wise supervision within a constrained instance-wise annotation budget.Different from Point-DETR which encodes 3D positional information solely through a point encoder, we propose an explicit positional query initialization strategy to enhance the positional prior. Considering the low quality of pseudo labels at distant regions produced by the teacher model, we enhance the detector's perception by incorporating dense imagery data through a novel Cross-Modal Deformable RoI Fusion (D-RoI).Moreover, an innovative point-guided self-supervised learning technique is proposed to allow for fully exploiting point priors, even in student models.Extensive experiments on representative nuScenes dataset demonstrate our Point-DETR3D obtains significant improvements compared to previous works. Notably, with only 5% of labeled data, Point-DETR3D achieves over 90% performance of its fully supervised counterpart.
CBGT-Net: A Neuromimetic Architecture for Robust Classification of Streaming Data
Mar 24, 2024This paper describes CBGT-Net, a neural network model inspired by the cortico-basal ganglia-thalamic (CBGT) circuits found in mammalian brains. Unlike traditional neural network models, which either generate an output for each provided input, or an output after a fixed sequence of inputs, the CBGT-Net learns to produce an output after a sufficient criteria for evidence is achieved from a stream of observed data. For each observation, the CBGT-Net generates a vector that explicitly represents the amount of evidence the observation provides for each potential decision, accumulates the evidence over time, and generates a decision when the accumulated evidence exceeds a pre-defined threshold. We evaluate the proposed model on two image classification tasks, where models need to predict image categories based on a stream of small patches extracted from the image. We show that the CBGT-Net provides improved accuracy and robustness compared to models trained to classify from a single patch, and models leveraging an LSTM layer to classify from a fixed sequence length of patches.
Scaling Learning based Policy Optimization for Temporal Tasks via Dropout
Mar 23, 2024This paper introduces a model-based approach for training feedback controllers for an autonomous agent operating in a highly nonlinear environment. We desire the trained policy to ensure that the agent satisfies specific task objectives, expressed in discrete-time Signal Temporal Logic (DT-STL). One advantage for reformulation of a task via formal frameworks, like DT-STL, is that it permits quantitative satisfaction semantics. In other words, given a trajectory and a DT-STL formula, we can compute the robustness, which can be interpreted as an approximate signed distance between the trajectory and the set of trajectories satisfying the formula. We utilize feedback controllers, and we assume a feed forward neural network for learning these feedback controllers. We show how this learning problem is similar to training recurrent neural networks (RNNs), where the number of recurrent units is proportional to the temporal horizon of the agent's task objectives. This poses a challenge: RNNs are susceptible to vanishing and exploding gradients, and na\"{i}ve gradient descent-based strategies to solve long-horizon task objectives thus suffer from the same problems. To tackle this challenge, we introduce a novel gradient approximation algorithm based on the idea of dropout or gradient sampling. We show that, the existing smooth semantics for robustness are inefficient regarding gradient computation when the specification becomes complex. To address this challenge, we propose a new smooth semantics for DT-STL that under-approximates the robustness value and scales well for backpropagation over a complex specification. We show that our control synthesis methodology, can be quite helpful for stochastic gradient descent to converge with less numerical issues, enabling scalable backpropagation over long time horizons and trajectories over high dimensional state spaces.
No more optimization rules: LLM-enabled policy-based multi-modal query optimizer
Mar 23, 2024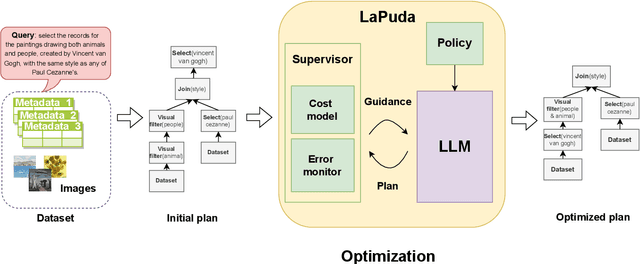
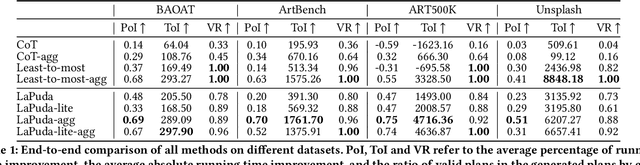
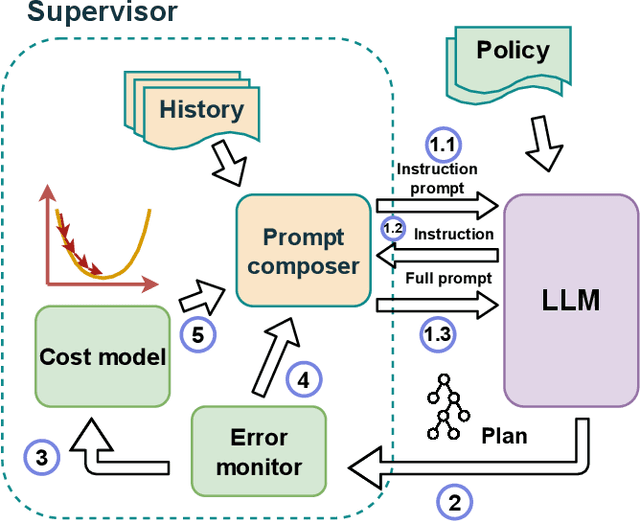
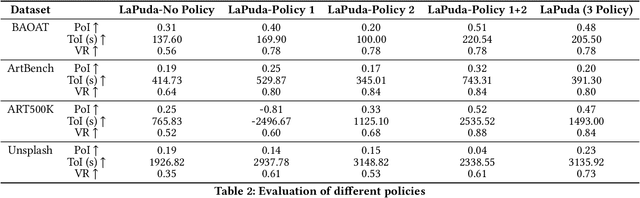
Large language model (LLM) has marked a pivotal moment in the field of machine learning and deep learning. Recently its capability for query planning has been investigated, including both single-modal and multi-modal queries. However, there is no work on the query optimization capability of LLM. As a critical (or could even be the most important) step that significantly impacts the execution performance of the query plan, such analysis and attempts should not be missed. From another aspect, existing query optimizers are usually rule-based or rule-based + cost-based, i.e., they are dependent on manually created rules to complete the query plan rewrite/transformation. Given the fact that modern optimizers include hundreds to thousands of rules, designing a multi-modal query optimizer following a similar way is significantly time-consuming since we will have to enumerate as many multi-modal optimization rules as possible, which has not been well addressed today. In this paper, we investigate the query optimization ability of LLM and use LLM to design LaPuda, a novel LLM and Policy based multi-modal query optimizer. Instead of enumerating specific and detailed rules, LaPuda only needs a few abstract policies to guide LLM in the optimization, by which much time and human effort are saved. Furthermore, to prevent LLM from making mistakes or negative optimization, we borrow the idea of gradient descent and propose a guided cost descent (GCD) algorithm to perform the optimization, such that the optimization can be kept in the correct direction. In our evaluation, our methods consistently outperform the baselines in most cases. For example, the optimized plans generated by our methods result in 1~3x higher execution speed than those by the baselines.
TOTEM: TOkenized Time Series EMbeddings for General Time Series Analysis
Feb 26, 2024The field of general time series analysis has recently begun to explore unified modeling, where a common architectural backbone can be retrained on a specific task for a specific dataset. In this work, we approach unification from a complementary vantage point: unification across tasks and domains. To this end, we explore the impact of discrete, learnt, time series data representations that enable generalist, cross-domain training. Our method, TOTEM, or TOkenized Time Series EMbeddings, proposes a simple tokenizer architecture that embeds time series data from varying domains using a discrete vectorized representation learned in a self-supervised manner. TOTEM works across multiple tasks and domains with minimal to no tuning. We study the efficacy of TOTEM with an extensive evaluation on 17 real world time series datasets across 3 tasks. We evaluate both the specialist (i.e., training a model on each domain) and generalist (i.e., training a single model on many domains) settings, and show that TOTEM matches or outperforms previous best methods on several popular benchmarks. The code can be found at: https://github.com/SaberaTalukder/TOTEM.
A priori Estimates for Deep Residual Network in Continuous-time Reinforcement Learning
Mar 07, 2024Deep reinforcement learning excels in numerous large-scale practical applications. However, existing performance analyses ignores the unique characteristics of continuous-time control problems, is unable to directly estimate the generalization error of the Bellman optimal loss and require a boundedness assumption. Our work focuses on continuous-time control problems and proposes a method that is applicable to all such problems where the transition function satisfies semi-group and Lipschitz properties. Under this method, we can directly analyze the \emph{a priori} generalization error of the Bellman optimal loss. The core of this method lies in two transformations of the loss function. To complete the transformation, we propose a decomposition method for the maximum operator. Additionally, this analysis method does not require a boundedness assumption. Finally, we obtain an \emph{a priori} generalization error without the curse of dimensionality.
Splat-Nav: Safe Real-Time Robot Navigation in Gaussian Splatting Maps
Mar 05, 2024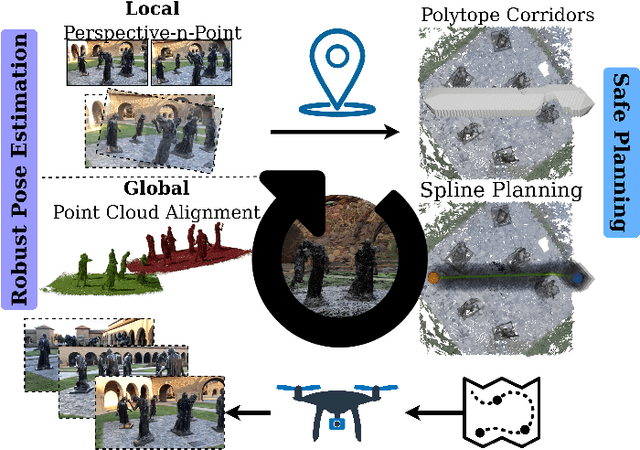
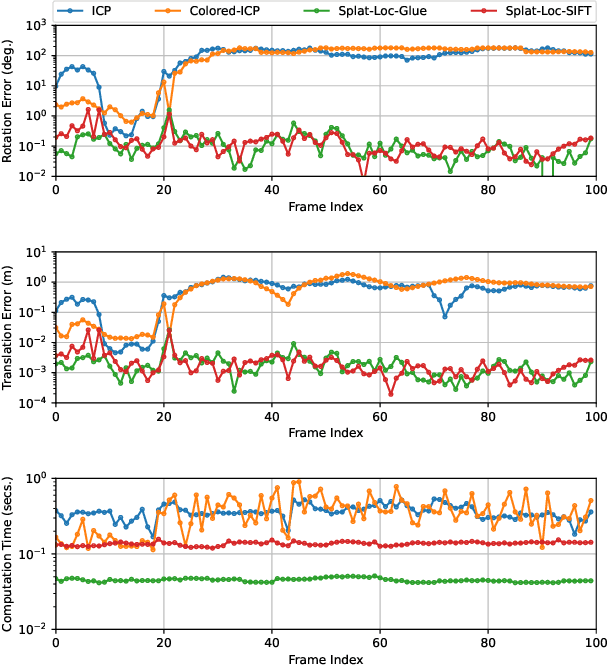
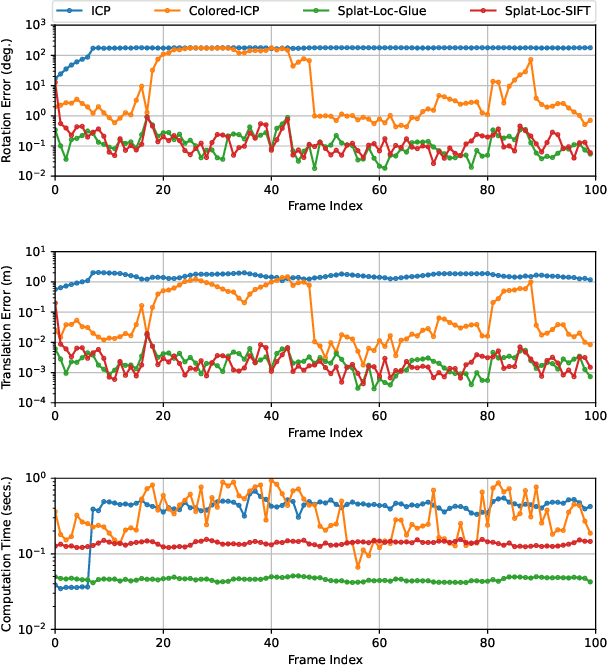

We present Splat-Nav, a navigation pipeline that consists of a real-time safe planning module and a robust state estimation module designed to operate in the Gaussian Splatting (GSplat) environment representation, a popular emerging 3D scene representation from computer vision. We formulate rigorous collision constraints that can be computed quickly to build a guaranteed-safe polytope corridor through the map. We then optimize a B-spline trajectory through this corridor. We also develop a real-time, robust state estimation module by interpreting the GSplat representation as a point cloud. The module enables the robot to localize its global pose with zero prior knowledge from RGB-D images using point cloud alignment, and then track its own pose as it moves through the scene from RGB images using image-to-point cloud localization. We also incorporate semantics into the GSplat in order to obtain better images for localization. All of these modules operate mainly on CPU, freeing up GPU resources for tasks like real-time scene reconstruction. We demonstrate the safety and robustness of our pipeline in both simulation and hardware, where we show re-planning at 5 Hz and pose estimation at 20 Hz, an order of magnitude faster than Neural Radiance Field (NeRF)-based navigation methods, thereby enabling real-time navigation.
HDRFlow: Real-Time HDR Video Reconstruction with Large Motions
Mar 06, 2024
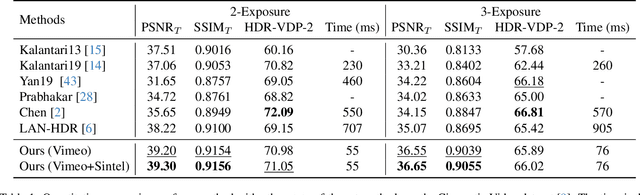

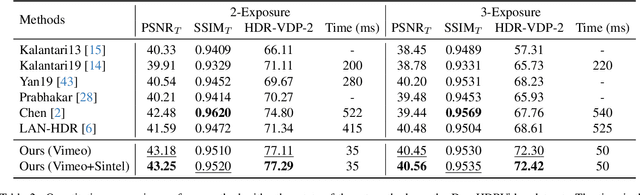
Reconstructing High Dynamic Range (HDR) video from image sequences captured with alternating exposures is challenging, especially in the presence of large camera or object motion. Existing methods typically align low dynamic range sequences using optical flow or attention mechanism for deghosting. However, they often struggle to handle large complex motions and are computationally expensive. To address these challenges, we propose a robust and efficient flow estimator tailored for real-time HDR video reconstruction, named HDRFlow. HDRFlow has three novel designs: an HDR-domain alignment loss (HALoss), an efficient flow network with a multi-size large kernel (MLK), and a new HDR flow training scheme. The HALoss supervises our flow network to learn an HDR-oriented flow for accurate alignment in saturated and dark regions. The MLK can effectively model large motions at a negligible cost. In addition, we incorporate synthetic data, Sintel, into our training dataset, utilizing both its provided forward flow and backward flow generated by us to supervise our flow network, enhancing our performance in large motion regions. Extensive experiments demonstrate that our HDRFlow outperforms previous methods on standard benchmarks. To the best of our knowledge, HDRFlow is the first real-time HDR video reconstruction method for video sequences captured with alternating exposures, capable of processing 720p resolution inputs at 25ms.