 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Consideration for the Perceptron
Sep 24, 2024



In this paper, we introduce the gated perceptron, an enhancement of the conventional perceptron, which incorporates an additional input computed as the product of the existing inputs. This allows the perceptron to capture non-linear interactions between features, significantly improving its ability to classify and regress on complex datasets. We explore its application in both linear and non-linear regression tasks using the Iris dataset, as well as binary and multi-class classification problems, including the PIMA Indian dataset and Breast Cancer Wisconsin dataset. Our results demonstrate that the gated perceptron can generate more distinct decision regions compared to traditional perceptrons, enhancing its classification capabilities, particularly in handling non-linear data. Performance comparisons show that the gated perceptron competes with state-of-the-art classifiers while maintaining a simple architecture.
Visual Geo-Localization from images
Jul 20, 2024This paper presents a visual geo-localization system capable of determining the geographic locations of places (buildings and road intersections) from images without relying on GPS data. Our approach integrates three primary methods: Scale-Invariant Feature Transform (SIFT) for place recognition, traditional image processing for identifying road junction types, and deep learning using the VGG16 model for classifying road junctions. The most effective techniques have been integrated into an offline mobile application, enhancing accessibility for users requiring reliable location information in GPS-denied environments.
An Embedded Intelligent System for Attendance Monitoring
Jun 19, 2024In this paper, we propose an intelligent embedded system for monitoring class attendance and sending the attendance list to a remote computer. The proposed system consists of two parts : an embedded device (Raspberry with PI camera) for facial recognition and a web application for attendance management. The proposed solution take into account the different challenges: the limited resources of the Raspberry Pi, the need to adapt the facial recognition model and achieving acceptable performance using images provided by the Raspberry Pi camera.
Towards Real Time Egocentric Segment Captioning for The Blind and Visually Impaired in RGB-D Theatre Images
Aug 26, 2023In recent years, image captioning and segmentation have emerged as crucial tasks in computer vision, with applications ranging from autonomous driving to content analysis. Although multiple solutions have emerged to help blind and visually impaired people move around their environment, few are applications that help them understand and rebuild a scene in their minds through text. Most built models focus on helping users move and avoid obstacles, restricting the number of environments blind and visually impaired people can be in. In this paper, we will propose an approach that helps them understand their surroundings using image captioning. The particularity of our research is that we offer them descriptions with positions of regions and objects regarding them (left, right, front), as well as positional relationships between regions, while we aim to give them access to theatre plays by applying the solution to our TS-RGBD dataset.
TS-RGBD Dataset: a Novel Dataset for Theatre Scenes Description for People with Visual Impairments
Aug 02, 2023Computer vision was long a tool used for aiding visually impaired people to move around their environment and avoid obstacles and falls. Solutions are limited to either indoor or outdoor scenes, which limits the kind of places and scenes visually disabled people can be in, including entertainment places such as theatres. Furthermore, most of the proposed computer-vision-based methods rely on RGB benchmarks to train their models resulting in a limited performance due to the absence of the depth modality. In this paper, we propose a novel RGB-D dataset containing theatre scenes with ground truth human actions and dense captions annotations for image captioning and human action recognition: TS-RGBD dataset. It includes three types of data: RGB, depth, and skeleton sequences, captured by Microsoft Kinect. We test image captioning models on our dataset as well as some skeleton-based human action recognition models in order to extend the range of environment types where a visually disabled person can be, by detecting human actions and textually describing appearances of regions of interest in theatre scenes.
Object Recognition System on a Tactile Device for Visually Impaired
Jul 05, 2023People with visual impairments face numerous challenges when interacting with their environment. Our objective is to develop a device that facilitates communication between individuals with visual impairments and their surroundings. The device will convert visual information into auditory feedback, enabling users to understand their environment in a way that suits their sensory needs. Initially, an object detection model is selected from existing machine learning models based on its accuracy and cost considerations, including time and power consumption. The chosen model is then implemented on a Raspberry Pi, which is connected to a specifically designed tactile device. When the device is touched at a specific position, it provides an audio signal that communicates the identification of the object present in the scene at that corresponding position to the visually impaired individual. Conducted tests have demonstrated the effectiveness of this device in scene understanding, encompassing static or dynamic objects, as well as screen contents such as TVs, computers, and mobile phones.
Theater Aid System for the Visually Impaired Through Transfer Learning of Spatio-Temporal Graph Convolution Networks
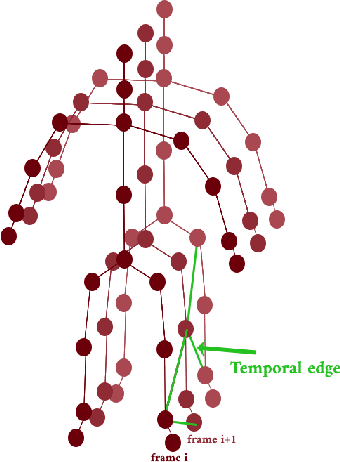
Jun 28, 2023The aim of this research is to recognize human actions performed on stage to aid visually impaired and blind individuals. To achieve this, we have created a theatre human action recognition system that uses skeleton data captured by depth image as input. We collected new samples of human actions in a theatre environment, and then tested the transfer learning technique with three pre-trained Spatio-Temporal Graph Convolution Networks for skeleton-based human action recognition: the spatio-temporal graph convolution network, the two-stream adaptive graph convolution network, and the multi-scale disentangled unified graph convolution network. We selected the NTU-RGBD human action benchmark as the source domain and used our collected dataset as the target domain. We analyzed the transferability of the pre-trained models and proposed two configurations to apply and adapt the transfer learning technique to the diversity between the source and target domains. The use of transfer learning helped to improve the performance of the human action system within the context of theatre. The results indicate that Spatio-Temporal Graph Convolution Networks is positively transferred, and there was an improvement in performance compared to the baseline without transfer learning.
A Computational Model for Machine Thinking
Jan 20, 2022


A machine thinking model is proposed in this report based on recent advances of computer vision and the recent results of neuroscience devoted to brain understanding. We deliver the result of machine thinking in the form of sentences of natural-language or drawn sketches either informative or decisional. This result is obtained from a reasoning performed on new acquired data and memorized data.
Semantic Labeling of Human Action For Visually Impaired And Blind People Scene Interaction
Jan 12, 2022
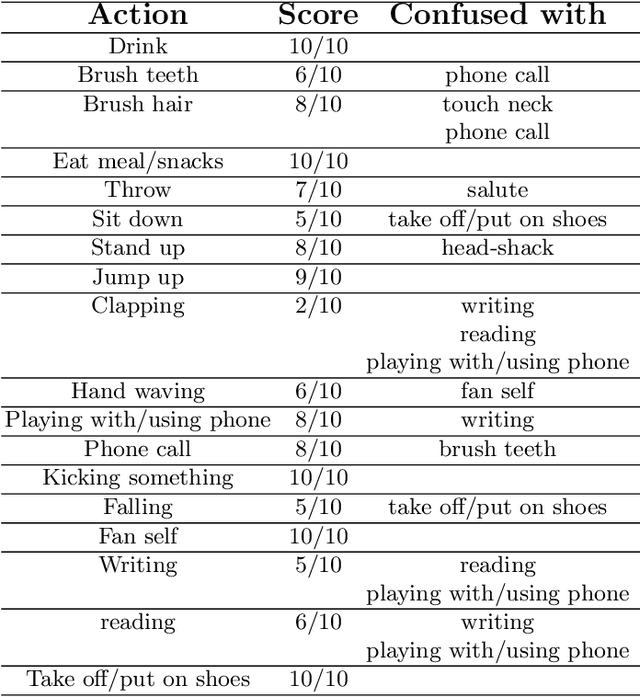
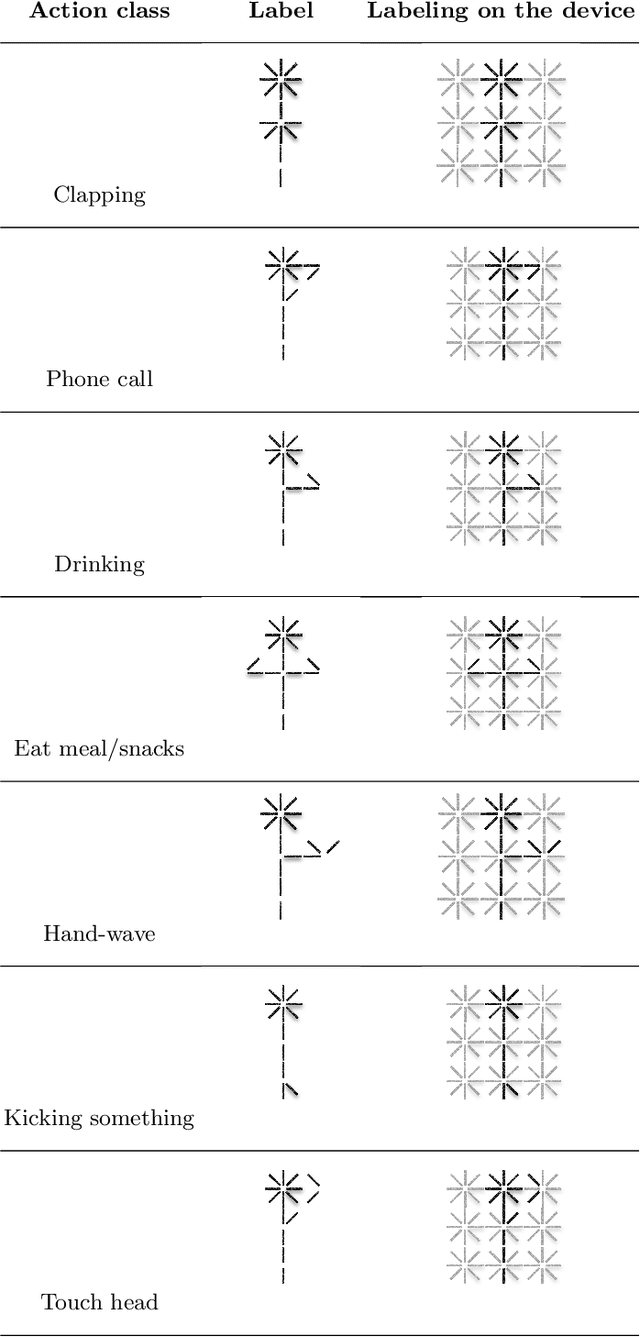
The aim of this work is to contribute to the development of a tactile device for visually impaired and blind persons in order to let them to understand actions of the surrounding people and to interact with them. First, based on the state-of-the-art methods of human action recognition from RGB-D sequences, we use the skeleton information provided by Kinect, with the disentangled and unified multi-scale Graph Convolutional (MS-G3D) model to recognize the performed actions. We tested this model on real scenes and found some of constraints and limitations. Next, we apply a fusion between skeleton modality with MS-G3D and depth modality with CNN in order to bypass the discussed limitations. Third, the recognized actions are labeled semantically and will be mapped into an output device perceivable by the touch sense.
Visual Place Representation and Recognition from Depth Images
Dec 27, 2021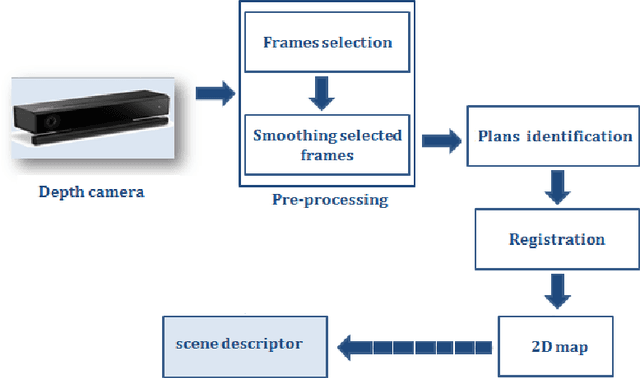
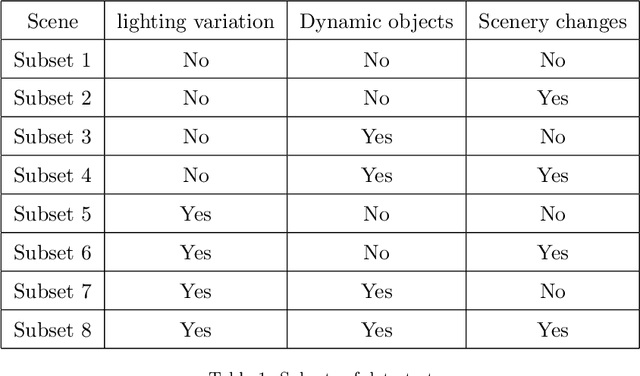
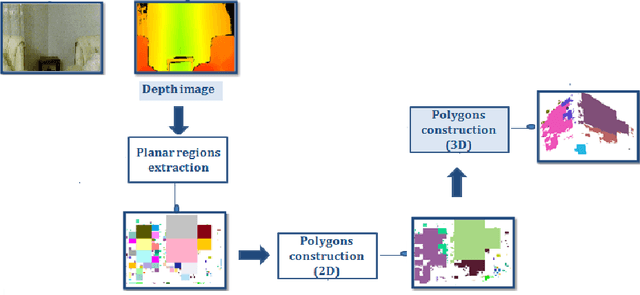
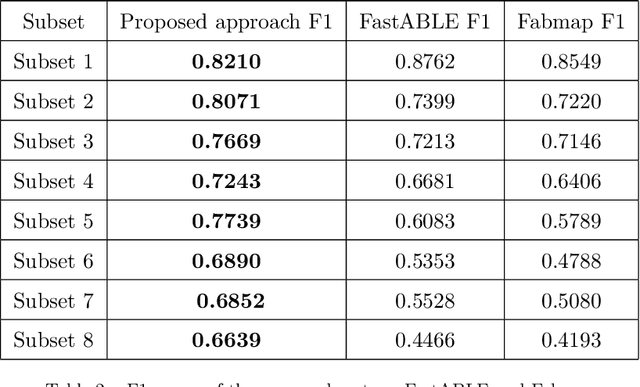
This work proposes a new method for place recognition based on the scene architecture. From depth video, we compute the 3D model and we derive and describe geometrically the 2D map from which the scene descriptor is deduced to constitute the core of the proposed algorithm. The obtained results show the efficiency and the robustness of the propounded descriptor to scene appearance changes and light variations.