 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Co-Attention Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
Jul 11, 2023
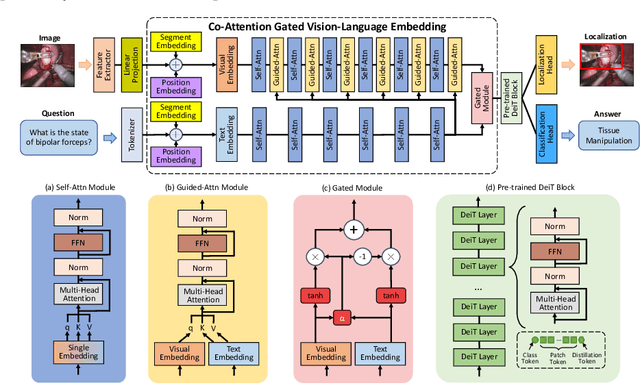
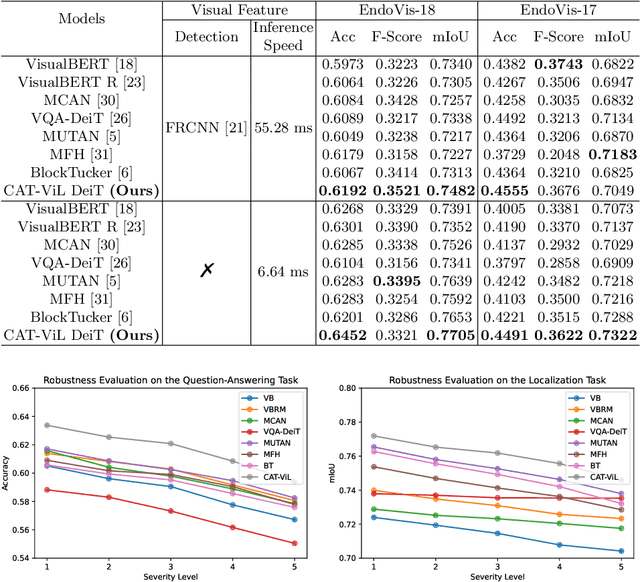
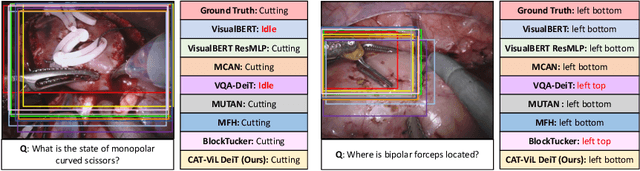
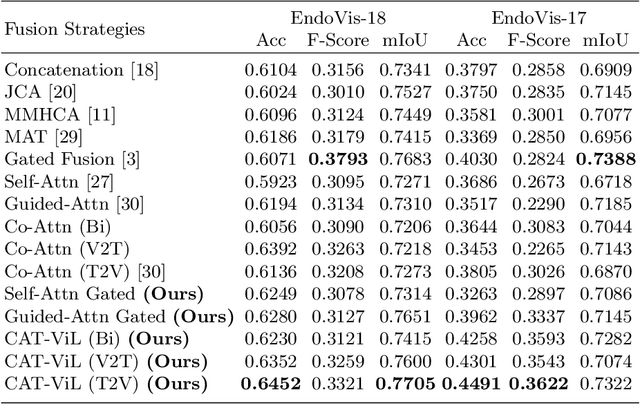
Medical students and junior surgeons often rely on senior surgeons and specialists to answer their questions when learning surgery. However, experts are often busy with clinical and academic work, and have little time to give guidance. Meanwhile, existing deep learning (DL)-based surgical Visual Question Answering (VQA) systems can only provide simple answers without the location of the answers. In addition, vision-language (ViL) embedding is still a less explored research in these kinds of tasks. Therefore, a surgical Visual Question Localized-Answering (VQLA) system would be helpful for medical students and junior surgeons to learn and understand from recorded surgical videos. We propose an end-to-end Transformer with Co-Attention gaTed Vision-Language (CAT-ViL) for VQLA in surgical scenarios, which does not require feature extraction through detection models. The CAT-ViL embedding module is designed to fuse heterogeneous features from visual and textual sources. The fused embedding will feed a standard Data-Efficient Image Transformer (DeiT) module, before the parallel classifier and detector for joint prediction. We conduct the experimental validation on public surgical videos from MICCAI EndoVis Challenge 2017 and 2018. The experimental results highlight the superior performance and robustness of our proposed model compared to the state-of-the-art approaches. Ablation studies further prove the outstanding performance of all the proposed components. The proposed method provides a promising solution for surgical scene understanding, and opens up a primary step in the Artificial Intelligence (AI)-based VQLA system for surgical training. Our code is publicly available.
Adaptive Principal Component Regression with Applications to Panel Data
Jul 03, 2023Principal component regression (PCR) is a popular technique for fixed-design error-in-variables regression, a generalization of the linear regression setting in which the observed covariates are corrupted with random noise. We provide the first time-uniform finite sample guarantees for online (regularized) PCR whenever data is collected adaptively. Since the proof techniques for analyzing PCR in the fixed design setting do not readily extend to the online setting, our results rely on adapting tools from modern martingale concentration to the error-in-variables setting. As an application of our bounds, we provide a framework for experiment design in panel data settings when interventions are assigned adaptively. Our framework may be thought of as a generalization of the synthetic control and synthetic interventions frameworks, where data is collected via an adaptive intervention assignment policy.
AVSegFormer: Audio-Visual Segmentation with Transformer
Jul 05, 2023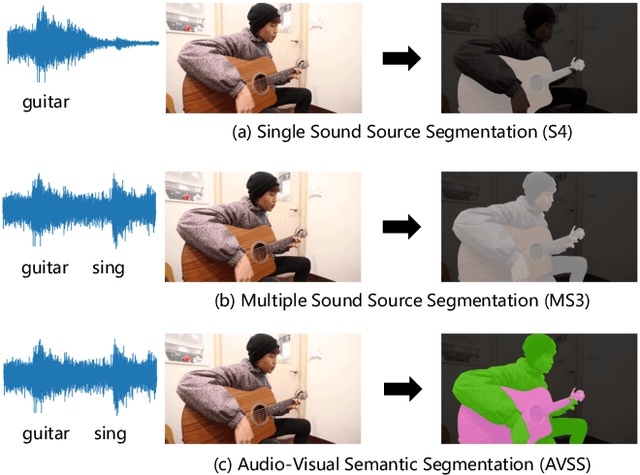
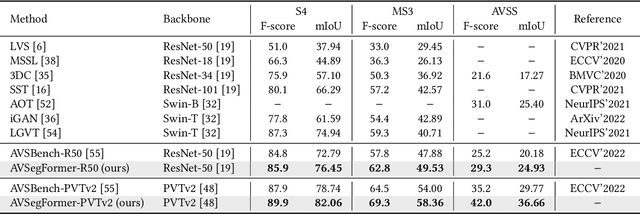
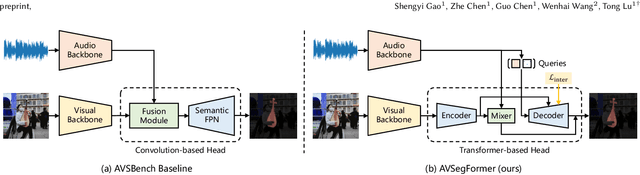
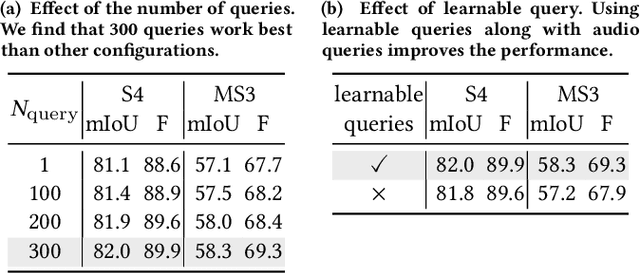
The combination of audio and vision has long been a topic of interest in the multi-modal community. Recently, a new audio-visual segmentation (AVS) task has been introduced, aiming to locate and segment the sounding objects in a given video. This task demands audio-driven pixel-level scene understanding for the first time, posing significant challenges. In this paper, we propose AVSegFormer, a novel framework for AVS tasks that leverages the transformer architecture. Specifically, we introduce audio queries and learnable queries into the transformer decoder, enabling the network to selectively attend to interested visual features. Besides, we present an audio-visual mixer, which can dynamically adjust visual features by amplifying relevant and suppressing irrelevant spatial channels. Additionally, we devise an intermediate mask loss to enhance the supervision of the decoder, encouraging the network to produce more accurate intermediate predictions. Extensive experiments demonstrate that AVSegFormer achieves state-of-the-art results on the AVS benchmark. The code is available at https://github.com/vvvb-github/AVSegFormer.
Object Recognition System on a Tactile Device for Visually Impaired
Jul 05, 2023People with visual impairments face numerous challenges when interacting with their environment. Our objective is to develop a device that facilitates communication between individuals with visual impairments and their surroundings. The device will convert visual information into auditory feedback, enabling users to understand their environment in a way that suits their sensory needs. Initially, an object detection model is selected from existing machine learning models based on its accuracy and cost considerations, including time and power consumption. The chosen model is then implemented on a Raspberry Pi, which is connected to a specifically designed tactile device. When the device is touched at a specific position, it provides an audio signal that communicates the identification of the object present in the scene at that corresponding position to the visually impaired individual. Conducted tests have demonstrated the effectiveness of this device in scene understanding, encompassing static or dynamic objects, as well as screen contents such as TVs, computers, and mobile phones.
Leveraging multilingual transfer for unsupervised semantic acoustic word embeddings
Jul 05, 2023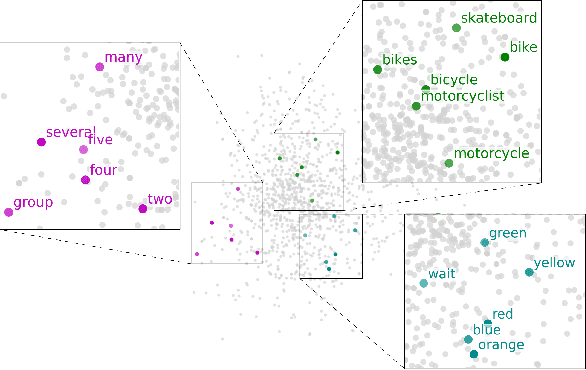
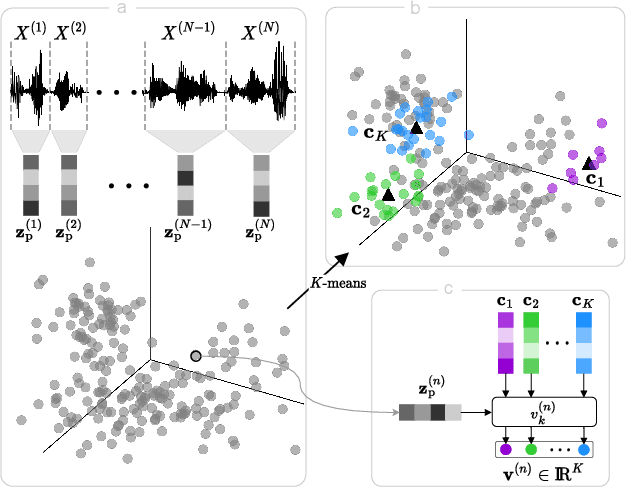
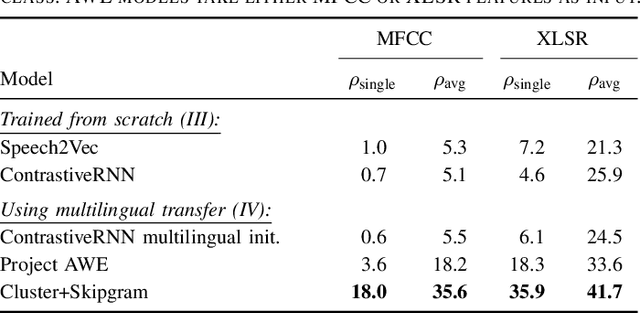
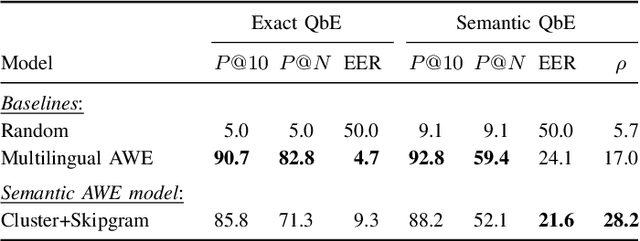
Acoustic word embeddings (AWEs) are fixed-dimensional vector representations of speech segments that encode phonetic content so that different realisations of the same word have similar embeddings. In this paper we explore semantic AWE modelling. These AWEs should not only capture phonetics but also the meaning of a word (similar to textual word embeddings). We consider the scenario where we only have untranscribed speech in a target language. We introduce a number of strategies leveraging a pre-trained multilingual AWE model -- a phonetic AWE model trained on labelled data from multiple languages excluding the target. Our best semantic AWE approach involves clustering word segments using the multilingual AWE model, deriving soft pseudo-word labels from the cluster centroids, and then training a Skipgram-like model on the soft vectors. In an intrinsic word similarity task measuring semantics, this multilingual transfer approach outperforms all previous semantic AWE methods. We also show -- for the first time -- that AWEs can be used for downstream semantic query-by-example search.
Elastic Decision Transformer
Jul 05, 2023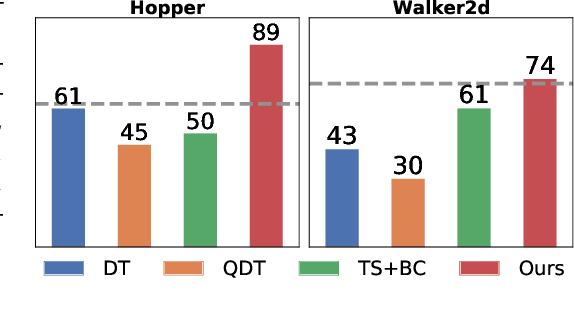

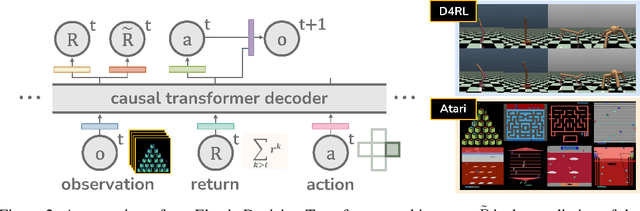
This paper introduces Elastic Decision Transformer (EDT), a significant advancement over the existing Decision Transformer (DT) and its variants. Although DT purports to generate an optimal trajectory, empirical evidence suggests it struggles with trajectory stitching, a process involving the generation of an optimal or near-optimal trajectory from the best parts of a set of sub-optimal trajectories. The proposed EDT differentiates itself by facilitating trajectory stitching during action inference at test time, achieved by adjusting the history length maintained in DT. Further, the EDT optimizes the trajectory by retaining a longer history when the previous trajectory is optimal and a shorter one when it is sub-optimal, enabling it to "stitch" with a more optimal trajectory. Extensive experimentation demonstrates EDT's ability to bridge the performance gap between DT-based and Q Learning-based approaches. In particular, the EDT outperforms Q Learning-based methods in a multi-task regime on the D4RL locomotion benchmark and Atari games. Videos are available at: https://kristery.github.io/edt/
Traversability Analysis for Autonomous Driving in Complex Environment: A LiDAR-based Terrain Modeling Approach
Jul 05, 2023
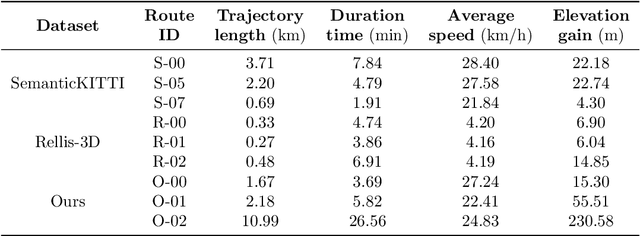
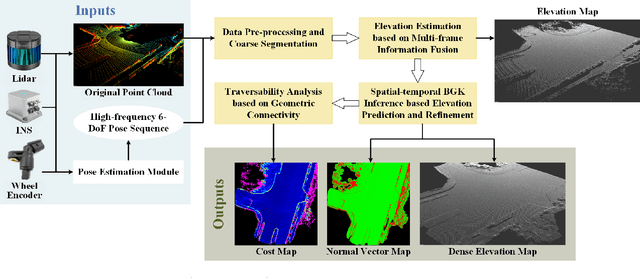

For autonomous driving, traversability analysis is one of the most basic and essential tasks. In this paper, we propose a novel LiDAR-based terrain modeling approach, which could output stable, complete and accurate terrain models and traversability analysis results. As terrain is an inherent property of the environment that does not change with different view angles, our approach adopts a multi-frame information fusion strategy for terrain modeling. Specifically, a normal distributions transform mapping approach is adopted to accurately model the terrain by fusing information from consecutive LiDAR frames. Then the spatial-temporal Bayesian generalized kernel inference and bilateral filtering are utilized to promote the stability and completeness of the results while simultaneously retaining the sharp terrain edges. Based on the terrain modeling results, the traversability of each region is obtained by performing geometric connectivity analysis between neighboring terrain regions. Experimental results show that the proposed method could run in real-time and outperforms state-of-the-art approaches.
* accepted to Journal of Field Robotics
Implementing contextual biasing in GPU decoder for online ASR
Jun 23, 2023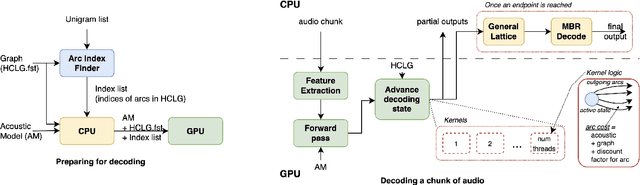
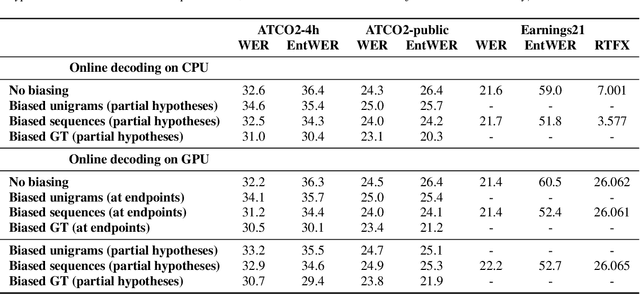
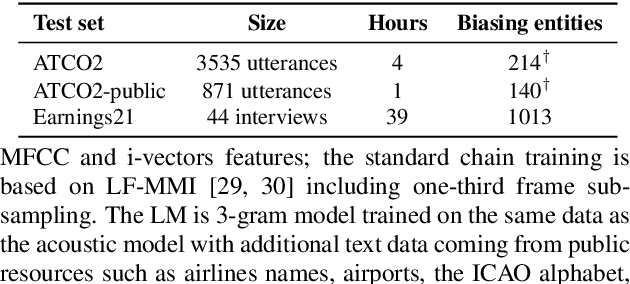
GPU decoding significantly accelerates the output of ASR predictions. While GPUs are already being used for online ASR decoding, post-processing and rescoring on GPUs have not been properly investigated yet. Rescoring with available contextual information can considerably improve ASR predictions. Previous studies have proven the viability of lattice rescoring in decoding and biasing language model (LM) weights in offline and online CPU scenarios. In real-time GPU decoding, partial recognition hypotheses are produced without lattice generation, which makes the implementation of biasing more complex. The paper proposes and describes an approach to integrate contextual biasing in real-time GPU decoding while exploiting the standard Kaldi GPU decoder. Besides the biasing of partial ASR predictions, our approach also permits dynamic context switching allowing a flexible rescoring per each speech segment directly on GPU. The code is publicly released and tested with open-sourced test sets.
Boosting Video Object Segmentation via Space-time Correspondence Learning
Apr 13, 2023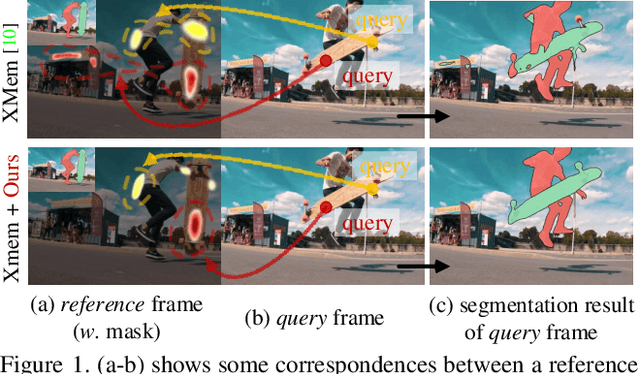
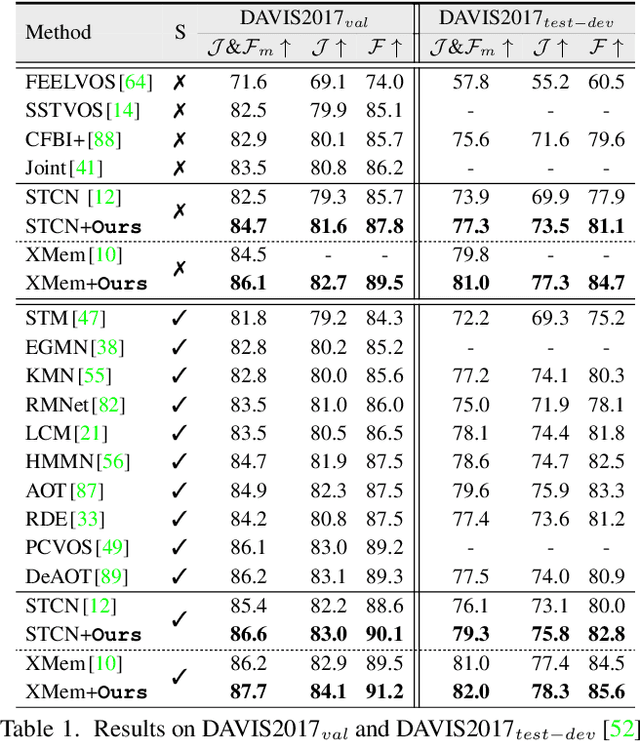
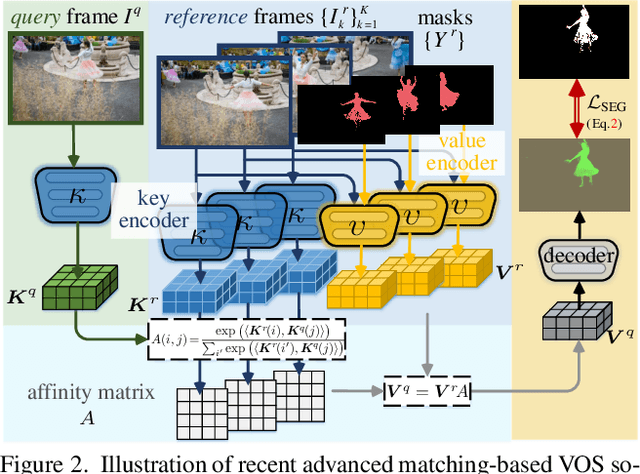
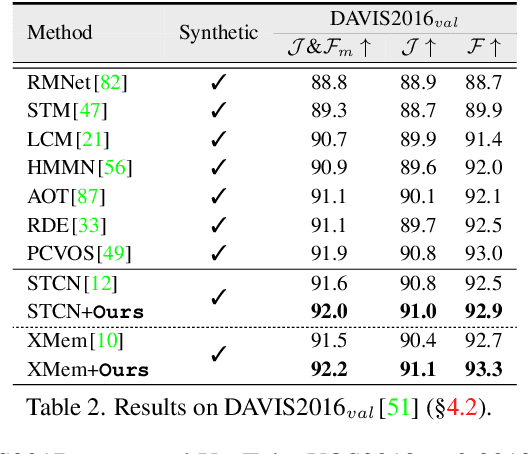
Current top-leading solutions for video object segmentation (VOS) typically follow a matching-based regime: for each query frame, the segmentation mask is inferred according to its correspondence to previously processed and the first annotated frames. They simply exploit the supervisory signals from the groundtruth masks for learning mask prediction only, without posing any constraint on the space-time correspondence matching, which, however, is the fundamental building block of such regime. To alleviate this crucial yet commonly ignored issue, we devise a correspondence-aware training framework, which boosts matching-based VOS solutions by explicitly encouraging robust correspondence matching during network learning. Through comprehensively exploring the intrinsic coherence in videos on pixel and object levels, our algorithm reinforces the standard, fully supervised training of mask segmentation with label-free, contrastive correspondence learning. Without neither requiring extra annotation cost during training, nor causing speed delay during deployment, nor incurring architectural modification, our algorithm provides solid performance gains on four widely used benchmarks, i.e., DAVIS2016&2017, and YouTube-VOS2018&2019, on the top of famous matching-based VOS solutions.
Self-supervised Optimization of Hand Pose Estimation using Anatomical Features and Iterative Learning
Jul 06, 2023
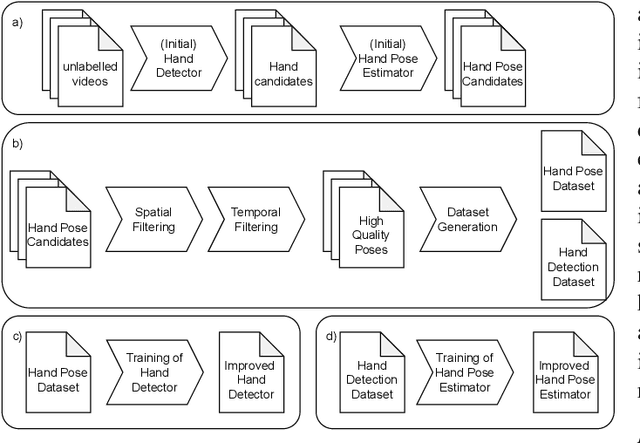
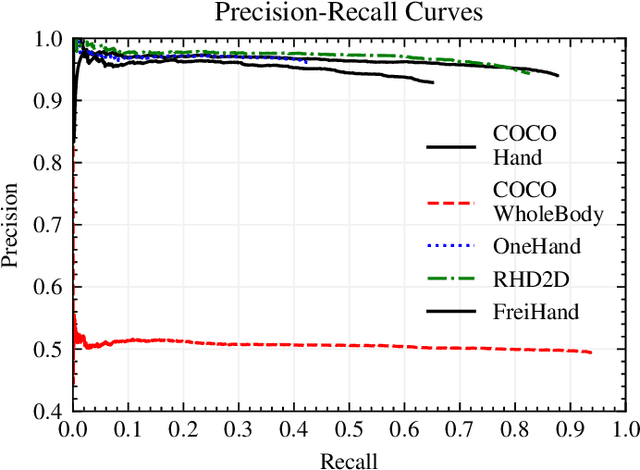
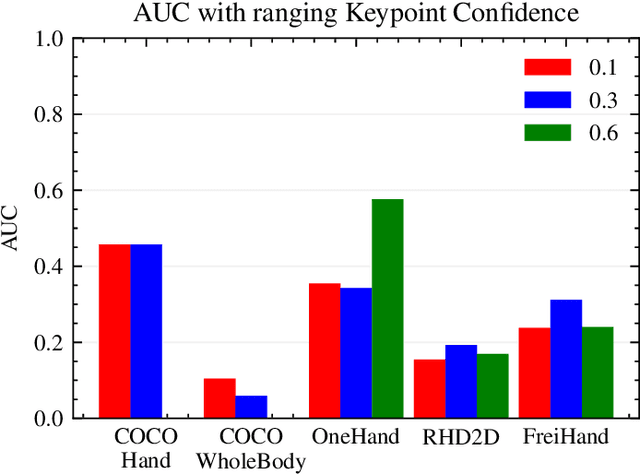
Manual assembly workers face increasing complexity in their work. Human-centered assistance systems could help, but object recognition as an enabling technology hinders sophisticated human-centered design of these systems. At the same time, activity recognition based on hand poses suffers from poor pose estimation in complex usage scenarios, such as wearing gloves. This paper presents a self-supervised pipeline for adapting hand pose estimation to specific use cases with minimal human interaction. This enables cheap and robust hand posebased activity recognition. The pipeline consists of a general machine learning model for hand pose estimation trained on a generalized dataset, spatial and temporal filtering to account for anatomical constraints of the hand, and a retraining step to improve the model. Different parameter combinations are evaluated on a publicly available and annotated dataset. The best parameter and model combination is then applied to unlabelled videos from a manual assembly scenario. The effectiveness of the pipeline is demonstrated by training an activity recognition as a downstream task in the manual assembly scenario.